国庆长假已结束,Python 告诉你 6 亿国人都去哪儿浪了

文 | 豆豆
来源:Python 技术「ID: pythonall」

2020 注定是不平凡的一年,一开年就被新冠疫情来了当头一棒,一瞬间大家都不约而同的采取家里蹲策略,在政府的得力领导下,全部人民上下一条心,到了四五月份终于将疫情稳定控制住了,时隔半年,国内疫情早已趋于稳定,人们的生活也基本恢复正常。
恰逢国庆中秋两个节日重合,在家憋这么久的人们怎么能不出去看看祖国的大好河山。据新华网消息,整个国庆长假外出游玩人次达 6.37 亿人次,那么这么多人都到哪儿去玩了呢,今天我们就用 Python 做一个全国热门景区热点图。

整体思路
我们的思路是,在中国地图上标注出热门景点,通过该热点图我们可以一眼看出哪些城市和地区最热门,也就意味着那个地区人是最多的。
那么我们就必须获先取到全国的旅游数据,最简单的思路就是从第三方旅游网站看下哪些景点的门票卖的最多最好,而最常用的网站就是飞猪、携程、去哪儿等。
有了数据来源之后就要想办法将网站的数据通过爬虫的方式爬取下来,之后在对爬取到的数据做清洗、过滤、整理。最后就将格式匹配的数据直接在地图上展示出来即可。
网站获取
经过对比几个第三方旅游网站,发现去哪儿网有一个「热门景点」的内页,在首页输入框直接输入「热门景点」即可直达该页面。该网站还将这些热门景点进行了分类,比如人文景观,城市风貌,古建筑等。同时我们需要的景点名称,城市,景区级别以及景区地址等信息都可以从该页面获取的到。

打开去哪儿网,首页输入「热门景点」仔细观察页面最上方的 URL 你会发现惊喜。其中 subject 就是景点主题,而 page 看样子则是页码,点击下一页验证一下,page 变成 2 了,没猜错。
不需要太多的数据,因此我们在每一个主题下面只取前十页的数据就可以了。
分析完 URL 之后,再来看看数据从什么地方获取的,切换到浏览器开发者模式,浏览下我们发现所有的景点数据都在一个叫做 ”search-list“ 的 div 中。针对单个景点,其数据是在一个 class = ‘sight_item’ 的 div 中。接下来就是解析页面原属,将景点,省市,时间,热度等数据做分析。
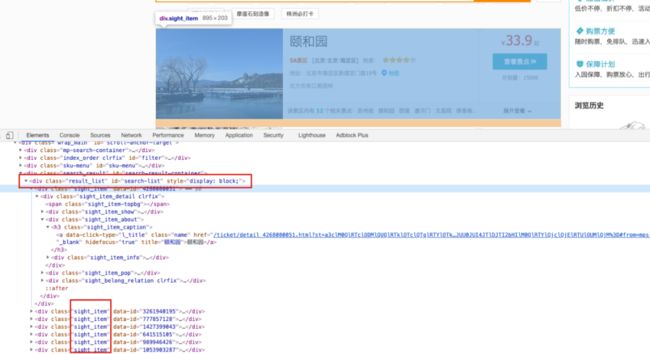
数据获取
数据源头已经分析完毕,接下来就可以开始我们的爬虫编码了,首先定义好我们的准备获取全国景点的主题。为了方便后续操作,我们可以将解析好的数据保存到 csv 文件中。
subjects = ['文化古迹', '自然风光', '农家度假', '游乐场', '展馆', '古建筑', '城市观光']
excel_file = open('data.csv', 'w', encoding='utf-8', newline='')
writer = csv.writer(excel_file)
writer.writerow(['名称', '城市', '类型', '级别', '热度', '地址'])
其次我们需要一个下载网页内容的函数,该函数接受一个 URL 参数,之后返回该 URL 对应的网页内容,同时为了更真实的模拟浏览器请求,需要添加 Headers。
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'referer': 'https://piao.qunar.com/',
'cookie': 'xxxyyyzzz...'
}
def get_page_html(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
获取到内容之后,我们还需要一个解析函数,该函数接收一个网页文本,然后将我们所需要的「名称, 城市, 类型, 级别, 热度, 地址」信息解析出来,并写入 csv 文件。
def parse_content(content, subject):
if not content:
return;
soup = BeautifulSoup(content, "html.parser")
search_list = soup.find(id='search-list')
items = search_list.find_all('div', class_="sight_item")
for item in items:
name = item['data-sight-name']
districts = item['data-districts']
address = item['data-address']
level = item.find('span', class_='level')
level = level.text if level else ''
star = item.find('span', class_='product_star_level')
star = star.text if star else ''
writer.writerow([name, districts, subject, level, star, address])
至此我们已经准备好,下载函数,解析函数,现在只需要直接遍历主题,拼接 URL 调用相关函数即可。为了防止被禁封 IP,每次请求之后让程序暂停 5 秒。
def get_data():
for subject in subjects:
for page in range(10):
page = page + 1
url = F'https://piao.qunar.com/ticket/list.htm?keyword=热门景点®ion=&from=mps_search_suggest&subject={subject}&page={page}&sku='
print(url)
content = get_page_html(url)
parse_content(content, subject, url)
time.sleep(5)
if __name__ == '__main__':
get_data()
最后执行 main 入口函数来运行程序,来看看我们搜集到的数据。

结果展示
获取到全国的旅游数据之后,就可以开始分析了。为了让操作方便,引入 pandas,先仔细看下我们的数据格式。首先热度一列里面含有中文,需要分割,其次因为热度数值是小数不方便操作,因此我们决定将热度扩大 1000 倍,因为是整体扩大了 1000 倍,因此并不会影响分析结果。
之后我们需要解析出该景点所在的城市。同样是分割字符串。同时因为还有一些地点是地图无法识别的,所以要去除。
data = []
with open('data.csv', 'r') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
data.append(row)
df_data = []
for row in data:
city = row[1].split('·')[1]
if city in ['保亭', '德宏', '湘西', '陵水', '黔东南', '黔南']:
continue
star = row[4].split('热度')[1].strip()
star = int(float(star) * 1000)
df_data.append([row[0], city, row[3], star])
df = pd.DataFrame(df_data, columns=['name', 'city', 'level', 'star'])
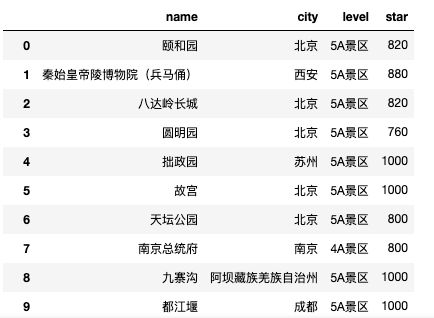
数据准备妥当,绘制热点图。
data = df.groupby(by=['city'])['star'].sum()
citys = list(data.index)
city_stars = list(data)
data = [list(z) for z in zip(citys, city_stars)]
geo = (
Geo()
.add_schema(maptype="china")
.add(
"热点图", #图题
data,
type_=ChartType.HEATMAP, #地图类型
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) #设置是否显示标签
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_ = 5000), #设置legend显示的最大值
title_opts=opts.TitleOpts(title=""), #左上角标题
)
)
geo.render_notebook()
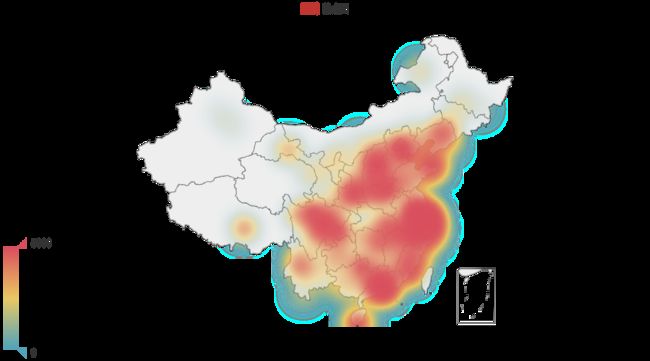
从上图可以看出,东南沿海,北京周边以及云南四川是比较热门的地区。
再来看看 TOP 15 的热点旅游城市:

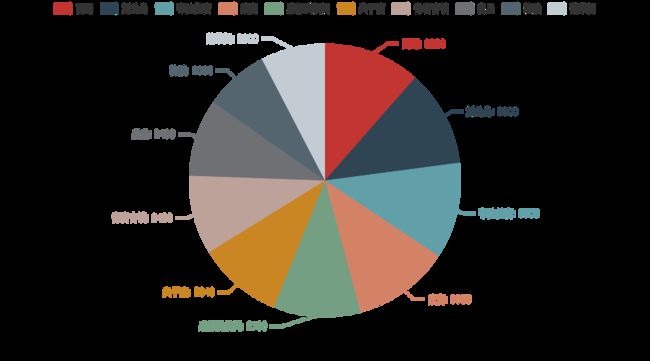
再来看看 TOP 10 的热点旅游景区:
总结
今天我们对去哪儿的国庆热门景点进行了抓取和分析,一整套流程下来还是涉及到不少东西。包括网站分析,数据抓取和清洗以及图标展示。尤其是网页元素分析,需要多点耐心。
分析结果也比较符合预期,风景建筑类地点比较多人想去,毕竟大城市的人天天待格子间,趁着长假多去户外呼吸呼吸新鲜空气,其次北京、上海、杭州、成都等大都市依然很受欢迎。
因为疫情,国庆节可以说是 2020 的第一个旅游黄金周了,就在国外还在为疫情苦苦发愁的时刻,我们的客运航运已经恢复的差不多了,同时为了刺激消费,各个地方政府接连发放各种优惠券,外出游玩的小伙伴们也算是奉旨出游,为我国经济增长贡献了自己的力量。
那么这个国庆节,你去哪浪了呢。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】
识别文末二维码,回复:201015
