API文档搜索引擎
导航小助手
一、认识搜索引擎
二、项目目标
三、模块划分
四、创建项目
五、关于分词
六、实现索引模块
6.1 实现 Parser类
6.2 实现 Index类
6.2.1 创建 Index类
6.2.2 创建DocInfo类
6.2.3 创建 Weight类
6.2.4 实现 getDocInfo 和 getInverted方法
6.2.5 实现 addDoc方法
6.2.6 实现save方法
6.2.7 实现 load方法
6.3 在 Parser 中调用 Index
6.3.1 新增 Index实例
6.3.2 修改 parseHTML方法
6.3.3 新增save方法的调用
6.4 验证索引模块
6.5 优化制作索引速度
七、实现搜索模块
7.1 创建 DocSearcher类
7.1.1 创建 Result类
7.1.2 实现 search方法
7.1.3 验证 DocSearcher类
7.1.4 修改 Parser类
八、实现Web模块
一、认识搜索引擎
关于搜索引擎,平时的时候都是用的比较多,如:百度、搜狗、谷歌等搜索引擎,但是并没有仔细的观察过~
以搜狗搜索为例,我们打开搜狗搜索,就会发现,有一个搜索主页,并且有一个搜索框,我们可以在搜索框中搜索 想要知道的内容,点击 搜索,就可以查找搜索结果的页面~

搜索引擎 的核心功能,就是查找到 一组和用户输入的查询词(或者是一句话),所相关联的网页~
通过观察可以发现,对于每一条搜索结果,都会显示该搜索结果的 标题、描述、展示url等属性(虽然有的结果样式上可能会更复杂,但是还是会有 标题、描述、展示url属性),当我们点击一条搜索记录的时候,就跳转到相应的页面(称之为 落地页)~
搜索引擎的核心实现思路:
搜索引擎的核心目的是:在很多很多的网页中 找到和查询词相关联的内容~
那么,对于一个搜索引擎来说,首先需要获取到很多的网页,然后再根据用户输入的查询词,在这些网页中进行查找~
这就涉及到了几个问题:
- 搜索引擎的网页是怎么获取到的(此处主要是涉及到 "爬虫" 程序,此处不过多介绍)
- 用户输入查询词之后,如何让查询词和当前的这些网页进行匹配呢(这个是重点)
假设 当前已经爬取到了 1亿 个网页(html文件),用户输入了一个 "蛋糕"查询词,此时如果使用的是 "暴力搜索"的话,那么就需要把 "蛋糕"这个字符串 在这1亿个网页里面进行查找,那肯定是效率很低的(特别是对于搜索引擎来说,我们都希望 再进行搜索之后,会立刻出现我们所要查找的结果)~
因此为了更加高效的解决这个问题,大佬们专门设计了一种特殊的数据结构 —— 倒排索引~
需要知道的知识:
举个例子:
在日常的生活中,我们也会有所体会(就比如说在 玩王者荣耀的时候):


![]()
二、项目目标
像搜索引擎这样的程序,是一个很复杂的程序,很难做出像百度、搜狗一样的规模庞大的搜索引擎,所以可以简化一下目标:可以做一个针对 Java API文档的搜索引擎~

通过观察可以发现,官方文档上面并没有一个搜索框,所以想要去查找某个类,但又不知道这个类在哪个包里,就会显得很麻烦~
因此就可以实现这样一个站内搜索引擎,让用户输入一些查询词,之后就可以找到相关的文档页面~
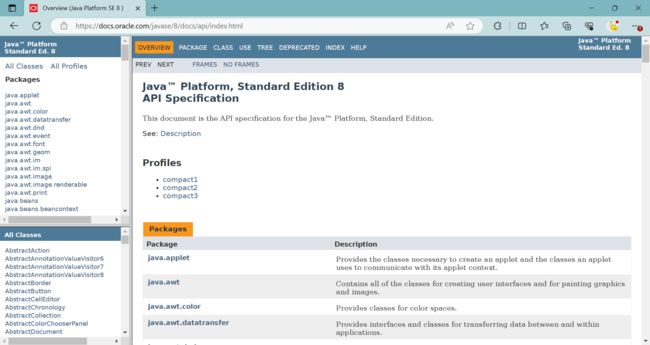
获取Java文档:
要想实现这个项目,首先就需要把相关的网页文档给获取到,然后才可以继续接下来的过程~
相关网页在 oracle官方网站上面,想要把上面所有的页面获取到,并不是一件很容易的事情~
虽然说,可以通过 "爬虫"技术,把这些文档获取到,但是 "爬虫"技术 还没有学到(听说 实现"爬虫"程序 会存在法律风险的),所以就暂时放弃这个方法~
针对于 Java API文档 来说,还有更加简单的方法 —— 可以直接从官网上直接下载,因此就不必通过爬虫来实现~
Java API文档 线上版本:https://docs.oracle.com/javase/8/docs/api/index.html
Java API文档 线下版本 下载地址:https://www.oracle.com/java/technologies/downloads/

![]()
三、模块划分
1)索引模块
- 扫描下载到的文档,分析文档内容,构建出 正排索引+倒排索引,并且把索引内容保存到文件中~
- 加载制作好的索引,并提供一些API实现查正排和查倒排这样的功能~
2)搜索模块
- 调用索引模块,实现一个搜索的完整过程~
- 输入:用户的查询词;输出:完整的搜索结果(包含了很多条记录,每个记录有 标题、描述、展示url,并且点击可以跳转)~
3)Web模块
- 需要实现一个简单的 web程序,能够通过网页的形式和用户进行交互~
![]()
四、创建项目
![]()
五、关于分词
用户在搜索引擎中,输入的查询词,不一定真的只是一个词,也有可能是一句话:

由上面的搜索结果我们可以知道,先针对完整的句子进行分词,然后根据每个词的分词结果,分别找到相关的文档~
针对 "分词"操作,人是非常容易完成的;但是对于机器来说,这就困难很多;英文的话还好,有空格就可以了,但是中文博大精深,额,就非常的哇塞了~
比如说,"我一把把车把把住","小龙女也想过过过儿过过的生活","下雨天留客天留我不留" ~
好在,我们要想实现这个分词效果,就可以基于一些现成的第三方库,从而实现分词效果~
分词实现原理
虽然说,我们现在使用的是第三方库,并不是自己实现分词逻辑,但是还是需要了解一下 分词的原理~
第一种情况:基于词库!
以汉语为例,虽然说,汉字很多,但是仍然是可以尝试着把所有的词都穷举在一本词典文件中,然后就可以依次的取句子中的内容:如:每隔一个字,就在词典里查一下;每隔两个字,查一下;......
但是,这并不能把所有的词都穷举出来,而且 随着时间的推移,也会产生越来越多的新词,......,关是基于词库,并不能分出所有的词~
第二种情况:基于统计!
利用这种方法,收集很多很多的 "语料库"(如:现有的一些文章、资料等等),接着就可以进一步进行人工标注/或者是直接统计,接着就进一步的知道了哪些词 成词的情况比较高(就类似于根据用户的习惯)~
分词的实现,就是属于 "人工智能" 典型应用的场景 ~
使用第三方库:
在Java中可以实现分词的第三方库 也是有很多的,在这里我们可以使用 ansj分词库~
org.ansj
ansj_seg
5.1.6
示例:
public static void main(String[] args) {
//准备一个比较长的话,用来分词(中文分词)
String str1 = "人终将被少年不可得之物困其一生,但也终会因一事一景解开一生困惑";
List terms1 = ToAnalysis.parse(str1).getTerms();
for (Term term1 : terms1) {
System.out.print(term1.getName() + '/');
}
System.out.println();
//英文分词(会把大写字母转换成小写字母)
String str2 = "I have a dream!";
List terms2 = ToAnalysis.parse(str2).getTerms();
for (Term term2 : terms2) {
System.out.print(term2.getName() + ' ');
}
} 结果:

![]()
六、实现索引模块
6.1 实现 Parser类
创建一个Parser类,通过这个类来完成制作索引的过程~
Parser:读取之前下载好的离线文档,去解析文档的内容,并完成索引的制作!
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
public class Parser {
//指定加载文档的路径
private static final String INPUT_PATH = "E:/doc_searcher_index/jdk-8u361-docs-all/docs/api/";
private void run() {
//整个Parser类的入口
//1、根据上面指定的路径,枚举出该路径中所有的 html文件(包括子目录中的文件)
//2、针对上面罗列出文件的路径,打开文件,读取文件内容,并进行解析,并构建索引
//3、todo 把在内存中构造好的索引数据结构,保存到指定的文件中
ArrayList fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
/**
* System.out.println(fileList);
* System.out.println(fileList.size());
*/
for (File f:fileList) {
//通过parseHTML()方法解析 .html文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
}
/**
* 解析 .html文件 的方法
* @param f
*/
private void parseHTML(File f) {
//解析 标题
String title = parseTitle(f);
//解析 url
String url = parseUrl(f);
//解析 对应的正文(描述 是正文的一小部分,先解析出来正文,然后才可以获取到 描述)
String content = parseContent(f);
//todo 把解析出来的这些信息,加入到索引当中
}
/**
* 通过观察,可以发现,在 .html文件中,标签 里面的就是标题
* 进一步可以发现,.html文件名 就是该文件的标题
*/
private String parseTitle(File f) {
return f.getName().substring(0,f.getName().length() - ".html".length());
}
/**
* url 是在线文档对应的链接
*/
private String parseUrl(File f) {
//先获取到固定的前缀
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
//后获取 线下文档api后面的部分
String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());
return part1 + part2;
}
/**
* 一个完整的 .html文件,里面有的是 <html>标签 + 内容
* 所以 解析正文的核心工作是:去掉 <html>标签,只剩下 内容
*/
public String parseContent(File f) {
//先按照一个字符一个字符的方式来读取( < 和 > 来控制拷贝数据的开关)
try( FileReader fileReader = new FileReader(f)) {
//加上一个开关:true拷贝,false不拷贝
boolean isCopy = true;
//加上一个保存结果的stringBuilder
StringBuilder stringBuilder = new StringBuilder();
while (true) {
//read()返回值是 int,而不是 char
//主要是为了表示一些非法情况,文件读完了,返回-1
int ret = fileReader.read();
if (ret == -1) {
break;
}
//如果结果不是-1,那就是合法的字符
char c = (char) ret;
if (isCopy) {
//开关打开,遇到普通字符就拷贝到 StringBuilder中
if (c == '<') {
//关闭开关
isCopy = false;
continue;
}
//去掉 .html文件当中的换行,不然实在是不好看
if (c == '\n' || c == '\r') {
//把换行替换成空格
c = ' ';
}
//其他字符,直接拷贝
stringBuilder.append(c);
}else {
//开关不拷贝,直到遇到 >
if (c == '>') {
isCopy = true;
}
}
}
return stringBuilder.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
/**
*
* @param inputPath 表示从哪个目录开始进行递归遍历
* @param fileList 表示递归所得到的结果
*/
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles(); //listFiles()方法,获取到rootPath目录下的路径名(仅仅只能看到一层内容)
//使用递归,看见所有子目录下面的内容
for (File f:files) {
//根据f类型,来决定是否需要递归
if (f.isDirectory()) {
//f 是一个目录,递归调用enumFile()方法,进一步获取子目录的内容
enumFile(f.getAbsolutePath(),fileList);
}else {
//f 是一个普通文件,加入到 fileList中
//在此处排除非.html文件(以.html的文件才添加上去)
if (f.getAbsolutePath().endsWith(".html")) {
fileList.add(f);
}
}
}
}
public static void main(String[] args) {
//通过 main方法,实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
</code></pre>
<p>在Parser类当中,主要做的是,枚举出当前指定目录中的所有的 .html文档,通过递归函数 enumFile(INPUT_PATH,fileList) ,把所获取到的文档存储在 fileList里面;接下来就可以循环遍历这里的每一个文件,再针对文件进行解析,每一个文件都是一个 .html,解析 .html文件的 标题、描述、展示url ~</p>
<p>在解析好了这些信息,就可以把它们加入到索引数据结构当中;于是,就可以专门创建一个 Index类,来负责构建索引数据结构~</p>
<hr>
<h3 id="6.2%20%E5%AE%9E%E7%8E%B0%20Index%E7%B1%BB">6.2 实现 Index类</h3>
<h4 id="6.2.1%20%E5%88%9B%E5%BB%BA%20Index%E7%B1%BB">6.2.1 创建 Index类</h4>
<p>Index类 主要实现的功能有:</p>
<ul>
<li>正排索引</li>
<li>倒排索引</li>
<li>新增一个文档</li>
<li>保存索引文件</li>
<li>加载索引文件</li>
</ul>
<pre><code>import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
/**
* 通过这个类在内存中构造出索引结构
*/
public class Index {
//使用数组下标表示 docId(正排索引)
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
//使用 哈希表 来表示倒排索引(key是词,value是一组和这个词相关联的文章)
private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>();
//这个类所提供的方法
//1.正排索引:给定一个 docId,在正排索引中,可以查询到文档的详细信息
//2.倒排索引:给定一个词,在倒排索引中,查找那些文档和这个词有关联
//3.将前面所解析出来的信息添加进去,向索引当中新增一个文档
//4.把内存中的索引结构保存到磁盘中
//5.把磁盘中的索引数据加载到内存
//1.
public DocInfo getDocInfo(int docId) {
//todo
return null;
}
//2.
public List<Weight> getInverted(String term) {
//todo
return null;
}
//3.
public void addDoc(String title,String url,String content) {
//todo
}
//4.
public void save() {
//todo
}
//5.
public void load() {
//todo
}
}
</code></pre>
<hr>
<h4 id="6.2.2%20%E5%88%9B%E5%BB%BADocInfo%E7%B1%BB">6.2.2 创建DocInfo类</h4>
<p>DocInfo类主要表示的是:在正排索引中,根据 docId 所查询的文档的相关细节~</p>
<pre><code>/**
* 该类当中可以表示一个文档的相关细节
*/
public class DocInfo {
private int docId;
private String title;
private String url;
private String content;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
</code></pre>
<hr>
<h4 id="6.2.3%20%E5%88%9B%E5%BB%BA%20Weight%E7%B1%BB">6.2.3 创建 Weight类</h4>
<p>Weight类主要表示的是:在倒排索引中,文档id 和 文档与词的相关性 的权重~</p>
<pre><code>/**
* 这个类是把 文档id 和 文档与词的相关性 的权重 进行一个包裹
*/
public class Weight {
private int docId;
//weight表示 文档和词之间的"相关性",值越大,就说明 这个词和这个文档越有关的
private int weight;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
</code></pre>
<hr>
<h4 id="6.2.4%20%E5%AE%9E%E7%8E%B0%20getDocInfo%20%E5%92%8C%20getInverted%E6%96%B9%E6%B3%95">6.2.4 实现 getDocInfo 和 getInverted方法</h4>
<pre><code> //1.
public DocInfo getDocInfo(int docId) {
return forwardIndex.get(docId);
}
//2.
public List<Weight> getInverted(String term) {
return invertedIndex.get(term);
}</code></pre>
<hr>
<p></p>
<h4 id="6.2.5%20%E5%AE%9E%E7%8E%B0%20addDoc%E6%96%B9%E6%B3%95">6.2.5 实现 addDoc方法</h4>
<pre><code>//3.
public void addDoc(String title,String url,String content) {
//新增文档操作,需要给正排索引和倒排索引都新增
//构建正排索引
DocInfo docInfo = buildForward(title,url,content);
//构建倒排索引
buildInverted(docInfo);
}
private void buildInverted(DocInfo docInfo) {
//倒排索引,是词与文档id的映射关系
//就需要知道当前的文档,里面存在有哪些词,就需要实现"分词"
//就需要针对 标题、正文 进行分词,之后就可以根据分词的结果,知道当前的文档id 应该要加入到哪一个倒排索引的key里
//1.针对标题进行分词,遍历分词结果,统计每个词出现的次数
//2.针对正文进行分词,遍历分词结果,统计每个词出现的个数
//3.汇总到HashMap中,简单设置权重,权重=标题出现的次数*10 + 正文出现的次数
//4.遍历HashMap,依次更新倒排索引中的结构
class WordCount {
public int titleCount; //标题次数
public int contentCount;//正文次数
}
//用来统计词频的数据结构
HashMap<String,WordCount> wordCountHashMap = new HashMap<>();
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
for (Term term:terms) {
//先判定term 是否存在
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
if (wordCount == null) {
//不存在,创建一个新的键值对,插入进去,titleCount设为1
WordCount newWordCount = new WordCount();
newWordCount.titleCount = 1;
newWordCount.contentCount = 0;
wordCountHashMap.put(word,newWordCount);
}else {
//存在,找到之前的值,对应的 titleCount+1
wordCount.titleCount += 1;
}
}
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
for (Term term:terms) {
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
if (wordCount == null) {
WordCount newWordCount = new WordCount();
newWordCount.titleCount = 0;
newWordCount.contentCount = 1;
wordCountHashMap.put(word,newWordCount);
}else {
wordCount.contentCount += 1;
}
}
for (Map.Entry<String,WordCount> entry : wordCountHashMap.entrySet()) {
//先根据这里的词去倒排索引中查一查
List<Weight> invertedList = invertedIndex.get(entry.getKey()); //倒排拉链
if (invertedList == null) {
ArrayList<Weight> newInvertedList = new ArrayList<>();
//把新的文档(当前 DocInfo),构造成 Weight对象,插入进来
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数*10+正文中出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
//如果为空,就插入一个新的键值对
invertedIndex.put(entry.getKey(),newInvertedList);
}else {
//如果非空,就把这个文档,构造一个 Weight对象,插入到倒排拉链的后面
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数*10+正文中出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}</code></pre>
<h4 id="6.2.6%20%E5%AE%9E%E7%8E%B0save%E6%96%B9%E6%B3%95">6.2.6 实现save方法</h4>
<p>至于为什么要实现save方法呢其实原因也是很简单的:当前索引是存储在 内存 中,而构建索引的过程(即上面实现的addDoc方法),实际上是非常耗时间的,仅仅一个API就有上万份文档了,更别说其他的了~</p>
<p>因此我们不应该服务器启动的时候才构建索引(启动服务器就可能会被拖慢很多了),万一服务器在运行过程中又崩溃了,那又要重启服务器,那又要浪费更长的时间了~</p>
<p>通常的操作可以是:先把这些耗时的操作,单独的去执行;执行好了之后,再让线上服务器直接加载这个构造好的索引;此时,加载的速度就仅在读磁盘上面花费时间了~</p>
<p>至于具体该如何去保存到文件中呢?我们都知道,文件里保存的不是 二进制数据,就是文本数据;这就需要把内存中的索引结构 变成一个字符串(这个过程叫做 序列化),然后就可以直接写文件就可以了~</p>
<blockquote>
<p>类似的,把特定结构的字符串 按照一定的结构解析回来(类/对象/基础数据结构),我们就称之为 反序列化~</p>
</blockquote>
<p>其实,序列化和反序列化 ,都有许多现成的方法,此处可以使用JSON的格式,来完成 序列化和反序列化,就可以很轻松的完成保存和加载索引的操作了~</p>
<blockquote>
<p>此处使用JSON的格式,可以从中央仓库中引入 相关依赖:</p>
<pre><code><!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
</code></pre>
</blockquote>
<pre><code>//引入 jackson 里面的核心对象
private ObjectMapper objectMapper = new ObjectMapper();
//保存的地址
private static final String INDEX_PATH = "E:\\doc_searcher_index\\";</code></pre>
<p>由于涉及到两种索引,就可以分别使用两个文件 来保存正排索引和倒排索引~</p>
<pre><code> //4.
public void save() {
//序列化
//使用两个文件,分别保存正排和倒排
System.out.println("保存所以开始!");
//1.先判断索引对应的目录是否存在,不存在就创建
File indexPathFile = new File(INDEX_PATH);
if (!indexPathFile.exists()) {
indexPathFile.mkdirs();
}
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e) {
e.printStackTrace();
}
System.out.println("保存索引完成!");
}
</code></pre>
<p></p>
<h4 id="6.2.7%20%E5%AE%9E%E7%8E%B0%20load%E6%96%B9%E6%B3%95">6.2.7 实现 load方法</h4>
<pre><code> //5.
public void load() {
//反序列化
System.out.println("加载索引开始!");
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("加载索引结束!");
}</code></pre>
<blockquote>
<p>当然,由于索引中的文件可能会有很多,构造出来的索引数据也是比较大的,那么保存和加载到底会消耗多长时间呢?<strong>我们就可以修改一下 load和save方法</strong>,来衡量出它们的运行时间:</p>
<pre><code>//4.
public void save() {
//序列化
long beg = System.currentTimeMillis();
//使用两个文件,分别保存正排和倒排
System.out.println("保存索引开始!");
//1.先判断索引对应的目录是否存在,不存在就创建
File indexPathFile = new File(INDEX_PATH);
if (!indexPathFile.exists()) {
indexPathFile.mkdirs();
}
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索引完成!所消耗的时间是:" + ( end - beg ) + "ms");
}
//5.
public void load() {
//反序列化
long beg = System.currentTimeMillis();
System.out.println("加载索引开始!");
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束!消耗时间:" + ( end - beg ) + "ms");
}</code></pre>
</blockquote>
<p></p>
<h3 id="6.3%20%E5%9C%A8%20Parser%20%E4%B8%AD%E8%B0%83%E7%94%A8%20Index">6.3 在 Parser 中调用 Index</h3>
<p>当然,关于 Parser类 和 Index类 之间的关系 我们需要清楚:Parser类 就相当于是 制作索引的入口,通过 Parser类 中的 main方法,就可以把整个流程给跑起来;Index类 就相当于是实现了 索引的数据结构,并且提供了一些API供他人调用~</p>
<p>因此,Index类 需要给 Parser类 调用,才可以完成整个制作索引的过程~</p>
<p>这也是上面的曾经留下了 两个todo 需要做的事情:</p>
<p><a href="http://img.e-com-net.com/image/info8/1c8eb4ada603472999f648bddd9e5190.jpg" target="_blank"><img alt="API文档搜索引擎_第10张图片" height="123" src="http://img.e-com-net.com/image/info8/1c8eb4ada603472999f648bddd9e5190.jpg" width="650" style="border:1px solid black;"></a></p>
<h4 id="6.3.1%20%E6%96%B0%E5%A2%9E%20Index%E5%AE%9E%E4%BE%8B">6.3.1 新增 Index实例</h4>
<pre><code>public class Parser {
......
//创建一个 Index实例
private Index index = new Index();
......
}</code></pre>
<p></p>
<h4 id="6.3.2%20%E4%BF%AE%E6%94%B9%20parseHTML%E6%96%B9%E6%B3%95">6.3.2 修改 parseHTML方法</h4>
<p>新增 addDoc方法的调用</p>
<pre><code>private void parseHTML(File f) {
//解析 标题
String title = parseTitle(f);
//解析 url
String url = parseUrl(f);
//解析 对应的正文(描述 是正文的一小部分,先解析出来正文,然后才可以获取到 描述)
String content = parseContent(f);
//todo 把解析出来的这些信息,加入到索引当中[新增]
index.addDoc(title,url,content);
}</code></pre>
<p></p>
<h4 id="6.3.3%20%E6%96%B0%E5%A2%9Esave%E6%96%B9%E6%B3%95%E7%9A%84%E8%B0%83%E7%94%A8">6.3.3 新增save方法的调用</h4>
<pre><code> private void run() {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
//整个Parser类的入口
//1、根据上面指定的路径,枚举出该路径中所有的 html文件(包括子目录中的文件)
//2、针对上面罗列出文件的路径,打开文件,读取文件内容,并进行解析,并构建索引
//3、todo 把在内存中构造好的索引数据结构,保存到指定的文件中
long begEnumFile = System.currentTimeMillis();
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
long endEnumFile = System.currentTimeMillis();
System.out.println("枚举文件完毕!消耗时间:" + ( endEnumFile - begEnumFile ) + "ms");
/**
* System.out.println(fileList);
* System.out.println(fileList.size());
*/
long begFor = System.currentTimeMillis();
for (File f:fileList) {
//通过parseHTML()方法解析 .html文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
long endFor = System.currentTimeMillis();
System.out.println("循环遍历文件完毕!消耗时间:" + ( endFor - begFor ) + "ms");
//新增save方法的调用(好吧,其实也新增了一些时间戳)
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕!消耗时间:" + ( end - beg ) + "ms");
}</code></pre>
<p></p>
<h3 id="6.4%20%E9%AA%8C%E8%AF%81%E7%B4%A2%E5%BC%95%E6%A8%A1%E5%9D%97">6.4 验证索引模块</h3>
<p> 运行Parser类,观察运行结果:</p>
<p></p>
<p><a href="http://img.e-com-net.com/image/info8/664043d1197047c4abc21097edd4af54.jpg" target="_blank"><img alt="" height="74" src="http://img.e-com-net.com/image/info8/664043d1197047c4abc21097edd4af54.jpg" width="650"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/9acdce438ee94f48802c7b5a7ddc658e.jpg" target="_blank"><img alt="" height="68" src="http://img.e-com-net.com/image/info8/9acdce438ee94f48802c7b5a7ddc658e.jpg" width="650"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/bee2bda5cda643a7a2591d77c24c30f6.jpg" target="_blank"><img alt="" height="68" src="http://img.e-com-net.com/image/info8/bee2bda5cda643a7a2591d77c24c30f6.jpg" width="650"></a></p>
<p></p>
<h3 id="6.5%20%E4%BC%98%E5%8C%96%E5%88%B6%E4%BD%9C%E7%B4%A2%E5%BC%95%E9%80%9F%E5%BA%A6">6.5 优化制作索引速度</h3>
<p>关于性能优化,首先就需要通过 "测试的手段"(咳咳,通过一些时间戳 知道某一段程序运行所花费的时间),找到其中的 "性能瓶颈"~</p>
<p>通过结果发现,主要花费的时间(性能瓶颈) 就是在循环遍历文件 上面,每次遍历一个 .html文件,都需要进行 读文件+分词+解析内容 等操作(主要就是花费在CPU运算上面)~</p>
<p>在单个线程的情况下,这些任务都是串行执行的;因此,可以引进多线程,并发执行,优化速度(当然,需要通过加锁来完成线程安全)~</p>
<pre><code>//通过这个方法实现多线程制作索引
public void runByThread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
//1.枚举所有文件
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH,files);
//2.循环遍历文件(引入线程池)
CountDownLatch latch = new CountDownLatch(files.size());
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (File f:files) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析:" + f.getAbsolutePath());
parseHTML(f);
latch.countDown();
}
});
}
//await方法会阻塞,直到所有选手都调用countDown撞线,才会阻塞结束
latch.await();
executorService.shutdown(); //手动杀死线程池里面的线程
//3.保存索引
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕(多线程)!消耗时间:" + ( end - beg ) + "ms");
}</code></pre>
<p><strong>解决线程安全问题:</strong></p>
<pre><code> //创建两个锁对象
private Object locker1 = new Object();
private Object locker2 = new Object();</code></pre>
<p><strong>修改 buildForward方法:</strong></p>
<pre><code>private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (locker1) {
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}</code></pre>
<p><strong>修改 buildInverted方法:</strong></p>
<pre><code>private void buildInverted(DocInfo docInfo) {
......
for (Map.Entry<String,WordCount> entry : wordCountHashMap.entrySet()) {
//先根据这里的词去倒排索引中查一查
synchronized (locker2) {
......
}
}
}
</code></pre>
<p>在调用多线程的方法之后,我们就可以发现 制作索引的速度就快了很多:</p>
<p></p>
<hr>
<p><strong>一些其他的小问题:</strong></p>
<p>比如说,第一次制作索引的时候,它的制作速度会特别慢,在之后制作索引的时候,速度又会快很多;但把电脑关掉,再一次重启电脑,第一次制作索引的时候又变得慢很多,后面的时候速度又会快很多,这是为什么呢?</p>
<blockquote>
<p>分析:在代码中 核心操作还是在 循环遍历上面,循环遍历上面 又调用了 parseHTML方法,parseHTML方法中又调用了 parseContent方法,进行了读取文件的操作~</p>
<p>在计算机读取文件的时候,是一个开销比较大的操作~</p>
<p>我们就可以猜想:是不是开机之后,首次读取文件的时候 速度特别慢呢~</p>
<hr>
<p>实际上,是因为缓存的问题~</p>
<p>首次运行的时候,由于当前的这些 Java API 文档,没有在内存中进行缓存,因此读取的时候就只能从硬盘上进行读取(这是及其耗时的);后面再运行的时候,由于前面已经读取过文档了,即 在操作系统中其实已经有了一个缓存(在内存中),所以这次读取的就不是直接读硬盘,而是直接读内存的缓存(速度就会快很多)~</p>
<hr>
<p>当然,这也是可以进行优化的~</p>
<p>BufferedReader 和 FileReader 搭配着来使用,BufferedReader 内部会内置一个缓冲区,就可以自动的把 FileReader 中的一些内容预读到内存中,从而减少直接访问磁盘的次数~</p>
<p>虽然说,后面的运行程序 的时候操作系统已经做了缓存,此时运行速度也提高不了太多,但也好歹是优化了一点点~</p>
</blockquote>
<p><img alt="" src="http://img.e-com-net.com/image/info8/a575c4c38f6b41248878c29d078cd7c3.jpg" width="650" height="29"></p>
<h2 id="%E4%B8%83%E3%80%81%E5%AE%9E%E7%8E%B0%E6%90%9C%E7%B4%A2%E6%A8%A1%E5%9D%97">七、实现搜索模块</h2>
<p>搜索模块 主要是调用 索引模块,来完成搜索的核心过程!!!!!!</p>
<p>其中是可以包括:</p>
<ul>
<li>分词:针对用户输入的查询词,进行分词</li>
<li>触发:拿着每一个分词结果,去倒排索引当中找出具有相关性的文章(调用 Index类 里面查倒排的方法即可)</li>
<li> 排序:根据上面所触发出来的结果,根据相关性降序进行排序</li>
<li>包装结果:根据排序后的结果,依次去查正排,获取到每个文档的详细信息,包装成一定结构的数据返回出去</li>
</ul>
<hr>
<h3 id="7.1%20%E5%88%9B%E5%BB%BA%20DocSearcher%E7%B1%BB">7.1 创建 DocSearcher类</h3>
<pre><code>import java.util.List;
//通过这个类 来完成整个搜索模块的过程
public class DocSearcher {
//此处需要加上索引对象的实例,同时需要完成索引加载的工作
private Index index = new Index();
public DocSearcher() {
index.load();
}
/**
* 完成整个搜索过程的方法
* @param query 查询词
* @return 搜索结果的集合
*/
public List<Result> searcher(String query) {
//1.分词
//2.触发
//3.排序
//4.包装结果
return null;
}
}
</code></pre>
<hr>
<h4 id="7.1.1%20%E5%88%9B%E5%BB%BA%20Result%E7%B1%BB">7.1.1 创建 Result类</h4>
<pre><code>//这个类来表示一个搜索结果
public class Result {
private String title;
private String url;
private String desc; //描述(正文的一段摘要)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return "Result{" +
"title='" + title + '\'' +
", url='" + url + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
</code></pre>
<hr>
<h4 id="7.1.2%20%E5%AE%9E%E7%8E%B0%20search%E6%96%B9%E6%B3%95">7.1.2 实现 search方法</h4>
<pre><code>//通过这个类 来完成整个搜索模块的过程
public class DocSearcher {
//此处需要加上索引对象的实例,同时需要完成索引加载的工作
private Index index = new Index();
public DocSearcher() {
index.load();
}
/**
* 完成整个搜索过程的方法
* @param query 查询词
* @return 搜索结果的集合
*/
public List<Result> searcher(String query) {
//1.分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
//2.触发(/针对分词结果进行倒排查找)
List<Weight> allTermResult = new ArrayList<>();
for (Term term:terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明这个词在所有文档中不存在
continue;
}
allTermResult.addAll(invertedList);
}
//3.排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//如果是升序排序:return o1.getWeight() - o2.getWeight()
//如果是降序排序:return o2.getWeight() - o1.getWeight()
return o2.getWeight() - o1.getWeight();
}
});
//4.包装结果
List<Result> results = new ArrayList<>();
for (Weight weight:allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms)); //描述
results.add(result);
}
return results;
}
//生成描述信息
private String GenDesc(String content, List<Term> terms) {
//先遍历分词结果,看看结果是否在 content 中存在
//正文需要先转成小写(重要)
int firstPos = -1;
for (Term term:terms) {
String word = term.getName();
firstPos = content.toLowerCase().indexOf( " " + word + " ");
if (firstPos >= 0) {
//找到了位置
break;
}
}
if (firstPos == -1) {
//所有的分词结果不在正文中存在
//取正文的前 160 个字符作为描述
return content.substring(0,160) + "...";
}
//从 firstPos 作为基准位置,往前找60个字符,往后找100个字符
String desc = " ";
int descBeg = firstPos < 60 ? 0 : firstPos-60;
if (descBeg + 160 > content.length()) {
//descBeg 位置很靠后面了
desc = content.substring(descBeg);
} else {
desc = content.substring(descBeg,descBeg+160) + "...";
}
return desc;
}
}
</code></pre>
<blockquote>
<p>在包装结果生成描述的时候,需要注意的是:</p>
<ul>
<li>前面使用第三方库分词的结果 都是小写形式的,所以不可以直接对着内容进行比较,需要先转换成小写才可以</li>
<li>其实需要根据实际的情况,类似于 买了一份"老婆饼",并不可以送一个"老婆",我们搜索的时候,不能把两个单词由于差不多,就归结于相关性较强,所以在查找单词的时候,可以在前面和后面加上 " ",虽然可能会查询不到在最前面或者最后面,但这毕竟还是少数情况(当然,也可以使用正则表达式去解决这个问题)</li>
</ul>
</blockquote>
<p></p>
<hr>
<h4 id="7.1.3%20%E9%AA%8C%E8%AF%81%20DocSearcher%E7%B1%BB">7.1.3 验证 DocSearcher类</h4>
<p>验证 DocSearcher类</p>
<pre><code> public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("-> ");
String query = scanner.next();
List<Result> results = docSearcher.searcher(query);
for (Result result : results) {
System.out.println("====================================");
System.out.println(result);
}
}
}</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/d37905c2ee944502a04fa9f487f7341f.jpg" target="_blank"><img alt="API文档搜索引擎_第11张图片" height="194" src="http://img.e-com-net.com/image/info8/d37905c2ee944502a04fa9f487f7341f.jpg" width="650" style="border:1px solid black;"></a></p>
<p>我们观察结果可以发现,在有的查询结果中出现了下面的内容:</p>
<p><img alt="" height="19" src="http://img.e-com-net.com/image/info8/27438167c6c14ff8a54ed0201c349ff0.jpg" width="650"></p>
<p>其实,这个内容就是 JavaScript 的代码,由于在处理文档的时候,只是针对正文 进行了 "去标签",而有的 HTML 里面包含了 script标签,就导致了在去标签过后,JS的代码也被整理到索引里面了,所以查的时候就出现了这个情况~</p>
<p>而这种情况并不科学,因此还需要在后面去掉(可以使用正则表达式)~</p>
<p></p>
<hr>
<h4 id="7.1.4%20%E4%BF%AE%E6%94%B9%20Parser%E7%B1%BB">7.1.4 修改 Parser类</h4>
<p> 修改 Parser类(换成使用正则表达式来解决):</p>
<pre><code> /**
* 通过这个方法内部基于正则表达式,实现去除标签,以及 script的效果
*/
public String parseContentByRegex(File f) {
//1.先把这个文件都读到 String 里面
String content = readFile(f);
//2.替换script标签
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
//3.替换普通的 .html标签
content = content.replaceAll("<.*?>"," ");
return content;
}
private String readFile(File f) {
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))) {
StringBuilder content = new StringBuilder();
while (true) {
int ret = bufferedReader.read();
if (ret == -1) {
//读完了
break;
}
char c = (char) ret;
if (c == '\n' || c == '\r') {
c = ' ';
}
content.append(c);
}
return content.toString();
}catch (IOException e) {
e.printStackTrace();
}
return "";
}</code></pre>
<p>此时,就可以验证一下效果如何:</p>
<p></p>
<p><a href="http://img.e-com-net.com/image/info8/364b0729842f4bc2a4f8ba3a57c166fc.jpg" target="_blank"><img alt="" height="100" src="http://img.e-com-net.com/image/info8/364b0729842f4bc2a4f8ba3a57c166fc.jpg" width="650"></a></p>
<p>可是,新的看起来也不是很好看(原因是因为空格太多了),我们就可以把多个空格合并成一个即可(同样是使用正则表达式):</p>
<pre><code> //4.使用正则表达式,把多个空格合并成一个空格
content = content.replaceAll("\\s+"," ");</code></pre>
<p></p>
<p>所以在解析正文的时候,就可以使用正则的方式了~</p>
<p><img alt="" src="http://img.e-com-net.com/image/info8/a575c4c38f6b41248878c29d078cd7c3.jpg" width="650" height="29"></p>
<h2 id="%E5%85%AB%E3%80%81%E5%AE%9E%E7%8E%B0Web%E6%A8%A1%E5%9D%97">八、实现Web模块</h2>
<p>此时,搜索的核心功能都已经实现出来了,但是此时仍然需要提供一个Web接口,以网页的形式,把程序呈现给用户~</p>
<p>因为 此时的效果只能是在控制台中进行操作,此时对于普通用户来说 并不友好,此时如果想真正的搜索引擎一样,有一个搜索框,有一个搜索按钮......想必这样的界面对于用户来说更加的友好~</p>
<blockquote>
<p>要想实现这样的Web模块,需要约定一下前后端通信的接口,需要明确的描述出,服务器都能接受什么样的请求 ,都能返回什么样的响应的~</p>
<p>前端(HTML+CSS+JS)+ 后端(Java + Servlet/Spring相关)~</p>
<p>针对于这个项目,我们只需要实现一个 搜索接口 即可~</p>
<pre><code>//约定
//请求:
GET/searcher?query=[查询词] HTTP/1.1
//响应:
HTTP/1.1
[
{
title:"这是标题1",
url:"这是描述1",
desc:"这是描述1"
}
]
</code></pre>
</blockquote>
<hr>
<p>如果是使用 Servlet 来实现后端的接口的话,第一步需要引入相关的依赖的jar包~</p>
<pre><code> <!-- 引入 Servlet依赖 -->
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency></code></pre>
<p>创建 DocSearchServlet类,基于Servlet来实现后端</p>
<pre><code>//指定当前的路径 和哪个Servlet类对应
@WebServlet("/searcher")
public class DocSearchServlet extends HttpServlet {
//引入 DocSearcher实例,调用 searcher方法
private static DocSearcher docSearcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1.先解析请求,拿到用户所提交的查询词
String query = req.getParameter("query");
if (query == null || query.equals(" ")) {
//用户的参数是不科学的,一个没有key,一个有key没有value
String msg = "您的参数非法!没有获得query的值";
System.out.println(msg);
System.out.println();
resp.sendError(404,msg);
return;
}
//2.打印 记录 query的值
System.out.println("query=" + query);
//3.调用搜索模块,来进行一下搜索
List<Result> results = docSearcher.searcher(query);
//4.把当前的搜索结果进行打包
resp.setContentType("application/json;charset=utf-8");
objectMapper.writeValue(resp.getWriter(),results);
}
}
</code></pre>
<hr>
<p>嗯,最后剩下的就是实现前端页面的部分了,关于这一部分内容,就不细细展开了~</p>
<p><a href="http://img.e-com-net.com/image/info8/3078fcc825114a5ba19b052753731045.jpg" target="_blank"><img alt="API文档搜索引擎_第12张图片" height="227" src="http://img.e-com-net.com/image/info8/3078fcc825114a5ba19b052753731045.jpg" width="650" style="border:1px solid black;"></a></p>
<hr>
<p>而如果是使用 Spring Boot 来实现后端接口的话,那么可以这样做:</p>
<p>在 controller包下面,创建 DocSearcherController 类:</p>
<pre><code>@RestController
public class DocSearcherController {
private static DocSearcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@RequestMapping("/searcher")
public String search(@RequestParam("query") String query) throws JsonProcessingException {
//参数是查询词,返回值是响应内容
//参数来自于请求query string中的query这个key的值
List<Result> results = searcher.search(query);
return objectMapper.writeValueAsString(results);
}
}
</code></pre>
<p></p>
<hr>
<p>对了,由于在运行的时候,路径会发生错误,因为有两条路径:一条是云服务器上的路径,一条是本地路径~</p>
<p>那么想要在哪里运行的话,就需要去运行哪条路径~</p>
<p>所以,想要更加方便的运行,可以制作一个开关来切换路径~</p>
<p>虽然说在实际开发中不是这样子的,但是这个却是一个更加简单粗暴的方法:</p>
<pre><code>//创建一个Config类
public class Config {
// 这个变量为 true,表示在云服务器上运行,为 false,表示在本地运行
public static boolean isOnline = false;
}</code></pre>
<pre><code>//Index类底下
public class Index {
private static String INDEX_PATH = null;
static {
if (Config.isOnline) {
INDEX_PATH = "/root/java/doc_searcher_index/";
}else {
INDEX_PATH = "E:\\doc_searcher_index\\";
}
}
......
}</code></pre>
<pre><code>//DocSearcher类底下
public class DocSearcher {
//停用词表的路径
private static String STOP_WORD_PATH = null;
static {
if (Config.isOnline) {
STOP_WORD_PATH = "/root/java/doc_searcher_index/stop_word.txt";
}else {
STOP_WORD_PATH = "E:\\doc_searcher_index\\stop_word.txt";
}
}
......
}
</code></pre>
<p><img alt="" src="http://img.e-com-net.com/image/info8/a575c4c38f6b41248878c29d078cd7c3.jpg" width="650" height="29"></p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1705335782614577152"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(项目,搜索引擎)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1903465500550164480.htm"
title="探索安全的开发之路:Eclipse Steady深度揭秘" target="_blank">探索安全的开发之路:Eclipse Steady深度揭秘</a>
<span class="text-muted">尚竹兴</span>
<div>探索安全的开发之路:EclipseSteady深度揭秘steadyEclipseSteady:这是一个开源的持续集成和持续部署工具,用于自动化软件的开发和部署过程。它提供了一个基于Web的界面,用于创建和管理软件项目的构建和部署流程。适合用于需要自动化软件开发和部署的开发团队。特点包括简单易用、丰富的插件生态系统和与Maven和Jenkins的紧密集成。项目地址:https://gitcode.c</div>
</li>
<li><a href="/article/1903465501028315136.htm"
title="探索终端的新境界:Scurses与Onions框架深度揭秘" target="_blank">探索终端的新境界:Scurses与Onions框架深度揭秘</a>
<span class="text-muted">雷竹榕</span>
<div>探索终端的新境界:Scurses与Onions框架深度揭秘ScursesScurses,terminaldrawingAPIforScala,andOnions,aScursesframeworkforeasyterminalUI项目地址:https://gitcode.com/gh_mirrors/sc/Scurses在数字化的今天,终端不仅是命令行交互的简单界面,它成为了开发人员和系统管理员的</div>
</li>
<li><a href="/article/1903465373391450112.htm"
title="探索数据安全新境界:Apache Spark SQL Ranger Security插件深度揭秘" target="_blank">探索数据安全新境界:Apache Spark SQL Ranger Security插件深度揭秘</a>
<span class="text-muted">乌昱有Melanie</span>
<div>探索数据安全新境界:ApacheSparkSQLRangerSecurity插件深度揭秘项目地址:https://gitcode.com/gh_mirrors/sp/spark-ranger随着大数据的爆炸性增长,数据安全性成为了企业不可忽视的核心议题。在这一背景下,【ApacheSparkSQLRangerSecurityPlugin】以其强大的数据访问控制能力脱颖而出,成为数据处理领域的明星级</div>
</li>
<li><a href="/article/1903465373794103296.htm"
title="探索简明虚拟机新纪元 —— SSVM 深度揭秘与应用指南" target="_blank">探索简明虚拟机新纪元 —— SSVM 深度揭秘与应用指南</a>
<span class="text-muted">殷巧或</span>
<div>探索简明虚拟机新纪元——SSVM深度揭秘与应用指南SSVMJavaVMrunningonaJVM项目地址:https://gitcode.com/gh_mirrors/ssv/SSVM在当今软件开发的浩瀚宇宙中,一种名为SSVM(StupidlySimpleVM)的轻量级虚拟机正悄然兴起,承诺为开发者带来前所未有的灵活性与效率。本文将深入剖析SSVM的核心特性,探讨其技术实现,展示应用场景,并揭示</div>
</li>
<li><a href="/article/1903465247038042112.htm"
title="探索ELF世界的大门:JElf库深度揭秘" target="_blank">探索ELF世界的大门:JElf库深度揭秘</a>
<span class="text-muted">班歆韦Divine</span>
<div>探索ELF世界的大门:JElf库深度揭秘jelfELFparsinglibraryinjava.项目地址:https://gitcode.com/gh_mirrors/je/jelf在软件工程的浩瀚星空中,有一种文件格式如星辰般不可或缺,它便是ExecutableandLinkableFormat(ELF)——一个为Linux和Unix系统而生的传奇。今天,我们荣幸地向您介绍一款专为此格式设计的J</div>
</li>
<li><a href="/article/1903460585920589824.htm"
title="云原生周刊丨CIO 洞察:Kubernetes 解锁 AI 新纪元" target="_blank">云原生周刊丨CIO 洞察:Kubernetes 解锁 AI 新纪元</a>
<span class="text-muted">KubeSphere 云原生</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%91%E5%8E%9F%E7%94%9F/1.htm">云原生</a><a class="tag" taget="_blank" href="/search/kubernetes/1.htm">kubernetes</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>开源项目推荐DRANETDRANET是由谷歌开发的K8s网络驱动程序,利用K8s的动态资源分配(DRA)功能,为高吞吐量和低延迟应用提供高性能网络支持。它旨在优化资源管理,确保K8s集群中的网络资源能够按需高效分配。DRANET采用Apache-2.0开源许可,鼓励社区贡献与扩展,是云原生环境下提升网络性能的创新解决方案。LazyjournalLazyjournal是一个用Go语言编写的终端用户界</div>
</li>
<li><a href="/article/1903459830325112832.htm"
title="深入解析深度学习中的过拟合与欠拟合诊断、解决与工程实践" target="_blank">深入解析深度学习中的过拟合与欠拟合诊断、解决与工程实践</a>
<span class="text-muted">古月居GYH</span>
<a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>一、引言:模型泛化能力的核心挑战在深度学习模型开发中,欠拟合与过拟合是影响泛化能力的两个核心矛盾。据GoogleBrain研究统计,工业级深度学习项目中有63%的失败案例与这两个问题直接相关。本文将从基础概念到工程实践,系统解析其本质特征、诊断方法及解决方案,并辅以可复现的代码案例。二、核心概念与通熟易懂解释简单而言,欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在</div>
</li>
<li><a href="/article/1903457437302714368.htm"
title="git runner 配置_gitlab-ci配置详解(一)" target="_blank">git runner 配置_gitlab-ci配置详解(一)</a>
<span class="text-muted">夏天的sunnyrain</span>
<a class="tag" taget="_blank" href="/search/git/1.htm">git</a><a class="tag" taget="_blank" href="/search/runner/1.htm">runner</a><a class="tag" taget="_blank" href="/search/%E9%85%8D%E7%BD%AE/1.htm">配置</a>
<div>近期因为折腾gitlab-ci,专门去翻了很多文档,想想貌似自己挺傻的。按照官网教程本来biubiubiu就弄好了,非自己折腾了好几天,还没啥积累,真是作。想想唯一能积累的就是ci的配置详解了。该文基于最新版GitLabCommunityEdition10.1.1和GitLabRunner9.5.1-1使用.gitlab-ci.yml配置你的项目这篇文档描述了.gitlab-ci.yml的用法,本</div>
</li>
<li><a href="/article/1903456932681805824.htm"
title="vite项目中vite.config.js使用.env.development文件中的配置数据" target="_blank">vite项目中vite.config.js使用.env.development文件中的配置数据</a>
<span class="text-muted">初遇你时动了情</span>
<a class="tag" taget="_blank" href="/search/vite/1.htm">vite</a><a class="tag" taget="_blank" href="/search/react/1.htm">react</a><a class="tag" taget="_blank" href="/search/vue3/1.htm">vue3</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/ecmascript/1.htm">ecmascript</a><a class="tag" taget="_blank" href="/search/vite/1.htm">vite</a>
<div>如下图.env和vite.config.js配置同级目录loadEnv就可以获取.env配置信息import{defineConfig,loadEnv}from"vite";importreactfrom"@vitejs/plugin-react-swc";import{resolve}from"path";importvitePluginImpfrom"vite-plugin-imp";impo</div>
</li>
<li><a href="/article/1903450693495222272.htm"
title="01年实习生被曝负责字节RL核心算法!系字节LLM攻坚小组成员" target="_blank">01年实习生被曝负责字节RL核心算法!系字节LLM攻坚小组成员</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%AD%90%E4%BD%8D/1.htm">量子位</a>
<div>一个超越DeepSeekGRPO的关键RL算法出现了!用上该算法后,Qwen2.5-32B模型只经过RL训练,不引入蒸馏等其他技术,在AIME2024基准上拿下50分,优于相同setting下使用GRPO算法的DeepSeek-R1-Zero-Qwen,且DAPO使用的训练步数还减少了50%。这个算法名为DAPO,字节、清华AIR联合实验室SIALab出品,现已开源。论文通讯作者和开源项目负责人都</div>
</li>
<li><a href="/article/1903437142302978048.htm"
title="OpenHarmony 开源硬件学习全指南:从入门到实战" target="_blank">OpenHarmony 开源硬件学习全指南:从入门到实战</a>
<span class="text-muted">琢磨先生David</span>
<a class="tag" taget="_blank" href="/search/%E5%BC%80%E6%BA%90/1.htm">开源</a><a class="tag" taget="_blank" href="/search/harmonyos/1.htm">harmonyos</a>
<div>OpenHarmony开源硬件学习全指南:从入门到实战随着万物互联时代的到来,OpenHarmony作为面向全场景的开源分布式操作系统,正逐步成为智能硬件开发的重要技术底座。本文将系统性地解析OpenHarmony开源硬件的学习路径、开发工具链及行业实践方案,为开发者提供从环境搭建到项目落地的完整指引。一、构建开发环境:混合平台的智慧选择OpenHarmony采用Windows与Linux混合开发</div>
</li>
<li><a href="/article/1903432225215541248.htm"
title="医疗旅游发展方案" target="_blank">医疗旅游发展方案</a>
<span class="text-muted">cainiaojunshi</span>
<a class="tag" taget="_blank" href="/search/%E6%97%85%E6%B8%B8/1.htm">旅游</a><a class="tag" taget="_blank" href="/search/%E8%BD%AF%E4%BB%B6%E6%80%9D%E8%B7%AF/1.htm">软件思路</a><a class="tag" taget="_blank" href="/search/%E9%A2%84%E7%AE%97%E6%96%B9%E6%A1%88/1.htm">预算方案</a>
<div>一、策划目标在深入剖析医疗旅游市场环境的基础上,设计出针对中低端市场的医疗旅游产品,通过有效的冷启动推广策略,实现项目的初步盈利与客户积累,逐步树立专业品牌形象,建立客户信任机制,形成可复制、可规模化的商业模式。二、医疗旅游发展环境分析(一)费用对比以根管治疗为例,国内外费用差异显著。以下通过表格对比能更直观呈现:项目国内费用(人民币)国外(以美国为例)费用(人民币)根管治疗费用500-2000元</div>
</li>
<li><a href="/article/1903431595373686784.htm"
title="学习111" target="_blank">学习111</a>
<span class="text-muted">麋鹿叔叔</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a>
<div>项目名称项目简介主要功能技术原理GitHub地址browser-use智能浏览器工具,让AI像人类一样操作浏览器,实现网页自动化网页浏览与操作、多标签页管理、视觉识别与内容提取、操作记录与重复执行、自定义动作支持、主流LLM模型支持为大语言模型服务的创新Python工具库GitHubEkoFellouAI推出的生产就绪型JavaScript框架,基于自然语言驱动创建智能代理支持所有平台,提供统一便</div>
</li>
<li><a href="/article/1903426052324126720.htm"
title="python将网银web工程转换成客户端electron工程案例" target="_blank">python将网银web工程转换成客户端electron工程案例</a>
<span class="text-muted">银行金融科技</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/DeepSeek/1.htm">DeepSeek</a><a class="tag" taget="_blank" href="/search/electron/1.htm">electron</a>
<div>以下是一个将网银Web工程转换为Electron客户端的技术方案,结合Python和Electron实现桌面端增强功能:bash#项目结构webank-electron/├──main/#Electron主进程代码│├──main.js│└──python_server.py├──renderer/#网页渲染进程│└──webank-web/#原始网银Web工程├──package.json└──</div>
</li>
<li><a href="/article/1903422143832584192.htm"
title="cmake makefile cmakelists.txt的区别和联系" target="_blank">cmake makefile cmakelists.txt的区别和联系</a>
<span class="text-muted">YRr YRr</span>
<a class="tag" taget="_blank" href="/search/CMake/1.htm">CMake</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/cmake/1.htm">cmake</a>
<div>cmakemakefilecmakelists.txt的区别和联系理解CMake、Makefile和CMakeLists.txt的区别和联系,可以帮助我们更好地管理和构建C/C++项目。Makefile(GNUMake):定义与作用:Makefile是一种文本文件,通常用于指定如何编译和链接源代码以生成可执行文件或库文件。它包含了一系列规则(rules),每个规则指定了如何生成一个或多个目标文件(</div>
</li>
<li><a href="/article/1903417607227240448.htm"
title="每天分析一个开源项目:open_deep_research" target="_blank">每天分析一个开源项目:open_deep_research</a>
<span class="text-muted">申非zz</span>
<a class="tag" taget="_blank" href="/search/LLM/1.htm">LLM</a><a class="tag" taget="_blank" href="/search/github/1.htm">github</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E6%BA%90/1.htm">开源</a>
<div>每天分析一个开源项目:open_deep_research项目链接:langchain-ai/open_deep_research项目介绍项目功能:OpenDeepResearch是一个基于LangGraph的Web研究助手,旨在帮助用户快速生成特定主题的综合性报告。它模拟了OpenAI和Gemini的DeepResearch流程,但提供了更强的自定义能力,允许用户配置模型、Prompt、报告结构</div>
</li>
<li><a href="/article/1903414079305871360.htm"
title="Cursor + 向量数据 生产力的提升!!" target="_blank">Cursor + 向量数据 生产力的提升!!</a>
<span class="text-muted">AI Agent首席体验官</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/AI%E7%BC%96%E7%A8%8B/1.htm">AI编程</a><a class="tag" taget="_blank" href="/search/ai%E7%BC%96%E7%A8%8B/1.htm">ai编程</a>
<div>1.Cursor+向量数据库意味着什么?将Cursor与向量数据库结合意味着强化AI辅助编程的能力,主要体现在以下几个方面:代码理解与上下文感知:Cursor作为AI编程工具可以利用向量数据库存储代码片段、函数、类和项目结构的向量表示,使AI能更精确地理解代码上下文和关系。语义搜索能力:向量数据库使Cursor能够执行基于语义的代码搜索,而不仅仅是关键词匹配,开发者可以用自然语言描述需求,找到语义</div>
</li>
<li><a href="/article/1903413699578753024.htm"
title="GitHub项目推荐--基于LLM的开源爬虫项目" target="_blank">GitHub项目推荐--基于LLM的开源爬虫项目</a>
<span class="text-muted">惟贤箬溪</span>
<a class="tag" taget="_blank" href="/search/%E7%A9%B7%E7%8E%A9Ai/1.htm">穷玩Ai</a><a class="tag" taget="_blank" href="/search/github/1.htm">github</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a>
<div>以下是一些基于大语言模型(LLM,LargeLanguageModel)的开源爬虫项目,它们结合了自然语言处理(NLP)技术与爬虫的功能,能在一定程度上提升爬取的智能化和精度。这些项目可以用于自动化抓取、内容提取、数据分析等任务。1.GPT-3WebScraper简介:这是一个基于OpenAIGPT-3模型的网页抓取工具,利用GPT-3的自然语言理解能力来生成有用的爬虫策略、处理网页内容并提取有价</div>
</li>
<li><a href="/article/1903408779161038848.htm"
title="毕业论文代码实验(Python\MATLAB)基于K-means聚类的EMD-BiLSTM-Attention光伏功率预测模型" target="_blank">毕业论文代码实验(Python\MATLAB)基于K-means聚类的EMD-BiLSTM-Attention光伏功率预测模型</a>
<span class="text-muted">清风AI</span>
<a class="tag" taget="_blank" href="/search/%E6%AF%95%E4%B8%9A%E8%AE%BE%E8%AE%A1%E4%BB%A3%E7%A0%81%E5%AE%9E%E7%8E%B0/1.htm">毕业设计代码实现</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/lstm/1.htm">lstm</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/1.htm">神经网络</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/matlab/1.htm">matlab</a><a class="tag" taget="_blank" href="/search/pytorch/1.htm">pytorch</a>
<div>一、项目背景1.1光伏功率预测意义在能源结构转型背景下(国家能源局2025规划),光伏发电渗透率已超过18%。但受天气突变、云层遮挡等因素影响,光伏出力具有显著波动性,导致:电网调度难度增加(±15%功率波动)电力市场交易风险提升光储协同控制效率降低1.2技术挑战多尺度特征耦合:分钟级辐照度变化与小时级天气模式共存非线性映射关系:气象因素与发电功率呈高阶非线性关系数据模态差异:数值天气预报(NWP</div>
</li>
<li><a href="/article/1903407263658340352.htm"
title="《破局项目延期魔咒:构建全周期风险防控体系》" target="_blank">《破局项目延期魔咒:构建全周期风险防控体系》</a>
<span class="text-muted">玩转数据库管理工具FOR DBLENS</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E7%94%98%E7%89%B9%E5%9B%BE/1.htm">甘特图</a><a class="tag" taget="_blank" href="/search/%E9%A1%B9%E7%9B%AE%E7%AE%A1%E7%90%86/1.htm">项目管理</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93%E5%BC%80%E5%8F%91/1.htm">数据库开发</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>在数字化转型加速的今天,某权威机构调研数据显示:72%的IT项目存在延期交付问题,其中38%的项目实际周期超出计划50%以上。项目延期不仅造成资源浪费,更可能引发客户信任危机。当项目计划屡屡失控、风险频发时,管理者需要以系统化思维重构项目管理体系。一、项目延期的根源解构需求蔓延综合症某智能工厂项目在实施阶段新增327项需求变更,导致交付周期延长11个月隐性需求显性化过程中的认知偏差,形成"需求黑洞</div>
</li>
<li><a href="/article/1903407011526144000.htm"
title="同步MySQL数据至Elasticsearch:go-mysql-elasticsearch实战指南" target="_blank">同步MySQL数据至Elasticsearch:go-mysql-elasticsearch实战指南</a>
<span class="text-muted">吴镇业</span>
<div>同步MySQL数据至Elasticsearch:go-mysql-elasticsearch实战指南go-mysql-elasticsearchSyncMySQLdataintoelasticsearch项目地址:https://gitcode.com/gh_mirrors/go/go-mysql-elasticsearch项目介绍go-mysql-elasticsearch是一个服务,能够自动将</div>
</li>
<li><a href="/article/1903405997347631104.htm"
title="GStreamer —— 3.1、Qt+GStreamer制作多功能播放器,支持本地mp4文件、rtsp流、usb摄像头等(可跨平台,附源码)" target="_blank">GStreamer —— 3.1、Qt+GStreamer制作多功能播放器,支持本地mp4文件、rtsp流、usb摄像头等(可跨平台,附源码)</a>
<span class="text-muted">信必诺</span>
<a class="tag" taget="_blank" href="/search/GStreamer/1.htm">GStreamer</a><a class="tag" taget="_blank" href="/search/Qt/1.htm">Qt</a><a class="tag" taget="_blank" href="/search/GStreamer/1.htm">GStreamer</a><a class="tag" taget="_blank" href="/search/Qt/1.htm">Qt</a>
<div>运行效果 介绍 本项目基于Qt和GStreamer开发了一款多功能播放器,</div>
</li>
<li><a href="/article/1903405998836609024.htm"
title="GStreamer —— 3.2、Qt+GStreamer+OpenCV制作图像处理播放器(对每帧图像处理),支持本地mp4文件、rtsp流、usb摄像头等(可跨平台,附源码)" target="_blank">GStreamer —— 3.2、Qt+GStreamer+OpenCV制作图像处理播放器(对每帧图像处理),支持本地mp4文件、rtsp流、usb摄像头等(可跨平台,附源码)</a>
<span class="text-muted">信必诺</span>
<a class="tag" taget="_blank" href="/search/GStreamer/1.htm">GStreamer</a><a class="tag" taget="_blank" href="/search/Qt/1.htm">Qt</a><a class="tag" taget="_blank" href="/search/GStreamer/1.htm">GStreamer</a><a class="tag" taget="_blank" href="/search/Qt/1.htm">Qt</a>
<div>运行效果 介绍 本项目是一个结合了Qt、GStreamer和OpenCV的跨平台图像处理播放器项目。该</div>
</li>
<li><a href="/article/1903403601850593280.htm"
title="Maven简介" target="_blank">Maven简介</a>
<span class="text-muted">z迦在线</span>
<a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>Maven简介Maven是Apache软件基金会的一个开源项目,是一个优秀的项目构建工具,它用来帮助开发者管理项目中的jar,以及jar之间的依赖关系、完成项目的编译(.java--->.class)、测试、打包(源代码--->.jar文件)和发布等工作。Maven是如何管理项目中的jar文件的?Maven简化了Java项目中的JAR文件管理,主要通过以下几个关键点:POM文件:Maven使用po</div>
</li>
<li><a href="/article/1903402720526659584.htm"
title="将MySQL数据同步到Elasticsearch作为全文检索数据的实战指南" target="_blank">将MySQL数据同步到Elasticsearch作为全文检索数据的实战指南</a>
<span class="text-muted">格子先生Lab</span>
<a class="tag" taget="_blank" href="/search/%E5%85%A8%E6%96%87%E6%A3%80%E7%B4%A2/1.htm">全文检索</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/elasticsearch/1.htm">elasticsearch</a>
<div>在现代应用中,全文检索是一个非常重要的功能,尤其是在处理大量数据时。Elasticsearch是一个强大的分布式搜索引擎,能够快速地进行全文检索、分析和可视化。而MySQL作为传统的关系型数据库,虽然能够处理结构化数据,但在全文检索方面的性能不如Elasticsearch。因此,将MySQL中的数据同步到Elasticsearch中,可以充分发挥两者的优势。本文将介绍如何将MySQL中的数据同步到</div>
</li>
<li><a href="/article/1903394522579136512.htm"
title="DS918 -6.24-25556 引导+安装包:高效稳定的NAS系统解决方案" target="_blank">DS918 -6.24-25556 引导+安装包:高效稳定的NAS系统解决方案</a>
<span class="text-muted">咎尉裕Lilah</span>
<div>DS918-6.24-25556引导+安装包:高效稳定的NAS系统解决方案【下载地址】DS918-6.24-25556引导安装包本仓库提供的是DS918_6.24-25556引导+安装包,包含所有必要的配套资源。经过亲测,该安装包完全可用,适合需要安装或升级DS918系统的用户使用项目地址:https://gitcode.com/open-source-toolkit/5d54e项目介绍DS918</div>
</li>
<li><a href="/article/1903394396267671552.htm"
title="FastAPI 最佳架构项目推荐" target="_blank">FastAPI 最佳架构项目推荐</a>
<span class="text-muted">穆耀双</span>
<div>FastAPI最佳架构项目推荐fastapi_best_architectureFastAPIbasedontheconstructionofthefrontandbackoftheseparationofrightscontrolsystem,usingauniquepseudothree-tierarchitecturemodeldesign,andasatemplatelibraryfree</div>
</li>
<li><a href="/article/1903394269893292032.htm"
title="推荐开源项目:FastAPI Best Architecture — 极致的后端架构设计" target="_blank">推荐开源项目:FastAPI Best Architecture — 极致的后端架构设计</a>
<span class="text-muted">蓬玮剑</span>
<div>推荐开源项目:FastAPIBestArchitecture—极致的后端架构设计项目地址:https://gitcode.com/gh_mirrors/fa/fastapi_best_architecture项目简介在寻找一款基于FastAPI构建的强大且灵活的后端解决方案吗?那么,你已经找到了——FastAPIBestArchitecture。这是一个遵循前端与后端分离原则的中间件层解决方案,采</div>
</li>
<li><a href="/article/1903390488560463872.htm"
title="Python技术全景解析:从基础到前沿的深度探索" target="_blank">Python技术全景解析:从基础到前沿的深度探索</a>
<span class="text-muted">靠近彗星</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96/1.htm">性能优化</a><a class="tag" taget="_blank" href="/search/%E4%B8%AA%E4%BA%BA%E5%BC%80%E5%8F%91/1.htm">个人开发</a><a class="tag" taget="_blank" href="/search/%E6%9E%81%E9%99%90%E7%BC%96%E7%A8%8B/1.htm">极限编程</a>
<div>目录一、Python为何成为开发者首选?1.核心优势矩阵2.性能进化史二、Python核心应用领域1.数据科学黄金三角2.AI开发新范式三、现代Python进阶技巧1.类型提示革命2.异步编程实战四、Python工程化实践1.现代项目架构2.性能优化矩阵五、Python未来生态展望1.前沿技术融合2.性能革命六、学习路线图1.技能成长路径基础阶段(1-3月)专业方向(3-6月)深度进阶(6-12月</div>
</li>
<li><a href="/article/1903389604430540800.htm"
title="在 Spring Boot 结合 MyBatis 的项目中,实现字段脱敏(如手机号、身份证号、银行卡号等敏感信息的部分隐藏)可以通过以下方案实现" target="_blank">在 Spring Boot 结合 MyBatis 的项目中,实现字段脱敏(如手机号、身份证号、银行卡号等敏感信息的部分隐藏)可以通过以下方案实现</a>
<span class="text-muted">冷冷清清中的风风火火</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/springboot/1.htm">springboot</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>在SpringBoot结合MyBatis的项目中,实现字段脱敏(如手机号、身份证号、银行卡号等敏感信息的部分隐藏)可以通过以下方案实现。以下是分步说明和完整代码示例:一、实现方案选择1.方案一:自定义注解+Jackson序列化脱敏适用场景:数据返回给前端时动态脱敏,数据库存储原始数据。优点:无侵入性,通过注解灵活控制脱敏字段,与业务逻辑解耦。核心实现:利用Jackson的JsonSerialize</div>
</li>
<li><a href="/article/60.htm"
title="Dom" target="_blank">Dom</a>
<span class="text-muted">周华华</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a>
<div><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q</div>
</li>
<li><a href="/article/187.htm"
title="【Spark九十六】RDD API之combineByKey" target="_blank">【Spark九十六】RDD API之combineByKey</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/spark/1.htm">spark</a>
<div>1. combineByKey函数的运行机制
RDD提供了很多针对元素类型为(K,V)的API,这些API封装在PairRDDFunctions类中,通过Scala隐式转换使用。这些API实现上是借助于combineByKey实现的。combineByKey函数本身也是RDD开放给Spark开发人员使用的API之一
首先看一下combineByKey的方法说明:</div>
</li>
<li><a href="/article/314.htm"
title="msyql设置密码报错:ERROR 1372 (HY000): 解决方法详解" target="_blank">msyql设置密码报错:ERROR 1372 (HY000): 解决方法详解</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E7%BD%AE%E5%AF%86%E7%A0%81/1.htm">设置密码</a>
<div>MySql给用户设置权限同时指定访问密码时,会提示如下错误:
ERROR 1372 (HY000): Password hash should be a 41-digit hexadecimal number;
问题原因:你输入的密码是明文。不允许这么输入。
解决办法:用select password('你想输入的密码');查询出你的密码对应的字符串,
然后</div>
</li>
<li><a href="/article/441.htm"
title="路漫漫其修远兮 吾将上下而求索" target="_blank">路漫漫其修远兮 吾将上下而求索</a>
<span class="text-muted">周凡杨</span>
<a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0+%E6%80%9D%E7%B4%A2/1.htm">学习 思索</a>
<div>王国维在他的《人间词话》中曾经概括了为学的三种境界古今之成大事业、大学问者,罔不经过三种之境界。“昨夜西风凋碧树。独上高楼,望尽天涯路。”此第一境界也。“衣带渐宽终不悔,为伊消得人憔悴。”此第二境界也。“众里寻他千百度,蓦然回首,那人却在灯火阑珊处。”此第三境界也。学习技术,这也是你必须经历的三种境界。第一层境界是说,学习的路是漫漫的,你必须做好充分的思想准备,如果半途而废还不如不要开始。这里,注</div>
</li>
<li><a href="/article/568.htm"
title="Hadoop(二)对话单的操作" target="_blank">Hadoop(二)对话单的操作</a>
<span class="text-muted">朱辉辉33</span>
<a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a>
<div>Debug:
1、
A = LOAD '/user/hue/task.txt' USING PigStorage(' ')
AS (col1,col2,col3);
DUMP A;
//输出结果前几行示例:
(>ggsnPDPRecord(21),,)
(-->recordType(0),,)
(-->networkInitiation(1),,)
</div>
</li>
<li><a href="/article/695.htm"
title="web报表工具FineReport常用函数的用法总结(日期和时间函数)" target="_blank">web报表工具FineReport常用函数的用法总结(日期和时间函数)</a>
<span class="text-muted">老A不折腾</span>
<a class="tag" taget="_blank" href="/search/finereport/1.htm">finereport</a><a class="tag" taget="_blank" href="/search/%E6%8A%A5%E8%A1%A8%E5%B7%A5%E5%85%B7/1.htm">报表工具</a><a class="tag" taget="_blank" href="/search/web%E5%BC%80%E5%8F%91/1.htm">web开发</a>
<div>web报表工具FineReport常用函数的用法总结(日期和时间函数)
说明:凡函数中以日期作为参数因子的,其中日期的形式都必须是yy/mm/dd。而且必须用英文环境下双引号(" ")引用。
DATE
DATE(year,month,day):返回一个表示某一特定日期的系列数。
Year:代表年,可为一到四位数。
Month:代表月份。</div>
</li>
<li><a href="/article/822.htm"
title="c++ 宏定义中的##操作符" target="_blank">c++ 宏定义中的##操作符</a>
<span class="text-muted">墙头上一根草</span>
<a class="tag" taget="_blank" href="/search/C%2B%2B/1.htm">C++</a>
<div>#与##在宏定义中的--宏展开 #include <stdio.h> #define f(a,b) a##b #define g(a) #a #define h(a) g(a) int main() { &nbs</div>
</li>
<li><a href="/article/949.htm"
title="分析Spring源代码之,DI的实现" target="_blank">分析Spring源代码之,DI的实现</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/DI/1.htm">DI</a><a class="tag" taget="_blank" href="/search/%E7%8E%B0/1.htm">现</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E4%BB%A3%E7%A0%81/1.htm">源代码</a>
<div>(转)
分析Spring源代码之,DI的实现
2012/1/3 by tony
接着上次的讲,以下这个sample
[java]
view plain
copy
print
</div>
</li>
<li><a href="/article/1076.htm"
title="for循环的进化" target="_blank">for循环的进化</a>
<span class="text-muted">alxw4616</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>// for循环的进化
// 菜鸟
for (var i = 0; i < Things.length ; i++) {
// Things[i]
}
// 老鸟
for (var i = 0, len = Things.length; i < len; i++) {
// Things[i]
}
// 大师
for (var i = Things.le</div>
</li>
<li><a href="/article/1203.htm"
title="网络编程Socket和ServerSocket简单的使用" target="_blank">网络编程Socket和ServerSocket简单的使用</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B%E5%9F%BA%E7%A1%80/1.htm">网络编程基础</a><a class="tag" taget="_blank" href="/search/IP%E5%9C%B0%E5%9D%80%E7%AB%AF%E5%8F%A3/1.htm">IP地址端口</a>
<div>
网络编程;TCP/IP协议
网络:实现计算机之间的信息共享,数据资源的交换
协议:数据交换需要遵守的一种协议,按照约定的数据格式等写出去
端口:用于计算机之间的通信
每运行一个程序,系统会分配一个编号给该程序,作为和外界交换数据的唯一标识
0~65535
查看被使用的</div>
</li>
<li><a href="/article/1330.htm"
title="JDK1.5 生产消费者" target="_blank">JDK1.5 生产消费者</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/thread/1.htm">thread</a><a class="tag" taget="_blank" href="/search/%E7%94%9F%E4%BA%A7%E6%B6%88%E8%B4%B9%E8%80%85/1.htm">生产消费者</a><a class="tag" taget="_blank" href="/search/java%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">java多线程</a>
<div>ArrayBlockingQueue:
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部 是在队列中存在时间最长的元素。队列的尾部 是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列检索操作则是从队列头部开始获得元素。
ArrayBlockingQueue的常用方法:
</div>
</li>
<li><a href="/article/1457.htm"
title="JAVA版身份证获取性别、出生日期及年龄" target="_blank">JAVA版身份证获取性别、出生日期及年龄</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%80%A7%E5%88%AB/1.htm">性别</a><a class="tag" taget="_blank" href="/search/%E5%87%BA%E7%94%9F%E6%97%A5%E6%9C%9F/1.htm">出生日期</a><a class="tag" taget="_blank" href="/search/%E5%B9%B4%E9%BE%84/1.htm">年龄</a>
<div> 工作中需要根据身份证获取性别、出生日期及年龄,且要还要支持15位长度的身份证号码,网上搜索了一下,经过测试好像多少存在点问题,干脆自已写一个。
CertificateNo.java
package com.bijian.study;
import java.util.Calendar;
import </div>
</li>
<li><a href="/article/1584.htm"
title="【Java范型六】范型与枚举" target="_blank">【Java范型六】范型与枚举</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>首先,枚举类型的定义不能带有类型参数,所以,不能把枚举类型定义为范型枚举类,例如下面的枚举类定义是有编译错的
public enum EnumGenerics<T> { //编译错,提示枚举不能带有范型参数
OK, ERROR;
public <T> T get(T type) {
return null;
</div>
</li>
<li><a href="/article/1711.htm"
title="【Nginx五】Nginx常用日志格式含义" target="_blank">【Nginx五】Nginx常用日志格式含义</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a>
<div>1. log_format
1.1 log_format指令用于指定日志的格式,格式:
log_format name(格式名称) type(格式样式)
1.2 如下是一个常用的Nginx日志格式:
log_format main '[$time_local]|$request_time|$status|$body_bytes</div>
</li>
<li><a href="/article/1838.htm"
title="Lua 语言 15 分钟快速入门" target="_blank">Lua 语言 15 分钟快速入门</a>
<span class="text-muted">ronin47</span>
<a class="tag" taget="_blank" href="/search/lua+%E5%9F%BA%E7%A1%80/1.htm">lua 基础</a>
<div>-
-
单行注释
-
-
[[
[多行注释]
-
-
]]
-
-
-
-
-
-
-
-
-
-
-
1.
变量 & 控制流
-
-
-
-
-
-
-
-
-
-
num
=
23
-
-
数字都是双精度
str
=
'aspythonstring'
</div>
</li>
<li><a href="/article/1965.htm"
title="java-35.求一个矩阵中最大的二维矩阵 ( 元素和最大 )" target="_blank">java-35.求一个矩阵中最大的二维矩阵 ( 元素和最大 )</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>the idea is from:
http://blog.csdn.net/zhanxinhang/article/details/6731134
public class MaxSubMatrix {
/**see http://blog.csdn.net/zhanxinhang/article/details/6731134
* Q35
求一个矩阵中最大的二维</div>
</li>
<li><a href="/article/2092.htm"
title="mongoDB文档型数据库特点" target="_blank">mongoDB文档型数据库特点</a>
<span class="text-muted">开窍的石头</span>
<a class="tag" taget="_blank" href="/search/mongoDB%E6%96%87%E6%A1%A3%E5%9E%8B%E6%95%B0%E6%8D%AE%E5%BA%93%E7%89%B9%E7%82%B9/1.htm">mongoDB文档型数据库特点</a>
<div>MongoDD: 文档型数据库存储的是Bson文档-->json的二进制
特点:内部是执行引擎是js解释器,把文档转成Bson结构,在查询时转换成js对象。
mongoDB传统型数据库对比
传统类型数据库:结构化数据,定好了表结构后每一个内容符合表结构的。也就是说每一行每一列的数据都是一样的
文档型数据库:不用定好数据结构,</div>
</li>
<li><a href="/article/2219.htm"
title="[毕业季节]欢迎广大毕业生加入JAVA程序员的行列" target="_blank">[毕业季节]欢迎广大毕业生加入JAVA程序员的行列</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
一年一度的毕业季来临了。。。。。。。。
正在投简历的学弟学妹们。。。如果觉得学校推荐的单位和公司不适合自己的兴趣和专业,可以考虑来我们软件行业,做一名职业程序员。。。
软件行业的开发工具中,对初学者最友好的就是JAVA语言了,网络上不仅仅有大量的</div>
</li>
<li><a href="/article/2346.htm"
title="PHP操作Excel – PHPExcel 基本用法详解" target="_blank">PHP操作Excel – PHPExcel 基本用法详解</a>
<span class="text-muted">cuiyadll</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/Excel/1.htm">Excel</a>
<div>导出excel属性设置//Include classrequire_once('Classes/PHPExcel.php');require_once('Classes/PHPExcel/Writer/Excel2007.php');$objPHPExcel = new PHPExcel();//Set properties 设置文件属性$objPHPExcel->getProperties</div>
</li>
<li><a href="/article/2473.htm"
title="IBM Webshpere MQ Client User Issue (MCAUSER)" target="_blank">IBM Webshpere MQ Client User Issue (MCAUSER)</a>
<span class="text-muted">darrenzhu</span>
<a class="tag" taget="_blank" href="/search/IBM/1.htm">IBM</a><a class="tag" taget="_blank" href="/search/jms/1.htm">jms</a><a class="tag" taget="_blank" href="/search/user/1.htm">user</a><a class="tag" taget="_blank" href="/search/MQ/1.htm">MQ</a><a class="tag" taget="_blank" href="/search/MCAUSER/1.htm">MCAUSER</a>
<div>IBM MQ JMS Client去连接远端MQ Server的时候,需要提供User和Password吗?
答案是根据情况而定,取决于所定义的Channel里面的属性Message channel agent user identifier (MCAUSER)的设置。
http://stackoverflow.com/questions/20209429/how-mca-user-i</div>
</li>
<li><a href="/article/2600.htm"
title="网线的接法" target="_blank">网线的接法</a>
<span class="text-muted">dcj3sjt126com</span>
<div>一、PC连HUB (直连线)A端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 B端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 二、PC连PC (交叉线)A端:(568A): 白绿,绿,白橙,蓝,白蓝,橙,白棕,棕; B端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 三、HUB连HUB&nb</div>
</li>
<li><a href="/article/2727.htm"
title="Vimium插件让键盘党像操作Vim一样操作Chrome" target="_blank">Vimium插件让键盘党像操作Vim一样操作Chrome</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/chrome/1.htm">chrome</a><a class="tag" taget="_blank" href="/search/vim/1.htm">vim</a>
<div>什么是键盘党?
键盘党是指尽可能将所有电脑操作用键盘来完成,而不去动鼠标的人。鼠标应该说是新手们的最爱,很直观,指哪点哪,很听话!不过常常使用电脑的人,如果一直使用鼠标的话,手会发酸,因为操作鼠标的时候,手臂不是在一个自然的状态,臂肌会处于绷紧状态。而使用键盘则双手是放松状态,只有手指在动。而且尽量少的从鼠标移动到键盘来回操作,也省不少事。
在chrome里安装 vimium 插件
</div>
</li>
<li><a href="/article/2854.htm"
title="MongoDB查询(2)——数组查询[六]" target="_blank">MongoDB查询(2)——数组查询[六]</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a><a class="tag" taget="_blank" href="/search/MongoDB%E6%9F%A5%E8%AF%A2%E6%95%B0%E7%BB%84/1.htm">MongoDB查询数组</a>
<div>MongoDB查询数组
转载请出自出处:http://eksliang.iteye.com/blog/2177292 一、概述
MongoDB查询数组与查询标量值是一样的,例如,有一个水果列表,如下所示:
> db.food.find()
{ "_id" : "001", "fruits" : [ "苹</div>
</li>
<li><a href="/article/2981.htm"
title="cordova读写文件(1)" target="_blank">cordova读写文件(1)</a>
<span class="text-muted">gundumw100</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/Cordova/1.htm">Cordova</a>
<div>使用cordova可以很方便的在手机sdcard中读写文件。
首先需要安装cordova插件:file
命令为:
cordova plugin add org.apache.cordova.file
然后就可以读写文件了,这里我先是写入一个文件,具体的JS代码为:
var datas=null;//datas need write
var directory=&</div>
</li>
<li><a href="/article/3108.htm"
title="HTML5 FormData 进行文件jquery ajax 上传 到又拍云" target="_blank">HTML5 FormData 进行文件jquery ajax 上传 到又拍云</a>
<span class="text-muted">ileson</span>
<a class="tag" taget="_blank" href="/search/jquery/1.htm">jquery</a><a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a><a class="tag" taget="_blank" href="/search/FormData/1.htm">FormData</a>
<div>html5 新东西:FormData 可以提交二进制数据。
页面test.html
<!DOCTYPE>
<html>
<head>
<title> formdata file jquery ajax upload</title>
</head>
<body>
<</div>
</li>
<li><a href="/article/3235.htm"
title="swift appearanceWhenContainedIn:(version1.2 xcode6.4)" target="_blank">swift appearanceWhenContainedIn:(version1.2 xcode6.4)</a>
<span class="text-muted">啸笑天</span>
<a class="tag" taget="_blank" href="/search/version/1.htm">version</a>
<div>
swift1.2中没有oc中对应的方法:
+ (instancetype)appearanceWhenContainedIn:(Class <UIAppearanceContainer>)ContainerClass, ... NS_REQUIRES_NIL_TERMINATION;
解决方法:
在swift项目中新建oc类如下:
#import &</div>
</li>
<li><a href="/article/3362.htm"
title="java实现SMTP邮件服务器" target="_blank">java实现SMTP邮件服务器</a>
<span class="text-muted">macroli</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a>
<div>电子邮件传递可以由多种协议来实现。目前,在Internet 网上最流行的三种电子邮件协议是SMTP、POP3 和 IMAP,下面分别简单介绍。
◆ SMTP 协议
简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)是一个运行在TCP/IP之上的协议,用它发送和接收电子邮件。SMTP 服务器在默认端口25上监听。SMTP客户使用一组简单的、基于文本的</div>
</li>
<li><a href="/article/3489.htm"
title="mongodb group by having where 查询sql" target="_blank">mongodb group by having where 查询sql</a>
<span class="text-muted">qiaolevip</span>
<a class="tag" taget="_blank" href="/search/%E6%AF%8F%E5%A4%A9%E8%BF%9B%E6%AD%A5%E4%B8%80%E7%82%B9%E7%82%B9/1.htm">每天进步一点点</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E6%B0%B8%E6%97%A0%E6%AD%A2%E5%A2%83/1.htm">学习永无止境</a><a class="tag" taget="_blank" href="/search/mongo/1.htm">mongo</a><a class="tag" taget="_blank" href="/search/%E7%BA%B5%E8%A7%82%E5%8D%83%E8%B1%A1/1.htm">纵观千象</a>
<div>SELECT cust_id,
SUM(price) as total
FROM orders
WHERE status = 'A'
GROUP BY cust_id
HAVING total > 250
db.orders.aggregate( [
{ $match: { status: 'A' } },
{
$group: {
</div>
</li>
<li><a href="/article/3616.htm"
title="Struts2 Pojo(六)" target="_blank">Struts2 Pojo(六)</a>
<span class="text-muted">Luob.</span>
<a class="tag" taget="_blank" href="/search/POJO/1.htm">POJO</a><a class="tag" taget="_blank" href="/search/strust2/1.htm">strust2</a>
<div>注意:附件中有完整案例
1.采用POJO对象的方法进行赋值和传值
2.web配置
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee&q</div>
</li>
<li><a href="/article/3743.htm"
title="struts2步骤" target="_blank">struts2步骤</a>
<span class="text-muted">wuai</span>
<a class="tag" taget="_blank" href="/search/struts/1.htm">struts</a>
<div>1、添加jar包
2、在web.xml中配置过滤器
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.st</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>