RNN和LSTM 原理与实践1
引言:
本篇是学习了台湾大学李宏毅老师的课程关于RNN的讲解一些学习心得,分为三个博客,原理在第1,扩展在第2篇,实践在3篇(时间序列预测,tensorflow官网示例),避免直接照抄课件,博客里的图有或多或少的修改,当然本文只是对于RNN学习总结,有不对之处尽请见谅。
背景:
Recurrent Neural Network (RNN)循环神经网络,循环神经网络,启发自神经学,发现了大脑皮层的刺激在神经回路中循环传递,认为是短期记忆的原因。所以记忆是它的一大特点之一,所以在对序列处理上具有优势,在自然语言处理,语音识别,机器翻译,和有关时间序列都有很好的效果,常见网络有双向循环(Bi-RNN)和长短期记忆网络(LSTM)。
示例:
考虑现实关于slot filling一个示例,可能大家都有用过类似订票或者快递系统,输入一句话,会自动识别出里面的地名,人名,日期等信息,下面就是关于订票的一个例子,自动识别出地点和日期。
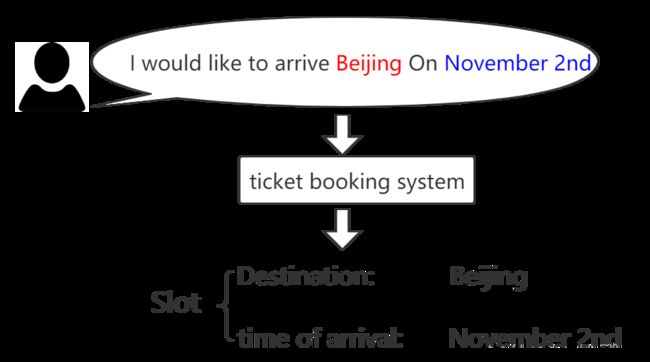
要实现这样的一个需求,我们可以根据设计这样的一个前馈网络:
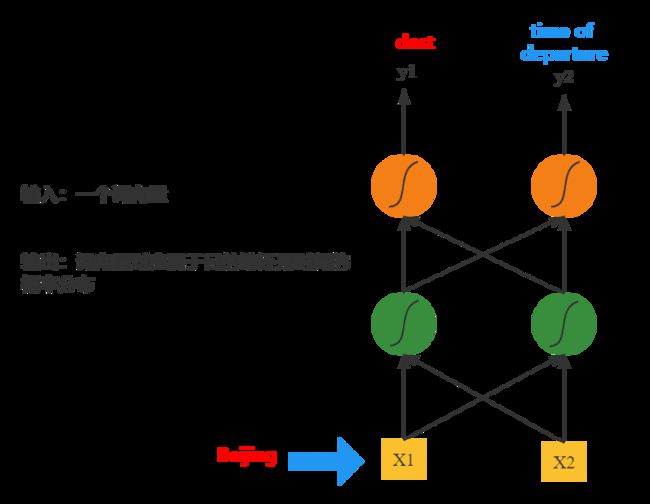
把每个词都当初一个向量输入,输出是对应这个词向量在属于地点,日期的概率。关于词如何变成一个向量有许多种方法,比如用1-of-N encoding的方法,也是老师在视频中提到的,如下:
词典有猫,狗,大象,苹果
lexicon = {cat, dog, elephant, apple}
那么每个词就可以表示成:
cat={1,0,0,0}
dog={0,1,0,0}
elephant={0,0,1,0}
apple={0,0,0,1}
考虑到有其他未在词典的词汇,可以多加一维other,这时候比如bag词
bag={0,0,0,0,1}
题外话:个人感觉,这边老师只是想说如何把一个词变成向量形式,所以举例了1-of-N encoding,但其实1-of-N 每个workd的 vector都是不一样的,比如现在有“台北”和“北京”两个词,他们都是属于地名这个范畴,但是他们vector却是不一样的,对于网络学习这样不同vector输出都是dest,个人感觉好像有点怪怪的,如果要充分考虑到词的相似性,感觉直接用word embedding可能就可以搞定了,其实应该只是为了引出RNN而做的铺垫。
回到正题,不管怎么样,只需要词变成向量形式到网络进行训练即可,但是这样又会出现一个问题,如下:

说这样两句话时候,网络并不会识别出来哪个地名属于出发地,哪个地名属于目的地,关键在于我们的网络是对于每个词单独进行预测,没有充分考虑到上下文的信息。而地点前面的动词,比如“leave”和“arrive”,往往是对后面地名隶属于出发地还是目的地产生很大影响,所以这时候引出RNN,我们需要一个网络能够有记忆的能力,他的输出不单单是取决于当前信息还借鉴了以往的信息。
循环神经网络RNN
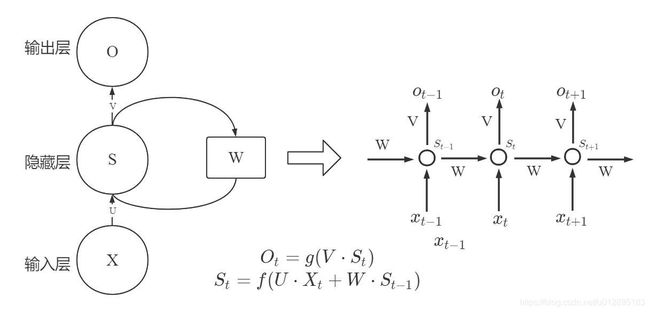
如图所示,是RNN(Recurrent Neural Network)的最基本结构图,假如把W的权重矩阵遮挡住,其实就是一个常见前馈网络,St只取决于输入Xt,而RNN由于是处理时间序列的,他的隐含层输出不单单取决于输入,还取决于上一时刻的输出St-1。
把上面那个例子,导入到RNN的模型来,就如下图所示,对于beijing的输入不单单有beijing本身,还会考虑到前面是leave还是arrive的信息。

当然RNN网络可以是deep,这里就不画了,也就是中间绿色的方块可以多层,这边插一句,当然实际在用的时候很可能不会像这样,可能是前一个网络输出然后再到RNN或者输出会另外接其他的网络,比如会在y输出再加全连接层。
Elman Network & Jordan Network &Bidirectional RNN
RNN有不同的变型,其中Elman network是Jeff Elman在1990年提出来的,叫做简单循环网络(simple recurrent networks,简称SRN)又称为Elman network,是在Jordan network(1986)的基础上进行了创新,并且简化了它的结构。两种网络结构如下图:

Elman network 就是把上一时刻存在来再下一个时间点使用起来,而Jordan network是把上一次的output在下一时刻使用起来,有提到Jordan network是有比较好的性能,因为很多时候output是有优化的目标的,所以会有比较好的性能。

而Bidirectional RNN是一个双向的RNN, 比如有一个句子,某个词的含义不单单通过前文信息,还有通过后文的信息,真正的上下文信息,它的优势在判断某个词是哪个slot时候它能够看完整个句子在进行判断。
长短期记忆网络LSTM
接下来轮到LSTM了(Long Short-Term Memory),其实很多时候场合说RNN都是说LSTM网络。这边也是遵循老师PPT,从简单结构理解到最终形态,先说说它的简单结构如图所示,有三个门,分别为输入门(input gate),输出门(output gate),以及遗忘门或者叫忘记门(forget gate),加上每个门都有自己控制信号和输入,输出,整个网络包裹在一个框中可以认为是四输入,一输出的一个网络。

下面就来说说我对LSTM理解,以上述slot filling问题为例,一个句子的某个词是有上下文关系的,所以网络需要有记忆能力,能够根据上下文信息对输入信息一种补充
- 忘记门:前面说网络需要记忆能力,那么前一刻的记忆信息到下一刻是否全部使用,答案是不一定,只是提取感兴趣的部分,或者叫遗忘掉不感兴趣部分,这里程度由控制信号决定。
- 输入门:图中的输入,可能画的还不够准确,到达橙色框的箭头上再标个W矩阵,实际上对输入是有做变换的,比如一个输入是一个一维序列x,经过了权重矩阵W的变换变成了x',这边变换可能是类似降维,或者转换后x'有更好表现力,而由输入门是将转换后x’进行再提取,类似忘记门,程度由控制信号决定。
- 输出门:输入结合了第1步提取后的信息和第二提取后输入信息,再由输出信号决定保留多少形成最终的输出。
如果上图能够清楚流程,那么由此过渡到这个图,也是最经常见到的LSTM的图:

类比于前一图,属于控制信号在图中是 ,即sigmoid层,取值范围在0~1,就很像阀门一样,是开还是关还是半开半掩,而图中Forget Gate,忘记门的控制信号就是ft,依次类推,输入层的控制信号是it,属于输出层控制信号是ot。
,即sigmoid层,取值范围在0~1,就很像阀门一样,是开还是关还是半开半掩,而图中Forget Gate,忘记门的控制信号就是ft,依次类推,输入层的控制信号是it,属于输出层控制信号是ot。
这幅图比前一张图复杂在于,前一张图没有讲控制信号是如何来的,从这张图说明了它的输入是xt和ht-1,也就是说它是由这一时刻的输入xt和上一时刻的输出ht-1构成的,所以下面依次拆分开:
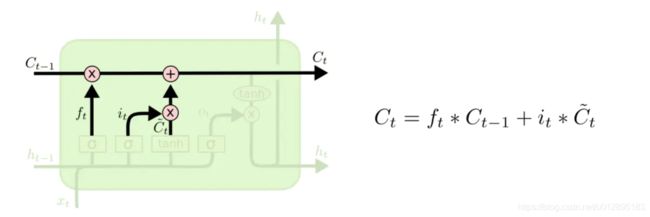
忘记门或遗忘门:
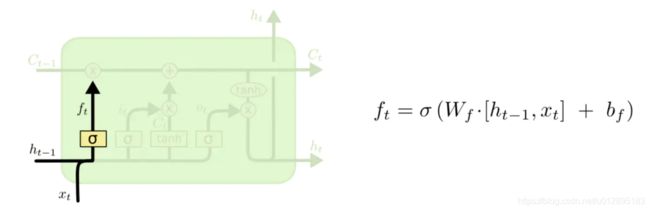
输入是ht-1和xt,经过了Wf权重矩阵转换再加上偏移矩阵bf,经过sigmoid,形成了控制信号ft.
而后续的步骤就是直接将控制信号ft和Ct-1相乘。
输入门:
类比,控制信号it,输入是ht-1和xt,经过了Wi权重矩阵转换再加上偏移矩阵bi,经过sigmoid,形成了控制信号it.
然后对于输入的提取多少,提取的过程经过WC权重矩阵转换和偏移矩阵bc,再经过tanh.

更新Cell:
更新网络记忆单元的值Ct,这个值奠定了后面输出门的输入。
输出门:
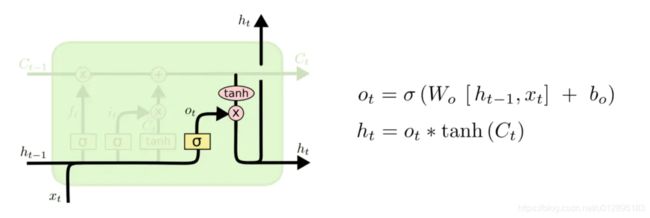
依次类推,输出门的控制信号ot,以及更新完cell作为输入Ct,经过tanh和信号ot输出ht
如果不同时刻,图就是如下:

LSTM变种-peephole
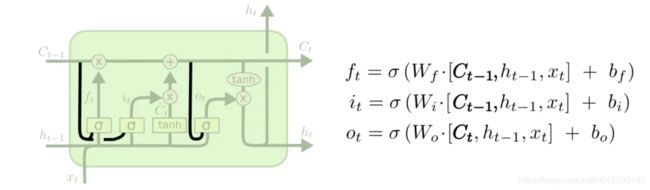
这时候再每个控制信号的输入,增加了窥视,也就是Ct-1,变成了Ct-1和ht-1,xt三个,在tensorflow有peepholeLSTMCell,但是还莫有去真实使用过,如果有更新就在第三篇实际代码上讲解。
LSTM变种-GRU

GRU 讲忘记和输入门组合成一个单一的“更新门”,并且单元格状态和隐藏状态合并,也进行了其他的修改,这种比标准的LSTM更简单,在使用上也受到许多人的选择。
其他信息
上面介绍了RNN,LSTM以及LSTM的变种等等,后面第二篇也会从李宏毅老师那边讲到的延伸做进一步探讨,RNN的BPTT算法,以及梯度弥散和梯度爆炸问题,也会加入注意力的机制和RNN的结合,最后一篇则是LSTM一个示例。