Python小知识点——traps
Python小知识点
文章目录
- Python小知识点
-
- 一、Python
-
- 1. tuple
- 2. time()
- 3. and ,or ,not
- 4. argsort()
- 二、Pytorch
-
- 1. torch.squeeze()
- 2. torch.unsqueeze()
- 3. torch.nn.functional.interpolate()
- 4. view()
- 5. torch.nn.function.kl_div()
- 6. transformer
- 7.transform中的rescale
- 8. 将数据转移到GPU()
- 9.muiltiprocessing & main()
- 10.fc:linear() & RuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x1 and 1024x3)
- 11. transform
- 12.lr_schedule()
- 13.cuda()
- 14.设置部分层冻结
- 15. 训练过程:loss无法backward
- 16. clamp()
- 三、Opencv
-
- 1.`cv2.error: OpenCV(4.6.0) /io/opencv/modules/imgproc/src/resize.cpp:4052: error: (-215:Assertion failed) !ssize.empty() in function 'resize'`
- 四、TensorFlow
最近发现好多东西经常不用就忘记了,所以写一篇,随手记录,并且不定时更新自己高频用到的,或者比较重要的小知识点
一、Python
1. tuple
tuple中的值是不可以改变的。但是如果tuple中的元素是list,那么list中的元素是可以改变的,但是只是list中的元素改变了,list还是没有改变的。在使用的过程中可以将tuple转换为list,后进行后续操作。
tuple_to_list = list(tuple_a)
2. time()
一般在训练模型的时候,(或者类似的情况:需要重复前面的工作生成新的result表格或者权重),为了不将前面训练好的东西覆盖,一般在文件名后面增加时间后缀,这样每一次运行的时间戳都是不一样的,所以不会存在运行后前面的结果被覆盖的情况,只需要在前面加上下面,然后在后文中用就OK
import time
# 打印时间戳
start_time = time.time() # 计算1970到现在经过了多长时间,以秒为单位
start_time = time.strftime('%Y-%m-%d-%H-%M',time.localtime(start_time)) # 将以秒为单位的时间转换成自己定义的格式
save_weight_path = f'D:/Python/ConvNext/weights/con_model/con_model_{start_time}.pth'
csv_path = f'D:/Python/ConvNext/result/result_{start_time}.csv'
3. and ,or ,not
大家一定要注意自己逻辑运算符的使用,稍不留神就掉进去了:
for name, para in model.named_parameters():
print(name,('attention' not in name) or ('haed' not in name))
这句的意思是name中只要没有attention或者没有head都会输出TRUE,attention和head也会输出TRUE
4. argsort()
是numpy中对数组排序的函数,返回数组中数值由小到大的index值,当然去负就是由大到小了。
image_pred[(-score).argsort()]
- socre 是一个数组
- 将原本image_pred按照score从大到小排序
二、Pytorch
1. torch.squeeze()
对张量降维
torch.squeeze(input, dim=None, out=None)
当dim没有设置时,默认为None,将输入张量形状中的1去除并返回,如果原始形状是(AB1C1D),输出的形状是(ABCD)。当给定dim时,那么squeeze只发生在给定的维度上 (并且该维度必须为1),例如:输入形状是(A1B),如果squeeze(input,0),则张量不会变,只有用squeeze(input,1)形状才会变为(A*B)
2. torch.unsqueeze()
用于扩展张量维度 (1维变2维,2维变3维…),返回一个新的张量,对输入的既定位置插入维度1
torch.unsqueeze(input, dim, out=None)
# input(tensor): 输入张量
# dim(int):插入维度的索引
# out(tensor/optional):结果为张量
3. torch.nn.functional.interpolate()
实现插值和上采样
可以简单的理解为任何可以让你的图像变成更高分辨率的技术,最简单的方法是重采样和插值。
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
# input(tensor):输入张量
# size(int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]): 输出大小.
# scale_factor (float or Tuple[float]):指定输出为输入的多少倍数。如果输入为tuple,也要制定为tuple类型
# mode (str):可使用的上采样算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’. 默认使用’nearest’
# align_corners (bool, optional) :如果align_corners=True,则对齐 input 和 output 的角点像素(corner pixels),保持在角点像素的值. 只会对 mode=linear, bilinear 和 trilinear 有作用. 默认是 False.
可用于重置大小的mode有:最近邻、线性(3D-only),、双线性, 双三次(bicubic,4D-only)和三线性(trilinear,5D-only)插值算法和area算法
4. view()
view是改变tensor的形状,返回具有相同数据但大小不同的新张量。
5. torch.nn.function.kl_div()
计算两个矩阵之间的kl散度
loss = F.kl_div(input,label,reduction,name)
# input:输入张量
# label:输入张量
# reduction:(可选)可用类型为‘none’ | ‘batchmean’ | ‘mean’ | ‘sum’,‘none’表示无reduction,‘batchmean’ 表示输出的总和除以批大小,‘mean’ 表示所有输出的平均值,‘sum’表示输出的总和。
# name(可选)
注:第一个参数传入的是对数概率矩阵,第二个参数是概率矩阵。
KL散度具有不对称性,存在一个指导和被指导的关系,因此input和label之间的顺序需要确定。如果想要label知道input,第一个参数要传input,即被指导的放在前面,之后求相应的概率和对数概率就行
6. transformer
又是被自己笨到的一个晚上!大家在transformer的时候千万别忘了在transformer后面加上需要增强的图像变量,否则你的img就会变成这样,ndarray显示是空的,因为这或许会出现一些奇奇怪怪的error,比如tuple out of index,我一晚上大部分时间都在这个问题上,虽然我调试了,但是忽视了前面的(),只看到了后面resize的大小是自己设定的大小,谁知,不尽人意,真就逻辑很重要,还有清晰的思维!!
# 错误写法
grade4_cam = transforms.Resize([int(r0*2) + 2, int(r0*2) + 2])
# 正确写法
grade4_cam = transforms.Resize([int(r0*2) + 2, int(r0*2) + 2])(grade4_cam)
劝大家细心!!
- 调试(错误结果)

- 调试(正确结果)

7.transform中的rescale
其中的scale参数可以设置为单个float数,表示缩放的倍数,也可以是float的tuple,表示将行列分开缩放
rescale=1./255
transform.rescale(img, 0.1) # 缩小为原来图片的0.1
transform.rescale(img, [0.5,0.25]) #缩小为原来图片行数一半,列数四分之一
transform.rescale(img, 2) #放大为原来图片大小的2倍
8. 将数据转移到GPU()
x = x.cuda(non_blocking=True)
一般见到的是x=x.cuda()将Tensor加载到GPU上,设置non_blocking参数的原因:
- non_blocking默认值为False, 通常我们会在加载数据时,将DataLoader的参数pin_memory设置为True
- DataLoader中参数pin_memory的作用是:设置生成的Tensor数据存放在哪里,值为True时,意味着生成的Tensor数据存放在锁页内存中,这样内存中的Tensor转义到GPU的显存会更快。
- 主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存(硬盘)进行交换,而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。
如果pin_memory=True的话,将数据放入GPU的时候,也应该把non_blocking打开,这样就只把数据放入GPU而不取出,访问时间会大大减少。
↑ 参考了这篇blog
9.muiltiprocessing & main()
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
在训练模型的时候有的时候会遇到这种错误,其主要原因是代码中如果使用了多线程,必须要写在main()函数中!将所有代码写在main()中
if __name__=="__main__":
...
nw = min([os.cpu_count(), batchsize if batchsize > 1 else 0, 4]) # number of workers
tb_writer = SummaryWriter()
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
#%% 准备train_dataloader和val_dataloader
#利用自定义类Mydataset创建对象train_dataset和train_dataloader
train_dataset = Mydataset(full = full_imgs_path,part = part_imgs_path,labels=labels,transform=data_transform['train'])
train_dataloader = torch.utils.data.DataLoader(train_dataset,
batch_size=batchsize,
shuffle=True,
num_workers=nw) #每次迭代时返回五个数据
10.fc:linear() & RuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x1 and 1024x3)
原始代码
class Conv_con(nn.Module):
def __init__(self, num_classes):
super(Conv_con, self).__init__()
self.fctl = _FCtL(768,768)
self.classifier = nn.Sequential(
nn.Linear(768*7*7, 4096),
nn.ReLU(True),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096,num_classes))
def forward(self, feature_x,feature_y):
features = self.fctl(feature_x,feature_y)
out = self.classifier(features)
return out
错误原因:卷积层的输入为四维[batch_size,channels,H,W] ,而全连接接受维度为2的输入,通常为[batch_size, size]。
改进代码
class Conv_con(nn.Module):
def __init__(self, num_classes):
super(Conv_con, self).__init__()
self.fctl = _FCtL(768,768)
self.classifier = nn.Sequential(
nn.Linear(768*7*7, 4096),
nn.ReLU(True),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096,num_classes))
def forward(self, feature_x,feature_y):
features = self.fctl(feature_x,feature_y)
features = torch.flatten(features, 1)
out = self.classifier(features)
return out
解决方案
# 方法1
x.view(-1,7* 7* 1024)
# 方法2
x = torch.flatten(x,1) //拉成二维向量[batch_size, size]
11. transform
最近想要结合两张图片的信息,进行训练,但是在dataset的过程中需要加载两张图片并数据增强。当时做的时候没有考虑到这一点——transform调用一次就会随机化参数,所以两张图片是两种不同的增强,所以已经丧失了两者之间的关键联系(空间信息)
温馨提醒:大家在写完dataset后,使用dataloader加载完成一定要检查数据的一致性!
12.lr_schedule()
lr_schedule有很多种“模式”,其中常用的三种:
- StepLR
torch.optim.lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1,verbose=False)
step_size (int):学习率调整步长,每经过step_size,学习率更新一次。
gamma (float):学习率调整倍数。
last_epoch (int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。 - MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
当前epoch数满足设定值时,调整学习率。适合后期调试使用,观察loss曲线,为每个实验制定学习率调整时期。
milestones (list):一个包含epoch索引的list,列表中的每个索引代表调整学习率的epoch。list中的值必须是递增的。 如 [20, 50, 100] 表示在epoch为20,50,100时调整学习率。
gamma (float):学习率调整倍数。
last_epoch (int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。 - ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
按指数衰减调整学习率,调整公式:lr = lr*gamma*epoch。
一般在每个epoch进行一次schedule的step!所以一般的格式是:
for epoch in range(epochs):
train_one_epoch()
evaluate()
lr_schedule.step()
13.cuda()
有时在本地代码运行没用问题,但是在服务器上会出现差错,很大程度是代码中网络to(device)转换成cuda版本,但是输入图像没有转换,会出现这样的errorInput type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
解决方法
将原本的输入.cuda(),如:model(img.unsqueeze(0))改为model(img.unsqueeze(0).cuda())
注:一般使用.cuda()默认将模型和变量加载到第一块device上,即如果有两块GPU(0,1),则直接加载到cuda0上面,如果前面的device设置为cuda1device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu"),在代码运行期间就会出现两个数据或者变量不在同一个设备上(一个在cuda0一个在cuda1),因此为了避免这一类的问题,建议搭建不要使用.cuda(),而是将代码写活,将device传过去使用.to(device)
14.设置部分层冻结
这个问题我在之前的一篇中有讲过,但是最近训练模型发现又出现了新的问题。是什么呢?
原本的代码:
if freeze_layers == True:
for name, para in model.named_parameters():
if ("head" not in name) or ("attention" not in name):
para.requires_grad_(False)
else:
continue
原意是将除了head和attention相关的层解冻,其他层冻结,但是最后训练的结果acc只有50%,这一看就是有问题的。打印了各层的梯度情况:
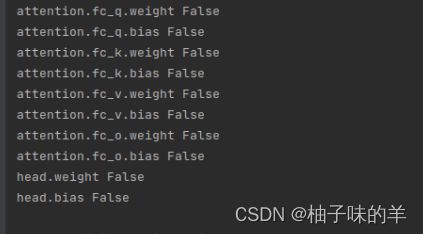
所有层都是冻结的,所以前面的学个啥呢?啥都没学!所以大家擦亮双眼检查好自己的代码是不是真的达到了自己的预期。我改了逻辑以后打印出来的结果是:
if freeze_layers == True:
for name, para in model.named_parameters():
if ("head" in name) or ("attention" in name):
para.requires_grad_(True)
else:
para.requires_grad_(False)

刚刚又看了一下自己的逻辑部分错了,与或非弄错了,所以结果不对,在part1中第三个写了,大家注意逻辑运算!
15. 训练过程:loss无法backward
element 0 of tensors does not require grad and does not have a grad_fn解决方案:
这个错误主要出现在我调试过程中的loss计算后,training过程中,可以看出只有可导的参数在可以backward,但是我的loss之前是没有设置require——grad的,所以在训练过程中error了,只需要将代码改一下:
previous
loss = 0.9 * loss_each_sample + 0.1 * loss_time_series
loss.backward()
now
loss = 0.9 * loss_each_sample + 0.1 * loss_time_series
loss.requires_grad_(True)
loss.backward()
16. clamp()
将torch中的数值控制在[min,max]之间,小于min的值赋值为min,大于max的值赋予max值,可以定义其中的任意一个,也可以两个都定义
torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0)
- torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0),将inter_rect_x2 - inter_rect_x1 + 1数组中小于0的值都赋予0
三、Opencv
1.cv2.error: OpenCV(4.6.0) /io/opencv/modules/imgproc/src/resize.cpp:4052: error: (-215:Assertion failed) !ssize.empty() in function 'resize'
在模型的训练过程中出现这个问题,确定代码没有问题,因为在其他的数据上运行都没有问题,就是dataset中使用的数据在cv2.resize的时候出现了问题,但是检查数据没有问题,这个时候就寻求了帮助,在各种博客上看到各种各样的问题,自己都一一排查,但是没有解决,先说一下网上说的情况:
- 图片读入的路径中存在中文文件夹
- 在图片的文件夹中掺杂非JPG或PNG图片文件的其他文件,如Python运行产生的checkpoint文件或者bat文件等
但是上面的解决方案,都没有解决的我的问题,还有一种说法是说图片质量问题使得图像变成了全零。于是我在dataset的forward函数中增加了打印当前加载图像的全路径,重新运行后,两次都在同一张图片上卡住了,所以最后的解决方案是:删了这张图片,现在一切正常
所以到底是什么问题呢?我查看了原来的图像,不存在质量问题,就很困惑,我猜:可能是中间裁剪之前定位的时候错了