ProtoBuf
文章目录
- 1.认识 ProtoBuf
- 2. 安装ProtoBuf
- 3. 快速上手 ProtoBuf
- 4. proto3 语法
- 5. probuf 实战
- 6. 总结
1.认识 ProtoBuf
在认识 啥是 ProtoBuf 之前我们先来 回顾一下 (或 了解 一下 啥是 序列化)
序列化概念回顾 :
图一 :

回顾 序列化 ,下面提出一个问题 如何来实现序列化
答 : XML , JSON , ProtoBuf 等.
通过 如何 实现序列化 就引出了 ProtoBuf , 关于 ProtoBuf 其实就是 帮助我们实现序列化的一种手段.
简单认识了一下 ProtoBuf ,下面就来看看 ProtoBuf 的特点 .
ProtoBuf 的自身特点 :
- 语⾔⽆关、平台⽆关:即?ProtoBuf?⽀持?Java、C++、Python?等多种语⾔,⽀持多个平台。?
- ⾼效:即⽐?XML?更⼩、更快、更为简单。
- 扩展性、兼容性好:你可以更新数据结构,⽽不影响和破坏原有的旧程序。
ProtoBuf 的使用特点
- ProtoPuf 是需要依赖 通过 编译生的 java 代码来使用的.
这里 想一下 我们自己实现一个序列化 要如何做 (在 Java 语言下) :

上面就是 ProtoBuf 的使用流程 ,下面在来看看 ProtoBuf 的使用特点 : ProtoPuf 是需要依赖 通过 编译生的 java 代码来使用的.
引用 : ProtoBuf 完整流程图

2. 安装ProtoBuf
下载地址
Windows环境下安装ProtoBuf
图一 :

图二 :
Linux 下安装 ProtoBuf
CentOs 环境
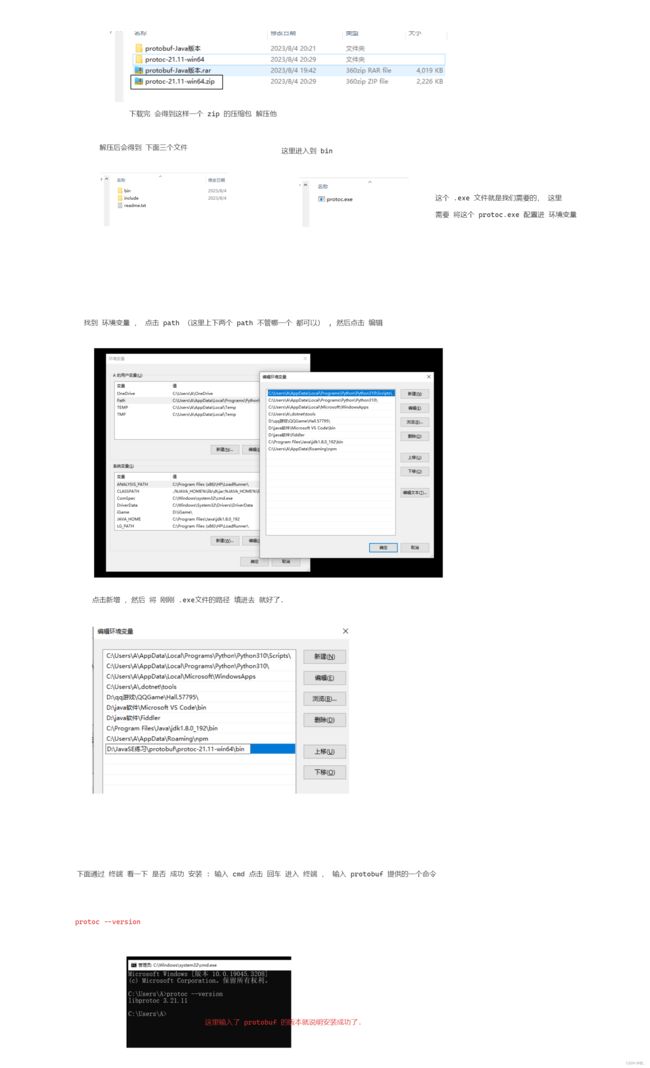
使用命令 : sudo yum install autoconf automake libtool curl make gcc-c++ unzip
图一 :
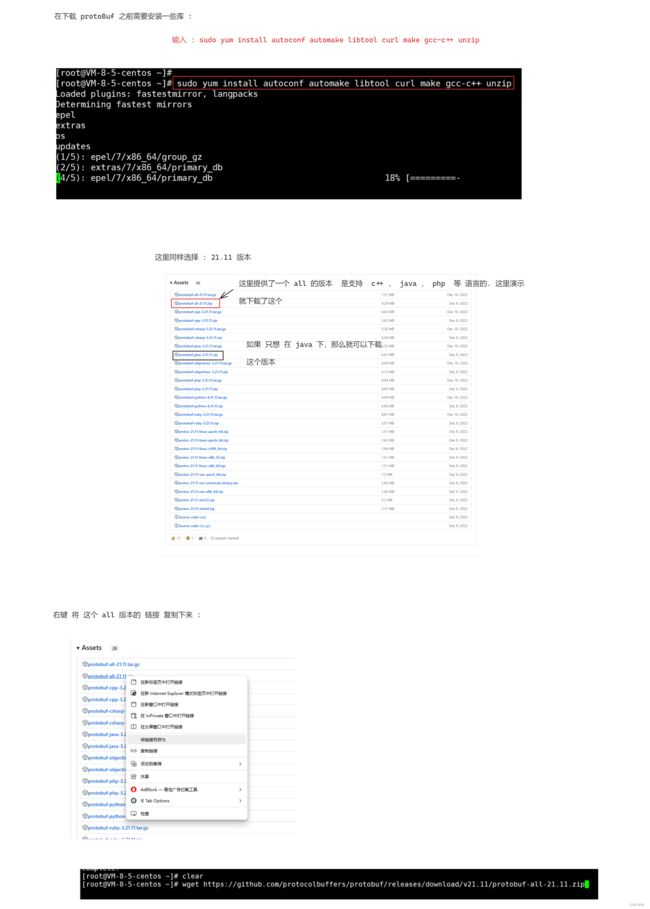
图二 :
# 第⼀步执⾏autogen.sh,但如果下载的是具体的某⼀⻔语⾔,不需要执⾏这⼀步。
./autogen.sh
# 第⼆步执⾏configure,有两种执⾏⽅式,任选其⼀即可,如下:
# 1、protobuf默认安装在 /usr/local ⽬录,lib、bin都是分散的
./configure
# 2、修改安装⽬录,统⼀安装在/usr/local/protobuf下
./configure --prefix=/usr/local/protobuf
图一 :

图二 :
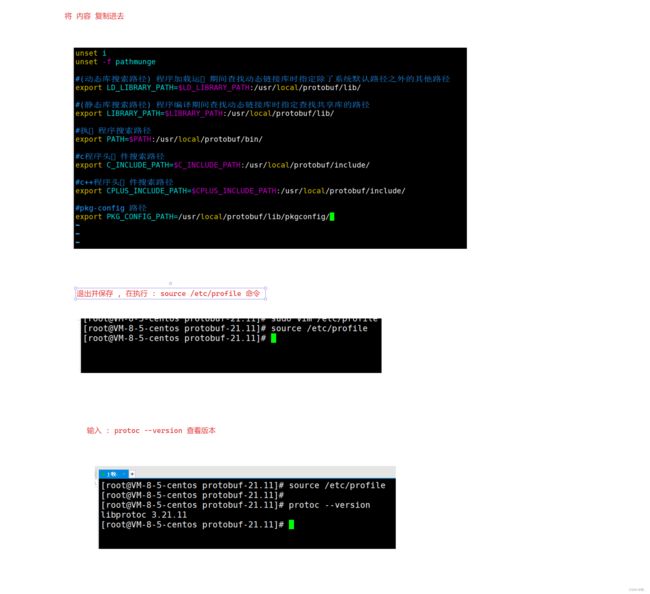
sudo vim /etc/profile
# 添加内容如下:
#(动态库搜索路径) 程序加载运⾏期间查找动态链接库时指定除了系统默认路径之外的其他路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/
#(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/
#执⾏程序搜索路径
export PATH=$PATH:/usr/local/protobuf/bin/
#c程序头⽂件搜索路径
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/
#c++程序头⽂件搜索路径
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/
#pkg-config 路径
export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/
最后⼀步,重新执⾏ /etc/profile ⽂件: source /etc/profile
到此 在 Linux 下 就安装完 ProtoBuf , 下面就来学习一下如何快速上手 ProtoBuf 。
3. 快速上手 ProtoBuf
关于 快速 上手 ProtoBuf , 这里有两个目的 :
- 体验 ProtoBuf 的使用流程
- l了解 ProtoBuf 的基础语法
这里来实现 一个 通讯录 1.0 来 了解 ProtoBuf 的使用流程 及 ProtoBuf 的基础语法.
需求 :
- 对⼀个联系⼈的信息使⽤ PB 进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤ PB 进⾏反序列,解析出联系信息并打印出来。
- 联系⼈包含以下信息: 姓名、年龄。
在编写代码之前 ,我们先来下载一个插件 :
第一步 : 创建一个 Maven 项目

2.进入 jar 包
<dependency>
<groupId>com.google.protobufgroupId>
<artifactId>protobuf-javaartifactId>
<version>${protobuf.version}version>
dependency>
注意 : 这里 使用的 jar 包 版本 需要和我们安装的 protobuf 版本一致 ,如 文章中使用的 3.21.11

3.创建 对应的包 和 文件

下面就来 编写我们的代码 , 这里先来说几个基本的语法点
在首行指定语法版本

添加文件选项
在 .proto 文件中 可以声明许多选项 使用 option 标注 选项能影响?proto?编译器的某些处理⽅式。
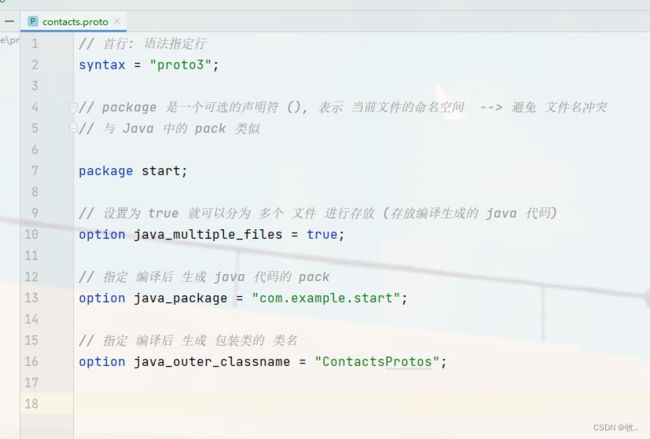
上面先简单写几个选项, 等后面说 proto3 的在详细介绍
完成上面的准本工作,下面就可以定义我们的联系人 message .
关于为啥要定义消息(message) 之前是说过的 ,在 认识ProtoBuf 中 提到过 , 这里再简单说一说 .
消息(message): 要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容。在⽹络传输中,我们需要为传输双⽅定制协议。
定制协议说⽩了就是定义结构体或者结构化数据,
⽐如,tcp,udp报⽂就是结构化的。再⽐如将数据持久化存储到数据库时,会将⼀系列元数据统⼀⽤对象组织起来,再进⾏存储
所以ProtoBuf就是以message的⽅式来⽀持我们定制协议字段,后期帮助我们形成类和⽅法来使⽤。
在通讯录1.0中我们就需要为联系⼈定义⼀个 message。
定义消息字段
在message中我们可以定义其属性字段,字段定义格式为:字段类型 字段名=字段唯⼀编号;
- 字段名称命名规范:全⼩写字⺟,多个字⺟之间⽤
_连接。 - 字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)。
- 字段唯⼀编号:⽤来标识字段,⼀旦开始使⽤就不能够再改变。
该表格展⽰了定义于消息体中的标量数据类型,以及编译 .proto ⽂件之后⾃动⽣成的类中与之对应的字段类型。在这⾥展⽰了与 JAVA 语⾔对应的类型
| .proto Type | Notes | Java Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可 能为负值,应使⽤ sint32 代替。 | int |
| int64 | 使⽤变⻓编码[1]。负数的编码效率较低⸺若字段可 能为负值,应使⽤ sint64 代替。 | long |
| uint32 | 使⽤变⻓编码[1]。 | int[2] |
| uint64 | 使⽤变⻓编码[1]。 | long[2] |
| sint32 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于 常规的 int32 类型。 | int |
| sint64 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于 常规的 int64 类型。 | long |
| fixed32 | 定⻓ 4 字节。若值常⼤于2^28 则会⽐ uint32 更⾼ 效。 | int |
| fixed64 | 定⻓ 8 字节。若值常⼤于2^56 则会⽐ uint64 更⾼ 效。 | long |
| sfixed32 | 定⻓ 4 字节。 | int |
| sfixed64 | 定⻓ 8 字节。 | long |
| string | 包含 UTF-8 和 ASCII 编码的字符串,⻓度不能超过 2^32 。 | String |
| bytes | 可包含任意的字节序列但⻓度不能超过 2^32 。 | ByteString |
| bool | boolean |
[1] 变⻓编码是指:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数。
[2] 在 Java 中,⽆符号 32 位和⽆符号 64 位整数使⽤它们对应的有符号整数来表⽰,这时第⼀个 bit 位仅是简单地存储在符号位中。
简单了解看完 标量数据类型 ,这里需要着重 的说一下 字符唯一编号的范围
1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可⽤。
19000 ~ 19999 不可⽤是因为:在 Protobuf 协议的实现中,对这些数进⾏了预留。
如果⾮要在.proto ⽂件中使⽤这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警:
// 消息中定义了如下编号,代码会告警: // Field numbers 19,000 through 19,999 are reserved for the protobuf implementation string name = 19000;
这里 编译 proto 文件 还没学, 这里先简单的 看一下 定义 编号为 19000 编译后的错误
最后 值得⼀提的是,范围为 1 ~ 15 的字段编号需要⼀个字节进⾏编码, 16 ~ 2047 内的数字需要两个字节 进⾏编码。编码后的字节不仅
只包含了编号,还包含了字段类型。所以 1 ~ 15 要⽤来标记出现⾮常频繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来。

上面我们定义完 message ,相面 就来编译 contacts.proto 文件 来生成 Java 文件
这里 编译的方法有两种
- 使用 命令行编译
- 使用 maven插件编译
这里先来看定义中 : 使用命令行编译

编译命令行格式为 :
protoc [--proto_path=IMPORT_PATH] --java_out=DST_DIR path/to/file.proto
protoc 是 Protocol Buffer 提供的命令⾏编译⼯具。
--proto_path 指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -I
IMPORT_PATH 。如不指定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他
.proto ⽂件时, 或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索⽬录。
--java_out= 指编译后的⽂件为 JAVA ⽂件。
OUT_DIR 编译后⽣成⽂件的⽬标路径。
path/to/file.proto 要编译的.proto⽂件。
学习完 命令行编译 , 在来学习一下 使用 maven 插件 编译 .
关于 这种编译⽅式⽐⼿动执⾏ protoc 命令,后⾯跟⼀堆易忘的参数要高效省心得多(每次编译都得google 或找之前记的笔记)。
使用 maven 插件 编译 只需要在pom中添加 porotbuf 编译插件:
<plugin>
<groupId>org.xolstice.maven.pluginsgroupId>
<artifactId>protobuf-maven-pluginartifactId>
<version>0.6.1version>
<configuration>
<protocExecutable>
D:\JavaSE练习\protobuf\protoc-21.11-win64\bin\protoc.exe
protocExecutable>
<protoSourceRoot>${project.basedir}/src/main/protoprotoSourceRoot>
<outputDirectory>${project.basedir}/src/main/javaoutputDirectory>
<clearOutputDirectory>falseclearOutputDirectory>
configuration>
plugin>
补充 : 使用这个插件是有坑的
- 使用这个插件 项目路径是不能带中文的

关于两种编译方式就看完了, 下面我们了解一下 编译生成的 java 文件 和 内容.
图一 :
图二 :
简单了解完 编译器生成的代码, 接下来就来到大家感兴趣的部分,开始写代码了.
到此我们就完成了下面三点.
- 对⼀个联系⼈的信息使⽤ PB 进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤ PB 进⾏反序列,解析出联系信息并打印出来。
- 联系⼈包含以下信息: 姓名、年龄。
简单快速上手 ProtoBuf , 下面我们来学习 Proto3 语法
4. proto3 语法
关于 Proto3 语法的学习,通过完成下面 几点需求 来学习.
- 不再打印联系⼈的序列化结果,⽽是将通讯录序列化后并写⼊⽂件中。
- 从⽂件中将通讯录解析出来,并进⾏打印。
- 新增联系⼈属性,共包括:姓名、年龄、电话信息、地址、其他联系⽅式、备注。
1.字段规则
消息的字段可以⽤下⾯⼏种规则来修饰:
• singular :消息中可以包含该字段零次或⼀次(不超过⼀次) ,proto3 语法中,字段默认使⽤该 规则。
• repeated :消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理 解为定义了⼀个数组。
演示 :

2. 消息类型的定义与使用
定义 : 在单个 .proto ⽂件中可以定义多个消息体,且⽀持定义嵌套类型的消息(任意多层)。每个消息体中 的字段编号可以重复。
图一 :
图二 :
看完上面两个语法点我们就可以来完成三个需求了 :
图一 :
图二 :
附上代码 :
package com.example.proto3;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
public class TestWrite {
public static void main(String[] args) throws IOException {
Contacts.Builder contactsBuilder = Contacts.newBuilder();
// // 读取本地已存在的 contacts.bin 反序列化出 通讯录对象
// Contacts contacts = Contacts.parseFrom(new FileInputStream(
// "src/main/java/com/example/proto3/contacts.bin"
// ));
//
// // 这里向统通讯录中新增一个联系人 需要获取到 builder .
// contactsBuilder = contacts.toBuilder();
try {
contactsBuilder.mergeFrom(
new FileInputStream(
"src/main/java/com/example/proto3/contacts.bin"
)
);
} catch (FileNotFoundException e) {
System.out.println("contacts.bin not find , create new file");
}
// 向通讯录中新增一个联系人
contactsBuilder.addContacts(addPeopleInfo());
// 序列化通讯录, 将结果写入文件中
FileOutputStream outputStream = new FileOutputStream(
"src/main/java/com/example/proto3/contacts.bin"
);
// writeTo 方法会完成两部操作 1. 序列化 联系热 2. 将序列化的结果添加到 文件中
contactsBuilder.build().writeTo(outputStream);
}
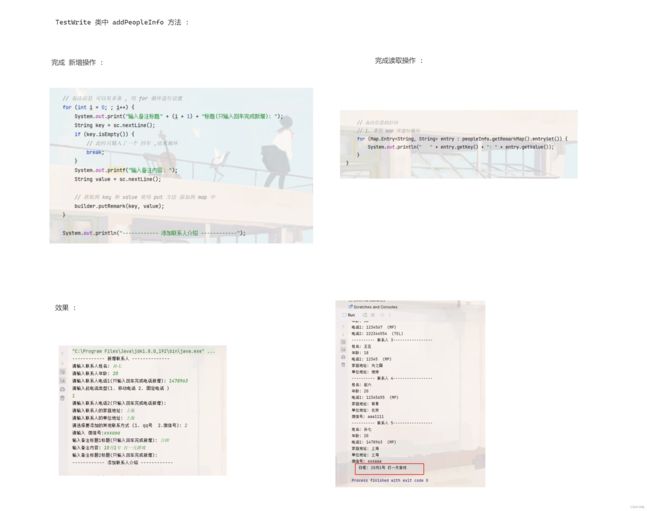
private static PeopleInfo addPeopleInfo() {
PeopleInfo.Builder builder = PeopleInfo.newBuilder();
Scanner sc = new Scanner(System.in);
System.out.println("------------ 新增联系人 --------------");
System.out.print("请输入联系人姓名: ");
String name = sc.nextLine();
builder.setName(name);
System.out.print("请输入联系人年龄: ");
int age = sc.nextInt();
// 用户输入完数字后会有一个回车 这里需要使用 nextLine() 将回车读出来
sc.nextLine();
builder.setAge(age);
// 设置联系人的电话信息
for (int i = 0; ; i++) {
// 这里 写一个死循环 ,让用户一直输出 电话信息
System.out.print("请输入联系人电话" + (i + 1) + "(只输入回车完成电话新增): ");
String number = sc.nextLine();
if (number.isEmpty()) {
break;
}
PeopleInfo.Phone.Builder phoneBuilder = PeopleInfo.Phone.newBuilder();
phoneBuilder.setNumber(number);
builder.addPhone(phoneBuilder);
}
System.out.println("------------ 添加联系人介绍 ------------");
// 通过 build 方法返回一个 peopleInfo
return builder.build();
}
}
读取 contacts.bin 文件 ,进行反序列操作
到此前两个 需求就完成了,下面我们继续来了解 proto3的语法点.
3. enum类型
图一 :

图二 :
简单学习完 枚举类型 ,下面就来通过 枚举 类型 来完成我们的需求三 :
- 新增联系⼈属性,共 包括:姓名、年龄、电话信息、地址、其他联系⽅式、备注。
枚举类型学完,下面继续 学习 proto3的语法
4. Any类型
Any 其实是一个 消息类型, 如 : message Any , Any 是ProtoBuf 为我们定义好了的消息类型.
引用
字段还可以声明为 Any 类型,可以理解为泛型类型。使⽤时可以在 Any 中存储任意消息类型。
Any 类 型的字段也⽤ repeated 来修饰。 Any 类型是 google 已经帮我们定义好的类型,在安装 ProtoBuf 时,其中的 include ⽬录下查找
所有 google 已经定义好的 .proto ⽂件。
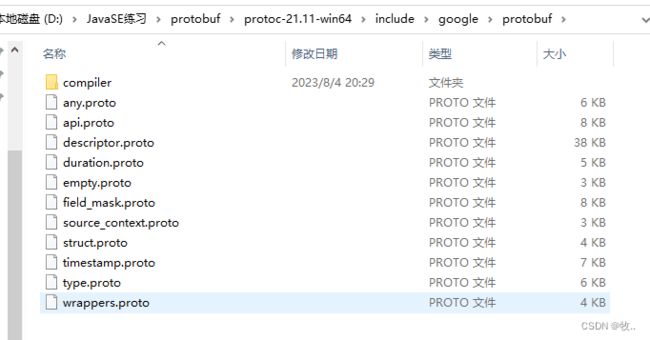
下面来使用一下 Any 类型 :
图一 :
图二 :

图三 :
附上代码 :
TestWrite
package com.example.proto3;
import com.google.protobuf.Any;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
public class TestWrite {
public static void main(String[] args) throws IOException {
Contacts.Builder contactsBuilder = Contacts.newBuilder();
// // 读取本地已存在的 contacts.bin 反序列化出 通讯录对象
// Contacts contacts = Contacts.parseFrom(new FileInputStream(
// "src/main/java/com/example/proto3/contacts.bin"
// ));
//
// // 这里向统通讯录中新增一个联系人 需要获取到 builder .
// contactsBuilder = contacts.toBuilder();
try {
contactsBuilder.mergeFrom(
new FileInputStream(
"src/main/java/com/example/proto3/contacts.bin"
)
);
} catch (FileNotFoundException e) {
System.out.println("contacts.bin not find , create new file");
}
// 向通讯录中新增一个联系人
contactsBuilder.addContacts(addPeopleInfo());
// 序列化通讯录, 将结果写入文件中
FileOutputStream outputStream = new FileOutputStream(
"src/main/java/com/example/proto3/contacts.bin"
);
// writeTo 方法会完成两部操作 1. 序列化 联系热 2. 将序列化的结果添加到 文件中
contactsBuilder.build().writeTo(outputStream);
// 最后别忘记关闭流对象
outputStream.close();
}
private static PeopleInfo addPeopleInfo() {
PeopleInfo.Builder builder = PeopleInfo.newBuilder();
Scanner sc = new Scanner(System.in);
System.out.println("------------ 新增联系人 --------------");
System.out.print("请输入联系人姓名: ");
String name = sc.nextLine();
builder.setName(name);
System.out.print("请输入联系人年龄: ");
int age = sc.nextInt();
// 用户输入完数字后会有一个回车 这里需要使用 nextLine() 将回车读出来
sc.nextLine();
builder.setAge(age);
// 设置联系人的电话信息
for (int i = 0; ; i++) {
// 这里 写一个死循环 ,让用户一直输出 电话信息
System.out.print("请输入联系人电话" + (i + 1) + "(只输入回车完成电话新增): ");
String number = sc.nextLine();
if (number.isEmpty()) {
break;
}
PeopleInfo.Phone.Builder phoneBuilder = PeopleInfo.Phone.newBuilder();
phoneBuilder.setNumber(number);
System.out.println("请输入此电话类型(1. 移动电话 2. 固定电话 )");
int type = sc.nextInt();
// 接收回车
sc.nextLine();
switch (type) {
case 1:
phoneBuilder.setType(PeopleInfo.Phone.PhoneType.MP);
break;
case 2:
phoneBuilder.setType(PeopleInfo.Phone.PhoneType.TEL);
break;
default:
System.out.println("选择错误!");
}
builder.addPhone(phoneBuilder);
}
// 设置联系人的 地址信息
Address.Builder addressBuilder = Address.newBuilder();
System.out.print("请输入联系人的家庭地址: ");
String homeAddress = sc.nextLine();
addressBuilder.setHomeAddress(homeAddress);
System.out.print("请输入联系人的单位地址: ");
String unitAddress = sc.nextLine();
addressBuilder.setUnitAddress(unitAddress);
builder.setData(Any.pack(addressBuilder.build()));
System.out.println("------------ 添加联系人介绍 ------------");
// 通过 build 方法返回一个 peopleInfo
return builder.build();
}
}
TestRead
package com.example.proto3;
import com.google.protobuf.InvalidProtocolBufferException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestRead {
public static void main(String[] args) throws IOException {
// 读取文件, 将读取的内容进行反序列化
Contacts contacts = Contacts.parseFrom(new FileInputStream(
"src/main/java/com/example/proto3/contacts.bin"
));
// 打印
printContacts(contacts);
// System.out.println(contacts.toString());
}
private static void printContacts(Contacts contacts) throws InvalidProtocolBufferException {
int i = 1;
// 通过 getContactsList() 方法 , 获取到每个 peopleInfo
for (PeopleInfo peopleInfo : contacts.getContactsList()) {
System.out.println("---------- 联系人 " + i++ + "-----------------");
System.out.println("姓名: " + peopleInfo.getName());
System.out.println("年龄: " + peopleInfo.getAge());
int j = 1;
// 联系人的电话信息是 存在一个数组里面这里就需要 遍历打印
for (PeopleInfo.Phone phone : peopleInfo.getPhoneList()) {
System.out.println("电话" + j++ + ": " + phone.getNumber()
+ " (" + phone.getType().name() + ")");
}
// 通过 hasData 方法 判断 Data 中是否存放了数据 , 通过 is 方法 判断 Data 中存放的是否为 Address
if (peopleInfo.hasData() && peopleInfo.getData().is(Address.class)) {
// 此时说明 有数据 , 并为 Address
// 在打印之前需要转化一下
Address address = peopleInfo.getData().unpack(Address.class);
if (!address.getHomeAddress().isEmpty()) {
System.out.println("家庭地址: " + address.getHomeAddress());
}
if (!address.getUnitAddress().isEmpty()) {
System.out.println("单位地址: " + address.getUnitAddress());
}
}
}
}
}
5. oneof 类型
到目前为止 ,我们的通讯录 已经可以添加 姓名 ,年龄 , 电话信息 , 地址信息 , 下面通过 oneof 类型 再给通讯录 添加一个 字段 如 : 其他联系方式 (qq , wechat)
图一 :
图二 :
6. map类型
这里我们学习 map 类型 ,同样 通过 升级 通讯录来学习, 这次我们向联系人中添加备注信息.
图一 :

图二 :
到此 关于 protobuf 的 大部分类型我们都看过了 ,想必大家对使用 protobuf 没啥问题了,下面来说说 使用 protobuf 的一些坑.
7. 默认值
反序列化消息时,如果被反序列化的⼆进制序列中不包含某个字段,反序列化对象中相应字段时,就 会设置为该字段的默认值。不同的类型对应的默认值不同:
• 对于字符串,默认值为空字符串。
• 对于字节,默认值为空字节。
• 对于布尔值,默认值为 false。
• 对于数值类型,默认值为 0。
• 对于枚举,默认值是第⼀个定义的枚举值, 必须为 0。
• 对于消息字段,未设置该字段。它的取值是依赖于语⾔。
• 对于设置了 repeated 的字段的默认值是空的( 通常是相应语⾔的⼀个空列表 )。
• 对于 消息字段 、 oneof字段 和 any字段 , 都有 has ⽅法来检测当前字段是否被设置。
• 对于 标量数据类型 没有 has 方法
举例 :

8. 更新消息
这里来说说 如果我们要更新消息类型需要注意那些点 :
如果现有的消息类型已经不再满⾜我们的需求,例如需要扩展⼀个字段,在不破坏任何现有代码的情 况下更新消息类型⾮常简单。
关于 更新规则 : 这里说两点
- 新增字段 : 注意新增的字段不和老字段冲突 :
名称 字段号 - 修改老字段 :
- 禁⽌修改任何已有字段的字段编号。
- int32, uint32, int64, uint64 和 bool 是完全兼容的。可以从这些类型中的⼀个改为另⼀个, ⽽不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,可能会被截断(例如,若将 64 位整数当做 32 位进⾏读取,它将被截断为 32 位)。
sint32 和 sint64 相互兼容但不与其他的整型兼容。
string 和 bytes 在合法 UTF-8 字节前提下也是兼容的。
bytes 包含消息编码版本的情况下,嵌套消息与 bytes 也是兼容的。
fixed32 与 sfixed32 兼容, fixed64 与 sfixed64兼容。 • enum 与 int32,uint32, int64 和 uint64 兼容(注意若值不匹配会被截断)。但要注意当反序 列化消息时会根据语⾔采⽤不同的处理⽅案:例如,未识别的 proto3 枚举类型会被保存在消息 中,但是当消息反序列化时如何表⽰是依赖于编程语⾔的。整型字段总是会保持其的值。
oneof:
将⼀个单独的值更改为 新 oneof 类型成员之⼀是安全和⼆进制兼容的。
若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新 oneof 类型也是可⾏的。
将任何字段移⼊已存在的 oneof 类型是不安全的。

补充:若是移除⽼字段,要保证不再使⽤移除字段的字段编号。正确的做法是保留字段编号 (reserved),以确保该编号将不能被重复使⽤。不建议直接删除或注释掉字段。
演示 : 删除老字段后 ,定义新字段 使用老子段的编号出现的问题 .
图一 :

TestRead :
package com.example.update.service;
import com.google.protobuf.InvalidProtocolBufferException;
import java.io.FileInputStream;
import java.io.IOException;
public class TestRead {
public static void main(String[] args) throws IOException {
// 读取文件, 将读取的内容进行反序列化
Contacts contacts = Contacts.parseFrom(new FileInputStream(
"src/main/java/com/example/proto3/contacts2.bin"
));
// 打印
printContacts(contacts);
// System.out.println(contacts.toString());
}
private static void printContacts(Contacts contacts) throws InvalidProtocolBufferException {
int i = 1;
// 通过 getContactsList() 方法 , 获取到每个 peopleInfo
for (PeopleInfo peopleInfo : contacts.getContactsList()) {
System.out.println("---------- 联系人 " + i++ + "-----------------");
System.out.println("姓名: " + peopleInfo.getName());
System.out.println("年龄: " + peopleInfo.getAge());
int j = 1;
// 联系人的电话信息是 存在一个数组里面这里就需要 遍历打印
for (PeopleInfo.Phone phone : peopleInfo.getPhoneList()) {
System.out.println("电话" + j++ + ": " + phone.getNumber());
}
}
}
}
TestWrite
package com.example.update.service;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Scanner;
public class TestWrite {
public static void main(String[] args) throws IOException {
Contacts.Builder contactsBuilder = Contacts.newBuilder();
try {
contactsBuilder.mergeFrom(
new FileInputStream(
"src/main/java/com/example/proto3/contacts2.bin"
)
);
} catch (FileNotFoundException e) {
System.out.println("contacts.bin not find , create new file");
}
// 向通讯录中新增一个联系人
contactsBuilder.addContacts(addPeopleInfo());
// 序列化通讯录, 将结果写入文件中
FileOutputStream outputStream = new FileOutputStream(
"src/main/java/com/example/proto3/contacts2.bin"
);
// writeTo 方法会完成两部操作 1. 序列化 联系热 2. 将序列化的结果添加到 文件中
contactsBuilder.build().writeTo(outputStream);
// 最后别忘记关闭流对象
outputStream.close();
}
private static PeopleInfo addPeopleInfo() {
PeopleInfo.Builder builder = PeopleInfo.newBuilder();
Scanner sc = new Scanner(System.in);
System.out.println("------------ 新增联系人 --------------");
System.out.print("请输入联系人姓名: ");
String name = sc.nextLine();
builder.setName(name);
System.out.print("请输入联系人年龄: ");
int age = sc.nextInt();
// 用户输入完数字后会有一个回车 这里需要使用 nextLine() 将回车读出来
sc.nextLine();
builder.setAge(age);
// 设置联系人的电话信息
for (int i = 0; ; i++) {
// 这里 写一个死循环 ,让用户一直输出 电话信息
System.out.print("请输入联系人电话" + (i + 1) + "(只输入回车完成电话新增): ");
String number = sc.nextLine();
if (number.isEmpty()) {
break;
}
PeopleInfo.Phone.Builder phoneBuilder = PeopleInfo.Phone.newBuilder();
phoneBuilder.setNumber(number);
builder.addPhone(phoneBuilder);
}
System.out.println("------------ 添加联系人介绍 ------------");
// 通过 build 方法返回一个 peopleInfo
return builder.build();
}
}
这两个类 相比之前 减少了一些 添加字段的操作.

看完上面知道了 要避免使用移除后老字段的编号 ,如果 字段非常多 ,编号也分常多 ,总免有忘记删除字段后使用过的编号
这里想要避免这种情况 就可以使用一个 关键字 : reserved , proto3提供的关键字.
演示 :
9. 未知字段
10. 前后兼容性
在 更新字段 规则中提到过 前后兼容性问题 ,这里 就来 具体的了解一下.
根据上述的例⼦可以得出,pb是具有向前兼容的。为了叙述⽅便,把增加了“⽣⽇”属性的 service 称为“新模块”;未做变动的 client 称为 “⽼模块”。
• 向前兼容:⽼模块能够正确识别新模块⽣成或发出的协议。这时新增加的“⽣⽇”属性会被当作未 知字段(pb 3.5版本及之后)。
• 向后兼容:新模块也能够正确识别⽼模块⽣成或发出的协议。 前后兼容的作⽤:当我们维护⼀个很庞⼤的分布式系统时,由于你⽆法同时 升级所有 模块,为了保证 在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼 容”。
前后兼容的作⽤:当我们维护⼀个很庞⼤的分布式系统时,由于你⽆法同时 升级所有 模块,为了保证 在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼容”。
11. option 选项
.proto 文件中可以声明许多选项,使用 option 标注。选项能影响 proto 编译器的某些处理⽅式。
关于 option 能选着的选项 可以在 google/protobuf/descriptor.proto 中查看.
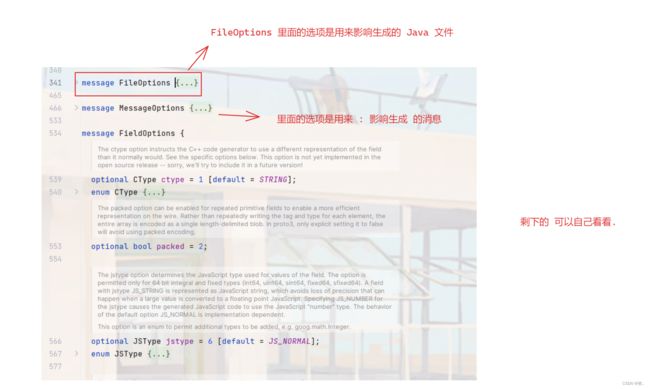
这里来说一说关于 java 常用的选项
- java_multiple_files:编译后⽣成的⽂件是否分为多个⽂件,该选项为⽂件选项。
- java_package:编译后⽣成⽂件所在的包路径,该选项为⽂件选项。
- java_outer_classname:编译后⽣成的proto包装类的类名,该选项为⽂件选项。
- allow_alias : 允许将相同的常量值分配给不同的枚举常量,⽤来定义别名。该选项为枚举选项。
前面三个 文件级别的选项我们已经 使用过 ,这里不多说 这里 主要看看 allow_alias 选项。
演示 :

除了 列举好了的选项 我们 还可以自定义选项 , 但是 关于自定义选项 大部分场景是用不到的,别人定义好的就足够用了, 这里有兴趣 可以自己查看
:Language Guide (proto 2) | Protocol Buffers Documentation (protobuf.dev) 这个网站进行学习.
5. probuf 实战
到此 我们 已经对 proto3 语法有了一定了解 ,但是 光了解 肯定还是不行的,下面我们来简单进行一个实战 ,对 通讯录 进行最后一次升级 ,实现一个网络版本的通讯录.
既然是网络版本的肯定是存在 客户端 , 服务器 .

这里来看看完成这个实战的 需求 :
• 客⼾端:向服务端发送联系⼈信息,并接收服务端返回的响应。
• 服务端:接收到联系⼈信息后,将结果打印出来。
• 客⼾端、服务端间的交互数据使⽤ Protobuf 来完成。
流程图 :

这里 使用 maven + upd 数据报套接字 进行 编程.
1.搭建客户端服务端
这里就是网络编程 使用 socket 套接字 , 如果 忘记或不清楚的话 可以看看 这篇文章 :网络编程 – socket 套接字_牧…的博客-CSDN博客
客户端 :
package com.example.internet.client;
import com.example.proto3.Address;
import com.example.proto3.PeopleInfo;
import java.io.IOException;
import java.net.*;
public class ContactsClient {
// 这里将 客户端的 端口号 和 IP 地址写死 .
private static SocketAddress ADDRESS = new InetSocketAddress("localhost", 8888);
public static void main(String[] args) throws IOException {
// 创建客户端 DatagramSocket
DatagramSocket socket = new DatagramSocket();
// 构造 request 请求
byte[] requestData = {'h', 'e', 'l', 'l', '0'};
DatagramPacket requestPacket = new DatagramPacket(requestData, requestData.length, ADDRESS);
// 发送 request 数据报
socket.send(requestPacket);
System.out.println("发送成功!");
// 获取 响应 (response)
// 创建 response 数据报 用于接收服务端返回的响应
byte[] udpResponse = new byte[1024];
DatagramPacket responsePacket = new DatagramPacket(udpResponse, udpResponse.length);
// 接收 response 数据报
socket.receive(responsePacket);
int length = BytesUtils.getValidLength(udpResponse);
byte[] responseData = BytesUtils.subByte(udpResponse, 0, length);
// 打印结果
System.out.printf("接收到响应 : %s" ,new String(responseData));
}
}
BytesUtil
package com.example.internet.client;
public class BytesUtils {
// 获取 bytes 的有效长度
public static int getValidLength(byte[] bytes) {
int i = 0;
if (null == bytes || 0 == bytes.length) {
return i;
}
for (; i < bytes.length; i++) {
if (bytes[i] == '\0') {
break;
}
}
return i;
}
// 截断bytes
public static byte[] subByte(byte[] b, int off, int length) {
byte[] b1 = new byte[length];
// 通过 arrayCopy 进行截断 (想到与 拷贝 length 长度到新的 数组中并返回)
System.arraycopy(b, off, b1, 0, length);
return b1;
}
}
服务端 :
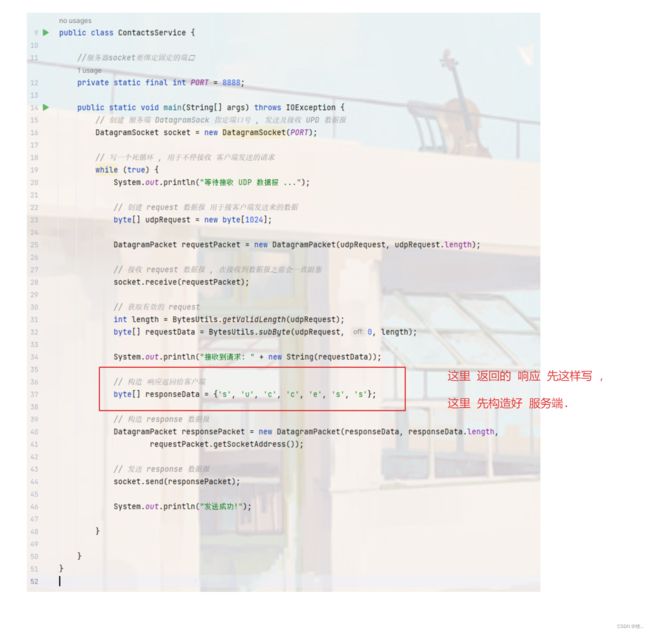
package com.example.internet.service;
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.SocketException;
import java.util.Arrays;
public class ContactsService {
//服务器socket要绑定固定的端⼝
private static final int PORT = 8888;
public static void main(String[] args) throws IOException {
// 创建 服务端 DatagramSock 指定端口号 , 发送及接收 UPD 数据报
DatagramSocket socket = new DatagramSocket(PORT);
// 写一个死循环 , 用于不停接收 客户端发送的请求
while (true) {
System.out.println("等待接收 UDP 数据报 ...");
// 创建 request 数据报 用于接客户端发送来的数据
byte[] udpRequest = new byte[1024];
DatagramPacket requestPacket = new DatagramPacket(udpRequest, udpRequest.length);
// 接收 request 数据报 , 在接收到数据报之前会一直阻塞
socket.receive(requestPacket);
// 获取有效的 request
int length = BytesUtils.getValidLength(udpRequest);
byte[] requestData = BytesUtils.subByte(udpRequest, 0, length);
System.out.println("接收到请求: " + new String(requestData));
// 构造 响应返回给客户端
byte[] responseData = {'s', 'u', 'c', 'c', 'e', 's', 's'};
// 构造 response 数据报
DatagramPacket responsePacket = new DatagramPacket(responseData, responseData.length,
requestPacket.getSocketAddress());
// 发送 response 数据报
socket.send(responsePacket);
System.out.println("发送成功!");
}
}
}
效果 :
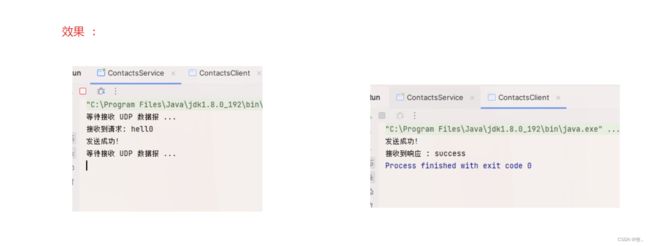
到此 客户端 和 服务端就构造好了,下面 就来用上我们的 protobuf 进行 序列化 和 反序列化操作.
图一 :
图二 :
6. 总结
到此关于 protobuf 的学习就完成了, 简单学习了一下语法 ,简单使用了一些 api .
这里来通过代码的形式来对比 验证 JSON 和 PB 的能力.
1. 序列化能力对比
在这⾥让我们分别使⽤ PB 与 JSON 的序列化与反序列化能⼒, 对值完全相同的⼀份结构化数据进⾏ 不同次数的性能测试。
为了可读性,下⾯这⼀份⽂本使⽤ JSON 格式展⽰了需要被进⾏测试的结构化数据内容:
{
"age": 20,
"name": "张珊",
"phone": [
{
"number": "110112119",
"type": 0
},
{
"number": "110112119",
"type": 0
},
{
"number": "110112119",
"type": 0
},
{
"number": "110112119",
"type": 0
},
{
"number": "110112119",
"type": 0
}
],
"qq": "95991122",
"address": {
"home_address": "陕西省西安市⻓安区",
"unit_address": "陕西省西安市雁塔区"
},
"remark": {
"key1": "value1",
"key2": "value2",
"key3": "value3",
"key4": "value4",
"key5": "value5"
}
}
提供测试用的代码 :
package com.example.compare;
import com.alibaba.fastjson2.JSON;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.protobuf.Any;
import com.google.protobuf.InvalidProtocolBufferException;
import static com.example.compare.PeopleInfoForJson.Phone.PhoneType.MP;
public class Compare {
private static int TEST_COUNT = 100000;
public static void main(String[] args) throws
InvalidProtocolBufferException, JsonProcessingException {
int count = 0;
byte[] pbBytes = new byte[0];
String jsonStr = null;
ObjectMapper objectMapper = new ObjectMapper();
// ------------------------------Protobuf 序列化 -----------------------------------
{
PeopleInfo peopleInfo = buildPeopleInfo();
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 序列化count次
while ((count--) > 0) {
pbBytes = peopleInfo.toByteArray();
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [pb序列化]耗时:%dms, 序列化后的⼤⼩: %d\n",
TEST_COUNT, etime - stime, pbBytes.length);
}
// ------------------------------Protobuf 反序列化 ---------------------------------
{
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 反序列化count次
while ((count--) > 0) {
PeopleInfo.parseFrom(pbBytes);
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [pb反序列化]耗时:%dms\n",
TEST_COUNT, etime - stime);
}
// ---------------------------- fastjson2 序列化 ------------------------------------
{
PeopleInfoForJson peopleInfoForJson = buildPeopleInfoForJson();
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 序列化count次
while ((count--) > 0) {
jsonStr = JSON.toJSONString(peopleInfoForJson);
//JSON.toJSONString(peopleInfoForJson);
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [fastjson2序列化]耗时:%dms, 序列化后的⼤⼩: % d\n",
TEST_COUNT, etime - stime, jsonStr.length());
}
// --------------------------- fastjson2 反序列化 -----------------------------------
{
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 反序列化count次
while ((count--) > 0) {
JSON.parseObject(jsonStr, PeopleInfoForJson.class);
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [fastjson2反序列化]耗时:%dms\n",
TEST_COUNT, etime - stime);
}
// ------------------------------jackson 序列化 ---------------------------------------
{
PeopleInfoForJson peopleInfoForJson = buildPeopleInfoForJson();
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 序列化count次
while ((count--) > 0) {
jsonStr = objectMapper.writeValueAsString(peopleInfoForJson);
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [jackson序列化]耗时:%dms, 序列化后的⼤⼩: % d\n",
TEST_COUNT, etime - stime, jsonStr.length());
}
// ------------------------------jackson 反序列化 -------------------------------------
{
count = TEST_COUNT;
long stime = System.currentTimeMillis();
// 反序列化count次
while ((count--) > 0) {
objectMapper.readValue(jsonStr, PeopleInfoForJson.class);
}
long etime = System.currentTimeMillis();
System.out.printf("%d次 [jackson反序列化]耗时:%dms\n",
TEST_COUNT, etime - stime);
}
}
private static PeopleInfo buildPeopleInfo() {
PeopleInfo.Builder peopleBuilder = PeopleInfo.newBuilder();
peopleBuilder.setName("张珊");
peopleBuilder.setAge(20);
peopleBuilder.setQq("95991122");
for (int i = 0; i < 5; i++) {
PeopleInfo.Phone.Builder phoneBuild =
PeopleInfo.Phone.newBuilder();
phoneBuild.setNumber("110112119");
phoneBuild.setType(PeopleInfo.Phone.PhoneType.MP);
}
com.example.proto3.Address.Builder addressBuilder =
com.example.proto3.Address.newBuilder();
addressBuilder.setHomeAddress("陕西省西安市⻓安区");
addressBuilder.setUnitAddress("陕西省西安市雁塔区");
peopleBuilder.setData(Any.pack(addressBuilder.build()));
peopleBuilder.putRemark("key1", "value1");
peopleBuilder.putRemark("key2", "value2");
peopleBuilder.putRemark("key3", "value3");
peopleBuilder.putRemark("key4", "value4");
peopleBuilder.putRemark("key5", "value5");
return peopleBuilder.build();
}
private static PeopleInfoForJson buildPeopleInfoForJson() {
PeopleInfoForJson peopleInfo = new PeopleInfoForJson();
peopleInfo.setName("张珊");
peopleInfo.setAge(20);
peopleInfo.setQq("95991122");
for (int i = 0; i < 5; i++) {
PeopleInfoForJson.Phone phone = new PeopleInfoForJson.Phone();
phone.setNumber("110112119");
phone.setType(MP);
peopleInfo.getPhones().add(phone);
}
PeopleInfoForJson.Address address = new PeopleInfoForJson.Address();
address.setHomeAddress("陕西省西安市⻓安区");
address.setUnitAddress("陕西省西安市雁塔区");
peopleInfo.setAddress(address);
peopleInfo.getRemark().put("key1", "value1");
peopleInfo.getRemark().put("key2", "value2");
peopleInfo.getRemark().put("key3", "value3");
peopleInfo.getRemark().put("key4", "value4");
peopleInfo.getRemark().put("key5", "value5");
return peopleInfo;
}
}
分别对相同的结构化数据进⾏ 100 、 1000 、 10000 、 100000 次的序列化与反序列化,包含:PB、fastjson2、jackson,分别获取其耗时与序列化后的 ⼤⼩。

完整代码 :
总结
| 序列化协议 | 通用性 | 格式 | 可读性 | 序列化大小 | 序列化性能 | 适⽤场景 |
|---|---|---|---|---|---|---|
| JSON | 通⽤ (json、 xml已成为多种 ⾏业标准的编 写⼯具) |
文本格式 | 好 | 轻量 (使 ⽤键值对 ⽅式,压 缩了⼀定 的数据空 间) |
中 | web项⽬。因为浏览 器对于json数据⽀持 ⾮常好,有很多内建 的函数⽀持。 |
| XML | 通⽤ | ⽂本格式 | 好 | 重量(数 据冗余, 因为需要 成对的闭 合标签) | 低 | XML 作为⼀种扩展标 记语⾔,衍⽣出了 HTML、RDF/RDFS, 它强调数据结构化的 能⼒和可读性。 |
| ProtoBuf | 独⽴ (Protobuf只 是Google公司 内部的⼯具) |
⼆进制格式 | 差(只能 反序列化 后得到真 正可读的 数据) | 轻量(⽐ JSON更轻 量,传输 起来带宽 和速度会 有优化) | ⾼ | 适合⾼性能,对响应 速度有要求的数据传 输场景。Protobuf⽐ XML、JSON 更⼩、 更快。 |
⼩结:
- XML、JSON、ProtoBuf 都具有数据结构化和数据序列化的能⼒。
- XML、JSON 更注重数据结构化,关注可读性和语义表达能⼒。ProtoBuf 更注重数据序列化,关注 效率、空间、速度,可读性差,语义表达能⼒不⾜,为保证极致的效率,会舍弃⼀部分元信息。
- ProtoBuf 的应用场景更为明确 , XML , JSON 的应用场景更为丰富.