【考公人的福利】Python爬取中公官网资料
【考公人的福利】Python爬取中公官网资料
-
- 一、简述
- 二、代码
- 三、运行结果
一、简述
写这个代码的目的是能够高效率提取中公官网的资料,例如:申论、行测、面试热点、公安基础知识等。大家可以根据个人需要进行爬取。
二、代码
# -*- coding = utf-8 -*-
# @Time : 2021/2/9 18:00
# @Author : 陈良兴
# @File : 申论范文.py
# @Software : PyCharm
import requests
from bs4 import BeautifulSoup # 网页解析,获取数据
import time # 时间处理
import re # 正则匹配
import xlwt # 进行excel操作
def main():
datalist = [] # 保存文章标题和内容
theme_list = {'4006': '申论热点', '4005': '申论范文', '4007': '申论技巧', '3994': '全部申论',
'3993': '行测技巧', '3995': '面试技巧', '4011': '面试热点', '4012': '公安基础知识', '3997': '综合指导'}
theme = input("请选择爬取内容代码(申论热点:4006、申论范文:4005、申论技巧:4007、全部申论:3994、行测技巧:3993、面试技巧:3995、面试热点:4011、公安基础知识:4012、综合指导:3997):")
page = input("请输入需要爬取的页数:")
URL_list = get_pages_url(theme, int(page)) # 获取每个文章的URL
savepath = r'.\\' + theme_list[theme] + '.xls'
for i in range(len(URL_list)):
print("正在获取第{}篇范文".format(i+1))
datalist.extend(get_Data(URL_list[i]))
time.sleep(0.5)
i += 1
# print(datalist)
saveData(datalist, savepath, theme_list[theme], len(datalist))
def askURL(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html = response.content.decode("utf-8")
bs = BeautifulSoup(html, "html.parser") # 解析html,提取数据
return bs
# 获取每一页的全部url
def get_pages_url(theme, page):
data = []
for num in range(0, page, 1):
url = 'http://www.offcn.com/gwy/ziliao/{}/{}.html'.format(theme, num+1)
print("正在提取第" + str(num+1) + "页")
bs = askURL(url)
time.sleep(0.5)
list01 = str(bs.find_all('ul', class_="lh_newBobotm02"))
pat_link = r'
link = re.findall(pat_link, list01, re.S)
link_list = str(link).strip("[").strip("]").replace("'", "").split(",")
data.extend(link_list)
return data
# 解析没一个URL,获取数据
def get_Data(url):
articleData = []
bs = askURL(url)
title_MsgStr = bs.select("h1")
title = ""
for title_str in title_MsgStr:
title = title + title_str.text
articleData.append(title)
content = ""
list01 = str(bs.find_all('div', class_="offcn_shocont"))
pat_link = r'(.*?)
'
link = re.findall(pat_link, list01, re.S)
for i in range(len(link)):
content = content + str(link[i]).replace("", "").replace("", "").replace('', "")
i += 1
articleData.append(str(content))
return articleData
# 保存数据
def saveData(datalist, savepath, name, sum):
m = 0
print("save......")
book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象
sheet = book.add_sheet(name, cell_overwrite_ok=True) # 创建工作表
col = ("标题", "内容")
for i in range(0, 2):
sheet.write(0, i, col[i]) # 列名
for j in range(int(sum/2)):
print("第%d条" % (j+1))
for k in range(0, 2):
if (m+1)/2 == 0:
j += 1
sheet.write(j+1, k, datalist[m])
m += 1
book.save(savepath) # 保存数据表
if __name__ == '__main__':
main()
print("爬取完毕!!!")
三、运行结果
1、运行程序,根据提示输入要爬取内容的代码;
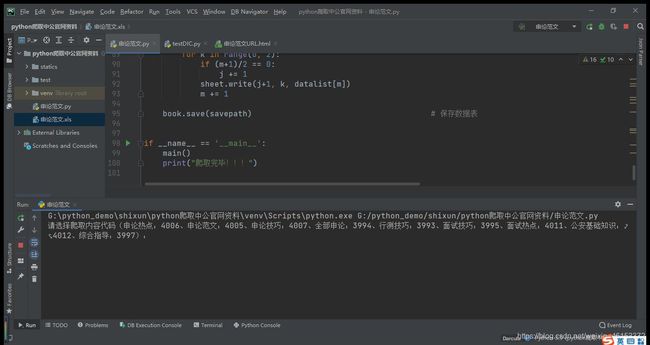
2、输入要爬取的网页数(其中每页有55篇文章的URL),回车;
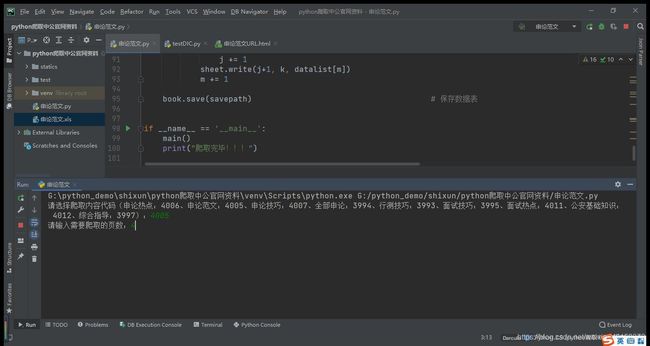
3、爬取结果
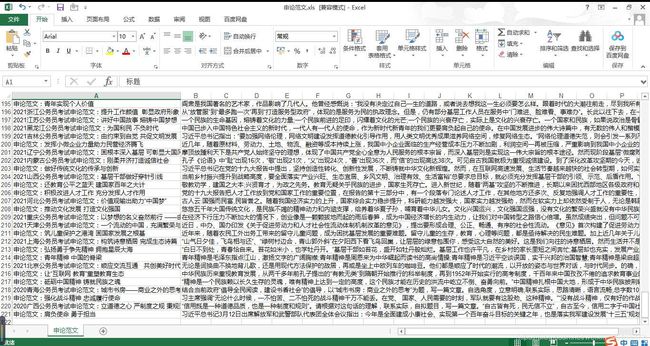
本次爬取的是220篇申论范文,见下图。