JPA的注解@Field指定为Keyword失败,导致查询不到数据
一、背景
使用 jpa 对es操作,查询条件不生效,需求是批量查询课程编号。说白了,就是一个In集合的查询。在es里,如果是精准匹配是termQuery,比如:
- queryBuilder.filter(QueryBuilders.termQuery(“schoolId”, schoolId))
而批量查询则是: - queryBuilder.filter(QueryBuilders.termsQuery(“schoolId”, schoolIds));
可以说,它们的区别仅仅在后者多了一个s(复数)。
不生效的原因,反复对比了好久,也没有看出有什么问题,因为代码太简单了。
我把拼接好的语句,在IDE工具(es-head、Kibana、ElisticHD)把查询条件验证,发现也是查询不到数据。
说明,不是java代码的问题,而是数据存储的问题了。
下面,我先把代码摘除一部分来,然后对es的索引信息重点分析,最后给出了我个人的解决方案。
二、代码摘引
1、model
import lombok.Data;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@Document(indexName = "course_idx", type = "_doc", shards = 1, refreshInterval = "-1")
public class CourseItem implements Serializable {
/**
* 课程编号
*/
@Field(type = FieldType.Keyword)
private String courseNo;
}
2、检索的条件匹配
检索的要求是:批量查询课程编号,传入的是多个课程编号集合。这里是在拼接es检索条件。
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
@Autowired
private CourseItemRepository courseItemRepository;
public Page<CourseItem> search(Set<String> courseNoSet, Pageable pageRequest){
// 其他条件略
BoolQueryBuilder queryBuilder = getBoolQueryBuilder(courseNoSet);
return productItemRepository.search(queryBuilder, pageRequest);
}
private BoolQueryBuilder getBoolQueryBuilder(Set<String> courseNoSet){
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
if (!CollectionUtils.isEmpty(courseNoSet)) {
queryBuilder.filter(QueryBuilders.termsQuery("courseNo", courseNoSet));
}
return queryBuilder;
}
3、CourseItemRepository.java
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface CourseItemRepository extends ElasticsearchRepository<CourseItem, String> {
}
三、代码自动生成的索引

可以看到,这个字段的类型不是keyword,实际自动生成的类型是text。
"courseNo":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
}
通常,这是由于 Elasticsearch 的自动类型推断机制所导致的。Elasticsearch 在某些情况下会根据数据的内容和用途来自动确定字段的类型,而忽略了显式的映射。
四、显式字段映射
为了确保字段类型按预期进行映射,您可以在 Elasticsearch 索引的映射定义中明确指定字段的类型,而不依赖于自动类型推断。这样可以确保字段始终具有所需的类型,无论数据内容如何。

// 在kibana dev tools手动创建索引,下面是简略的一个json。
// 注意courseNo的类型我手动指定为keyword
// name字段还是text类型,以支持分词检索。
// id字段也像courseNo一样,手动指定为keyword类型
PUT course_idx_dev
{
"mappings":{
"_doc":{
"properties":{
"courseType":{
"type":"long"
},
"courseNo":{
"type":"keyword"
},
"name":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"id":{
"type":"keyword"
}
}
}
}
}
- text类型的name字段,它的检索条件拼接示例是
// keywords是输入内容
QueryBuilders.functionScoreQuery(
QueryBuilders.matchPhraseQuery("name", keywords), ScoreFunctionBuilders.weightFactorFunction(1000))
.scoreMode(FunctionScoreQuery.ScoreMode.SUM)
.setMinScore(10.0F);
通过下图可以看出,courseNo的类型已纠正过来了。
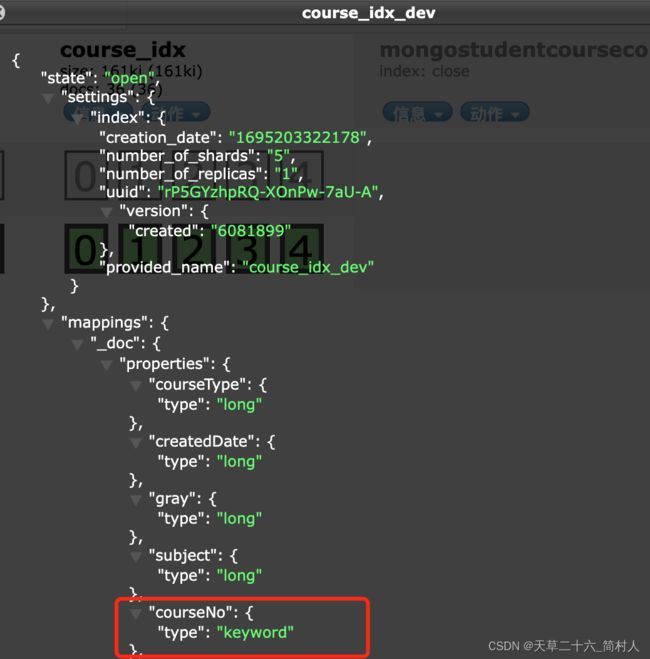
五、总结
至此,我们对courseNo的批量查询也就生效了。
本文通过一个查询需求,揭示出了text和keyword的显著差异,如果你也遇到查询不生效的问题,希望可以帮助到你。
es还有许多类型,除了基本类型外,还有Nested和Object,在相应的场景下使用它们,可以让你的代码变得更加优雅。
补充es查询语句
- 单个精确匹配
GET course_idx/_doc/_search
{
"query" : {
"term" : {
"courseNo" : {
"value" : "C00B5230920105650700A1",
"boost" : 1.0
}
}
}
}
对应的jpa语句:
{
"bool" : {
"filter" : [
{
"term" : {
"courseNo" : {
"value" : "C00B5230920105650700A1",
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
- 批量查询
GET course_idx/_doc/_search
{
"query" : {
"terms" : {
"courseNo" : [
"C00B5230920105650700A1",
"C00B5230921171813401A8"
],
"boost" : 1.0
}
}
}
对应的jpa语句:
{
"bool" : {
"filter" : [
{
"terms" : {
"courseNo" : [
"C00B5230920105650700A1"
],
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}