MySQL VS PostgreSQL,谁是世界上最成功的数据库?
 # 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周1 | 鹅厂工程师带你审判技术
# 第5期 | 成江东:谁是世界上最成功的数据库?


StackOverflow《2023 技术调查》中,PostgreSQL 超越 MySQL 成为了最受欢迎的数据库。专业的开发者更倾向于使用 PostgreSQL(有50%的人选择使用),而那些正在学习编程的人则更喜欢使用 MySQL(有54%的人选择使用)。
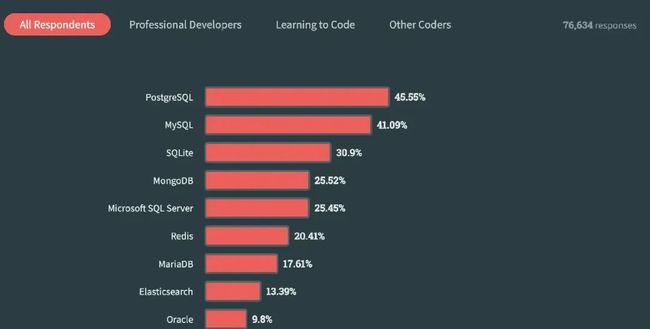
于是有同学得出结论:
PostgreSQL 现在是全世界最流行的数据库!PostgreSQL 是开发者最喜爱欣赏的数据库!PostgreSQL 是用户需求最为强烈的数据库!
这个结论可谓一石激起千层浪,在数据库社区引起了大量的争论。那么这个结论正确吗?让我们一步步来分析。

在讨论哪个数据库是世界上最成功的之前,首先要明确“成功”的定义。“成功”可以基于流行度、技术特点、应用领域、受欢迎度等多种因素来定义。
如果我们以流行度来看,那无疑 DB-Engines 排名更权威,为什么这样说呢?一个是 DB-Engines 聚焦于数据库领域,更为专业。另外,DB-Engines 排名的计算方法更全面、更科学。我们看下它的计算方式:
DB-Engines 排名是按其当前受欢迎程度对数据库管理系统进行排名的一个列表。我们如何衡量一个系统的受欢迎程度呢?
▶︎ 在网站上的提及次数:我们查看在搜索引擎(目前我们使用的是 Google 和 Bing)中这个系统的提及次数。为了只计算相关结果,我们搜索系统名称和“数据库”这个词,例如“Oracle”和“数据库”。
▶︎ 系统的普遍兴趣:我们使用 Google Trends 来查看系统的搜索频率。
▶︎ 关于系统的技术讨论频率:我们根据著名的IT相关问答网站 Stack Overflow和DBA Stack Exchange 上的相关问题和感兴趣的用户数量来衡量。
▶︎ 提及系统的工作机会数量:我们查看主要的工作搜索引擎 Indeed 和 Simply Hired 上提及该系统的工作机会数量。
▶︎ 在专业网络上的个人资料数量:我们查看在最受欢迎的国际专业网络 LinkedIn 上提及该系统的个人资料数量。
▶︎ 在社交网络中的相关性:我们计算提及该系统的 Twitter 推文数量。
我们通过标准化和平均各个参数来计算系统的受欢迎程度。这些数学变换是为了保持各个系统之间的差距。也就是说,当系统 A 在 DB-Engines 排名中的值是系统 B 的两倍时,那么在平均评价标准上,它的受欢迎程度也是系统 B 的两倍。
为了消除数据源数量变化所引起的影响,受欢迎分数总是一个相对值,只应与其他系统进行比较。
DB-Engines 排名并不衡量系统的安装次数或其在IT系统中的使用情况。可以预期,系统受欢迎程度的增加(如在讨论或工作机会中)会在系统广泛使用之前预先出现。因此,DB-Engines 排名可以作为一个早期指标。
可以看到上面的计算方法里面已经包括了 Stack Overflow 上的相关问题和感兴趣的用户数量指标,同时还包括搜索引擘、招聘网站、社交网站的指标,非常全面,且用户覆盖面也是千万到亿级用户。对比之下,参与 StackOverflow《2023 技术调查》数据库部分的只有不到8万人,用这个数据来说明谁是最流行的数据库太偏颇了。
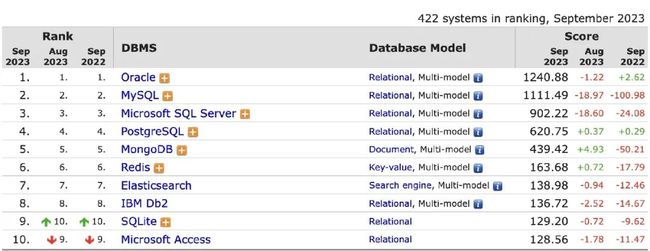
我们看下 DB-Engines 最新的数据库排名,可以看到前4名都是关系型数据库,其中 Oracle 是第1名,但它是收费的,随着国产数据库替代的潮流趋势,其在中国的市场份额将会持续缩小。第2名就是 MySQL,是第4名 PostgreSQL 分数的2倍,可见当前 MySQL 才是最流行的数据库。

有同学说分布式数据库的核心权衡是“以质换量”:牺牲功能、性能、复杂度、可靠性,换取更大的数据容量与请求吞吐量。但分久必合,硬件变革让集中式数据库的容量与吞吐达到一个全新高度,使分布式(TP)数据库失去了存在意义。以 NVMe SSD 为代表的硬件遵循摩尔定律以指数速度演进,十年间性能翻了几十倍,价格降了几十倍,性价比提高了三个数量级。单卡 32TB+, 4K随机读写 IOPS 可达 1600K/600K,延时 70µs/10µs,价格不到 200 ¥/TB·年。跑集中式数据库单机能有一两百万的点写/点查 QPS。真正需要分布式数据库的场景屈指可数,典型的中型互联网公司/银行请求数量级在几万到几十万 QPS,不重复 TP 数据在百 TB 上下量级。真实世界中 99% 以上的场景用不上分布式数据库,剩下1%也大概率可以通过经典的水平/垂直拆分等工程手段解决。
上面的观点非常片面,我举一个例子,微信商业退款要求5年内的订单都能退,而微信商业订单的量级是1天20亿级,1年万亿级,5年数据量在 PB 级,如果用单机版的数据库,单个数据库肯定搞不定,而水平拆分无论是对运维还是开发来说,管理难度和成本都非常高,实际上早期使用过单体数据库来存储历史数据,并且还使用了高压缩比的 tokuDB 引擘和大容量磁盘,但随着数据量的不断增长,以及不同业务的历史数据增长情况不同,经常出现有的历史库写满,有的很空闲,需要经常调整写入策略和读取路由。如果单个节点的磁盘故障,因为单个实例容量太大,重做数据的时间也非常长。
所以这里选择用分布式数据库如 TDSQL 更合适。分布式数据库将分片管理、路由管理都交给了存储层,业务层只需要关注于业务逻辑开发,像使用单体数据库一样进行开发,大大减轻了业务开发和运维的复杂度,也提升了可用性。
TDSQL 计算层100%兼容 MySQL。

有同学说 TPC-C 是 30 年前的测试标准,是过时的标准,而且可以通过堆机器的方式提升性能。
我们先看下什么是 TPC-C,它的要求是什么?
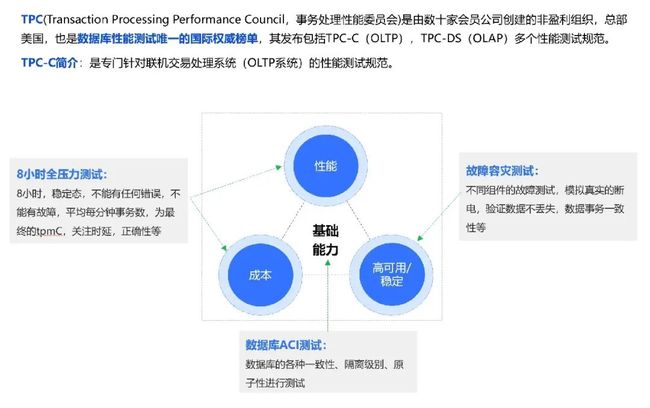
如上图所示,TPC-C 对性能的要求是非常严格的,要求8小时不能有任何错误,并且 tmpC 波动率小于2%。除了性能这外,还关注成本、和稳定性,并不是堆机器就可以的。
2019年-2020年,OceanBase 先后两次完成了国内数据库厂商的首次 TPCC 打榜,而且第二次打榜直接跑到7.07亿 tpmC。
2023年1月-2月,腾讯云进行了一次打榜,在3月份正式发布了打榜结果,如下图所示:实现了吞吐量(tpmC)和性价比(Price/tpmC)的双榜世界第一。

为什么数据库 Oracle,IBM 不打榜了?不是因为不想,而是因为集中式的数据库的吞吐量受限于单机性能其上限比计算层和存储层可以分别进行自动化扩容的分布式数据库要低很多,从榜单来看,分布式数据库的 tmpC 比集中式数据库高1个数量级。

刚才提到,最受欢迎的数据库前4名是 Oracle、MySQL、SQL Server、 PostgreSQL,但 Oracle,SQL Server 是商业数据库,不开源,且未来在中国的市场只会越来越小,所以我们全面对比下 MySQL/PostgreSQL:
事务内语句失败是否回滚
BEGIN;
INSERT INTO t VAVLUES (1,...);
INSERT INTO t VAVLUES (1,...); -- 主键冲突,报错
COMMIT;
SELECT * FROM t;
-- 得到1这条记录让我们看下这个上面这个例子,这个事务在 MySQL 和 PostgreSQL 中的执行结果有差异。
在 MySQL 中,用户选择 COMMIT 而不是 ROLLBACK,第1条 insert 会写入成功,而 Oracle 、Microsoft SQL Server 也支持这样的行为特性。
通过设置参数 sql_mode ,MySQL 也可以遇到单条更新语句失败后立即退出。
所以这是更多的是一个 Feature,由用户自主选择遇到单条语句错误是否提交或者回滚事务,而不是所谓的 BUG。
开源协议
PostgreSQL License 是一个宽松的开源许可证,类似于 MIT 许可证。它允许用户自由使用、修改和分发,无需公开源代码。它也不强制任何特定的版权声明,这使得它与许多其他开源和专有许可证兼容。
MySQL 采用 GPLv2 是一个“传染性”的开源许可证,这意味着任何基于 GPLv2 许可的代码进行修改或扩展,并且要分发的派生作品,也必须在 GPLv2 下发布。这确保了软件的自由性,但也可能限制了与非 GPL 软件的集成。
通俗来说,PostgreSQL License 支持第三方进行修改后商业化,还可以不开源。但 GPLv2 协议要求任何基于 GPLv2 软件的衍生作品也必须是开源的,所以第三方的优化成果最终也会反馈给社区。长期来看,GPLv2 协议更能带动开源社区的发展。
MVCC 实现机制
PostgreSQL 将历史元组和最新元组都保存在 Heap 表中,这种方式的好处是无须做回滚操作,如果一个写事务异常终止,则其他事务将无法读到这条元组。此方法虽然可以避免事务回滚带来的消耗,但仍被广为诟病。假设一个事务不停地更新数据,那么一条元组就会产生大量的历史版本。其他事务在访问时需要查看这些元组是否满足可见性要求,这会增加读操作的时延,降低数据扫描的效率。为了防止数据膨胀,PostgreSQL 数据库采用 Vacuum 机制清理表中的无效元组。如果使用 Vacuum FULL 命令,则还会负责对所有的元组进行搬迁,避免清理页面的过程中产生大量的“空洞”。
MySQL、Oracle 采用了一种基于“回滚段”的方法来保存元组的历史版本(前像),如果事务更新了一条元组,它可以“原地”更新这条元组(新元组的 Size 需要小于等于旧元组的 Size),历史元组会以 Undo 日志记录的形式保存到回滚段中,这样就实现了元组的原地更新(Inplace Update)。当有并发事务需要访问历史元组时,可以从回滚段中“回滚”出这条元组,如果事务异常终止,则可以利用 Undo 日志将数据恢复。当所有可能访问历史元组的事务全部结束后,Undo 日志中的历史元组就可以被清理。由于 Undo 日志被集中存储到某一个回滚段,所以清理也较为便捷。
这一块的处理无疑 MySQL 更合理。
多进程 VS 多线程
PostgreSQL 采用多进程
优点:
▶︎ 稳定性:由于每个连接都有自己的进程,一个进程崩溃不太可能影响其他进程。这为系统提供了额外的稳定性。
▶︎ 内存隔离:每个进程都有自己的内存空间,这可以减少内存泄漏或其他问题对整个系统的影响。
▶︎ 开发简单性:多进程模型在某些情况下可能更容易开发和维护。
缺点:
▶︎ 资源开销:进程通常比线程需要更多的资源。每个进程都有自己的内存空间,这可能导致更高的内存使用。
▶︎ 上下文切换:进程之间的上下文切换可能比线程之间的上下文切换更加昂贵。
▶︎ 进程间通信:进程间通信(IPC)可能比线程间通信更复杂和开销更大。
MySQL 采用多线程
优点:
▶︎ 资源效率:线程共享相同的内存空间,这通常导致更低的内存使用和更快的上下文切换。
▶︎ 高并发性:多线程模型通常能够更好地处理高并发情况,尤其是在多核 CPU 上。
▶︎ 线程间通信:线程间通信通常比进程间通信更简单和更快。适合短暂任务:对于短暂的、需要快速响应的任务,多线程模型可能更为合适。
缺点:
▶︎ 稳定性问题:一个线程的问题可能会影响到同一进程中的其他线程。例如,一个线程导致的内存泄漏可能会影响整个进程。
▶︎ 复杂的同步:在多线程环境中,数据同步和锁定可能会变得更加复杂。
全局变量和静态变量:由于线程共享内存,全局变量和静态变量的使用可能会导致问题。
既然开发难度上说多线程比多进程难,为什么 MySQL 选择了多线程呢?正如一个优秀的骑手与马合为一体,Monty(MySQL 的创始人)也与计算机融为一体。他无法忍受看到系统资源被浪费。他对自己有足够的信心,认为自己能够编写几乎没有错误的代码,处理线程带来的并发问题,甚至能够在小的堆栈上工作。这是一个令人兴奋的挑战!不用说,他选择了线程模型。——《Understanding MySQL Internals》
PostgreSQL 选择多进程的原因:多线程要求构建一个相当完整的特定目的操作系统。相比之下,每个用户一个进程的模型更简单实现,但在大多数常规操作系统上的性能可能不会那么好。经过深思熟虑,由于我们的编程资源有限,我们决定使用每个用户一个进程的模型来实现 POSTGRES——《The design of Postgres》
概括来说,主要是当年操作系统对线程支持不给力,开发难度也更大,所以早期一般使用多进程。而 MySQL 是特例,因为创始人 Monty 喜欢挑战,另外一个原因是 MySQL 后于 Oracle 和 PostgreSQL,那个时候操作系统的线程支持已经基本完善了。
多进程 VS 多线程
PostgreSQL 堆表:数据存储在一个称为"堆"的无序结构中。索引存储指向堆中行的指针(CTID),而不是实际的行数据。
优点:
▶︎ 简单性:堆表是最基本的表结构,不需要特定的排序或组织。
▶︎ 快速插入:数据可以迅速地添加到表的末尾,不需要重新排序或调整数据。
▶︎ 灵活性:可以轻松地添加或删除索引,而不影响表的基本结构。
缺点:
▶︎ 查询速度:由于数据没有特定的组织方式,查询可能需要全表扫描,尤其是在没有索引的情况下。
▶︎ 空间使用:可能会有更多的碎片,因为删除的行可能不会立即被回收,需要额外的操作如表重组来回收空间。
MySQL 索引组织表:
数据直接存储在主键索引的叶子节点中,这意味着表数据按主键的顺序存储。由于数据与主键索引紧密结合,所以通常可以更快地访问基于主键的查询。
优点:
▶︎ 查询性能:由于数据是按键值排序的,范围查询和某些类型的查找可以更快。
▶︎ 空间效率:通常使用较少的磁盘空间,因为它们减少了数据的冗余和碎片。
▶︎ 数据完整性:由于数据是按键值存储的,这可以确保数据的完整性和一致性。
缺点:
▶︎ 插入和更新开销:插入或更新数据可能需要重新组织表,以保持键值的排序。
▶︎ 复杂性:管理和维护索引组织表可能比堆表更复杂。
▶︎ 特定的用途:索引组织表主要适用于查询密集型的应用,而不是频繁的插入和更新操作。
其它项目对比

可以看到 PostgreSQL 在复杂查询性能,以及功能丰富性上有一定优势,但 MySQL 更专注,在 OLTP 领域表现更好。

Postgre 虽然功能更丰富,对复杂查询的优化做得更好。但 MySQL 抓住了互联网发展的红利,通过大量高并发、海量数据的 OLTP 业务证明了自己的一致性、性能、可靠性、可运维性,在流行度上过去和现在都是超过 PostgreSQL 很多,是当前最成功的数据库。
目前中国日交易量在20亿级别的 OLTP 金融级业务:财付通使用的是 TXSQL(腾讯云数据库内核版本,完全兼容 MySQL),支付宝使用的是 OceanBase,而兼容 MySQL 的工作一直是 OceanBase 团队长期工作的重点,也从侧面证明了 MySQL 的成功。
-End-
原创作者|成江东
你觉得谁是世界上最成功的数据库呢?欢迎留言。我们将挑选一则最有创意的答案,为其留言者送出腾讯定制便捷通勤袋。9月25日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)




