同一份数据全域共享,HashData UnionStore实时性背后的故事
时至今日,数据已经被越来越多的企业视为发展的战略资源,而云数仓则是数据发挥重要价值的关键媒介。云数仓的出现,不仅改变了传统数据仓库的服务模式,更给用户带来了应对海量、新型数据的存储和处理能力,为满足业务现代化需求提供了基础。
然而,随着经营节奏的加快,企业对实时分析和快速结论的需求越来越强烈,传统数仓的离线同步已经逐渐无法满足业务要求。
站在这样一个行业需求的路口,面对这个难题,酷克数据给出了自己的解法:在优势OLAP产品的基础上,研发推出了崭新的UnionStore模块,在保持顶层同一套引擎、底层同一套存储与数据的一致性设计的情况下,实现了近事务级的计算与查询实时性,为用户应用云数仓打开了新的思路和场景。
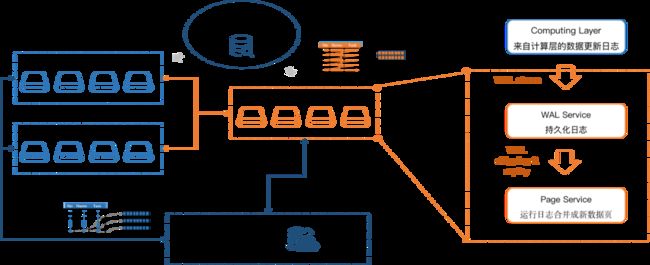
图1:HashData UnionStore模块架构图
酷克数据是一家专注于云端数据仓库的科技公司,公司旗舰产品HashData秉承云原生的理念与设计框架,帮助诸多企业打破了数据烟囱,整合了数据孤岛;打造的企业级云数仓,支撑着各种各样的数据分析负载。
要想了解HashData是如何实现云数仓的实时特性,我们需要回到云数仓的演进历史。其实,正所谓“历史一直在螺旋式上升”,任何新变化都不是一蹴而就,云数仓成为今天企业数字化转型的核心技术,其中的变化也是逐步演化而来,并非一蹴而就的过程。
云数仓演进历史
过去十年是信息化高速发展的十年,也是大数据速成长的十年。信息数据呈爆发式增长,不仅让传统企业加速向数字经济靠拢,更带来了底层数据架构变化的新范式。越来越多的企业希望把数据存好、用好,通过数据背后的逻辑分析去挖掘商业价值,探索数据之间的关联关系,找出大数据里面有价值的信息,辅助商业决策。数据仓库在此种背景下逐渐被企业重视。
同传统数据仓库相比,云数仓依托云计算的特点,在搭建、使用、扩容及运维等方面有着显著的优势,已成为目前最为主流的技术产品。它可以把大规模并行计算与云的优势结合在一起,更好地实现数仓的分析能力。
比如:在高性能方面,云数仓可以支持向量计算异步的执行框架,包括通过并行计算来最大化地利用 CPU资源去提升查询的性能。在数据一致性方面,可以支持ACID特性,包括在数据新鲜度上,可以支持数据的实时增、删、改、查。而从可扩展性来看,云数仓这种存算分离的架构,可以按需扩展,按使用量去计费,极大地降低了用户的使用成本。当计算不够的时候可以去扩计算,存储不够的时候可以扩存储,实现充分灵活。
架构变革
一般来说,由于数仓产品普遍采用列存,产品通常在离线处理和实时处理之中更偏向离线,而实时性会成为相对的短板。
在离线处理的场景中,用户数据载入后,通过ETL进行数据的抽取和清洗,然后存储到数据仓库,执行离线分析、批处理、报表生成等作业。数据工程师们常常在下班前将前一天或者当天的查询计划输入到数仓,系统在夜间来执行作业,第二天上班后来查询报表结果,时效是T+1天以上。
然而,随着企业数据种类越来多,数据量越来越大,数据处理过程越来越复杂,单一的传统数仓越来越难以满足业务需求。企业希望使用一套架构去承载数据,提升整体性能,同时还要满足实时需求,这些都在促使OLAP和OLTP发生进一步的融合。
如今,各行各业都在不断追求更好的用户体验,这一追求带动了实时数据分析能力的需求越来越强烈。
例如,消费品公司希望通过电商平台和社交网络上来了解用户的搜索行为和关注热点,这无疑需要获取实时数据。这一变化将传统的Lambda架构推到风口浪尖。Lambda架构的优势是高容错、低延时和可扩展等特征。但是,它的弊端则在于需要将所有的算法实现两次。其中,一套系统用来做批处理,进行存量数据计算;另一套系统用来满足实时性业务需求。两套系统的并行运作为开发和运维工作带来了大量的成本与负担。
为了实现架构简化,业界推出了Kappa架构作为一个新的演进方向。这种只采用流式处理引擎的方式,使得开发人员只需维护实时处理模块,极大地降低了开发的复杂性。
提到实时处理,很难不提Flink。通过消息队列的形式,Flink可以保存历史数据,并支持用户源源不断地去消费这些数据,对数据进行实时处理,将结果反馈输出。对于云数仓而言,与Flink方案的结合,在计算和存储引擎端带来了不同的架构变化。在计算引擎上,产品需要支持实时性,快速捕捉数据。而在存储引擎上,通过分布式存储,实现高可靠性与高扩展性的需求,同时实现较低的存储成本。
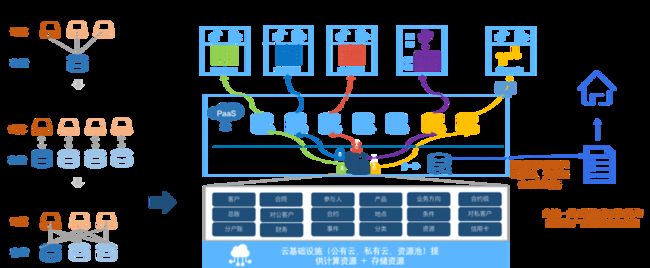
图2:基于“存算分离”架构的HashData云数仓在金融行业落地方案示意图
展望未来,存算分离和Serverless架构将会成为主流。考虑到可扩展性成本,企业更愿意基于完善的存储设施平台去构建技术底座,提升查询性能。作为业内领先的云数仓产品,HashData采用的是元数据、计算和存储完全分离的架构设计,通过对象存储来共享一份全域数据的方式,充分发挥云架构优势,实现集群的秒级自动扩缩容,在满足实时性的同时,提供了更高的架构与成本灵活度。
应用趋势
从应用趋势来看,金融、电信、能源、政务等行业领域,会是云数仓的重要应用场景。在数字化转型浪潮推动下,会有越来越多的企业想成为数据驱动型企业,发动基于数据的业务创新。
对于金融行业而言,业务属性对云数仓的实时性提出了更高要求,包括处理速度、I/O性能等。例如,在金融风控和反欺诈场景中,数据系统需要在短时间内进行响应,做出决策,才能最大程度避免经济损失。
同时,可扩展性、易用性、性价比也是金融场景的重要需求点。只有打破部门之间的壁垒,实现架构上的突破,才能经受得住复杂场景下的打磨和验证。
面对用户“既要、又要、还要”的问题,HashData在内核层面进行了创新突破,让实时数据处理成为可能。以HashData UnionStore为例,这是一种基于日志的数据库架构思想,当存算解耦后,让使用不同引擎分开处理数据成为可能,Log is database理念可以全面提升数仓的TP性能,在磁盘随机访问、异步提交、并发控制、批处理、重放等方面进行了全面优化,从而实现了实时性提升。
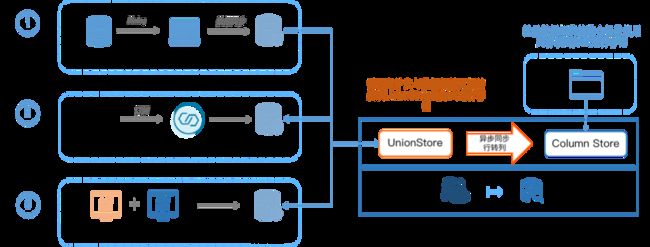
图3:HashData UnionStore应用场景
如今,已经有很多的领先金融企业选择用HashData实现了传统数据仓库的替代,解决传统架构扩容难题。金融领域数据量一般比较大,集群很多,传统MPP的部署方式导致每个部门都有自己的专属集群及相关数据,扩容过程繁琐,时间周期长,运维成本居高不下。在进行数据流动、数据共享,数据互通的操作时,一般通过数据同步或者复制的方式来创建数据副本,创建新的集群,这样的方式带来了巨大的成本压力。
HashData不仅解决了用户的可扩展问题,还能实现按需收费。举例来说,如果用户的CPU需求密集,可以创建一个CPU比较多的集群,根据集群请求灵活扩展资源。不同集群对应同一份数据,可以满足各类读写需求。
今天我们看到,存算分离已经成为云数仓的主流技术趋势。HashData正通过一份数据全域共享的方式,满足核心业务的实时性需求,为企业业务决策提速带来了强大助力。相信随着企业对实时分析需求的不断增强,HashData会和更多用户携手同行,奔向数智化的新未来!