使用pytorch划分数据集和加载数据
1 划分数据集
使用pytorch需要 手动 划分数据集为训练集、验证集、测试集。以下面这个数据集为例对数据集进行划分

#导入工具包
import os
import random
import shutil
from shutil import copy2
def data_set_split(src_data_folder,target_data_folder,train_scale=0.8,val_scale=0.1,test_scale=0.1):
'''
src_data_folder:源文件夹(未划分的数据集)
target_data_folder:目标文件夹(划分后的数据集)
scale:分别为训练集、验证集、测试集所占比例
'''
class_names=os.listdir(src_data_folder)
#返回源数据文件夹下各文件的名字(类名)
#在目标文件夹下创建训练集、验证集、测试集文件夹
split_names=['train','val','test']
for split_name in split_names:
split_path=os.path.join(target_data_folder,split_name)
if os.path.isdir(split_path):
pass
else:
os.makedirs(split_path)
#在三个数据集文件夹下创建类别文件夹
for class_name in class_names:
class_split_path=os.path.join(split_path,class_name)
if os.path.isdir(class_split_path):
pass
else:
os.makedirs(class_split_path)
#按照scale划分数据集,并将源文件夹的数据复制到目标文件夹
#首先遍历数据
for class_name in class_names:
current_class_data_path=os.path.join(src_data_folder,class_name)
current_class_data=os.listdir(current_class_data_path)
current_data_length=len(current_class_data)
current_data_index_list=list(range(current_data_length))
random.shuffle(current_data_index_list)#将所有元素随机排序
#添加数据
train_folder=os.path.join(target_data_folder,'train',class_name)
val_folder=os.path.join(target_data_folder,'val',class_name)
test_folder=os.path.join(target_data_folder,'test',class_name)
train_stop_flag=current_data_length*train_scale
val_stop_flag=current_data_length*(train_scale+val_scale)
current_idx=0
train_num=0
val_num=0
test_num=0
for i in current_data_index_list:
src_img_path=os.path.join(current_class_data_path,current_class_data[i])
if current_idx<=train_stop_flag:
copy2(src_img_path,train_folder)
train_num=train_num+1
elif current_idx>train_stop_flag and current_idx <=val_stop_flag:
copy2(src_img_path,val_folder)
val_num=val_num+1
else:
copy2(src_img_path,test_folder)
test_num=test_num+1
current_idx=current_idx+1
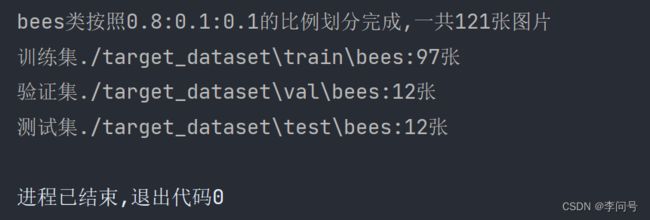
print("{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name,train_scale,val_scale,test_scale))
print("训练集{}:{}张".format(train_folder,train_num))
print("验证集{}:{}张".format(val_folder,val_num))
print("测试集{}:{}张".format(test_folder,test_num))
if __name__ =='__main__':
src_data_folder='./hymenoptera_data/train'
target_data_folder='./target_dataset'
data_set_split(src_data_folder,target_data_folder)
实验结果
2 加载数据
训练时:进行数据增强和归一化
验证时:归一化
import os
import torch
from torchvision import transforms, datasets
data_transforms={
"train":transforms.Compose([
transforms.RandomResizedCrop(224),#随即裁剪
transforms.RandomHorizontalFlip(),#随机水平翻转
transforms.ToTensor(),#RGB——>tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"val":transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
data_dir='./hymenoptera_data'
image_datasets={x:datasets.ImageFolder(os.path.join(data_dir,x),
data_transforms[x])
for x in ['train','val']}
'''
ImageFolder(root,transform=None,target_transform=None,loader=default_loader)
root: 图片总目录,子层级为各类型对应的文件目录。
transform: 对PIL image进行转换操作,
'''
dataloaders={x:torch.utils.data.DataLoader(image_datasets[x],batch_size=4,
shuffle=True,num_workers=1)
for x in ['train','val']}
dataset_sizes={x:len(image_datasets[x]) for x in ['train','val']}
class_names=image_datasets['train'].classes
device=torch.device("cuda:1" if torch.cuda.is_available() else "cpu")