用户行为数据全链路解析
用户行为数据全链路解析
-
- 一、数据采集
-
- 1.埋点概念
- 2.埋点分类
- 3.埋点参数
- 4.抓包工具
- 二、数据上报
-
- 1.上报流程
- 2.上报策略
- 3.数据存储
- 三、数据消费
-
- 1.离线消费
- 2.实时消费
企业中除了商品、库存、物流、交易等业务数据外,还有一类用户行为数据。用户行为数据指的是用户与客户端(泛指企业的APP、网页门户、小程序等)交互时产生的数据,主要用于记录和分析用户的行为习惯。目前,用户行为数据越来越受企业的重视,通过对用户行为数据的分析可以指导产品的优化方向,挖掘新的业务增长点,并且可以为企业的各项发展决策提供数据支撑。以下从用户行为数据的采集、上报和消费三个过程对数据流向进行简单的解析。
一、数据采集
1.埋点概念
埋点是获取用户行为数据的工具,处于数据链路的最前端,一套准确合理的埋点方案是精准获取用户行为数据的先决条件,是后续数据分析的基石。目前常用的埋点技术可以分为代码埋点、可视化埋点和无埋点三类。代码埋点是在需要上报数据的页面或位置的源码中嵌入埋点代码,当埋点机制被触发时上报数据;可视化埋点就是通过设备与web埋点管理界面进行连接,将客户端相关页面展示在管理界面上,让埋点人员直接在管理界面对页面中需要采集数据的位置配置埋点信息,这种埋点方式可以跳过代码部署、测试和发版的过程,做到"所见即所得";无埋点也可以理解为"全埋点",这种埋点方式是采集客户端所有控件的数据,后续在分析界面根据需求配置相关的控件进行数据分析。
其中,代码埋点历史最久,具有兼容性好,可自定义属性值等优点。由于代码埋点可以采集更深、更细粒度的用户行为数据,因此是目前大型互联网企业主流的数据采集方式。以下针对代码埋点进行数据采集、上报和落表过程的分析.
代码埋点是根据业务需求在用户产生行为的页面和位置植入的一种统计代码,通过SDK或者前端JS上报统计数据,用于采集用户的行为数据。通俗点解释:这类埋点就是一串标识(通常为自定义的英文字符串),用以标记某个页面、坑位或者某块区域等。如定义ProductDetail标识商品详情页面,即商详页的页面id是ProductDetail,用户每次打开商详页时会上报一条页面id为ProductDetail的数据,通过统计ProductDetail上报的次数就可以知道商品详情页被打开了多少次,这个ProductDetail就是一个埋点。同理,用AddCart标识加入购物车这个按钮,即加购这个点击事件的id是AddCart,用户每点击一次加入购物车按钮都会上报事件id为AddCart的数据,通过统计AddCard的上报次数就可以知道加购按钮被点击了多少次,这个AddCart就是一个埋点。
2.埋点分类
根据用户的行为,可将埋点分为点击埋点、PV(即page view,页面浏览)埋点、曝光埋点和订单埋点等类型;根据埋点所在的平台可以将埋点分为APP原生埋点、M端埋点、PC端埋点、小程序埋点等类型。
按 行 为 分 类 { 点 击 埋 点 P V ( 浏 览 ) 埋 点 曝 光 埋 点 订 单 埋 点 按行为分类\left\{ \begin{aligned} 点击埋点 \\ PV(浏览)埋点\\ 曝光埋点\\ 订单埋点 \end{aligned} \right. 按行为分类⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧点击埋点PV(浏览)埋点曝光埋点订单埋点
- 点击埋点:标记页面中的某一坑位,一般在用户触发点击行为时上报,用于采集用户的点击数据;
- PV埋点:标记某个页面,一般在页面加载完成时上报,用于采集用户浏览页面的访问数据;
- 曝光埋点:标记页面中的某些区域,一般是所标记区域在屏幕中展示时进行上报,用于采集某一区域在屏幕中展示的数据即某一区域被用户浏览的数据;
- 订单埋点:标记用户产生的订单,通常在订单产生(订单号生成)时进行上报,用于统计订单相关数据。
按 平 台 分 类 { A P P 原 生 埋 点 M 端 埋 点 P C 埋 点 小 程 序 埋 点 按平台分类\left\{ \begin{aligned} APP原生埋点 \\ M端埋点\\ PC埋点\\ 小程序埋点\\ \end{aligned} \right. 按平台分类⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧APP原生埋点M端埋点PC埋点小程序埋点
- APP原生埋点:指APP端原生页面上的埋点,此类埋点数据使用SDK采集,埋点更新需要依赖APP的发版;
- M端埋点:指移动设备浏览器中打开的H5页面上的埋点,包括APP中内嵌的H5页面,此类埋点数据使用JS代码采集,埋点的更新不依赖发版,可随时更新;
- PC埋点:指PC端网页上的埋点,此类埋点数据使用JS代码采集,埋点的更新不依赖发发版,可随时更新;
- 小程序埋点:指微信小程序、百度小程序等小程序页面上的埋点,小程序也有原生页面和H5页面之分,一般采用JS代码采集埋点数据。
3.埋点参数
大数据时代,用户产生的行为数据是复杂的,仅通过埋点上报对应页面、坑位或区域标识的数据已无法满足分析的需要。因此,在埋点上报的过程中还需要附带一些多维度的属性参数以满足个性化的数据分析需求。如PV埋点ProductDetail标识商品详情页,用于统计商详的访问情况,但这仅是对于商详页总访问量的统计,而商品种类繁多,每种商品都会有商详页,要统计特定种类商品的商详页访问情况仅靠统一的商详标识是无法实现的,这时候就需要在PV埋点上报时增加一个商品sku的属性参数上报,这样就可以通过参数(sku)来识别该商详页具体是哪个商品。同理,如果页面某个广告位是算法推荐的即千人千面,不同用户展示的广告不同,那么这个坑位的点击埋点即点击位标识也只能统计到这个坑位总体的点击数据,无法统计不同广告下分别的点击数据,因此该点击埋点也需要上报一个跟广告内容有关的广告id属性参数,用以统计不同广告下这个坑位的点击数据。
在实际业务中,数据分析需求多种多样,应用场景也相当丰富。因此,每个埋点都会上报很多参数,参数按照json形式上报,其大致可以分为公共参数和自定义参数两个部分。顾名思义,公共参数是所有埋点都会上报的通用参数,如用户唯一标识(uid)、用户账号(pin)、上报时间(report_ts)、平台(osp)等等;自定义参数是每个埋点单独设计的,其他埋点是否需要根据具体情况,如商品sku(skuid)、渠道号(source)、分类(sort)、关键词(keyword)等等。
以商详页的PV埋点和商详页中加购按钮的点击埋点数据上报为例,简化后的数据如下,其中“data”中的数据eventid和pageid就是对应坑位和页面的标识,即所谓的点击埋点和PV埋点,eventparam是点击埋点上报的自定义参数,pageparam是PV埋点上报的自定义参数,data之外的数据uid、pin、report_ts、osp则是所有埋点都会上报的公共参数。
商详页PV埋点上报数据
{
"uid":"***",
"pin":"***",
"report_ts":"1603163223211",
"osp":"iphone",
"data":{
"pageid":"ProductDetail",
"pageparam":"skuid_source_sort_keyword"
}
}
商详页中加购按钮的点击埋点上报数据
{
"uid":"***",
"pin":"***",
"report_ts":"1603163223211",
"osp":"iphone",
"data":{
"eventid":"AddCart",
"eventparam":"skuid_source_sort_keyword"
}
}
4.抓包工具
埋点抓包即检测埋点上报的数据是否准确。埋点开发完成后需要进行埋点测试,以确保上报的数据准确无误。由于埋点数据的上报是通过http请求将数据传输至服务器,因此可通过web代理工具监视数据传输过程,获取传输过程中的数据,进而对上报数据进行检测。比较常用的web代理工具有Fiddler和Whistle。另外,网页自带的开发者工具(F12)也可以监视http请求,也可以用来检测埋点数据。
有的公司为了提高测试童鞋的工作效率,同时也为了便于非技术出生的产品童鞋进行抓包工作,会自研一些抓包工具,这些自研的抓包工具一般门槛较低,容易上手。
埋 点 抓 包 工 具 { F i d d l e r W h i s t l e F 12 开 发 者 工 具 企 业 自 研 的 抓 包 工 具 埋点抓包工具\left\{ \begin{aligned} Fiddler\\ Whistle\\ F12开发者工具 \\ 企业自研的抓包工具 \\ \end{aligned} \right. 埋点抓包工具⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧FiddlerWhistleF12开发者工具企业自研的抓包工具
二、数据上报
1.上报流程
获取用户行为数据的第一步是搭建埋点上报机制。首先,埋点产品童鞋根据数据需求对需要监控用户行为的页面和坑位制定合理的埋点方案,即定义好各页面、坑位等的标识和参数。然后研发按照埋点方案在对应页面和坑位的源代码中植入相应的埋点(标识)并制定好上报时机,如PV埋点一般在页面加载完成时上报埋点数据、点击埋点一般在用户触发点击动作时上报埋点数据等。当用户与对应页面发生交互触发埋点上报机制时,埋点数据就会按照设定好的规则上报至服务器,如用户打开了商详页(页面标识为ProductDetail),当商详页加载完成时会上报一条PV埋点,即上报pageid=ProductDetail以及相关参数至服务器,又如用户在商详页点击了加购按钮(坑位标识是AddCart),则会上报一条点击埋点,即上报eventid=AddCart以及相关参数至服务器。埋点上报的简易流程图如下:
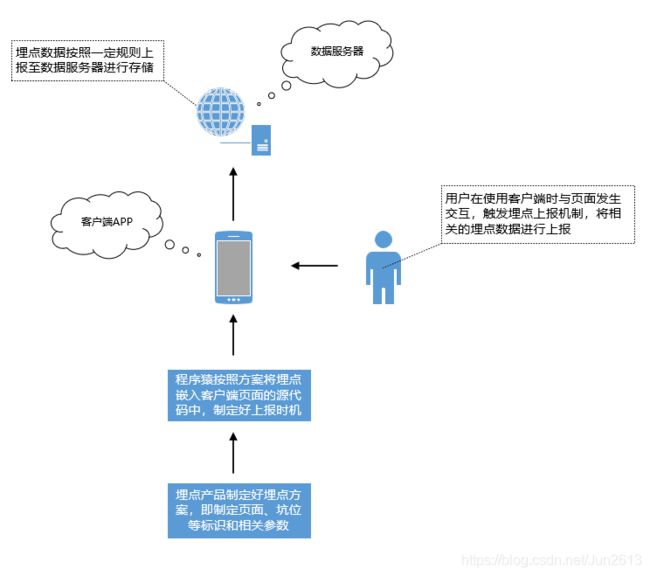
2.上报策略
用户触发埋点上报时其数据并非完全是实时上报至服务器,不同情况下有不同的上报策略。由于不同的网络状态(2G、3G、4G、wifi等)对数据传输影响较大,并且当用户访问量较大时,实时传输数据会使服务器接收数据上报请求的压力过大。因此,需要根据不同的情况制定不同的上报策略,一般有实时上报和本地存储再上报两种方式。
通常情况下,客户端APP是用户与页面交互的主要阵地,其流量较大,因此对于客户端原生的埋点数据会采取本地存储再上报的方式,一般是将产生的埋点数据缓存在手机自带的sqlite数据库,在满足设定的条件后将数据打包统一上报至服务器,数据发送成功后再删除本地sqlite数据库中的数据。原生埋点数据是通过嵌入在APP中的SDK(Software Development Kit)进行上报的,SDK会包含不同的上报策略,常见的有缓存满足一定条数或者缓存达到一定时间上报数据等。如设定的策略是满足30条上报即本地数据库缓存的埋点数据达到30条则将这30条数据一并打包上报至服务器;若设定的策略是30秒上报即每30秒打包上报一次数据库中缓存的埋点数据。而对于移动端浏览器访问的H5页面埋点即M端埋点,由于其访问量相对不大,埋点数据通常采用实时上报的方式,即产生的数据不经过本地存储直接上报至服务器。
本地存储再上报和实时上报两者的区别在于数据的延迟性。本地存储再上报数据会存在延迟性,即用户与页面交互触发埋点上报的时间和服务器接收埋点数据的时间存在一个时间差,这是因为埋点数据经过本地缓存满足一定条件后再上报,期间需要一定的时间。而实时上报则不存在数据的延迟,因其埋点数据实时上报,数据上报的时间和服务器接收数据的时间是一致的(数据传输耗时可忽略)。
3.数据存储
前面已经提到,埋点数据的上报是通过http请求实现的。当用户与页面交互触发埋点上报机制后会发起http请求,将预先设置好的数据或者后端下发的数据上报至服务器,服务器对上报过来的数据进行解析并根据不同的类型(点击、PV、曝光等)进行分类存储,通常是以日志文件的形式进行存储,即"以文件形式存储在服务器的文件夹"中。埋点数据以http的Post请求上报数据,当然http的Get请求也可以上报数据。Post请求是将埋点数据置于http包的body中,向服务器发送请求时将body中的数据传递给服务器;Get请求是将需要传输的数据置于url的参数中即ur问号之后的部分中,多个数据之间一般用&拼接,如https://www.baidu.com?info1&info2,这里的info1和info2就是向服务器传输的数据。需要注意的是,由于Get请求发送的数据放在url中,而url可以被很直观的看到,如果页面可以被缓存或者机器可以被别人使用,那么url中的信息就很容易泄露,因此Get请求传输数据会存在安全问题。而Post则相对安全(也存在安全问题,但比Get好),Post请求传输的数据不会被直观看到,一般需要抓包才能获取,通过对Post传输的数据进行加密、压缩,其安全性有一定的保障。此外,Get请求传输的数据大小一般会有限制,而Post传输数据的大小一般无限制,因此通常采用http协议的Post请求来传输埋点数据。以下示意图展示了用户与页面交互产生的点击、浏览等埋点数据的流向,服务器接收数据后会对不同类型(点击、PV、曝光等)的埋点数据进行分类存储。
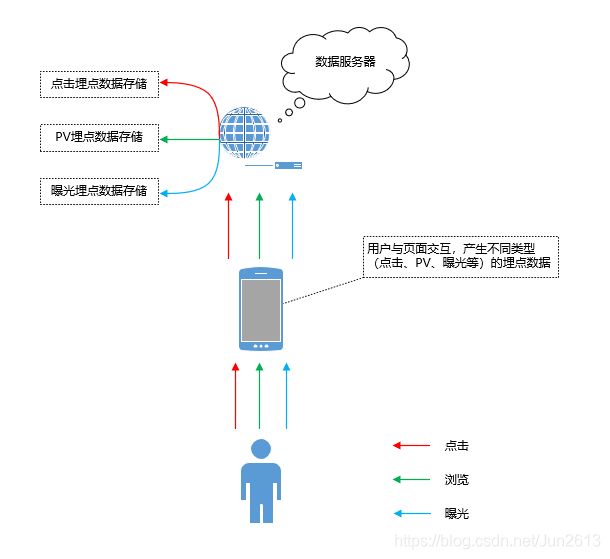
三、数据消费
数据采集的最终目的是为了分析,从而指导产品迭代和业务发展。因此数据上报至服务器后紧接着就是消费这些数据,也就是对上报至服务器的数据进行加工,使之成为可供分析和使用的数据。
数据消费分为两类,一类是离线消费,一般是按照某个固定周期消费数据。如常见的按天消费,任务一般在凌晨进行,然后将消费的数据落成离线表,离线表的最新分区是昨天,因此这类数据的使用方所能查询到的最新数据是前一天的,即今天的数据明天才能在表中查到。另一类是实时消费,该类任务会实时消费上报至服务器的数据,及时生成可供使用的数据指标,该类数据的使用方可得到实时的用户行为数据,即数据上报到服务器之后即可被使用。当然,实时数据消费在数据的产生和最终使用之间也会存在一定的时间差,主要是数据上报的延迟和任务执行耗时导致的,这个时间差一般不长,实力雄厚的企业可以控制在秒级。
1.离线消费
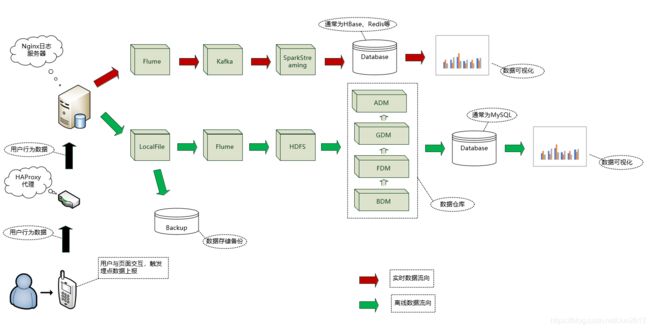
当用户触发埋点上报机制时会向数据服务器发起http请求,经过代理服务器(负载均衡)将数据传输出日志服务器。上报的数据存储至本地文件后会进行备份和抽取两个步骤。数据备份是为了避免数据永久丢失,而数据的抽取是将数据写入HDFS,后同步至数据仓库中。数据同步至数仓之前会经过ETL,即抽取、转换、加载的过程。
数据仓库一般为四层结构,不同公司在命名和设计上有所区别。以某大型电商的数仓为例,数据仓库分为缓冲数据层(BDM)、基础数据层(FDM)、通用数据层(GDM)和聚合数据层(ADM)。数据加载进数据仓库首先经过缓冲数据层,该层是源业务系统数据的快照,保存细节数据,一般情况下每个BDM表对应着源业务系统的一个表或者一个日志文件,数据结构与线上基本是对应的。基础数据层(FDM)用来保存源业务系统数据的快照,数据永久保存。通用数据层(GDM)是根据业务主题按照星型或雪花模型设计的最细业务粒度汇总层,这一层需要进行指标与维度的标准化,保证指标数据的唯一性。聚合数据层(ADM)是根据不同业务需求采用星型或雪花模型设计构建的按维度汇总的数据。内部分析同学常用的表大多数是通用数据层(GDM)和聚合数据层(ADM)的表。
数据可视化操作是建立在数据仓库基础上的,一般是将数据仓库中的数据提前导入MySQL数据库,然后利用MySQL数据库中的数据建立可视化数据看板。此是因为数据仓库中的表一般较大,SQL的执行效率偏低,跑数耗时较长。因此提前将可视化所需的指标数据从数据仓库中取出同步到MySQL数据库相应的表中,再利用MySQL数据库中的指标数据建立可视化数据看板,可极大提高数据展示的效率。
2.实时消费
用户行为数据的离线消费不能满足实时分析的需求,如直播间的实时访问人数、电商大促期间实时的GMV数据等,这些都是需要看到实时数据的。因此用户行为数据上报至服务器后的另一条消费路径就是实时消费。
数据经代理服务器上报至日志服务器后由Flume实时采集并写入Kafka,经Kafka分发至SparkStreaming,然后将处理后的实时数据导入Hbase、Redis等数据库为后续实时数据分析提供相应的指标数据。
埋点数据即用户行为数据的完整链路如下图:
用户行为数据采集是一项浩大的工程,其中每一个环节细分下来都可以形成一个岗位,如数据产品、前端研发、服务端研发、大数据工程师、数据分析师等。本文仅就个人学习所得浅析了用户行为数据的整条链路,如有问题,欢迎交流指正~