第十章 Flink
1.Flink初识
1.1 数据处理架构的发展和演变
-
流处理和批处理
- 流处理对应实时计算
- 批处理对应离线计算
-
传统事务处理

传统的事务处理,就是最基本的流处理架构。
缺点:传统事务处理对表和数据库的设计要求很高;当数据规模越来越庞大、系统越来越复杂时,可能需要对表进行重构,而且一次联表查询也会花费大量的时间,甚至不能及时得到返回结果。于是,作为程序员就只好将更多的精力放在表的设计和重构,以及 SQL的调优上,而无法专注于业务逻辑的实现。
-
有状态的流处理
-
状态
当前计算流程需要依赖到之前计算的结果,那么之前计算的结果就是状态。
在传统的事务处理中我们把状态放在关系型数据库中,在
Flink中状态是保存在内存中。状态总是和算子关联。Flink状态
-
检查点(checkpoint)
因为采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们可以定期地将应用状态的一致性检查点( checkpoint)存盘,写入远程的持久化存储,遇到故障时再去读取进行恢复,这样就保证了更好的容错性。
-
有状态流解决的问题
- 优化查询时间
- 通过分布式系统,解决重构问题。
-
有状态流常见应用
-
事件驱动式应用
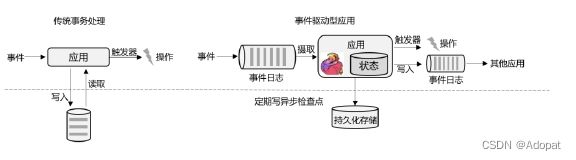
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 Kafka为代表的消息队列几乎都是事件驱动型应用。
-
数据分析型应用
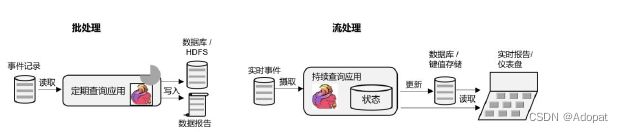
实时数仓
-
数据管道型应用

用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再去周期性触发,连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用。所以可以用
Flink搭建实时ETL工具。
-
-
-
Lambda架构-
概念
Lambda架构由Storm 的作者 [Nathan Marz] 提出, 根据维基百科的定义,Lambda 架构的设计是为了在处理大规模数据时,同时发挥流处理和批处理的优势。通过批处理提供全面、准确的数据,通过流处理提供低延迟的数据,从而达到平衡延迟、吞吐量和容错性的目的。为了满足下游的即席查询,批处理和流处理的结果会进行合并。
-
架构图

-
优缺点
优点:兼具了批处理器和第一代流处理器的特点,同时保证了低延迟和结果的准确性。
缺点:首先, Lambda架构本身就很难建立和维护;而且,它需要我们对一个应用程序,做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,它们的
API也完全不同。为了实现一个应用,付出了双倍的工作量,这对程序员显然不够友好。 -
参考资料
大数据架构之-- Lambda架构
-
-
新一代流处理器(
Flink)Flink称为第三代流处理器(为了和Lambda区分)
1.2 Flink是什么
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。

分布式处理引擎是为了处理大规模数据,无界对应的式流处理,有界对应的是批处理。内存执行速度,说明
Flink是一个基于内存的计算引擎,任意规模说明Flink可扩展性强。
1.3 Flink特点
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。
Flink提供了事件时间( event time)和处理时间 processing time语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。 - 精确一次( exactly once)的状态一致性保证。
- 可以连接到最常用的存储系统,如
Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis和(分布式)文件系统,如HDFS和S3。 - 高可用。本身高可用的设置,加上与
K8sYARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间 7××24全天候运行。 - 能够更新应用程序代码并将作业( jobs)迁移到不同的
Flink集群,而不会丢失应用程序的状态。
1.4 Flink应用场景
-
电商和市场营销
实时数据报表,广告投放,实时推荐
-
物联网(
IOT)举例:传感器实时数据采集和显示、实时报警,交通运输业
-
物流配送和服务业
举例:订单状态实时更新、通知信息推送
-
银行和金融业
举例:实时结算和通知推送,实时检测异常行为
1.5 Flink分层API
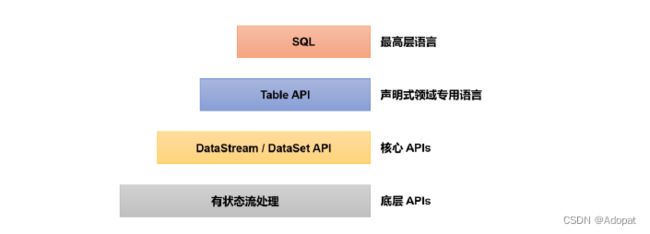
注意
DataSet作为批处理 API实际应用较少, 2020年 12月 8日发布的新版本 1.12.0, 已经完全实现了真正的流批一体,DataSet API已处于软性弃用( soft deprecated)的状态。用Data Stream API写好的一套代码 , 即可以处理流数据 , 也可以处理批数据,只需 要设置不同的执行模式。这与之前版本处理有界流的方式是不一样的。
1.6Flink和 Spark对比
离线批处理选用Spark,实时流处理选用Flink
2.Flink 快速入门
2.1 环境准备
- Windows 10
- 需提前安装 Java 8
- 集成开发环境(
IDE使用IntelliJ IDEA) - 安装
IntelliJ IDEA之后,还需要安装一些插件 Maven和 Git
2.2 创建项目
-
创建Maven项目(
FlinkTutorial)
-
添加项目依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId> <artifactId>FlinkTutorial</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> </properties> <build> <plugins> <!-- java编译插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- scala编译插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.1.6</version> <configuration> <scalaCompatVersion>2.11</scalaCompatVersion> <scalaVersion>2.11.12</scalaVersion> </configuration> <executions> <execution> <id>compile-scala</id> <phase>compile</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>test-compile-scala</id> <phase>test-compile</phase> <goals> <goal>add-source</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!-- 打包插件 --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <!-- 打包时指定main函数入口,可选--> <mainClass>com.atguigu.wc.StreamWordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> <dependencies> <!-- 引入 Flink 相关依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <!-- 打包时标注为provided,集群中存在此jar包,不需要打包--> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!-- <scope>provided</scope>--> </dependency> <!-- 引入日志管理相关依赖--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> <!-- <scope>provided</scope>--> </dependency> </dependencies> </project>pom.xml文件。 -
配置日志管理
log4j.rootLogger=error, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n在目录
src/main/resources下添加文件 :log4j.properties
2.3 编写代码
-
批处理代码
package com.atguigu.wc; /** * DataSet批处理 */ import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.AggregateOperator; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.operators.FlatMapOperator; import org.apache.flink.api.java.operators.UnsortedGrouping; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; public class BatchWordCount { public static void main(String[] args) throws Exception { // 1.创建执行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // 2.从文件中读取数据,按行读取 DataSource<String> lineDS = env.fromElements("hello you","hello me"); // 3.转换数据格式 FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> { String[] words = line.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1L)); } } ).returns(Types.TUPLE(Types.STRING, Types.LONG)); // 4.按照word进行分组 UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0); // 5.分组内聚合统计 AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1); // 6.打印结果 sum.print(); } } -
流处理代码1
package com.atguigu.wc; /** * 有界流处理 */ import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; public class BoundedStreamWordCount { public static void main(String[] args) throws Exception { // 1.创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.读取文件 DataStreamSource<String> lineDSS = env.readTextFile("input/words.txt"); // 3.转换数据格式 SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS .flatMap((String line, Collector<String> words) ->{ Arrays.stream(line.split(" ")).forEach(words::collect); }) .returns(Types.STRING) .map(word->Tuple2.of(word,1L)) .returns(Types.TUPLE(Types.STRING,Types.LONG)); // 4.分组 KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0); // 5.求和 SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1); // 6.打印 result.print(); // 7.执行 env.execute(); } } -
流处理代码2
package com.atguigu.wc; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class StreamWordCount { public static void main(String[] args) throws Exception { // 1.创建按执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.读物文本流 DataStreamSource<String> lineDSS = env.socketTextStream("172.18.22.23", 9999); // SingleOutputStreamOperator<String> words = lineDSS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { String[] words = value.split(" "); for (String word : words) { out.collect(word); } } }); // 将单词转为 (word,1) SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String value) throws Exception { return Tuple2.of(value, 1L); } }); // 按照单词分组 KeyedStream<Tuple2<String, Long>, String> keyByWord = wordAndOne.keyBy(new KeySelector<Tuple2<String, Long>, String>() { @Override public String getKey(Tuple2<String, Long> value) throws Exception { return value.f0; } }); // 同一个单词 数量相加 SingleOutputStreamOperator<Tuple2<String, Long>> wordCount = keyByWord.sum(1); // 打印结果 wordCount.print(); env.execute(); } }
2.4 将代码提交到集群
-
pom.xml文件设置<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId> <artifactId>FlinkTutorial</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> </properties> <build> <plugins> <!-- java编译插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- scala编译插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.1.6</version> <configuration> <scalaCompatVersion>2.11</scalaCompatVersion> <scalaVersion>2.11.12</scalaVersion> </configuration> <executions> <execution> <id>compile-scala</id> <phase>compile</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>test-compile-scala</id> <phase>test-compile</phase> <goals> <goal>add-source</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!-- 打包插件 --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <!-- 打包时指定main函数入口,可选--> <mainClass>com.atguigu.wc.StreamWordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> <dependencies> <!-- 引入 Flink 相关依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <!-- 打包时标注为provided,集群中存在此jar包,不需要打包--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!-- 引入日志管理相关依赖--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> <scope>provided</scope> </dependency> </dependencies> </project> -
执行打包命令
mvn clean package -DskipTests -
在
Flink WEBUI提交JAR包注意,出了在Flink WEBUI提交JAR包,也可以在命令行提交
$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.StreamWordCount ./FlinkTutorial 1.0 SNAPSHOT jar with dependencies.jar-m 指定了提交到的
JobManager,-c 指定了入口类(打包时指定了,就不需要填)flink run --help查看帮助 -
观察结果

3 .Flink集群部署
3.1 集群环境准备
- 准备三台服务器,系统版本为centos7.9
- 安装Java8
- 安装Hdoop集群,Hadoop版本3.0以上
- 配置集群节点服务器间的时钟同步以及免密登录,关闭防火墙
3.2 Flink Standalone集群安装和部署
Flink Standalone集群安装和部署
3.3 Flink on Yarn 部署Session-Cluster和Per-Job-Cluster
Flink on Yarn 部署Session-Cluster和Per-Job-Cluster
3.4 Flink服务的HA配置
Flink服务的HA配置
4. Flink 运行时架构
4.1 Flink作业提交流程
-
抽象提交流程

(1 一般情况下,由客户端( App)通过分发器提供的 REST接口,将作业提交给JobManager。
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster将JobGraph解析为可执行的ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源( slots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5 )TaskManager启动之后,向ResourceManager注册自己的可用任务槽( slots)。
(6)资源管理器通知 TaskManager为新的作业提供 slots。
(7)TaskManager连接到对应的对应的JobMaster,提供slots。。
(8)JobMaster将需要执行的任务分发TaskManager。
(9)TaskManager执行任务,互相之间可以交换数据。注意Flink提交流程会因为部署模式,存在一些差异。
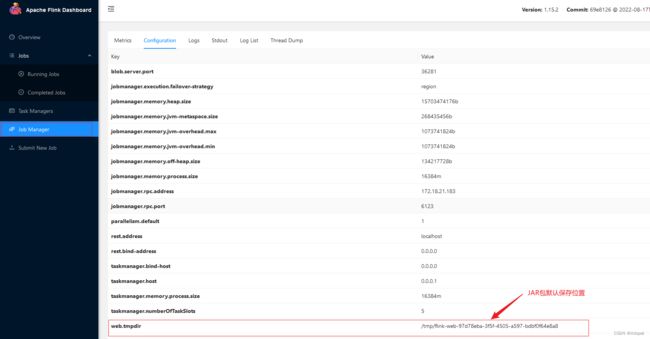
4.2 Flink作业提交保存位置
Flink 提交的JAR包保存在web.tmpdir,如果在配置文件中没有指明web.tmpdir路径,由 java.io.tmpdir + “flink-web-” + UUID 组成的!可以在web ui 上查看这个路径。你上传的 jar 包藏到哪里去了?
4.3 Flink常见名词解释
4.31 算子
-
概念
在Flink中我们把对流的处理转换操作叫做算子。
-
分类
根据Flink程序由三部分组成(Source,Transformation,Sink),分为三类
-
源算子(Source)
负责读取数据源
-
转换算子(Transformation)
利用各种算子进行处理加工
-
下沉算子(Sink)
负责数据的输出
-
-
怎么判断方法是不是一个算子
-
算子一定是一个转换处理的操作
-
看方法的返回值,如果方法的返回类型为
SingleOutputStreamOperator,说明这是一个算子操作如
keyBy之后的返回数据类型是KeyedStream,则说明keyBy不是算子操作
-
-
算子链
-
算子间的数据传输
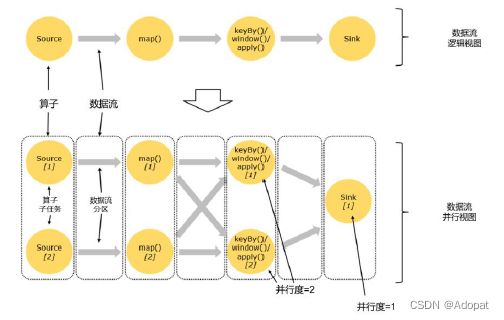
一对一模式:
这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和 map算子, source算子读取数据之后,可以直接发送给 map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着 “一对一 ”的关系。 map、 filter、 flatMap等算子都是这种 one to one的对应关系。这种算子关系类似于Spark中的窄依赖。
重分区模式:
在这种模式下,数据流的分区会发生改变。比图中的 map和后面的 keyBy/window算子之间(这里的 keyBy是数据传输算子,后面的 window、 apply方法共同构成了 window算子) ),以及 keyBy/window算子和 Sink算子之间,都是这样的关系。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键( key)的哈希值 hashCode)进行了重分区;而当并行度
改变时,比如从并行度为 2的 window算子,要传递到并行度为 1的 Sink算子,这时 的数据传输方式是再平衡( rebalance),会把数据均匀地向下游子任务分发出去。这些传输方式都会引起重分区( redistribute)的过程,这一过程类似于 Spark中的 shuffle。总体说来,这种算子间的关系类似于 Spark中的宽依赖。 -
合并算子链
在Flink中,并行度相同的一对一( one to one)算子操作,可以直接链接在一起形成一个“大”的任务 task),这样原来的算子就成为了真正任务里的一部分,这样的技术被称为算子链。

-
算子链作用
将算子链接成 task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
-
算子链设置
// 禁用算子链 map(word --> Tuple2.of(word, 1L)).disableChaining() // 从当前算子开始新链 map(word --> Tuple2.of(word, 1L)).startNewChain()Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置。
-
4.32 并行度
-
并行概念
在
Flink中并行指的是数据并行,而是算子并行,我们把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多 个 并行的“子任务 subtasks),再将它们分发到不同节点,就真正实现了并行计算。在
Flink执行过程中,每一个算子( operator)可以包含一个或多个子任务 operator subtask这些子任务在不 同的线程、不同的物理机或不同的容器中完全独立地执行。 -
并行子任务数和并行度区别

当前数据流中有 source、 map、 window、 sink四个算子,除最后 sink,其他算子的并行度都为 2。整个程序包含了 7个子任务,至少需要 2个分区来并行执行。我们可以说,这段流处理程序的并行度就是 2。注意作业,任务,任务节点,分区,并行度区别。
-
如何设置并行
-
代码中设置算子并行
stream.map(word --> Tuple2.of(word, 1L)).setParallelism(2); -
设置全局并行(不推荐,无法动态扩容)
env.setParallelism(2); -
提交时设置并行
bin/flink run p 2 c com.atguigu.wc .StreamWordCount ./FlinkTutorial 1.0 SNAPSHOT.jar -
配置文件设置
// 在flink-conf.yaml中设置 parallelism.default: 2 -
设置并行度优先级
代码中设置>全局设置>提交时设置>配置文件设置
注意对于非并行算子,无论怎么设置,并行度都是一,如读取 socket文本流的算子
socketTextStream注意在代码中只针对算子设置并行度,不设置全局并行度,方便在提交作业时进行动态扩容。一般推荐在提交作业时指定参数。
-
4.33 Flink调度中生成的图
-
生成图顺序
逻辑流图(
StreamGraph)----> 作业图(JobGraph)----> 执行图(ExecutionGraph)---->物理图(Physical Graph)逻辑流图也被称为 数据流图(
Dataflow Graph) -
逻辑流图(
StreamGraph)这是根据用户通过
DataStream API编写的代码生成的最初的 DAG图,用来表示程序的拓扑结构。这一步一般在客户端完成。我们可以看到,逻辑流图中的节点,完全对应着代码中的四步算子操作:源算子Source →扁平映射算子 →分组聚合算子Keyed →输出算子。
-
作业图(
JobGraph)StreamGraph经过优化后生成的就是作业图(JobGraph),这 是提交给JobManager的数据结构,确定了当前作业中所有任务的划分。主要的优化为 : 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。分组聚合算子( Keyed Aggregation)和输出算子 Sink(print)并行度都为 2而且是一对一的关系,满足算子链的要求,所以会合并在一起,成为一个任务节点。
-
执行图(
ExecutionGraph)JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。从图中可以看到,与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
-
物理图(
Physical Graph)JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。从图中可以看到,与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。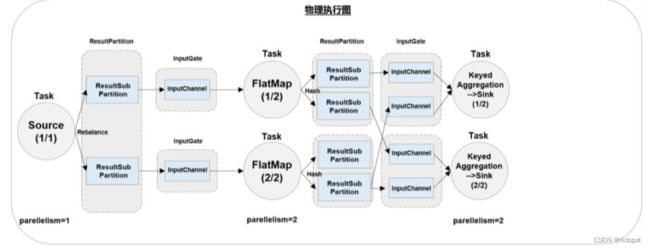
4.34 Task 和 Task Slots
-
任务槽(Task Slots)
在
TaskManager上设置"卡槽",将任务分配到卡槽中就可以并行执行任务。Task slot 是静态的概念,指的是TaskManager具有的并发执行能力。
每个任务槽(task slot)其实表示了 TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
假如一个TaskManager有三个 slot,那么它会将管理的内存平均分成三份,每个 slot独自占据一份。这样一来,我们在 slot上执行一个子任务时,相当于划定了一块内存 “专款专用,就不需要跟来自其他作业的任务去竞争内存资源了。所以现在我们只要2个个TaskManager,就可以并行处理分配好的可以并行处理分配好的5个任务了。
-
任务槽数量的设置
// 在flink-conf.yaml中设置 taskmanager.numberOfTaskSlots: 8 -
任务对任务槽的共享
只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个 slot上执行。

默认情况下,Flink 允许子任务共享slot,即使他们是不同任务的子任务。这样的结果就是一个slot可以保存作业的整个pipeline。
从图中可以看出来,第一个slot会运行3个subtask,也就是执行3个线程,由于slot只是做了内存隔离,并没有做CPU隔离,假设这样一种情况,我们的服务器是6核CPU的,也就是意味着每个slot就可以分到一个CPU资源,那么就意味着这3个子任务中,一个子任务执行时就有2个子任务在等待状态,所以我们在设置slot个数时,也要考虑一下集群的资源,尽量使得每个slot能使用得到合理的CPU资源。
-
任务槽和并行度关系
并行度如果小于等于集群中可用 slot的总数,程序是可以正常执行的,因为 slot不一定要全部占用,有 十分力气可以只用八分;而如果并行度大于可用 slot总数,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。(从图中我们可以看出,同一任务节点如Source map 是按照并行数逐一在Slots中展开,所以并行数不能大于Slots数)
-
任务槽设置建议
建议设置CPU核数,所以我们可以得出 并行度<=Slots
5. DataStream API基础篇
5.1 执行环境
5.1.1 创建执行环境方法
-
getExecutionEnvironment(推荐使用)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();最简单的方式,就是直接调用
getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境 。这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式。 -
createLocalEnvironmentLocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(2);这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU核心数。
-
createRemoteEnvironmentStreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment. createRemoteEnvironment( "host", // JobManager 主机名 1234, // JobManager 进程端口号 提交给 JobManager 的 JAR 包 "path/to/jarFile. " );这个方法返回集群执行环境。需要在调用时指定
JobManager的 主机名 和端口号,并指定要在集群中运行的 Jar包。在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。关于时间语义和容错。
5.1.2 执行模式
-
流执行模式(STREAMING)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();默认情况下就是流执行模式
-
批执行模式(BATCH)
-
通过命令行提交时设置
bin/flink run -Dexecution.runtime-mode=BATCH -
通过代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH); -
什么时候选用BATCH模式
用BATCH模式处理批量数据,用 STREAMING模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候 , 我们没得选择 只有 STREAMING模式才能处理持续的数据流。
-
在Flink1.12前设置批处理模式方法
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();在
Flink1.12后实现了流批一体,
-
-
自动模式(AUTOMATIC)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); -
执行模式总结
当然所有的执行模式都可以在配置文件(
flink-conf.yaml)中指定execution.runtime-mode指定,注意在Flink1.12实现了流批一体,推荐在命令行提交时设置执行模式为BATCH
5.1.3 触发程序执行
Flink是由事件驱动的,只有等到数据到来,才会触发真正 的计算,这也被称为“延迟执行”或“懒执行”( lazyexecution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。 execute()方法将一直等待作业完成,然后返回一个执行结果( JobExecutionResult)。
env.execute();
5.2 数据源(Source)
5.2.1 准备一个POJO对象
-
具体代码如下
package com.atguigu.source; public class Event { public String user; public String url; public Long timestamp; @Override public String toString() { return "Event{" + "user='" + user + '\'' + ", url='" + url + '\'' + ", timestamp=" + timestamp + '}'; } public Event() { } public Event(String user, String url, Long timestamp) { this.user = user; this.url = url; this.timestamp = timestamp; } public String getUser() { return user; } public void setUser(String user) { this.user = user; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public Long getTimestamp() { return timestamp; } public void setTimestamp(Long timestamp) { this.timestamp = timestamp; } }POJO数据类型指的是一个简单的Java对象,具有以下特点
- 类时公有的(public)
- 有一个无参的构造方法
- 所有属性都是公有的(public)
- 所有属性的类型都是可以序列化的
注意上面代码中的getter setter 方法不是必须的。
5.2.2 从集合中读取数据
-
具体代码
package com.atguigu.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * 从集合中读取数据 */ public class FromCollection { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<Event> clicks = new ArrayList<>(); clicks.add(new Event("Mary","./home",1000L)); clicks.add(new Event("Bob","./cart",2000L)); DataStreamSource<Event> stream = env.fromCollection(clicks); stream.print(); env.execute(); } }
5.2.3 从文件中读取数据
-
读取本地文件
package com.atguigu.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 从文件中读取数据 */ public class FromTextFile { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> stream = env.readTextFile("input/words.txt"); stream.print(); env.execute(); } }readTextFile()参数可以时目录或者文件,路径可以时相对路径也可以是绝对路径
相对路径是从系统属性
user.dir获取路径 : idea下是 project的根目录 , standalone模式下是集群节点根目录;# 获取路径 String property = System.getProperty("user.dir"); System.out.println(property); -
读取
HDFS文件package com.atguigu.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 从HDFS文件中读取 */ public class FromHDFSFile { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSourcestream = env.readTextFile("hdfs://bigdata01:9000/hello.txt"); stream.print(); env.execute(); } } 由于Flink没有提供hadoop相关依赖,需要在pom文件中增加依赖
<!-- 增加hadoop相关依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.2.0</version> <!-- <scope>provided</scope>--> </dependency>
5.2.4 从Socket中读取数据
-
具体代码
package com.atguigu.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 从Socket中读取数据 */ public class FromSocket { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> stream = env.socketTextStream("172.18.22.23", 9999); stream.print(); env.execute(); } }linux服务器上开启nc命令nc -l 9999Linux命令之nc命令
Windows下使用nc命令
5.2.5 从Kafka中读取数据
-
具体代码
package com.atguigu.source; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import java.util.Properties; /** * 从Kafka中读取数据 */ public class FromKafka { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "172.18.22.23:9092"); properties.setProperty("group.id", "consumer group"); properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization"); properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization"); properties.setProperty("auto.offset.reset", "latest"); DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>( "clicks", // 将字节数组反序列化字符串 new SimpleStringSchema(), // 设置客户端的属性 properties )); stream.print(); env.execute(); } }Flink内部没有提供读取Kafka的预实现,需要添加依赖
<!-- 增加官方提供的kafka连接工具--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency>
5.2.5 从自定义Source中读取数据
-
实现
SourceFunction<>package com.atguigu.source; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.util.Calendar; import java.util.Random; /** * ClickSource */ public class ClickSource implements SourceFunction<Event> { // 声明一个布尔变量,作为控制数据生成的标识位 private Boolean running = true; @Override // 重写 run()方法,使用运行时上下文对象(SourceContext)向下游发送数据 public void run(SourceContext<Event> ctx) throws Exception { Random random = new Random(); String[] users = {"Mary","Alice","Bob","Cary"}; String[] urls = {"./home","./cart","./fav","./prod?id=1","./prod?id=2"}; while (running){ ctx.collect(new Event( users[random.nextInt(users.length)], urls[random.nextInt(urls.length)], Calendar.getInstance().getTimeInMillis() )); // 每隔一秒生成一个点击事件,方便观测 Thread.sleep(1000); } } @Override public void cancel() { running=false; } }package com.atguigu.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 自定义Source 并行度为1 * public class ClickSource implements SourceFunction* 只能设置并行度为1 */ public class SourceCustom { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 调用自定义Source DataStreamSource<Event> stream = env.addSource(new ClickSource()); // 只能设置并行度为1 //DataStreamSourcestream = env.addSource(new ClickSource()).setParallelism(2); stream.print("SourceCustom"); env.execute(); } }这里要注意的是
SourceFunction接口定义的数据源,并行度只能设置为 1,如果数据源设置为大于 1的并行度,则会抛出异常。 -
实现
ParallelSourceFunctionpackage com.atguigu.source; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction; import java.util.Calendar; import java.util.Random; /** * 自定义Source 并行度不为1 */ public class ParalleSourceCustom { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.addSource(new CustomerSource()).setParallelism(2).print(); env.execute(); } public static class CustomerSource implements ParallelSourceFunction<Event> { // 声明一个布尔变量,作为控制数据生成的标识位 private boolean running = true; private Random random = new Random(); String[] users = {"Mary","Alice","Bob","Cary"}; String[] urls = {"./home","./cart","./fav","./prod?id=1","./prod?id=2"}; @Override public void run(SourceContext<Event> ctx) throws Exception { while(running){ ctx.collect(new Event( users[random.nextInt(users.length)], urls[random.nextInt(urls.length)], Calendar.getInstance().getTimeInMillis() )); } Thread.sleep(1000); } @Override public void cancel() { running=false; } } }
5.2.6 Flink支持的数据类型
Apache Flink——Flink 支持的数据类型
5.3 转换操作
5.3.1 基本转换算子
-
map
-
概念
map主要用于将数据流中的数据进行一一映射,形成新的数据流。

-
实现代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * map 方法实现 MapFunction方法 */ public class MapDemo { public static void main(String[] args) throws Exception { // 1.获取 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置全局并行度 env.setParallelism(1); ArrayList<Event> array = new ArrayList<>(); array.add(new Event("Mary","./hone",1000L)); array.add(new Event("Bob","./home",2000L)); DataStreamSource<Event> stream = env.fromCollection(array); // 方法一 使用 匿名内部类,传入MapFunction接口的实现类 SingleOutputStreamOperator<String> map = stream.map(new MapFunction<Event, String>() { @Override public String map(Event value) throws Exception { return value.user; } }); // map.print(); System.out.println("======================="); // 方法二 传入 MapFunction的实现类 stream.map(new UserExtraction()).print(); env.execute(); } public static class UserExtraction implements MapFunction<Event,String>{ @Override public String map(Event value) throws Exception { return value.user; } } }
-
-
filter
-
概念
对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true则元素正常输出,若为 false则元素被过滤掉。

-
实现代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * Filter */ public class FilterDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据 DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./hone", 1000L), new Event("Bob", "./home", 2000L)); // 4.匿名函数实现 filter SingleOutputStreamOperator<Event> filter = stream.filter(new FilterFunction<Event>() { @Override public boolean filter(Event value) throws Exception { return value.user.equals("Mary"); } }); // filter.print(); stream.filter(new FilterUser()).print(); env.execute(); } public static class FilterUser implements FilterFunction<Event>{ @Override public boolean filter(Event value) throws Exception { return value.user.equals("Bob"); } } }
-
-
flatMap
-
概念
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0到多个元素。 flatMap可以认为是“扁平化”( flatten和“映射”( map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。

-
实现代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * FlatMapDemo * Collector作为收集器,用来指定输出结果 * 如果需要多次输出,只需指定collect方法就可以 */ public class FlatMapDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./hour", 2000L) ); // 4.调用重写的FlatMap方法 SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = stream.flatMap(new FlatMapFunction<Event, String>() { @Override public void flatMap(Event value, Collector<String> out) throws Exception { if ("Bob".equals(value.user)) { out.collect(value.user); } else if ("Mary".equals(value.user)) { out.collect(value.user); out.collect(value.url); } } }); stringSingleOutputStreamOperator.print(); env.execute(); } }
-
5.3.2 聚合算子
-
keyBy
-
概念
keyBy是聚合前必须使用的一个算子,通过指定键,),可以将一条流从逻辑上划分成不同的分区( partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽( task slot)。

-
实现代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * keyby 选择器 * */ public class KeyByDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 2.读取数据 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./hour", 2000L) ); // 使用lambda 实现 key选择器 KeyedStream<Event, String> eventStringKeyedStream = stream.keyBy(e -> e.user); // 使用匿名内部类实现 key选择器 KeyedStream<Event, String> eventStringKeyedStream1 = stream.keyBy(new KeySelector<Event, String>() { @Override public String getKey(Event value) throws Exception { return value.user; } }); // eventStringKeyedStream.print(); eventStringKeyedStream1.print(); env.execute(); } }注意keyBy并不是转换算子,keyBy得到的结果将不再是 DataStream,而是会将 DataStream转换为KeyedStream。 KeyedStream可以认为是“分区流”或者“键控流”,它是对 DataStream按照key的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定 key的类型。
-
-
简单聚合
-
实现代码
package com.atguigu.tramsform; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 简单聚合函数 * sum * max * min * maxBy * minBy * min 和 minBy 都会返回整个元素,只是 min 会根据用户指定的字段取最小值,并且把这个值保存在对应的位置,而对于其他的字段,并不能保证其数值正确 */ public class SimpleAggDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.获取数据流 DataStreamSource<Tuple3<Integer, Integer, Integer>> stream = env.fromElements( Tuple3.of(0, 1, 0), Tuple3.of(0, 1, 1), Tuple3.of(0, 2, 2), Tuple3.of(0, 1, 3), Tuple3.of(1, 2, 5), Tuple3.of(1, 2, 9), Tuple3.of(1, 2, 11), Tuple3.of(1, 2, 13), Tuple3.of(2, 1, 1), Tuple3.of(2, 1, 2), Tuple3.of(2, 2, 2), Tuple3.of(2, 1, 4), Tuple3.of(2, 1, 5) ); // stream.keyBy(r -> r.f0).sum(2).print(); // stream.keyBy(r -> r.f0).sum("f2").print(); // stream.keyBy(r -> r.f0).max(2).print(); // stream.keyBy(r -> r.f0).max("f2").print(); // stream.keyBy(r -> r.f0).min(2).print(); // stream.keyBy(r -> r.f0).min("f2").print(); // stream.keyBy(r -> r.f0).maxBy(2).print(); // stream.keyBy(r -> r.f0).maxBy("f2").print(); // stream.keyBy(r -> r.f0).minBy(2).print(); // stream.keyBy(r -> r.f0).minBy("f2").print(); env.execute(); } }
-
-
规约聚合(reduce)
-
概念
reduce可以对已有的数据进行规约处理,数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做 一个聚合计算。 -
实现代码
package com.atguigu.tramsform; import com.atguigu.source.ClickSource; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * reduce 规约聚合 */ public class ReduceDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // env.addSource(new ClickSource()) .map(new MapFunction<Event, Tuple2<String,Long>>() { @Override // 将Event数据转换为元组类型 public Tuple2 map(Event value) throws Exception { return Tuple2.of(value.user,1L); } }) // 使用用户名进行分组 .keyBy(r->r.f0) .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { // 使用reduce 算子实现sum功能,每到一条数据,用户pv的统计值加1 return Tuple2.of(value1.f0,value1.f1+value2.f1); } }) .keyBy(r->true) .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { /// 将累加器更新为当前最大的 pv 统计值,然后向下游发送累加器的值,使用reduce 算子实现maxBy() 功能 return value1.f1 > value2.f1 ? value1:value2; } }) .print(); env.execute(); } }reduce同简单聚合算子一样,也要针对每一个 key保存状态。因为状态不会清空,所以我们需要将 reduce算子作用在一个有限 key的流上。
-
5.3.3 用户自定义函数(UDF)
-
函数类/匿名函数
-
概念
对于大部分操作而言,都需要传入一个用户自定义函数(UDF),实现相关操作的接口来完成处理逻辑的定义。 Flink暴露了所有 UDF函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、 FilterFunction、ReduceFunction等。所以最简单直接的方式,就是自定义一个函数类,实现对应的接口。
-
实现代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 使用UDF 实现Filter */ public class FunctionUDFTest { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "/.home", 1000L), new Event("Bob", "/.hurry", 1000L) ); // 4.匿名内部类实现filter SingleOutputStreamOperator<Event> streamFilter = stream.filter(new FilterFunction<Event>() { @Override public boolean filter(Event value) throws Exception { return value.user.equals("Bob"); } }); // streamFilter.print(); // 方法二 // stream.filter(new Filter()).print(); // 方法三 使用 lambda stream.filter((FilterFunction<Event>) value -> value.user.equals("Mary")).print(); env.execute(); } // 方法二使用 方法实现类 public static class Filter implements FilterFunction<Event>{ @Override public boolean filter(Event value) throws Exception { return value.url.contains("home"); } } }
-
-
富函数类
-
概念
“富函数类”也是DataStream API提供的一个函数类的接口,所有的 Flink函数类都有其Rich版本。富函数类一般以抽象类的形式出现的。例如: RichMapFunction、 RichFilterFunction、RichReduceFunction等。既然“富”,那么它一定会比常规的函数类提供更多、更丰富的功能。与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
-
Rich Function的生命周期
-
open
Rich Function的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前, open()会首先被调用。所以像文件 IO的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。。
-
close
是生命周期中的最后一个 调用的方法,类似于解构方法。一般用来做一些清理工作。
-
-
代码
package com.atguigu.tramsform; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 富函数类 * */ public class RichFunctionDemo { public static void main(String[] args) throws Exception { // 1. 获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3. 读取数据 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cat", 2000L), new Event("Alice", "./dog", 5 * 1000L), new Event("Cary", "./monkey", 60 * 1000L) ); stream.map(new RichMapFunction<Event, Long>() { @Override public void open(Configuration parameters) throws Exception { super.open(parameters); System.out.println("索引为 "+getRuntimeContext().getIndexOfThisSubtask()+" 的任务开始"); } @Override public Long map(Event value) throws Exception { return value.timestamp; } @Override public void close() throws Exception { super.close(); System.out.println("索引为 "+getRuntimeContext().getIndexOfThisSubtask()+" 的任务结束"); } }).print(); env.execute(); } } -
富函数常见应用场景
public class MyFlatMap extends RichFlatMapFunction<IN, OUT>{ @Override public void open(Configuration configuration) { // 做一些初始化工作 // 例如建立一个和 MySQL 的连接 } @Override public void flatMap(IN in, Collector<OUT out) { /// 对数据库进行读写 } @Override public void close() { // 清理工作,关闭和 MySQL 数据库的连接。 } }一个常见的应用场景就是,如果我们希望连接到一个外部数据库进行读写操作,那么将连接操作放在 map()中显然不是个好选择 因为每来一条数据就会重新连接一次数据库;所以我们可以在 open()中建立连接,在 map()中读写数据,而在 close()中关闭连接。
-
5.3.4 物理分区
常见的物理分区包括:随机分区,轮询分区,重缩放分区,广播。
-
随机分区
-
概念
最简单的重分区方式就是直接“洗牌”。通过调用DataStream的 .shuffle()方法,将数据随机地分配到下游算子的并行任务中去。随机分区服从均匀分(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,因为是完全随机的,所以对于同样的输入数据 , 每次执
行得到的结果也不会相同。 -
图解
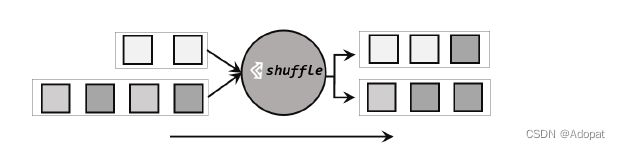
-
代码实现
package com.atguigu.tramsform; import com.atguigu.source.ClickSource; import com.atguigu.source.Event; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 物理分区--shuffle(随机分区) */ public class ShuffleDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据 DataStreamSource<Event> stream = env.addSource(new ClickSource()); // 4.执行shuffle操作设置并行度 stream.shuffle().print("shuffle").setParallelism(4); env.execute(); } }
-
-
轮询分区
-
概念
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发,通过调用 DataStream的 .rebalance()方法,就可以实现轮询重分区。 rebalance使用的是 Round Robin负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
-
图解

-
代码实现
package com.atguigu.tramsform; import com.atguigu.source.ClickSource; import com.atguigu.source.Event; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 物理分区--轮询分区(rebalance) */ public class RebalanceDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.addSource(new ClickSource()); stream.rebalance().print("rebalance").setParallelism(4); env.execute(); } }
-
-
重缩放分区
-
概念
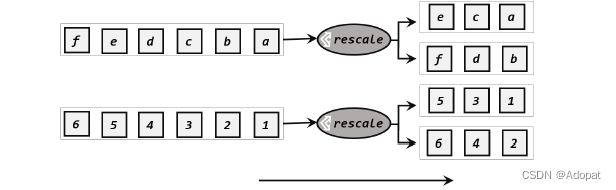
重缩放分区和轮询分区非常相似。当调用rescale()方法时,其实底层也 是使用 Round Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,也就是说,“发牌人”如果有多个,那么 rebalance的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
-
图解
-
代码实现
package com.atguigu.tramsform; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; /** * 重新缩放分区--rescale */ public class RescaleDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 设置并行数据源 env.addSource(new RichParallelSourceFunction<Integer>() { @Override public void run(SourceContext<Integer> ctx) throws Exception { for (int i = 0; i < 24; i++) { if((i+1)%2== getRuntimeContext().getIndexOfThisSubtask()){ ctx.collect(i+1); } } } @Override public void cancel() { } }) .setParallelism(2) .rescale() .print().setParallelism(6); env.execute(); } }
-
-
广播
-
概念
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
-
图解
-
代码实现
package com.atguigu.tramsform; import com.atguigu.source.ClickSource; import com.atguigu.source.Event; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 广播 */ public class BroadCastDemo { public static void main(String[] args) throws Exception { // 1.创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据源 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Mary1", "./home", 1000L), new Event("Mary2", "./home", 1000L), new Event("Mary3", "./home", 1000L) ); // 经广播发送到下游算子 设置并行度为4 stream.broadcast().print().setParallelism(4); env.execute(); } }
-
-
全局分区
-
概念
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
-
代码实现
-
-
自定义分区
-
概念
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与 keyBy指定 key基本一样:可以通过字段名称指定,也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
-
代码实现
package com.atguigu.tramsform; import org.apache.flink.api.common.functions.Partitioner; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 自定义分区 */ public class CustomPartitionDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 将自然数按照奇偶分区 env.fromElements(1,3,5,7,9,2,4,6,8,10) .partitionCustom(new Partitioner<Integer>() { @Override public int partition(Integer key, int numPartitions) { return key % 2; } }, new KeySelector<Integer, Integer>() { @Override public Integer getKey(Integer value) throws Exception { return value; } }) .print().setParallelism(2); env.execute(); } }
-
5.4 输出
-
输出到文件
-
代码实现
package com.atguigu.sink; import com.atguigu.source.Event; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.util.concurrent.TimeUnit; /** * 输出到文件 * 行编码 * 批量编码 */ public class SinkFileDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.读取数据 DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Mary1", "./home", 1000L), new Event("Mary2", "./home", 1000L), new Event("Mary3", "./home", 1000L), new Event("Mary4", "./home", 1000L), new Event("Mary5", "./home", 1000L), new Event("Mary6", "./home", 1000L), new Event("Mary7", "./home", 1000L), new Event("Mary8", "./home", 1000L) ); StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"), new SimpleStringEncoder<>("UTF-8")) // withRollingPolicy 指定滚动策略 .withRollingPolicy( DefaultRollingPolicy.builder() // 至少包含15分钟数据 .withRolloverInterval(TimeUnit.MINUTES.toMinutes(15)) // 最近5分钟没有收到新的数据 .withInactivityInterval(TimeUnit.MINUTES.toMinutes(5)) // 文件大小达到1GB .withMaxPartSize(1024 * 1024 * 1024) .build()) .build(); // 将Event 转换为String 写入文件 // stream.map(Event::toString).addSink(fileSink);// 方法引用 语法糖 类的实例方法引用 stream.map(new MapFunction<Event, String>() { @Override public String map(Event value) throws Exception { return value.toString(); } }).addSink(fileSink); env.execute(); } }
-
-
输出到Kafka
-
增加依赖
<!-- 增加官方提供的kafka连接工具--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.12</artifactId> <version>1.13.0</version> </dependency> -
代码实现
package com.atguigu.sink; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import java.util.Properties; /** * 输出到Kafka */ public class SinkToKafkaDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度 env.setParallelism(1); // 3.设置属性 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "172.18.22.23:9092"); // 4.读取文件 DataStreamSource<String> stream = env.readTextFile("input/words.txt"); // 5.输出到Kafka stream.addSink(new FlinkKafkaProducer<String>( "clicks", new SimpleStringSchema(), properties )); env.execute(); } }
-
-
输出到Redis
-
输出到Elasticsearch
-
输出到 MySQL JDBC
-
增加依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!-- 添加mysql依赖--> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>8.0.31</version> </dependency> -
代码实现
package com.atguigu.sink; import com.atguigu.source.Event; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.jdbc.JdbcSink; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 输出到对应数据库 */ public class SinkToMysqlDemo { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度 env.setParallelism(1); DataStreamSource<Event> stream = env.fromElements( new Event("Mary1", "./home", 1000L), new Event("Mary2", "./home", 1000L), new Event("Mary3", "./home", 1000L), new Event("Mary4", "./home", 1000L), new Event("Mary5", "./home", 1000L) ); stream.addSink(JdbcSink.sink("insert into clicks values(?,?)", (preparedStatement, event) -> { preparedStatement.setString(1,event.user); preparedStatement.setString(2,event.url); }, JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://localhost:3306/flincdc") .withDriverName("com.mysql.cj.jdbc.Driver") .withUsername("root") .withPassword("root") .build() ) ); env.execute(); } }
-
-
自定义Sink输出
6. Flink中的时间语义和窗口
6.1 时间语义
-
事件时间
事件时间指的是数据产生的时间。数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“ 时间戳”( Timestamp)。
在Flink中,由于处理时间比较简单,早期版本默认的时间语义是处理时间;而考虑到事件时间在实际应用中更为广泛,从 1.12版本 开始 Flink已经将 事件时间作为了默认的时间语义。
-
处理时间
处理时间指的是执行处理操作的机器的系统时间。
6.2 水位线
-
概念
在 Flink中,这种用来衡量事件时间( Event Time)进展的标记,就被称作“水位线 Watermark)。
-
特性
- 水位线是插入到数据流中的一个标记, 可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以通过设置延迟,来保证正确处理乱序数据
- 一个水位线 Watermark( 表示在当前流中事件时间已经达到了时间戳 t, 这代表 t之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t的数据
-
水位线生成策略
-
水位线默认计算公式
水位线 = 观察到的最大事件时间 - 最大延迟时间 - 1毫秒。
6.3 窗口
-
概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是 将无限数据切割成有限的 “数据块 ”进行处理,这就是所谓的 “窗口 Window)。
-
分类
-
按照驱动类型分类
时间窗口,计数窗口
-
按照窗口分配数据的规则分类
滚动窗口,滑动窗口,会话窗口,全局窗口
-
-
窗口函数
7. Flink处理函数
7.1 基本处理函数
7.2 按键分区处理函数
7.3 窗口处理函数
7.4 侧输出流
8. 多流转换
8.1 分流
8.2 基本合流操作
8.3 基于时间的合流
9. 状态编程
9.1 Flink中的状态
9.2 按键分区状态
9.3 算子状态
9.4 广播状态
9.5 状态持久化和状态后端
10. 容错机制
10.1 检查点(Checkpoint)
10.2 状态一致性
10.3 端到端精确一次
11. Table API和SQL
Flink 官方文档
12. Flink CEP
Flink的复杂事件处理机制CEP
13. Flink工具库CDC
debezium文档
FlinkCDC文档
14. Flink性能与监控
基于 Flink 的实时监控告警系统