简介
编程语言离不开函数,函数是对一段代码的封装,往往实现了某个特定的功能,在程序中可以多次调用这个函数。稍有编程经验的同学都知道,函数是由栈实现的,调用对应入栈,退出对应出栈。在写递归函数的时候,如果递归层次太深会出现栈溢出(StackOverFlow)的错误。
"函数栈"包含了对函数调用的基本理解,但是从细节来看,还有很多疑问,例如:
- 函数的栈是如何开辟的?
- 如何传入参数?
- 返回值是如何得到的?
本文以 C 语言为例,从内存布局、汇编代码的角度来分析函数栈的实现原理。
Linux 进程内存布局
当程序被执行的时候,Linux 会为其在内存中分配相应的空间以支撑程序的运行,如下图所示。
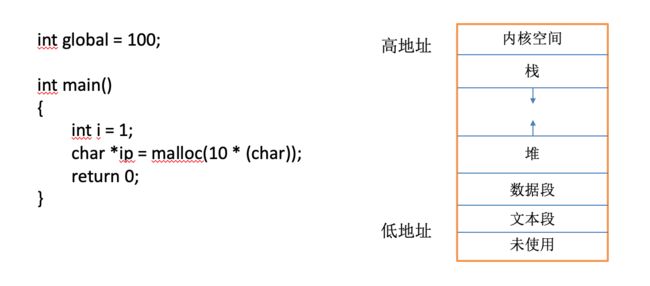
在虚拟内存中,内存空间被分为多个区域。代码指令保存在文本段,已初始化的全局变量 global 保存在数据段,程序运行中动态申请的内存malloc(10 * char())放在堆中,而函数执行的时候则在栈中开辟空间运行。例如main函数便占有一个函数栈,其中的变量i和ip都保存在main的栈空间中。
函数的栈空间有个名字叫做 栈帧,下面就具体了解一下栈帧。
栈帧
下图是栈的结构。图中右侧是栈空间,其中有多个栈帧。从上往下由较早的栈帧到较新的栈帧,由于栈是从高地址往低地址生长的,所以最新的栈永远在最下面,即栈顶。
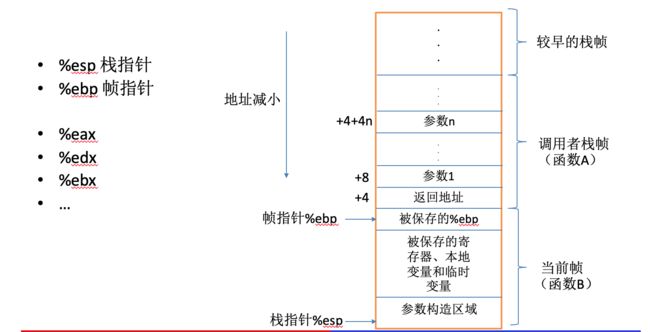
图中有两个画出了具体结构的栈帧,分别是函数 A 和函数 B。函数 A 的栈帧最上面有一块省略号标识的区域,其中保存的是上一个栈帧的寄存器值以及函数 A 自己内部创建的局部变量。下面的参数 n 到参数 1 则是函数 A 要传给函数 B 的调用参数。那么函数 B 如何获取?答案是用寄存器。
CPU 计算时会把很多变量放在寄存器中,根据硬件体系的不同,寄存器数量和作用也不同。一般在 x86 32位中,寄存器 %esp 保存了栈指针的值,也就是栈顶,而 %ebp 作为当前栈帧的帧指针,也就是当前栈帧的底部,所以通过 %esp 和 %ebp 就可以知道当前栈帧的头跟尾。除了这两个寄存器,还有其它一些通用寄存器(%eax、%edx等),用于保存程序执行的临时值。
了解了寄存器的基本知识后,下面我们就可以知道函数 B 如何获取到函数 A 传给它的参数了。参数 1 的地址是 %ebp + 8,参数 2 的地址是 %ebp + 12,参数 n 的地址是 %ebp + 4 + 4 * n。相信大家已经看明白,通过帧指针往上找就可以取得这些参数,而这些参数之所以在这里当然是函数 A 预先准备好的,关于这一点下文会有例子。
另外在所有参数的最下面保存着 返回地址,这个是在函数 B 返回之后接下来要执行的指令的地址。
看了函数 A 之后,再看看函数 B。在函数 B 的栈帧最上面是 被保存的 %ebp,这个指的是函数 A 的帧指针,毕竟 %ebp 这个寄存器就一个,所以新的函数入栈的时候要先把老的保存起来,等函数出栈再恢复。在这个老的帧指针下面则是其它需要保存的寄存器变量以及函数 B 自己内部用到的局部变量。再往下是 参数构造区域,也就是函数 B 即将调用另一个函数,在这里先把参数准备好。可以看出,函数 B 与函数 A 的栈帧结构是类似的。
了解了栈帧的理论之后,大家可能会觉得很抽象,下面结合具体实例来看栈帧从产生到消亡的过程。
函数调用实例
下面图是函数 caller 的具体执行过程,左边是 C 代码,中间是汇编码,右边是对应的栈帧。

我们一行一行的来分析,看中间汇编码,上面三行绿色的:
pushl %ebp // 保存旧的 %ebp
movl %esp, %ebp // 将 %ebp 设置为 %esp
subl $24, %esp // 将 %esp 减 24 开辟栈空间
这三行其实是为栈帧做准备工作。第一行保存旧的 %ebp,此时新的栈空间还没有创建,但保存旧的 %ebp 的这一行空间将作为新栈帧的栈底,也就是帧指针,因此第二行将栈指针 %esp(永远指向栈顶)的值设置到 %ebp 上。 第三行将 %esp 下移 24 个字节,这一行其实就是为函数 caller 开辟栈空间了。从图中可以看出,下面的空间用于保存 caller 中的变量以及传给下个函数的参数。有部分空间未使用,这个是为了地址对齐,不影响我们的分析,可以忽略。
在开辟了栈帧之后,就开始执行 caller 内部的逻辑了,caller 首先创建了两个局部变量(arg1和arg2)。对应的汇编代码为 movl $534, -4(%ebp); movl $1057, -8(%ebp),其中 -4(%ebp) 表示 %ebp - 4 的位置,也就是图中 arg1 所在的位置, arg2 的位置则是 %ebp - 8 的位置。这两行是把 534 和 1057 保存到传送到这两个位置上。
继续往下是这几行:
leal -8(%ebp), %eax // 把 %ebp - 8 这个地址保存到 %eax
movl %eax, 4(%esp) // 把 %eax 的值保存到 %esp + 4 这个位置上
leal -4(%ebp), %eax // 把 %ebp - 4 这个地址保存到 %eax
movl %eax, ($esp) // 把 %eax 的值保存到 %esp 这个位置上
第一行把 %ebp - 8 这个地址保存到 %eax 中,而 %ebp - 8 是 arg2 的地址,下一行把这个地址放到 %esp + 4 这个位置上,也就是图中 &arg2 的那个区域块。其实这一行是在为函数 swap_add 准备参数 &arg2,而下面两行则是准备参数 &arg1。
再下面一行是 call swap_add。这一行就是调用函数 swap_add 了,不过在这之前还需要把返回地址压到栈上,这里的返回地址是函数 swap_add 返回后要接着执行的代码的地址,也就是 int diff = arg1 - arg2 地址。
在调用 swap_add 后用到了其返回值 sum 继续进行计算,我们还不知道返回值是怎么拿到的。在这之前,我们先进入 swap_add 函数,下面是对应的代码执行图:

swap_add 对应的汇编代码的前三行与 caller 类似,同样是保存旧的帧指针,但是因为 swap_add 不需要保存额外的变量,只需要多用一个寄存器 %ebx,所以这里保存了这个寄存器的旧值,但是没有将 %esp 直接下移一段长度的操作。
接下来绿色的两行就是关键了:
movl 8(%ebp), %edx // 从 %ebp + 8 取值保存到 %edx
movl 12(%ebp), %ecx // 从 %ebp + 12 取值保存到 %ecx
这两行分别是从 caller 中保存参数 &arg1 和 &arg2 的地方取得地址值,并根据地址取得 arg1和arg2 的实际数值。
接下来的 4 行是交换操作,这里就不具体看每一行的逻辑了。
再下面一行 addl %ebx, %eax 是将返回值保存到寄存器 %eax 中,这里非常关键,函数 swap_add 的返回值保存在 %eax 中,一会儿 caller 就是从这个寄存器获取的。
swap_add 的最后几行是出栈操作,将 %ebx 和 %ebp 分别恢复为 caller 中的值。最后执行 ret 返回到 caller 中。
下面我们继续回到 caller 中,刚才执行到 call swap_add,下面几行是执行 int diff = arg1 - arg2,结果保存在 %edx 中。
最后一行是计算 sum * diff,对应的汇编代码为 imull %edx, %eax。这里是把 %edx 和 %eax 的值相乘并且把结果保存到 %eax 中。在上面的分析中,我们知道 %eax 保存着 swap_add 的返回值,这里还是从 %eax 中取出返回值进行计算,并且把结果继续保存到 %eax 中,而这个值又是 caller 的返回值,这样调用 caller 的函数也可以从这个寄存器中获取返回值了。
caller 函数的最后一行汇编代码是 ret,这会销毁 caller 的栈帧并且恢复相应寄存器的旧值。到此,caller 和 swap_add 这个函数的调用过程就全部分析完了。
总结
本文详细分析了函数调用过程中栈帧变化的过程,对于开头提出的几个疑问也都有了解答。函数栈的实现在常规的开发中几乎不会涉及到,但是学习其中的原理有利于更深入地理解内存以及编程语言的奥秘。
参考
- 《深入理解计算机系统》