作者:鲍凤其
爱可生 dble 团队开发成员,主要负责 dble 需求开发,故障排查和社区问题解答。少说废话,放码过来。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
大家在使用 Java NIO 的过程中,是不是也遇到过堆外内存泄露的问题?是不是也苦恼过如何排查?
下面就给大家介绍一个在dble中排查堆外内存泄露的案例。
现象
有客户在使用dble之后,有一天dble对后端MySQL实例的心跳检测全部超时,导致业务中断,最后通过重启解决。
分析过程
dble 日志
首先当然是分析dble日志。从dble日志中可以发现:
- 故障时间点所有后端 MySQL 实例心跳都超时
- 日志中出现大量“You may need to turn up page size. The maximum size of the DirectByteBufferPool that can be allocated at one time is 2097152, and the size that you would like to allocate is 4194304”的日志
日志片段:
//心跳超时
2022-08-15 11:40:32.147 WARN [TimerScheduler-0] (com.actiontech.dble.backend.heartbeat.MySQLHeartbeat.setTimeout(MySQLHeartbeat.java:251)) - heartbeat to [xxxx:3306] setTimeout, previous status is 1
// 堆外内存可能泄露的可疑日志
2022-08-15 11:40:32.153 WARN [$_NIO_REACTOR_BACKEND-20-RW] (com.actiontech.dble.buffer.DirectByteBufferPool.allocate(DirectByteBufferPool.java:76)) - You may need to turn up page size. The maximum size of the DirectByteBufferPool that can be allocated at one time is 2097152, and the size that you would like to allocate is 4194304通过上面的日志猜测:
- 所有MySQL 实例超时是很特殊的,可能是由于故障时间发生了长时间停顿的gc
- 而长时间停顿的gc可能是由于堆外内存不够,大量的业务流量涌进堆内存中,从而导致频繁的gc
验证猜想
为了验证上面的猜想,获取了dble机器的相关监控来看。
故障时 dble 机器的内存图:
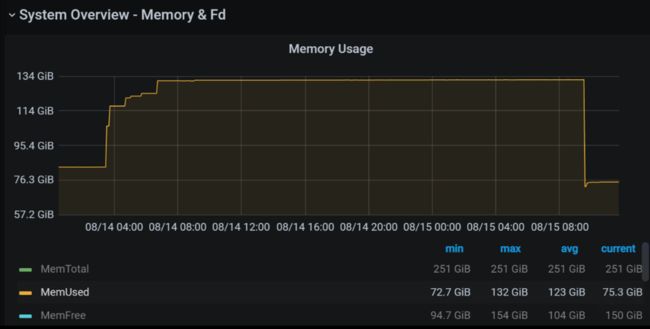
可以看到确实存在短时间攀升。而 dble cpu 当时的使用率也很高。

再来看 dble 中 free buffer的监控图(这个指标是记录dble中Processor的堆外内存使用情况的):
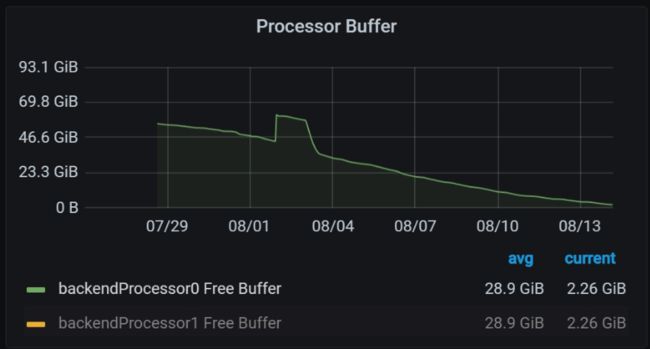
从图中可以看到,从dble启动后堆外内存呈现递减的趋势。
通过上面的监控图,基本可以确认故障发生时的时序关系:
堆外内存长期呈现递减的趋势,堆外内存耗尽之后,在dble中会使用堆内存存储网络报文。
当业务流量比较大时,堆内存被迅速消耗,从而导致频繁的fullgc。这样dble来不及处理MySQL实例心跳的返回报文,就引发了生产上的一些列问题。
堆外内存泄露分析
从上面的分析来看,根因是堆外内存泄露,因此需要排查dble中堆外内存泄露的点。
考虑到dble中分配和释放堆外内存的操作比较集中,采用了btrace 对分配和释放的方法进行了采集。
btrace 脚本
该脚本主要记录分配和释放的对外内存的内存地址。
运行此脚本后,对程序的性能有 10% - 20% 的损耗,且日志量较大,由于堆外内存呈长期递减的趋势,因此只采集了2h的日志进行分析:
package com.actiontech.dble.btrace.script;
import com.sun.btrace.BTraceUtils;
import com.sun.btrace.annotations.*;
import sun.nio.ch.DirectBuffer;
import java.nio.ByteBuffer;
@BTrace(unsafe = true)
public class BTraceDirectByteBuffer {
private BTraceDirectByteBuffer() {
}
@OnMethod(
clazz = "com.actiontech.dble.buffer.DirectByteBufferPool",
method = "recycle",
location = @Location(Kind.RETURN)
)
public static void recycle(@ProbeClassName String pcn, @ProbeMethodName String pmn, ByteBuffer buf) {
String threadName = BTraceUtils.currentThread().getName();
// 排除一些线程的干扰
if (!threadName.contains("writeTo")) {
String js = BTraceUtils.jstackStr(15);
if (!js.contains("heartbeat") && !js.contains("XAAnalysisHandler")) {
BTraceUtils.println(threadName);
if (buf.isDirect()) {
BTraceUtils.println("r:" + ((DirectBuffer) buf).address());
}
BTraceUtils.println(js);
}
}
}
@OnMethod(
clazz = "com.actiontech.dble.buffer.DirectByteBufferPool",
method = "allocate",
location = @Location(Kind.RETURN)
)
public static void allocate(@Return ByteBuffer buf) {
String threadName = BTraceUtils.currentThread().getName();
// 排除一些线程的干扰
if (!threadName.contains("writeTo")) {
String js = BTraceUtils.jstackStr(15);
// 排除心跳等功能的干扰
if (!js.contains("heartbeat") && !js.contains("XAAnalysisHandler")) {
BTraceUtils.println(threadName);
if (buf.isDirect()) {
BTraceUtils.println("a:" + ((DirectBuffer) buf).address());
}
BTraceUtils.println(js);
}
}
}
}分析采集的btrace日志
采集命令:
$ btrace -o 日志的路径 -u 11735 /path/to/BTraceDirectByteBuffer.java过滤出分配的堆外内存的地址:
$ grep '^a:' /tmp/142-20-dble-btrace.log > allocat.txt
$ sed 's/..//' allocat.txt > allocat_addr.txt # 删除前两个字符过滤出释放的堆外内存的地址:
$ grep '^r:' /tmp/142-20-dble-btrace.log > release.txt
$ sed 's/..//' release.txt > release_addr.txt # 删除前两个字符此时取两个文件的差集:
$ sort allocat_addr.txt release_addr.txt | uniq -u > res.txt这样 res.txt 得到的是仅仅分配而没有释放的堆外内存(可能会有不准确)
从中任选几个堆外内存的 address,查看堆栈。排除掉误记录的堆栈后,出现最多的堆栈如下:
complexQueryExecutor176019
a:139999811142058
com.actiontech.dble.buffer.DirectByteBufferPool.allocate(DirectByteBufferPool.java:82)
com.actiontech.dble.net.connection.AbstractConnection.allocate(AbstractConnection.java:395)
com.actiontech.dble.backend.mysql.nio.handler.query.impl.OutputHandler.(OutputHandler.java:51)
com.actiontech.dble.services.factorys.FinalHandlerFactory.createFinalHandler(FinalHandlerFactory.java:28)
com.actiontech.dble.backend.mysql.nio.handler.builder.HandlerBuilder.build(HandlerBuilder.java:90)
com.actiontech.dble.server.NonBlockingSession.executeMultiResultSet(NonBlockingSession.java:608)
com.actiontech.dble.server.NonBlockingSession.lambda$executeMultiSelect$55(NonBlockingSession.java:670)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:748) review 代码
在通过btrace知道了dble中的泄露点之后,下面就回到dble的代码中 review 代码。
首先通过上面的堆栈定位到下面的代码:
// com/actiontech/dble/backend/mysql/nio/handler/builder/HandlerBuilder.java
public RouteResultsetNode build(boolean isHaveHintPlan2Inner) throws Exception {
TraceManager.TraceObject traceObject = TraceManager.serviceTrace(session.getShardingService(), "build&execute-complex-sql");
try {
final long startTime = System.nanoTime();
BaseHandlerBuilder builder = getBuilder(session, node, false);
DMLResponseHandler endHandler = builder.getEndHandler();
// 泄露点在这,dble 会创建 OutputHandler实例,OutputHandler会分配堆外内存
DMLResponseHandler fh = FinalHandlerFactory.createFinalHandler(session);
endHandler.setNextHandler(fh);
...
RouteResultsetNode routeSingleNode = getTryRouteSingleNode(builder, isHaveHintPlan2Inner);
if (routeSingleNode != null)
return routeSingleNode;
HandlerBuilder.startHandler(fh);
session.endComplexExecute();
long endTime = System.nanoTime();
LOGGER.debug("HandlerBuilder.build cost:" + (endTime - startTime));
session.setTraceBuilder(builder);
} finally {
TraceManager.finishSpan(session.getShardingService(), traceObject);
}
return null;
}
// com/actiontech/dble/backend/mysql/nio/handler/query/impl/OutputHandler.java
public OutputHandler(long id, NonBlockingSession session) {
super(id, session);
session.setOutputHandler(this);
this.lock = new ReentrantLock();
this.packetId = (byte) session.getPacketId().get();
this.isBinary = session.isPrepared();
// 分配堆外内存
this.buffer = session.getSource().allocate();
}通过上面的代码可以判断在构造复杂查询执行链的时候会分配堆外内存。
问题到这其实还是没有解决,上述代码仅仅找到了堆外内存分配的地方,堆外内存没有释放仍然有以下几种可能:
- 程序bug导致复杂查询未下发,从而执行链被丢弃而没有回收buffer
- 程序下发了,由于未知bug导致没有释放buffer
dble 中复杂查询的下发和执行都是异步调用并且逻辑链比较复杂,因此很难通过review代码的方式确认是哪种情况导致。
那如何进一步缩小范围呢?
堆内存dump
既然堆外内存泄露的比较快,平常状态下的dump 文件中应该可以找到异常的没有被回收的OutputHandler实例。
在dble 复杂查询的执行链中,OutputHandler 实例的生命周期往往伴随着BaseSelectHandler,因此是否可以通过异常OutputHandler的BaseSelectHandler来确定复杂查询有没有下发来进一步缩小范围。
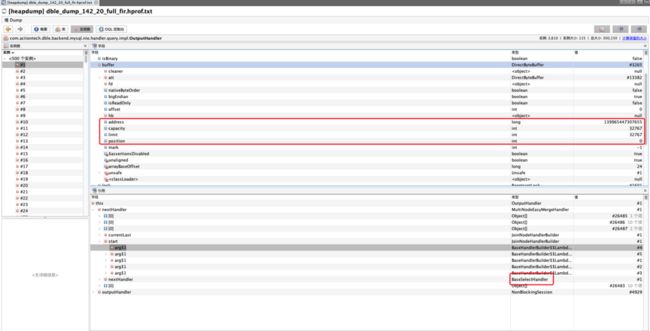
通过现场收集到的异常OutputHandler中buffer的状态是:
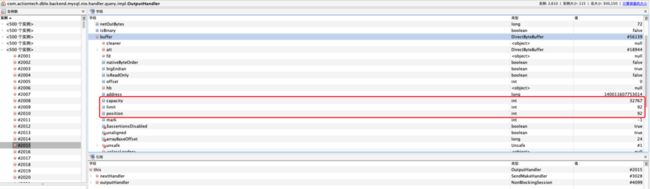
正常写出的OutputHandler中buffer的状态是:
找到的异常的OutputHandler的BaseSelectHandler中状态值:
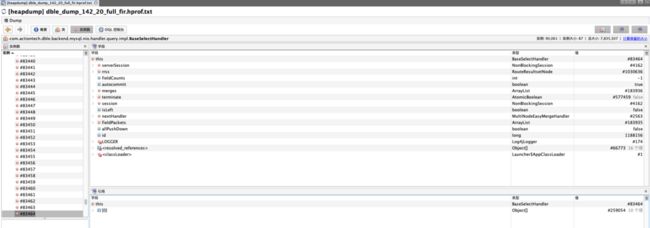
可以看出其中的状态值都是初始值,可以认为,异常的OutputHandler执行链没有被执行就被丢弃了。
这样范围被进一步缩小,此次堆外内存泄露是由于程序bug导致复杂查询的执行链被丢弃而导致的。
重新回到代码中,review 下发复杂查询之前和构造之后的代码:
// com/actiontech/dble/backend/mysql/nio/handler/builder/HandlerBuilder.java
public RouteResultsetNode build(boolean isHaveHintPlan2Inner) throws Exception {
TraceManager.TraceObject traceObject = TraceManager.serviceTrace(session.getShardingService(), "build&execute-complex-sql");
try {
final long startTime = System.nanoTime();
BaseHandlerBuilder builder = getBuilder(session, node, false);
DMLResponseHandler endHandler = builder.getEndHandler();
// 泄露点在这,dble 会创建 OutputHandler,OutputHandler会分配堆外内存
DMLResponseHandler fh = FinalHandlerFactory.createFinalHandler(session);
endHandler.setNextHandler(fh);
...
RouteResultsetNode routeSingleNode = getTryRouteSingleNode(builder, isHaveHintPlan2Inner);
if (routeSingleNode != null)
return routeSingleNode;
// 下发复杂查询,review 之前的代码
HandlerBuilder.startHandler(fh);
session.endComplexExecute();
long endTime = System.nanoTime();
LOGGER.debug("HandlerBuilder.build cost:" + (endTime - startTime));
session.setTraceBuilder(builder);
} finally {
TraceManager.finishSpan(session.getShardingService(), traceObject);
}
return null;
}review 到 startHandler 的时候,上一个语句 return routeSingleNode 引起了我的注意。
按照逻辑,岂不是如果符合条件 routeSingleNode != null ,就不会执行 startHandler,而直接返回了。而且执行链的作用域在本方法内,不存在方法外的回收操作,这不就满足了未下发而直接返回的条件了。
至此,泄露的原因找到了。
修复
修复的话,在OutputHandler中,不采取预分配buffer,而是使用到的时候才会进行分配。
总结
到这里,整个堆外内存泄露的排查就结束了。希望对大家有帮助。