关于爬虫反爬机制处理方法(整合)
常见得反爬机制及解决办法
1、针对请求头做出得反爬
简介:网站通过去检查headers中的User-Agent字段来反爬,如果我们没有设置请求头,那么headers默认是python这样就会出现访问失败、没有权限等原因,如果去伪造一个请求头是可以避开得,不过如果短时间内频繁使用同一个User-Agent访问可能会被检测出来导致被封掉爬虫
解决办法:通过fake_useragent构造随机请求头
第一步:下载fake_useragent
可以直接在cmd当中输入:
pip install fake-useragent接下来设置代码如下:
import requests
from fake_useragent import UserAgent
import random #随机模块
ua = UserAgent() # 创建User-Agent对象
useragent = ua.random
headers = {'User-Agent': useragent}
到这里得时候其实已经写好了,但肯定有小伙伴会想着去测试一下是不是真的自己使用了随机请求头那么我们去访问 http://httpbin.org/headers 看下返回得请求头数据
第二步:验证请求头
import requests
from fake_useragent import UserAgent
import random #随机模块
ua = UserAgent() # 创建User-Agent对象
useragent = ua.random #随机使用请求头
headers = {'User-Agent': useragent}
url='http://httpbin.org/headers'
renoes=requests.get(url,headers=headers)
print(renoes.text)运行两次结果如下
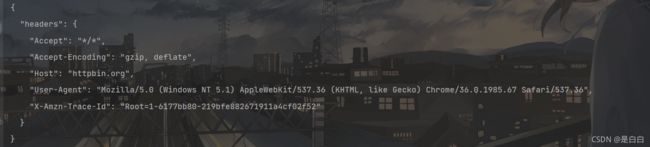

可以发现请求头已经发生了变化并且每次不一样
补充说明一点:
在使用fake_useragent有时候会报错第一个原因可能是UserAgent列表发生了变动,而本地UserAgent的列表未更新所导致
解决方法可以参考这篇文章
(21条消息) 解决fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached问题_一条会编程的鱼-CSDN博客 https://blog.csdn.net/weixin_43581288/article/details/106529656?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163523713016780357226389%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163523713016780357226389&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-106529656.first_rank_v2_pc_rank_v29&utm_term=fake_useragent.errors.FakeUserAgentError%3A+Maximum+amount+of+retries+reached&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_43581288/article/details/106529656?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163523713016780357226389%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163523713016780357226389&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-106529656.first_rank_v2_pc_rank_v29&utm_term=fake_useragent.errors.FakeUserAgentError%3A+Maximum+amount+of+retries+reached&spm=1018.2226.3001.4187
如果通过上面那篇文章还是没有解决报错可以参考下面这篇
(21条消息) 简单修改setting文件,解决fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached_大河的博客-CSDN博客https://blog.csdn.net/qq_45773419/article/details/119063825?spm=1001.2014.3001.5506
然后得话还有一个要注意得地,用这个方法爬取某些网站得时候获取网站源代码,你会发现获取得竟然是一个提示,提示说浏览器版本太老啦,其实这个原因就是fake_useragent里面浏览器版本确实挺低得,遇到这种情况用自己得浏览器请求头就可以解决,可以这样写
import requests
import random #随机模块
#这个列表里面存放你自己收集来得请求头,下面得请求头是我用fake_useragent随机生成得,仅用来做演示如果直接使用还是有可能会提示浏览器版本低
UserAgents=[
'Mozilla/5.0 (Windows x86; rv:19.0) Gecko/20100101 Firefox/19.0',
'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
'Mozilla/5.0 (Microsoft Windows NT 6.2.9200.0); rv:22.0) Gecko/20130405 Firefox/22.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36'
]
user_agent=random.choice(UserAgents)
headers = {'User-Agent':user_agent}
url='http://httpbin.org/headers'
renoes=requests.get(url,headers=headers)
print(renoes.text)2、针对ip做出得反爬
简介:网站后台检测到IP频繁访问,从而封掉IP地址
解决办法:使用代理IP 或者构建IP代理池
使用代理IP的话个人是比较推荐快代理的隧道代理 快代理 - 企业级代理云服务提供商 (kuaidaili.com)
原因嘛就是可以每次请求更换IP地址配合上面说的随机请求头更加保险

当然设置起来也是很简单的他们官方有专门的技术文档,在代码样例里面可以看到也是支持下载代码到本地

3、账号封禁
简介:有的网站必须要求登录账号才能继续访问,如果我们用一个账号爬取过于频繁就会导致这个账号被封禁
解决办法:使用接码平台注册账号(这里不过多讲解具体操作,自己百度一下吧~)
4、处理验证码
简介:我们在爬取一些网站的时候它们并不是静态页面,而是通过Ajax交互来异步更新网页
解决办法:分析其JS接口、使用selenium模拟浏览器来获取数据(后面得话都是将如何用selenium获取数据,因为分析JS接口有些网站会加密本人目前暂时不会JS逆向,下次一定补上)

1、处理普通的图像验证码
列如:
这种的话可以使用tesseract这个库去识别,但是吧这样费时费力而且识别准确度不高不如直接动用打码平台快,可以使用超级鹰打码平台便宜速度还快
处理方法参考我写的另外一篇文章:
超级鹰的使用方式_m0_59874815的博客-CSDN博客首先肯定要有一个账号嘛超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大 (chaojiying.com)注册我觉得没啥好说的小伙伴门自己来哈,注册好账号之后我们点击开发文档,选择自己的语言我这里选择的是python点击下载之后得到的是一个压缩文件需要解压我们点击这个文件即可其它不用管这里更换为自己的账号密码,最后的软件ID如下图获取这里需要注意的是由于是python3的版本我们还需要在print后面加上()到这里就差...https://blog.csdn.net/m0_59874815/article/details/121007373
2、处理图像识别
列如:
这种我依然使用的超级鹰打码,不过的话有些图片实在是太模糊识别成功率吧~不会太高不过勉强能用
处理方法参考我写的另外一篇文章:
使用python+selenium超级鹰破解图像识别验证码_m0_59874815的博客-CSDN博客大家做爬虫的时候肯定会遇到很多验证码列如本文所指的图像识别:我在爬取拉勾网的时候过于频繁被跳转到了验证系统,真是令人头大url=安全访问验证-拉勾网https://sec.lagou.com/verify.html?e=2&f=https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=我们需要先点击这里的验证按钮之后就会直接跳出图像验证码,在识别完成之后点击...https://blog.csdn.net/m0_59874815/article/details/121048996
3、处理滑块验证
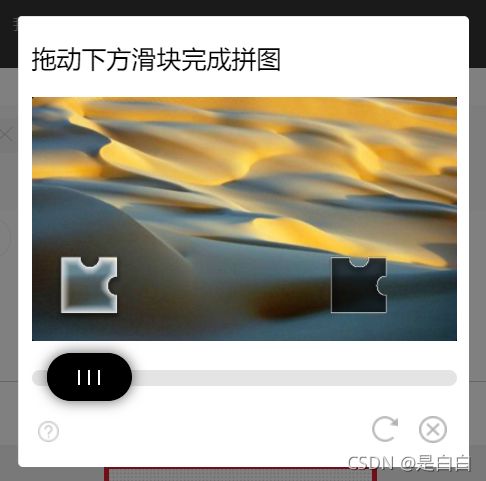
这种我们使用opencv来识别缺口从而模拟拖动
处理方法如下:
selenium+opencv破解滑块验证码_m0_59874815的博客-CSDN博客 https://blog.csdn.net/m0_59874815/article/details/121195481?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_59874815/article/details/121195481?spm=1001.2014.3001.5501
4、使用selenium获取cookie,并且携带cookie信息登录从而避免再次认证
之前我们不是已经介绍了验证码如何处理嘛,那我们第一次模拟登录之后下一次总不能在继续识别验证码之后在登陆吧,这样很烧钱得呀(超级鹰识别要钱,虽然不贵但那也是钱嘛)而且还不能保证成功率,所以我们模拟登录之后需要获取其cookie信息下次在登录直接携带即可
处理方法参考我写的另外一篇文章:
selenium获取cookie并携带模拟登录_m0_59874815的博客-CSDN博客前言:有小伙伴可能会觉得明明F12在开发者选项里面就能获取到cookie信息为啥还要专门写一个程序去获取,这不多此一举嘛其实并不是哟,首先呢一般你直接登录之后得cookie信息都是不完整得只有一条而且大部分都是加密过得,哪怕我们假设它是完整得你直接复制之后selenium也接受不了,因为直接复制得格式不是selenium要求的你再去转换格式不得很麻烦呀不多废话哈切入正题,这次测试得目标网站为QQ空间 https://mail.qq.com/1、获取cookie信息先定义前面...https://blog.csdn.net/m0_59874815/article/details/121183959
好了反爬整合就写到这里拉,以后想起啥在补充吧
声明
本文仅限于做技术交流学习,请勿用作任何非法用途!