如何将 Transformer 应用于时间序列模型
在机器学习的广阔前景中,transformers 就像建筑奇迹一样高高耸立,以其复杂的设计和捕获复杂关系的能力重塑了我们处理和理解大量数据的方式。
自 2017 年创建第一个 Transformer 以来,Transformer 类型呈爆炸式增长,其中包括 ChatGPT 和 DALL-E 等强大的生成式 AI 模型。虽然transformers 在文本到文本或文本到图像模型中非常有效,但将transformers 应用于时间序列时存在一些挑战。在 2023 年北美开源峰会 上,Ezequiel Lanza 分享了 transformers 模型的问题,并介绍了新的 transformers ,这些 transformers 开始在时间序列方面显示出有希望的结果。
这篇文章[1]不会深入探讨技术方面的内容,但如果您想阅读更多内容,我们将在全文中提供重要论文的链接。

Transformer 功能概述
让我们看看 Transformer 在 Stable Diffusion 中的作用,这是一种深度学习模型,可以将短语(例如“戴眼镜的狗”)转换为图像。转换器接收用户输入的文本并生成文本嵌入。文本嵌入是可以由卷积神经网络 (CNN)(在本例中为 U-NET)读取的文本表示。虽然稳定扩散模型使用嵌入来生成图像,但嵌入可用于生成对时间序列模型有用的附加输出。
Transformer 如何工作
为了理解如何将 Transformer 应用到时间序列模型中,我们需要关注 Transformer 架构的三个关键部分:
- 嵌入和位置编码
- 编码器:计算多头自注意力
- 解码器:计算多头自注意力
作为一个例子,我们将解释普通Transformer 是如何工作的,这是一种将简单短语从一种语言翻译成另一种语言的Transformer 。
- 嵌入和位置编码:如何表示输入数据
当您将短语“我爱狗”输入普通转换器时,一种名为 Word2Vec 的算法会将每个单词转换为数字列表(称为向量)。每个向量都包含有关单词含义以及它与其他单词如何相关的信息,例如同义词和反义词。
模型还必须理解短语中每个单词的位置。例如,“我爱狗”与“我爱狗”的含义不同。第二种算法称为位置向量,它使用复杂的数学方程来帮助您的模型理解句子顺序。将 Word2Vec 和位置向量算法提供的信息打包在一起,就是所谓的文本嵌入,或者以机器可以读取的方式表示的原始短语。
- 编码器级别的多头自注意力
接下来,编码器接收文本嵌入并将其转换为新的向量,添加信息以帮助模型辨别短语中单词之间的关系。例如,在短语“孩子们在公园里玩耍”中,编码器会将最大权重分配给“孩子”、“玩耍”和“公园”。我们称这个过程为自注意力,因为它决定了模型应该最关注哪些单词。
为了计算自注意力,编码器为每个单词创建三个向量——查询向量、键向量和值向量。通过将短语乘以三个矩阵来创建向量。这是一个复杂的算法,但需要理解的重要部分是短语中的每个单词都会与短语中的每个其他单词相乘,并且可能需要大量时间来计算长短语的注意力。
为了更好地理解单词之间的关系,自注意力层可以同时运行多个头。这个过程称为多头注意力,它允许模型同时关注短语的不同部分,例如当存在短期和长期依赖性时。例如,在短语“动物没有过马路,因为它太累了”中,多头注意力告诉模型“动物”和“它”指的是同一个想法。
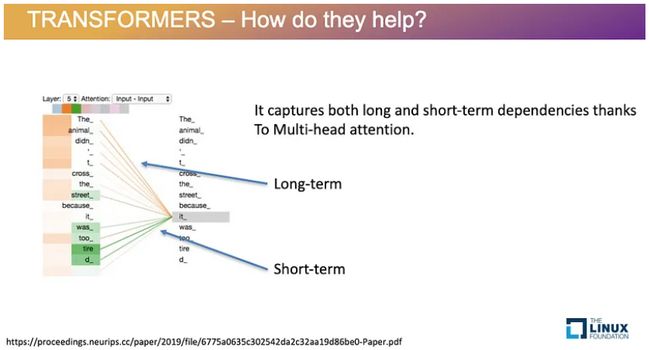
- 解码器级别的多头自注意力
解码器的工作方式与编码器相同,只是它是使用不同的数据集进行训练的。例如,在普通 Transformer 中,如果编码器接受过英语数据训练,解码器接受过法语数据训练,则解码器将运行相同的多头自注意力算法,将原始短语翻译成法语。
使用时间序列转换器
为什么这种Transformer 架构不适用于时间序列?时间序列在某些方面就像一种语言,但它与传统语言不同。在语言中,您可以使用截然不同的单词或句子顺序来表达相同的想法。一旦基于语言的转换器(例如 vanilla)接受了某种语言的训练,它就可以理解单词之间的关系,因此当您用两个不同的输入表示一个想法时,转换器仍然会得出大致相同的含义。然而,时间序列需要严格的顺序——数据点的顺序更重要。这对使用时间序列转换器提出了挑战。
让我们看看我们目前如何解决这个问题以及为什么这些模型存在不足。
- 目前的方法
自回归积分移动平均 (ARIMA) 模型适用于某些时间序列,但需要深入了解相关趋势、季节性变化和残差值,即使如此,它也仅适用于线性相关性。在许多具有多元问题特征的时间序列中,依赖关系之间的关系不是线性的,ARIMA 不起作用。
还有几种使用神经网络的方法。
-
前馈神经网络 (FNN) 模型使用系列中任何前六个数据点来预测接下来的六个数据点。尽管 FNN 支持非线性依赖性,但它们要求您手工制作一个专注于非常具体的问题或数据子集的模型,这使得为大型数据集构建该模型过于耗时。
-
在循环神经网络 (RNN) 模型中,您可以向模型提供与时间序列相关的一小部分数据点,RNN 中的单元将记住哪些数据点很重要以及它们的权重是多少。然而,当您处理具有长期依赖性的数据集时,权重变得不那么相关,并且模型的准确性随着时间的推移而降低。
-
长短期记忆 (LSTM) 模型与 RNN 类似,不同之处在于每个单元都有一个记忆,允许您在长序列期间更频繁地更新权重。这使得 LSTM 成为某些用例的良好解决方案。
-
Seq2seq 是一种提高 LSTM 性能的方法。您可以将数据输入编码器,而不是直接输入网络,编码器会生成输入的特征并输入解码器。
-
Transformer 如何改进时间序列?
使用 Transformer 启用的多头注意力可以帮助改进时间序列模型处理长期依赖性的方式,从而提供优于当前方法的优势。为了让您了解变压器对于长依赖关系的工作效果如何,请考虑 ChatGPT 可以在基于语言的模型中生成的长而详细的响应。通过允许一个头专注于长期依赖性,而另一个头专注于短期依赖性,将多头注意力应用于时间序列可以产生类似的好处。我们相信 Transformer 可以让时间序列模型预测未来多达 1,000 个数据点,甚至更多。
- 二次复杂度问题
Transformer 计算多头自注意力的方式对于时间序列来说是有问题的。由于系列中的数据点必须乘以系列中的每个其他数据点,因此添加到输入中的每个数据点都会以指数方式增加计算注意力所需的时间。这称为二次复杂度,在处理长序列时会产生计算瓶颈。

改进时间序列的 Transformer 模型
今年早些时候发布的一项调查确定了在将 Transformer 应用于时间序列之前需要解决的两项重要网络修改:
- 位置编码:我们如何表示输入数据
- 注意力模块:降低时间复杂度的方法
下一部分将介绍主要要点,但您可以阅读调查以了解有关修改及其结果的更多详细信息。
- 网络修改1:位置编码
2019 年,我们尝试在普通 Transformer 中应用 Word2Vec 编码过程,但该模型无法充分利用时间序列的重要特征。 Vanilla Transformer 擅长辨别单词之间的关系,但不擅长遵循数据序列中的严格顺序。阅读更多。
2021 年,我们创建了可学习的文本嵌入,使我们能够在输入中包含额外的位置编码信息。与普通 Transformer 中的固定编码相比,可学习的位置编码允许 Transformer 更加灵活并更好地利用顺序排序信息。这有助于 Transformer 了解有关时间序列的更重要的上下文,例如季节信息。
- 网络修改2:注意力模块
为了降低注意力层的二次复杂度,新的 Transformer 引入了 ProbSparse Attention 的概念。通过使注意力层仅使用最重要的数据点而不是所有数据点来计算权重和概率,ProbSparse 有助于大大减少计算注意力所需的时间。

测试新 「Transformers」
虽然 LogTrans、Pyraformer 和 FEDformer 等许多新 Transformer 都纳入了这些网络修改,但这里我们重点关注 Informer 和 Spacetimeformer,因为它们是开源的。 GitHub 存储库提供参考文档和示例,让您可以轻松根据数据微调模型,而无需了解关注层的每个细节。
让我们看看 Informer 和 Spacetimeformer 如何利用这些网络修改,看看它们会生成什么样的结果。
- 「Informer」 架构
Informer Transformer 使您能够向它们提供有关季节性、每月或假期趋势的重要信息,以帮助模型了解一年中数据行为方式的细微差异。例如,您的数据集在夏季的表现可能与冬季不同。通过位置编码,您可以告诉模型在一年中的不同时间使用不同的权重,从而使您可以更好地控制输入的质量。
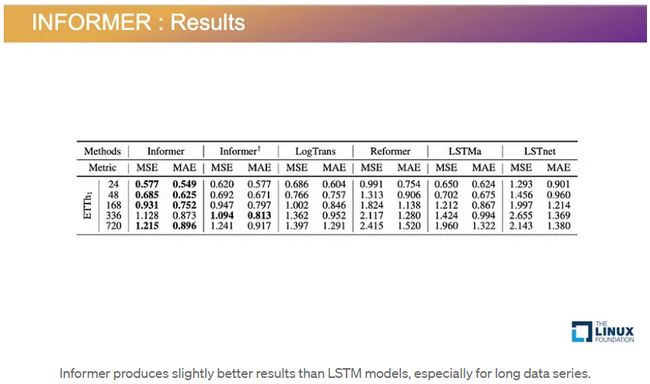
通过结合 ProbSparse 注意力模型和位置编码,Informer 比 LSTM 等传统 Transformer 具有性能优势。当预测未来 24 个数据点时,Informer 产生的均方误差 (MSE) 为 0.577,比 LSTM 的 MSE 0.650 稍好一些。当预测 720 个数据点时,性能差异更大,Informer 的 MSE 为 1.215,而 LSTM 的 MSE 为 1.960。我们可以得出的结论是,Informer 在长序列中提供了稍微更好的结果,但 LSTM 对于某些短期用例仍然可能产生良好的结果。
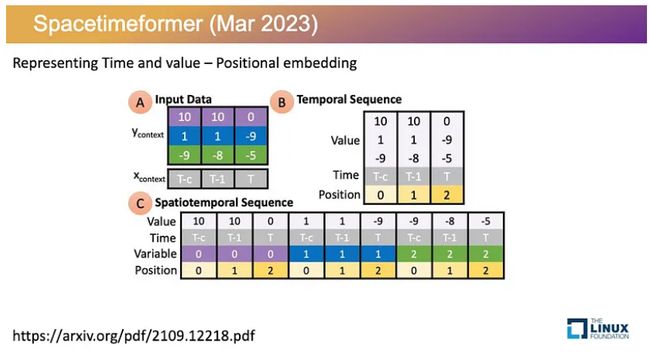
「Spacetimeformer」 架构
Spacetimeformer 提出了一种表示输入的新方法。像 Informer 这样的时间注意力模型表示单个输入标记中每个时间步长的多个变量的值,它没有考虑特征之间的空间关系。图注意力模型允许您手动表示特征之间的关系,但依赖于不能随时间变化的硬编码图。
Spacetimeformer 结合了时间和空间注意力方法,创建一个输入标记来表示给定时间单个特征的值。这有助于模型更多地了解空间、时间和价值信息之间的关系。
与 Informer 一样,Spacetimeformer 提供的结果比 LSTM 稍好一些。在预测未来 40 小时时,Spacetimeformer 的 MSE 为 12.49,略好于 LSTM 的 MSE 14.29。虽然对于较长的序列,这一裕度会变大,但 Spacetimeformer 尚未为每个用例提供比 LSTM 更好的结果。

用例:微服务架构上的延迟
让我们将时间序列模型应用于在线精品店。该商店有 11 个微服务,包括允许用户添加和删除商品的购物车服务以及允许用户搜索单个产品的目录服务。

为了演示对最终用户的影响,我们将预测用户必须等待每个微服务处理请求的时间。基于每个服务之前 360 个数据点的模型,我们对未来的 36 个数据点进行了短期预测,并对未来的 120 个数据点进行了长期预测。
在预测接下来的 36 个数据点时,Informer 产生的 MSE 为 0.6,略优于 LSTM。然而,Informer 需要更多时间来处理。长模型的结果也是如此:Informer 的预测更准确,但处理时间更长。
 image-20230917230120011
image-20230917230120011
测试
时间序列的复杂性各不相同,因此测试模型以找到最适合您的用例的模型非常重要。虽然 LSTM 等传统模型是某些短期时间序列的有力选择,但 Informer 和 Spacetimeformer 可以为长期序列提供更准确的预测。随着我们继续对注意力层以及输入数据的表示方式进行优化,我们预计性能将会提高。此外,作为开源框架,Informer 和 Spacetimeformer 使安装模型并开始使用数据进行测试变得更加容易。
Reference
[1]Source: https://medium.com/intel-tech/how-to-apply-transformers-to-time-series-models-spacetimeformer-e452f2825d2e
本文由 mdnice 多平台发布