CHAPTER 9: DESIGN A WEB CRAWLER
Step 1 - Understand the problem and establish design scope
- Given a set of URLs, download all the web pages addressed by the URLs.
- Extract URLs from these web pages
- Add new URLs to the list of URLs to be downloaded. Repeat these 3 steps.
Candidate: What is the main purpose of the crawler? Is it used for search engine indexing,
data mining, or something else?
Interviewer: Search engine indexing.
Candidate: How many web pages does the web crawler collect per month?
Interviewer: 1 billion pages.
Candidate: What content types are included? HTML only or other content types such as PDFs and images as well?
Interviewer: HTML only.
Candidate: Shall we consider newly added or edited web pages?
Interviewer: Yes, we should consider the newly added or edited web pages.
Candidate: Do we need to store HTML pages crawled from the web?
Interviewer: Yes, up to 5 years
Candidate: How do we handle web pages with duplicate content?
Interviewer: Pages with duplicate content should be ignored.
Scalability: The web is very large. There are billions of web pages out there. Web
crawling should be extremely efficient using parallelization.
• Robustness: The web is full of traps. Bad HTML, unresponsive servers, crashes,
malicious links, etc. are all common. The crawler must handle all those edge cases.
• Politeness: The crawler should not make too many requests to a website within a short
time interval.
• Extensibility: The system is flexible so that minimal changes are needed to support new
content types. For example, if we want to crawl image files in the future, we should not
need to redesign the entire system.
Back of the envelope estimation
• Assume 1 billion web pages are downloaded every month.
• QPS: 1,000,000,000 / 30 days / 24 hours / 3600 seconds = ~400 pages per second.
• Peak QPS = 2 * QPS = 800
• Assume the average web page size is 500k.
• 1-billion-page x 500k = 500 TB storage per month. If you are unclear about digital
storage units, go through “Power of 2” section in Chapter 2 again.
• Assuming data are stored for five years, 500 TB * 12 months * 5 years = 30 PB. A 30 PB
storage is needed to store five-year content.
Step 2 - Propose high-level design and get buy-in

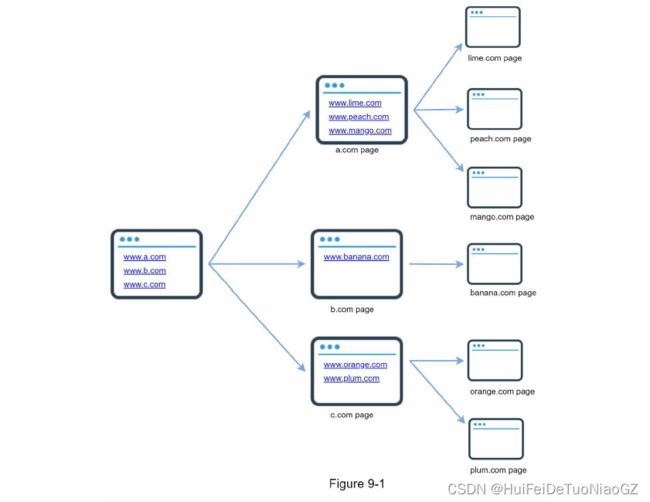
A good seed URL serves as a good starting point that a crawler can utilize to traverse as many links as possible.
The general strategy is to divide the entire URL space into smaller ones. The first proposed approach is based on locality as different countries may have different popular websites.
Another way is to choose seed URLs based on topics
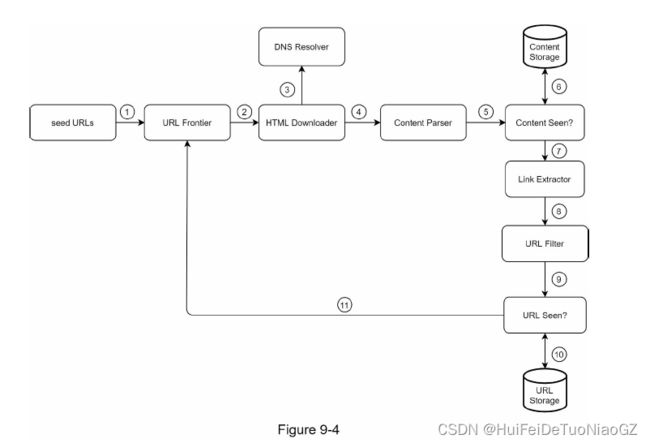
URL Frontier
Most modern web crawlers split the crawl state into two: to be downloaded and already downloaded.
You can refer to this as a First-in-First-out (FIFO) queue.
Content Seen?
To compare two HTML documents, we can compare them character by character.
An efficient way to accomplish this task is to compare the hash values of the two web pages
Content Storage
Most of the content is stored on disk because the data set is too big to fit in memory.
• Popular content is kept in memory to reduce latency.
URL Extractor

URL Seen?
Bloom filter and hash table
Web crawler workflow
Step 3 - Design deep dive
DFS vs BFS
DFS is usually not a good choice because the depth of DFS can be very deep.
Most links from the same web page are linked back to the same host.
When the crawler tries to download web pages in parallel, Wikipedia servers will be flooded with requests. This is considered as “impolite”.
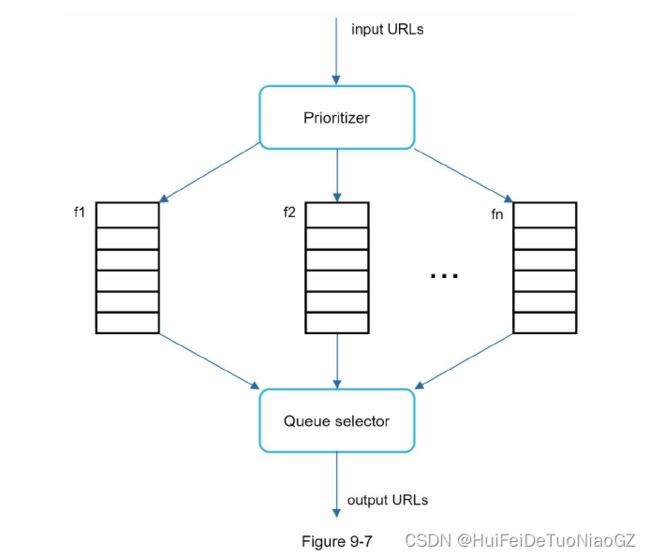
Standard BFS does not take the priority of a URL into consideration. The web is large and not every page has the same level of quality and importance. Therefore, we may want to prioritize URLs according to their page ranks, web traffic, update frequency, etc.
URL frontier
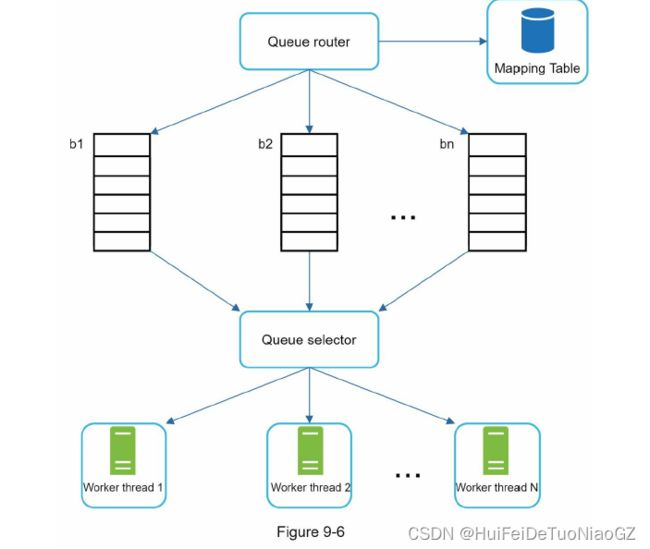
The general idea of enforcing politeness is to download one page at a time from the same host. A delay can be added between two download tasks.
Priority
We prioritize URLs based on usefulness, which can be measured by PageRank [10], website traffic, update frequency, etc. “Prioritizer” is the component that handles URL prioritization. Refer to the reference materials [5] [10] for in-depth information about this concept.

Freshness
• Recrawl based on web pages’ update history.
• Prioritize URLs and recrawl important pages first and more frequently.
Storage for URL Frontier
We adopted a hybrid approach. The majority of URLs are stored on disk, so the storage space is not a problem. To reduce the cost of reading from the disk and writing to the disk, we maintain buffers in memory for enqueue/dequeue operations. Data in the buffer is periodically written to the disk.
HTML Downloader
Robots Exclusion Protocol
crawl a web site, a crawler should check its corresponding robots.txt first and follow its rules.
To avoid repeat downloads of robots.txt file, we cache the results of the file.
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people//reviews
Disallow: /gp/pdp/rss//reviews
Disallow: /gp/cdp/member-reviews/
Disallow: /gp/aw/cr/
Performance optimization
1. Distributed crawl

2. Cache DNS Resolver
3. Locality
Distribute crawl servers geographically. When crawl servers are closer to website hosts,
crawlers experience faster download time. Design locality applies to most of the system components: crawl servers, cache, queue, storage, etc.
4. Short timeout
To avoid long wait time, a maximal wait time is specified.
Robustness
Consistent hashing
A new downloader server can be added or removed using consistent hashing
Save crawl states and data
Exception handling
Data validation
Extensibility
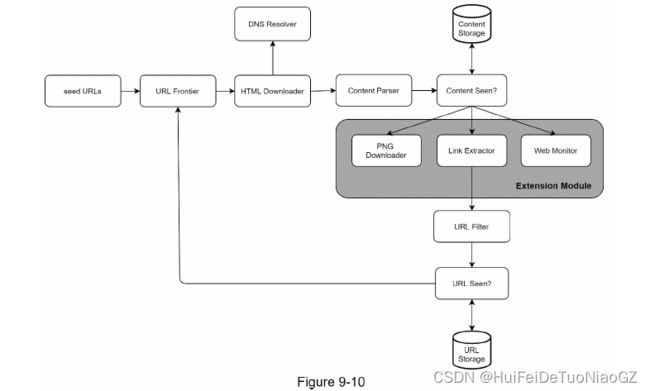
• PNG Downloader module is plugged-in to download PNG files.
• Web Monitor module is added to monitor the web and prevent copyright and trademark infringements.
Detect and avoid problematic content
- Spider traps
A spider trap is a web page that causes a crawler in an infinite loop. - Data noise
Step 4 - Wrap up
• Server-side rendering: Numerous websites use scripts like JavaScript, AJAX, etc to
generate links on the fly. If we download and parse web pages directly, we will not be able
to retrieve dynamically generated links. To solve this problem, we perform server-side
rendering (also called dynamic rendering) first before parsing a page [12].
• Filter out unwanted pages: With finite storage capacity and crawl resources, an anti-spam
component is beneficial in filtering out low quality and spam pages [13] [14].
• Database replication and sharding: Techniques like replication and sharding are used to
improve the data layer availability, scalability, and reliability.
• Horizontal scaling: For large scale crawl, hundreds or even thousands of servers are
needed to perform download tasks. The key is to keep servers stateless.
• Availability, consistency, and reliability: These concepts are at the core of any large
system’s success. We discussed these concepts in detail in Chapter 1. Refresh your
memory on these topics.
• Analytics: Collecting and analyzing data are important parts of any system because data
is key ingredient for fine-tuning.