数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设计
“Krypton 源于 DC 宇宙中的氪星,它是超人的故乡,以氪元素命名”。
引言
近些年, 在复杂的分析需求之外,字节内部的业务对于实时数据的在线服务能力也提出了更高的要求。大部分业务不得不采用多套系统来应对不同的 Workload,虽然能满足需求,但也带来了不同系统数据一致性的问题,多个系统之间的 ETL 也浪费了大量的资源, 同时对于研发人员来讲,也不得不学习维护多套系统。为了解决这个问题,我们开启了 Krypton 项目,这是字节跳动基础架构 计算-实时引擎, 创新应用中心, 存储-HDFS & NoSQL 团队共同合作研发的新一代面向复杂业务的实时服务分析系统(HSAP: Hybrid Serving and Analytical Processing),希望能在应对大数据复杂分析场景的同时,也能满足业务对于实时数据在线服务的需求。
论文链接: https://www.vldb.org/pvldb/vol16/p3528-chen.pdf
背景与介绍
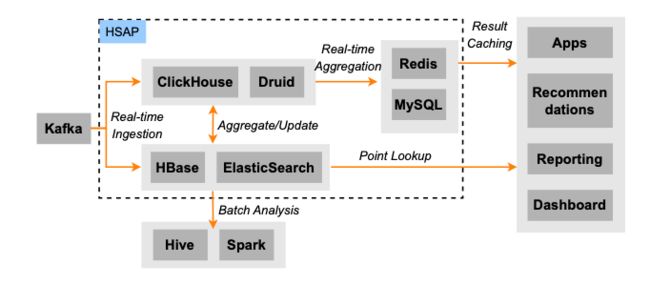
上图是字节典型的广告后端架构,数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:
-
可伸缩。我们希望设计一款能够应对各种 Workload 的系统,对于不同的 Workload,系统的各个组件都可以自由的进行伸缩。
-
高并发低时延。为了应对线上 Serving 场景的需求,系统需要能够满足百万级别的并发和毫秒级别的时延需求。
-
数据强一致。我们的客户希望数据能够实现原子性导入,并能够支持 Snapshot Read。
-
高时效性。大部分用户都需要数据亚秒级别可见,部分 Serving 场景下,用户需要数据毫秒级别的可见。
-
高吞吐导入。大数据场景下,导入性能十分关键。
-
标准 SQL 支持。用户很多都是从 MySQL 这样的系统迁移过来,所以 ANSI SQL 的支持对于用户的迁移十分关键。
系统概览
数据模型
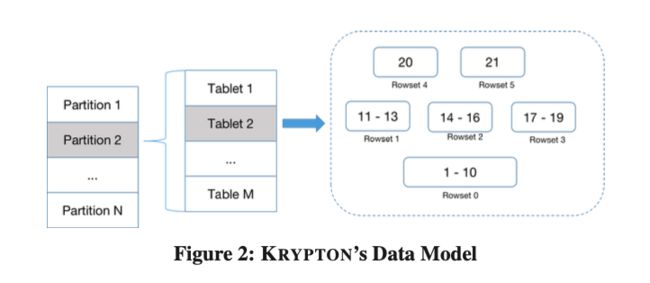
如图所示,Krypton 支持两层分区,第一层叫做 Partition,第二层我们称为 Tablet,每一层都支持 Range/Hash/List 的分区策略。每个 Tablet 都包含一组 Rowsets,每个 Rowset 内部数据按照 Schema 中定义的 Sort Key 排好序。 Rowset 有版本号的概念,同一个 Primary Key 对应的行可能在不同的 Rowset 中存在多份,读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带上数据的版本号从而实现 Snapshot Read。
根据不同的合并算法,Krypton 支持了三种表模型:
-
Duplicate Table:相同的行存在多份。
-
Unique Table:系统需要定义 Primary Key(PK),相同的 PK 只会存在一份,高版本覆盖低版本。
-
Aggregate Table:和 Unique Table 类似,需要定义 PK,但是相同 PK 多行的合并算法不同列可以自定义。
架构
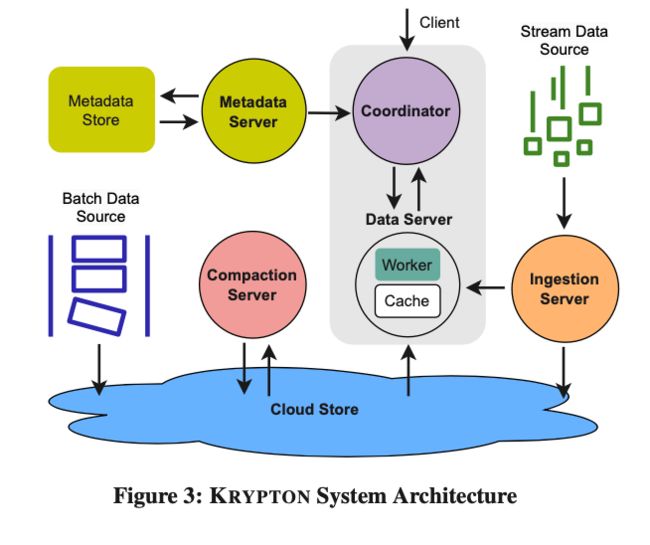
如上图所示,Krypton 的架构有如下几个特点:
-
存算分离
-
Krypton 的数据存放在了 Cloud Store 上,例如:HDFS、标准对象存储接口 S3 等;元数据也放在了外部的存储系统中,例如:ZK 及分布式 KV 等系统。
-
-
读写分离
-
Ingestion Server 负责数据的导入,Compaction Server 负责将数据定期 Merge。数据导入后,Ingestion Server 会写 WAL,同时数据进入内存 Buffer,Buffer 满了 Flush 成列存文件到 Cloud Store 上,并向 Meta Server 注册新的数据,更新相关的 Tablet 的 Commit Version。
-
Coordinator 和 Data Server 组成了读链路,Coordinator 会访问 Meta Server 得到 Schema 和数据的最新版本号,生成分布式执行 Plan 下发给 Data Server,Data Server 负责 Query Plan 的执行。Krypton 的 Query Processor 采用了 MPP 的执行模式。
-
为了提供更好的数据可见性,我们支持了 Dirty Read 的功能,也就是 Data Server 可以直接访问 Ingestion Server 内存中的数据,提供毫秒级别的数据可见性。
-
-
Cache
-
为了支持在线 Serving 低时延的需求,我们在 Cooridinator 支持了Metadata Cache, Plan Cache 和 Result Cache。在 Data Server 内部支持了数据的多级 Cache,包括 DRAM、PMEM 和 SSD 多种介质。为了减小毛刺,我们还支持 Cache 的预热功能,新的数据在注册到 Meta Server 之前会通知 Data Server 先行加载。
-
物化视图
Materialized View(MV)无论在 Serving 场景还是在 AP 场景下都扮演了一个十分重要的角色。 Krypton 基于自己的架构特点,实现了一套单表实时强一致的 MV 策略,并且 MV 无需与 Base Table 保持相同的分区策略。
MV Maintainance
在 Ingestion Server 内部,当 Base 表内存里的数据需要 Flush 的时候,会执行 MV Query 将这部分内存的数据转换成 MV 的数据,MV 的数据与 Base 表的数据会执行原子性的 Flush,都 Flush 成功后,会向 Meta Server 注册, 原子性的更新 Base 表与 MV 的版本号,保证了 MV 与 Base 表的数据一致性。
Query Rewrite
这里介绍了一种比较特殊的改写场景,这个场景也是来自于字节内部业务。原始 Query 是对一个时间窗口内的数据做聚合,比如如下的 SQL:

由于需要聚合的数据量比较大,线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体做法如下:
-
为原始表创建两个 MV,一个按照天聚合,一个按照小时进行聚合。
-
将 Query 中的时间窗口拆分成三部分:
-
2022- 05-01 00:00:00 - 2022-05-09 00:00:00
-
2022-05-09 00:00:00 - 2022-05-09 14:00:00
-
2022-05-09 14:00:00 - 2022-05-09 14:12:15
-
-
对于 2.a 的时间窗直接查询天级别的 MV,2.b 的时间窗查询小时级别的 MV,2.c 的时间窗查询明细表,最后将三部分的结果 Merge 到一起。
整个 Query 的改写由 Optimizer 自动完成,用户无需感知。
Automatic Data Model Derivation
另外,MV 作为一种特殊的表,也可以选择使用不同的表模型,Krypton 基于 Base 表的表模型和 MV Query 可以自动推导出 MV 的表模型,减轻用户的负担。
Query Processor
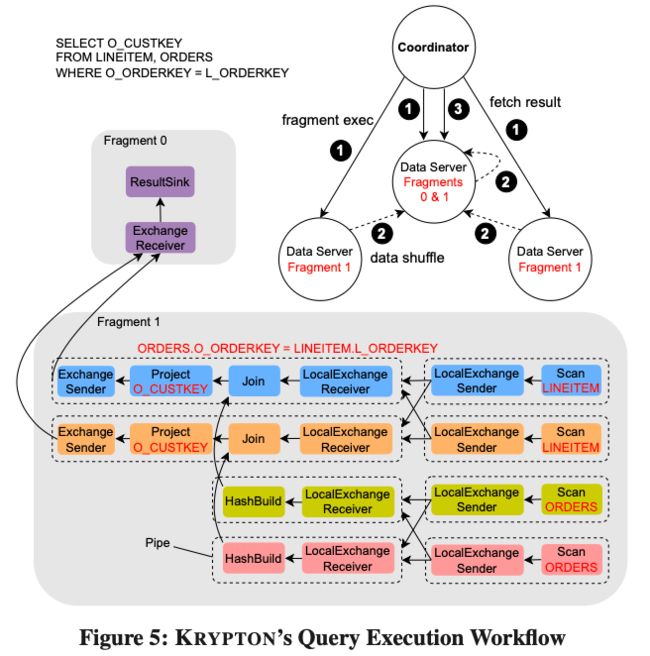
Krytpon 实现了 Push-based 的向量化引擎,并采用了基于 Coroutine 的异步调度执行框架。以上图为例,展示了一个 Query 的执行流程。Coordinator 会把优化过的 Query 生成 Fragments 并下发给一组 Data Servers 来执行。比如上图的 Query 生成了两组 Fragments:Fragment 0 和 Fragment 1。Fragment 1 负责执行两表的 Scan 并进行 Colocate Join,生成的结果 Shuffle 给 Fragment 0 所在的 Data Server,Fragment 0 负责将数据聚合在一起后被 Coordinator 定期的取走。其中 Fragment 1 内部还会被切分成多个 Pipe,每个 Pipe 都由一组 Operators 组成,这些 Pipe 的执行逻辑上不会阻塞。不同的 Pipe 之间通过一个 Local Exchanger 的算子连接起来,不同的 Pipe 可以设置不同的并发度。
统计信息与 Query Cache
-
Query Cache
-
Cache Maintainance: 为了防止使用过期的数据,在 Cache Key 中加入了版本号的信息,并且后台有个线程定期的与 Meta Server 中的数据版本进行对比,并移除掉过期的 Cache Entry。
-
Plan/Stats/Result Cache: Coordinator中会把Query plan cache住,对于一些Query Fragment的selectivity估算信息也会cache下来,最后Query 执行的结果也会被Cache 住,这种通常使用在数据不经常更新,相同 Queries 比较多的场景下。另外,Krypton 也会 Cache Query 执行的一些中间结果,可以更有效的被其他的 Query 使用。
-
-
Statistics
-
Incremental Stats: Krypton 动态的维护了 Table Row Count 和 Column 的 NDV。NDV 使用了 HLL 来进行增量的计算。Ingestion Server Flush 数据的时候,会把内存中数据的 Row Count 与 HLL NDV 计算出来提交给 Meta Server。
-
Dynamic Sampling: 对于 Filter Selectivity 的预估,Krypton 在 Plan 阶段会直接发一个 Sample Query Plan Fragment 来收集统计信息,TPCH-1T 的测试集上,Sample 数据的统计预估和支持数据的统计值只相差 1%,Sample Query 执行的 Overhead 不超过执行时长的 2%。 另外我们的 Query 在执行完毕后,会收集一些轻量的统计信息和结果一起返回给 Coordinator 帮助优化器更新统计信息。
-
并发控制
Krypton 使用了静态和动态相结合的方式来决定 Query 执行的并发度。
-
在 Plan 阶段,Optimizer 会根据 Data Server 的数目,来决定 Fragment 级别和 Pipe 级别的并发度,这么做可以避免动态修改 Plan 带来的额外开销,并且可以尽可能的去掉 Local Exchanger 避免数据的 Shuffle。
-
在执行阶段,每个 Pipe 对应一个 Execution Task,Task 会交给一个相应的 Coro Thread 来执行,具体执行的并发度以及执行的顺序,是由底层 Coro-scheduler 根据当前系统的情况动态的决定的。我们可以给不同 Task 设置不同的 Priority,当碰到优先级更高的task时,Coro-scheduler会动态的减少在途的task对应的coro-threads数目。另外 Coro-thread 相比 pthread 而言,Context Switch 的开销要小很多,并且 IO 操作可以异步化,这样做能够更充分的利用 CPU。
资源隔离
Serving 与 AP 的 Workload 相差较大,因此资源隔离对于混合 Workload 的场景十分重要,Krypton 实现了两级的资源隔离策略。
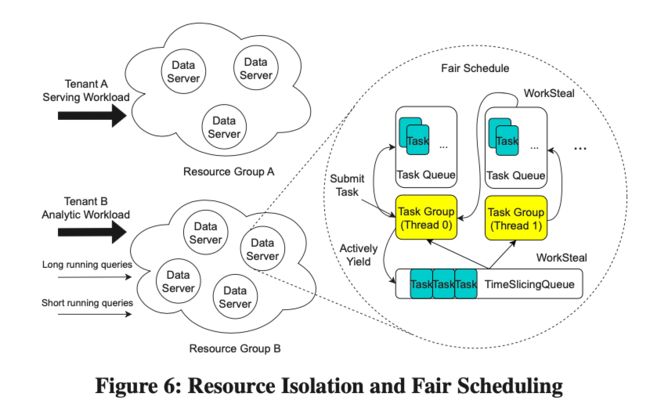
1.DS Instance 粒度的资源隔离
由于 Krypton 采用了云原生部署的模式,每个 DS Instance 对应一个容器,因此我们完全可以把 DS Instance 划分成多个 Resource Group,不同的 Workload 通过 Resource Group 实现隔离。由于 Krypton 存算分离的特点,多个 Resource Group 可以共享一份数据。对于一些临时的 ETL Queries,Krypton 可以快速拉起一些资源进行处理,处理完后再将资源释放。
2.DS 内部基于 Coro 的资源隔离
在同一个 Resource Group 内部,不同的 Query 也需要进行隔离,Krypton 提供了一个基于 Coroutine 的公平调度策略。 如图 6 所示,每一个 Core 都绑定了一个 Task Group,它管理了所有分配给它的 Tasks, 这里每个 Task 对应一个 Coro-thread,在执行期间,Task 被提交到 Local Task Queue 中等待执行,在一段时间 t 之后,没有完成的 Local Task 会被放进 Global 的 Time-slicing Queue 中。当 Local Task Queue 空了的时候,对应的 Task Group 会到 Global Queue 里面取 Tasks,其中 Global Queue 的优先级是基于每个 Task 已经消耗得 CPU Time。这便是公平调度算法的基本原理。
Serving 场景下特有的优化
1.Lightweight API
在 Serving 场景下,通常每个 Query 都不是很复杂,返回的结果数量也不多。因此 Coordinator 当发现生成的是一个 Single Node Plan 的时候,便会直接调用相应 DS 的 Lightweight API 来获取结果。Lightweight API 避免了大 Query 下多次 RPC 通信的问题,也避免了大量的线程切换。
2.Dirty Read
对于时效性要求比较高的场景,我们提供了 Dirty Read 的功能。Coordinator 带着 Commited Version 将 Query 下发给 DS 后,DS 去 Ingestion Server 内存里获取 Uncommited 的那部分数据,返回后和 Committed 的数据进行合并。Ingestion Server 在把内存中的数据 Flush 到 HDFS 后,还会把这部分数据多 Cache 一段时间,保证 Dirty Read 的 Request 一定能拿到 Committed Version 之后的那部分数据,不会出现数据空洞。
多级 Cache
为了满足性能的需求,Krypton 在 Data Server 内部实现了一个多级 Cache,可以使用 DRAM、PMEM 和 SSD 来作为 Cache 的存储介质。如下图所示,Cache 模块包含了三个部分:Cache Index、Replacement Policy 和 Cache Storage Engine。
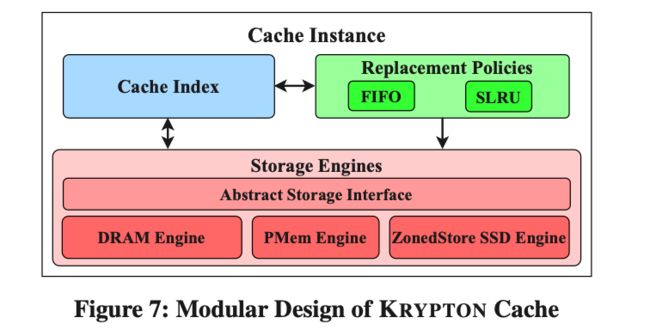
Replacement Policy
AP 经常需要扫描大量的数据,但是 Serving 具有明显的数据访问局部性。因为我们的 Cache 的替换策略为了保证 Serving 的性能,需要具有“抗扫描”的特性。
我们选择了 SLRU 作为我们的 Cache 替换策略。除了具有“抗扫描”的特性之外,这个策略对于访问已经在 Cache 中的数据无需再次加锁,并且相对于 MemCached 的 SLRU,我们使用了无锁 Hash Table 来存储 Cache Index,进一步减少了锁带来的开销。与 FIFO 策略相比,在 Serving 场景下,我们的策略在 P99 Latency 上有 28%的提升。
NUMA-Aware Async PMem Write
PMem 在读的 Latency 和吞吐上具有优势,但是写的带宽是性能瓶颈。 PMem 写带宽仅为 DRAM 写带宽的六分之一,低于读带宽的并发访问水平,并且在跨 NUMA 节点访问时性能还会剧烈下降。
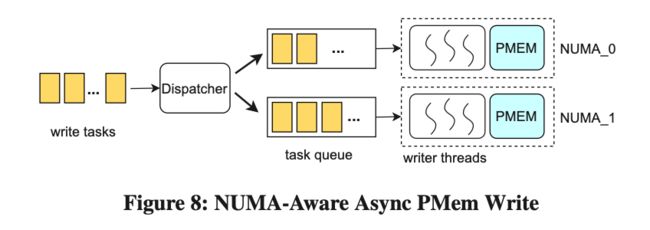
Krypton 实现了一套基于 NUMA 的异步写策略来提高 PMem 写入的性能。如上图所示,每一个 PMem 设备都有一个写线程池对应,并且绑定在了一个 NUMA 节点上,负责所有对这个 PMem 设备的写入。异步的写任务会被分配给对应的线程池处理。经过测试,在每个 Thread Pool 有 3 个 Thread 的情况下,PMem 的写入性能提高了 23%。
ZonedStore Based SSD Cache
SSD Cache 可以让 Krypton 尽可能多的把数据 Cache 在本地,并且当系统重启的时候可以快速的 Warm Up。在字节内部,大部分的 SSD Cache 都是使用了类似于 Rocksdb 这种 LSM Tree 架构的 KV 存储,但是 LSM Tree 并非为 SSD Cache 所设计,他造成了大量的空间浪费和读写放大。为了解决这个问题,我们设计了 ZonedStore。
ZonedStore 把 SSD 切分成了多个相等大小的 Zones,其中只有一个 Zone 是可写的,新写入的数据会顺序的追加写在当前可写 Zone 中,这可以减少 SSD 内部的写放大。因为在 ZonedStore 中,大部分的 Cache Item 都大于 4kb, 这让我们可以把所有 Items 的索引放在内存中来加速查询,减少读放大。为了在重启的时候提高 Index Recovery 的速度,我们会将一个 Summary Segment 写入到 Zone 的最后。
ZonedStore 是按照 Zone 的粒度来回收空间。每个 Zone 的垃圾比率和访问频率会在内存中的 Zone Metadata 中记录,GC 的策略会选择垃圾比例高访问率低的 Zone 来回收。对于淘汰的 Cache Item,我们会标记为 Soft-deleted,因为 Krypton 中 Cache 的数据是 Immutable 的,所以这些 Cache Items 在被回收之前仍然是可以用来提供在线服务。 ZoneStore 为了控制 GC 带来的写放大,会直接把回收的 Zone 的有效数据也直接丢弃掉。
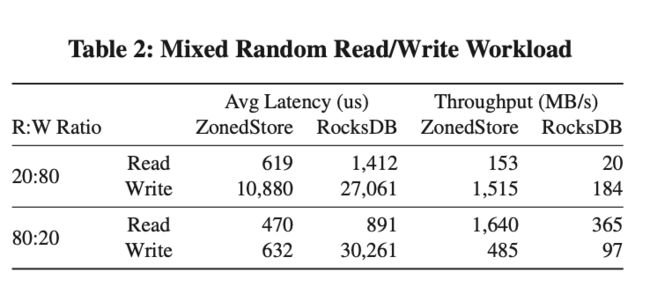
从上图中可以看到,无论在哪种 Workload 下,不管是 Latency 还是 Throughput,ZonedStore 相比 RocksDB 都有比较大的提升。
存储格式
为了同时应对 Serving 和 AP 两种 Workload,Krypton 设计了自己的存储文件格式。Data Page (1MB)是数据读写的基本单元,整个文件分成了 Data、Index、Meta 三部分,每一部分都是按照 Column 进行分区。处理 Query 时,先利用 Index 来过滤出需要读的 Data Page,然后再访问 Data Page。
Encoding and Index Algorithms
Krypton 使用了多种 Data Encoding 和 Index 来加速 Scan 与点查。为了快速定位数据的物理位置,用户可以在 DDL 中选择合适的 Index,Krypton 支持的 Index 如下:
-
Ordinal Index:根据行号快速查找目标的 Data Page。
-
Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filter,可以快速过滤掉无效的 Data Page。
-
Short-key Index:使用 Sorted Key 的前 36 个字节作为 Index Key 构建索引,是一种特殊的稀疏索引。
-
BitMap Index:可以根据等值的 Predicates 快速过滤出行号。
-
Skip Index:可以在一个 Data Page 内部快速定位数据的位置。
Nested Type Handling
在复合数据类型的处理上,Krypton 与 Dremel 不同,Dremel 只会存储叶子结点,Krypton 则会把所有的字段按照 B-tree 的方式组织,并把所有字段的数据顺序存储且独立分开。在非叶子结点中,存储了孩子节点的出现次数(Occurrence)和有效性(Validity)的信息;在叶子结点中,存储了数据。出现次数(Occurrence)表示子字段出现次数的前缀和,从而可以在获取重复数据的偏移量和长度时实现 O(1)的时间复杂度。因此,即使在嵌套和重复数据的情况下,我们仍然可以实现 O(m)的查找效率,其中 m 是 Schema Tree 的深度。有效性(Validity)用来区分这个 Field 是空还是 NULL。对于 NULL Field 我们不会存储任何的数据,对于存储稀疏数据提高了效率。相比 Dremel,我们的算法有两个优势:
-
稀疏字段具有更高的存储效率。
-
对于复合重复类型具有更好的 Seek 效率。
Query Engine Integration
Krypton 的存储格式设计与 Query Execution 深度绑定,为了尽可能的减少 IO,延迟物化和谓词下推被大量的使用。谓词过滤(Predicate Filtering)和列剪枝(Column Pruning)与推送下来的运行时过滤谓词(Push-down Runtime Filter Predicates)和文件索引一起在格式层进行处理。在读取过程中,首先使用能够匹配上索引的谓词来过滤出一组被选中的行号(Selection Vector)。接着,我们使用表达式框架来执行那些不能匹配上索引的谓词, 进一步减少所选中的行号,并进行列裁剪。最后,我们根据 Selection Vector 中的行号来物化数据。另外 Krypton 还支持直接在编码的数据上直接进行计算,此时 Format 会把编码的数据直接返回给 QE。
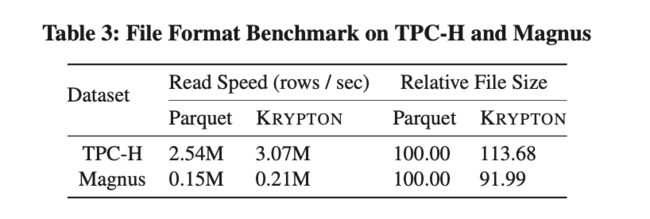
我们与 Parquet 格式在 TPC-H 和 Magnus 数据集上做了一个对比测试,Magnus 是字节内部在 ML 场景上的一个数据集,大量使用了复合数据类型。从上面的表格中可见,Krypton Format 相比 Parquet,读性能在 TPCH 上提高了 21%,在 Magnus 上提升了 40%;在数据大小上,TPC-H 上,Krypton 增长了 13%,主要是因为 Krypton 内部的索引,但在 Magnus 上,Krypton 减少了 8%,这主要受益于在复合类型的高效存储。
实验
环境
-
实验环境:YCSB Workload C + TPC-H 1T
-
生产环境: 住小帮(注:字节跳动一站式家装家居服务平台)场景,这是一个典型的特征服务场景,需要对给定用户的任意特征做任意时间窗口内的聚合预算。数据持续导入,实时查询,查询 QPS 10K/s
-
集群配置: 8 台物理机 (2.4GHz、48 Cores、96 vCPUs、128G DRAM、512G PMEM、2TB NVME、25G NICs)
-
Coordinators:2 台
-
Data Servers:3 台
-
Compaction Server:1 台
-
Ingestion Server:1 台
-
Metadata Server:1 台
Hybrid Performance
-
Resource Group Isolation
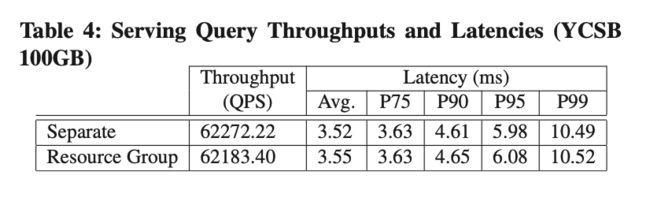
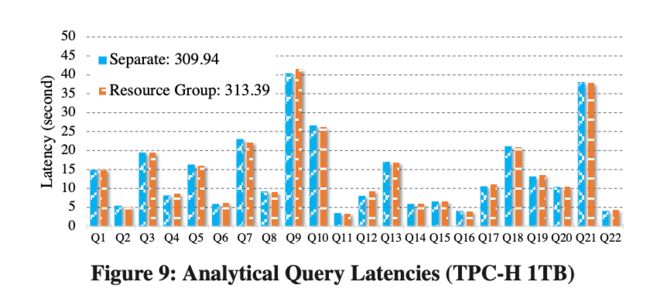
我们创建了两个 Resource Group 分别来承载 YCSB 和 TPCH 的 Workload,从表格 4 和图 9 可见,与分别运行 YCSB 和 TPCH-1T 相比,使用了 Resource Group 做隔离后,性能没有明显损耗。
-
Fair Scheduling
为了验证 Fair Scheduling 解决同一个 Resource Group 内部资源竞争的效果,我们在同一个 Resource Group 下运行了 TPCH-Q6 和 Q21,分别代表了短 Query 和长 Query。
所有的 Query 都从 1 个 Client 开始,然后 Q6 的 Client 数目按照 1、2、4、8 递增。

从图 10 中, 我们可以看到:
-
在没有 Fair Scheduling 的情况下,随着 Q6 并发的增加,Q21 的性能回退明显;
-
在有了 Fair Scheduling 之后,我们给 Q21 和 Q6 分配的资源分别为 20%和 80%,Q21 的 Latency 随着客户端的数目只有轻微增长。
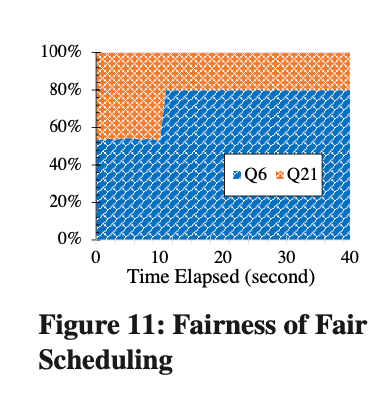
在图 11 中可以看到,当开始运行 Q6 的时候,Q6 并没有完全用完自己的资源(80%),只用了大概 53%,Fair Scheduling 可以自适应的将剩余的 27%的资源分配给 Q21 运行。随着 Q6 客户端数目的增加,Q6 和 Q21 都用满了自己所拥有的资源。
-
Adaptive Parallelism Control
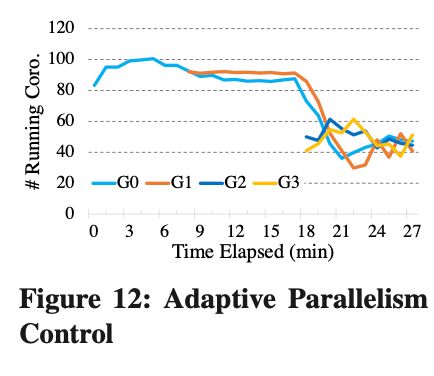
为了验证我们自适应并发控制的效果,我们使用了 4 个客户端(G0 - G3),每一个客户端会按照最大的并发度重复的发送 Q6。从图 12 中可见,只有 G0 的时候,在充足的 CPU 资源下,完全可以按照最大的并发度来执行。随着我们启动 G1 - G3,CPU 资源出现竞争,最后每个 Client 所运行的 Coro-threads 也动态的发生了改变。
Production Performance
-
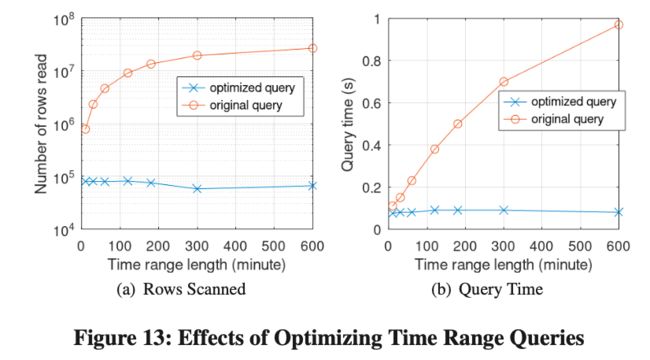
Effects of Optimizing Time Range Queries
为了测试使用 MV 改写 Time Range 查询的效果,我们使用了线上住小帮的真实 Workload。Query 如下:

我们固定了结束时间,然后动态的改变起始时间,整个 Time Range 从 10 分钟到 10 个小时。
-
Effects of Lightweight API
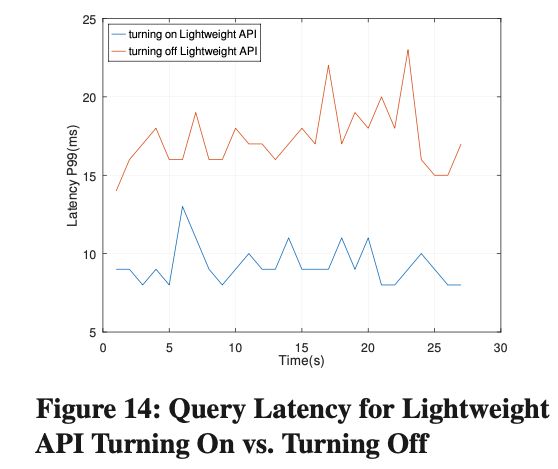
我们对比测试了线上 10K QPS 下的 Latency,在打开 Lightweight API 后,Query P99 Latency 下降了 45%。
-
Data Freshness of Streaming Ingestion
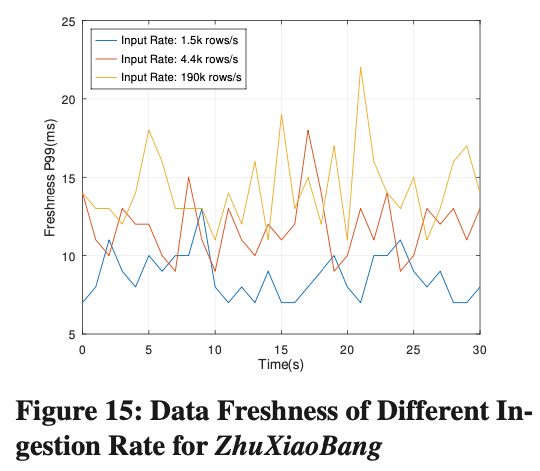
Data Freshness 定义为一条数据导入后到能查询到的时间间隔。图 15 可以看到,Data Freshness P99 的 Latency 一直保持在 15ms 左右,并且不会随着导入速率的升高而变化。
-
Read/Write Scenario in Production
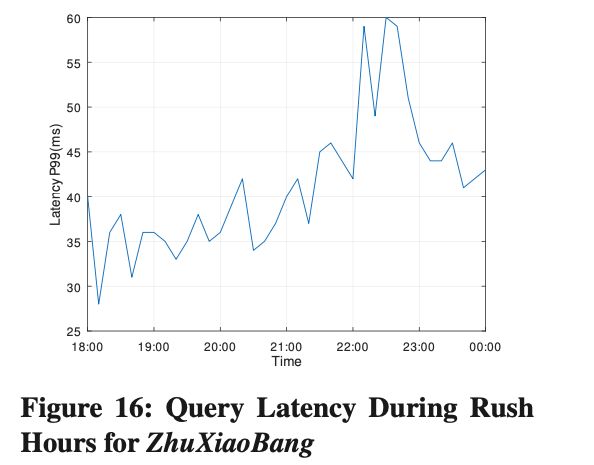
住小帮是典型的读写混合场景,每天 18:00-22:00 是高峰期,期间导入速率提高 460%,查询 QPS 提高 300%,由于 Krypton 采用了读写分离的架构,图 16 可见,Query P99 的 Latency 在高峰期并没有很大变化,并一直保持在 60ms 以内。
总结
在整个 Krypton 的设计研发和上线过程中,我们学到了很多很有用的经验:
-
Krypton 大部分的业务方之前使用的 Doris,Doris 周边的生态工具建设的也比较完善。因此我们一开始就决定接口层面,数据模型全面兼容 Doris。得益于此,后续用户在从 Doris 迁移时并没有碰到特别大的阻力,之前的一些生态也可以继续使用。
-
在用户场景中寻找机会进行优化。比如我们发现有的用户 QPS 很高,但是查询模式基本固定,只是一些过滤条件不一样,这时候 Result / Plan Cache 就发挥了很大的作用。还有一些技术,比如支持压缩的 WAL,全异步的写链路对于在高速写入场景中起了巨大的作用。
-
通过在线的流量进行测试。Krypton 是一个非常复杂的系统,并且用户对于新系统的稳定性通常持怀疑态度。因此我们开发了一套线上流量的双读双写框架,灰度线上流量到 Krypton,待系统稳定运行后再进行流量切换。