数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设
导读:同程数科成立于 2015 年,是同程集团旗下的旅游产业金融服务平台。2020 年,同程数科基于 Apache Doris 丰富的数据接入方式、优异的并行运算能力、极简运维等特性,引入 Apache Doris 进行数仓架构2.0 的搭建。本文详细讲述了架构1.0 到 2.0 的演进过程及 Doris 的应用实践,希望对大家有所帮助。
作者|同程数科大数据高级工程师 王星
业务背景
业务介绍
同程数科是同程集团旗下的旅游产业金融服务平台,前身是同程金服,正式成立于 2015 年。同程数科以“数字科技引领旅游产业”为愿景,坚持以科技的力量,赋能我国旅游产业。
目前,同程数科的业务涵盖产业金融服务、消费金融服务、金融科技及数字科技等板块,累计服务覆盖超过千万用户和 76 座城市。
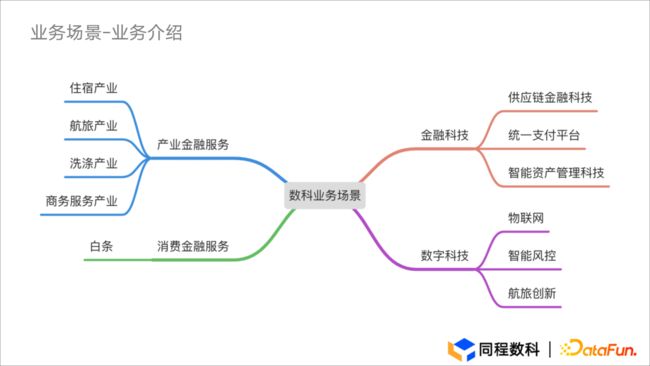
图1.1 业务场景-业务介绍
业务需求
主要包含四大类:
-
看板类:主要包括业务实时驾驶舱以及 T+1 业务看板等。
-
预警类:主要包括风控熔断、资金异常以及流量监控等。
-
分析类:主要包括及时性数据查询分析以及临时取数等。
-
财务类:主要包括清算以及支付对账需求。

图1.2 业务场景-业务需求
综合以上业务需求,我们进行了系统架构建设。
架构演进之 1.0
工作流程

图2.1 架构演变-架构1.0
架构1.0 是前几年非常流行的以 SteamSets 和 Apache Kudu 为核心的第一代架构。
该架构通过 StreamSets 进行数据库 Binlog 采集后实时写入 Apache Kudu 中,最后通过 Apache Impala 和可视化工具进行查询和使用。这个过程存在架构链路较长以及 SteamSets 对部分配置复用性表现欠佳的问题,另外 Apache Kudu 的多表关联与大表关联存在一定的性能瓶颈,且对 IO 方面要求较高。
图2.1 下半部分中实时计算流程的应用与上半部分较为相近,在实时计算中,埋点数据发送到 Kafka 后会通过 Flink 进行实时计算,并将计算结果数据落入分析库与 Hive 库中用于数仓关联。
优势与不足

图2.2 架构演变 优点与缺点
优势:
-
架构1.0 选择了 CDH 全家桶。CDH 提供了众多大数据组件,可以相互集成并投入使用,同时其配置相对灵活。
-
使用的 SteamSets 支持可视化拖拉式与配置式的开发方式,因此开发人员对 SteamSets 的接受程度较高。。
不足:
-
组件引入过多,维护成本随之增加;当数据出现问题时,排查与修复链路相对较长。
-
多种技术架构和过长的开发链路,提高了数仓人员的学习成本与要求,数仓人员需要在不同地方转换后再进行开发,导致开发流程不顺畅、开发效率降低。
-
Apache Kudu 在大表关联 Join 方面性能差强人意。
-
由于架构使用 CDH 构建,离线集群和实时集群未进行分离,形成资源相互竞争;离线跑批的过程中对 IO 或磁盘消耗较大,无法保证实时数据的及时性。
-
虽然 SteamSets 配备了预警能力,但作业恢复能力仍相对欠缺。配置多个任务时对 JVM 的消耗较大,导致恢复速度较慢。
架构演进之 2.0
工作流程
由于架构1.0 的不足远多于优点,在 2020年,我们调研了市面许多进行实时开发的组件,发现了 Apache Doris,通过调研对比,最终决定将 Apache Doris 引入了架构2.0。
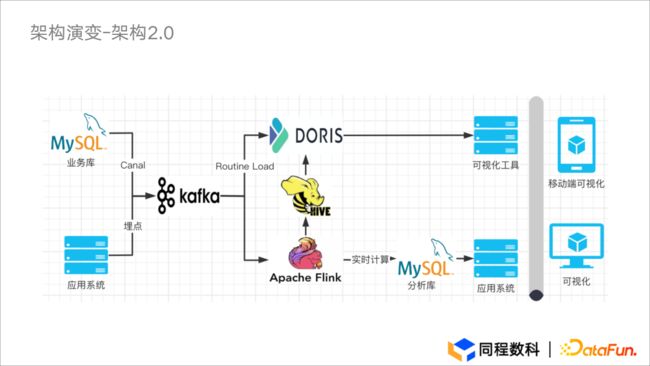
图3.1 架构演变-架构2.0
引入 Apache Doris 后,对整体架构进行了以下改造:
-
通过 Canal 的 CDC 能力,将 MySQL 数据采集到 Kafka 中。因 Apache Doris 与 Kafka 的契合度较高,可以便捷地使用 Routine Load 进行数据加载与接入。
-
对原有离线计算的数据链路进行了细微调整。对于存储在 Hive 中的数据,Apahce Doris 支持通过 Broker Load 将 Hive 数据引入进来,因此离线集群的数据可以直接加载进 Doris 之中。
选型 Doris
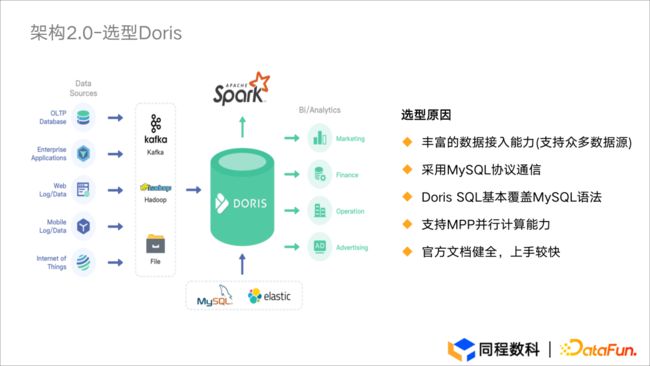
图3.2 架构2.0-选型Doris
在选型的过程中,Apache Doris 整体表现堪称惊艳:
-
数据接入:提供了丰富的数据导入方式,能够支持众多数据源的接入。
-
数据连接:Doris 支持 JDBC 与 ODBC 等连接方式,对 BI 工具的可视化展示比较友好,能够便捷地与 BI 工具进行连接,另外 Doris 实现了 MySQL 协议层,可以通过各类 Client 工具直接访问 Doris。
-
SQL 语法:Doris 支持标准 SQL,语法向 MySQL 兼容,对于数仓人员学习成本较低;
-
MPP 并行计算:Doris 基于 MPP 架构提供了非常优秀的并行计算能力,对于大表 Join 支持得非常好。
-
最重要的一点:Doris 官方文档非常健全,对于用户而言上手较快。
系统选型调研时,我们也了解了 ClickHouse,ClickHouse 对 CPU 的利用率较高,在单表查询时表现比较优秀,但是在多查询高 QPS 的情况下表现欠佳。
结合以上几点因素,最终我们选择了 Apache Doris。
Doris 部署架构
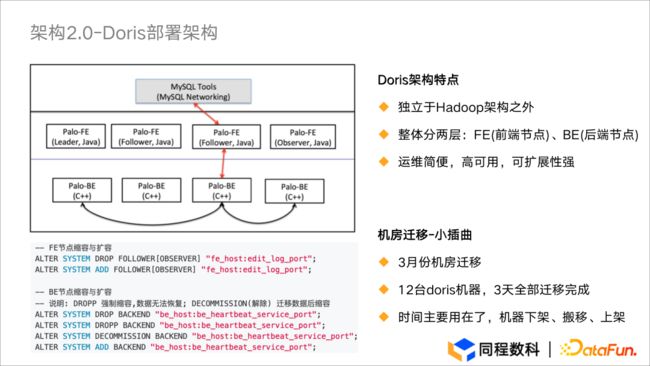
图3.3 架构2.0-Doris部署架构
Apache Doris 部署架构极为简单,主要是 FE 和 BE:
FE 是前端节点,主要进行用户请求的接入、元数据和集群的管理以及查询计划的生成。
BE 是后端节点,主要进行数据存储以及查询计划的生成及执行。
Doris 运维十分简便:
3 月份我们对机房的机器进行了滚动式迁移,12 台 Doris 节点机器在三天内全部迁移完成,整体操作较为简单,主要用于机器下架、搬移及上架;FE 扩容与缩容动作花费的时间也不多,只运用了 Add 与 Drop 等简单指令。
特别注意:尽量不要使用类似于 Drop 等指令直接对 BE 进行操作。当使用 Drop 指令进行强制删除时,Doris 会提示并要求手动确认是否删除,强制删除后数据将无法恢复。因此建议采用接触方式下线节点,该方式在数据迁移工作完成之后,可以直接将 BE 节点再次加入,较为灵活。
Doris 实时系统架构
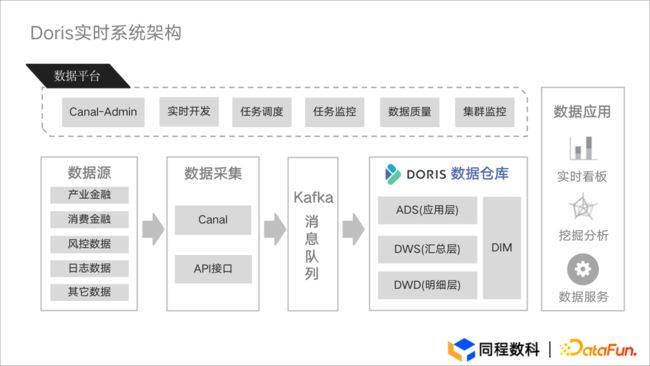
图3.4 Doris实时系统架构
数据源:在实时系统架构中,数据源来自产业金融、消费金融、风控数据等业务线,通过 Canal 和 API 接口进行采集。
数据采集:Canal 通过 Canal- Admin 进行数据采集后,将数据发送到 Kafka 消息队列之中,再通过 Routine Load 接入到 Doris 集群。
Doris 数仓:Doris 集群构建了数据仓库的三层分层,分别是:使用了 Unique 模型的 DWD 明细层 、 Aggregate 模型的 DWS 汇总层以及 ADS 应用层。
数据应用:架构应用于实时看板、数据及时性分析以及数据服务三方面。
Doris 新数仓特点

图3.5 Doris新数仓特点
数据导入方式简便,根据不同场景采用 3 种不同的导入方式:
-
Routine Load:主要用于业务数据的接入并作为消费 Kafka 的常驻任务存在。当我们提交 Rountine Load 任务时,Doris 内部会有一个常驻进程实时消费 Kafka ,不断从 Kafka 中读取数据导入进 Doris中。
-
Broker Load:进行如基础维度表及历史数据等离线数据导入任务。
-
Insert Into:用于定时跑批作业,负责将 DWD 层数据处理,形成 DWS 层以及 ADS 层。
Doris 的良好数据模型,提升了我们的开发效率:
-
Unique 模型在 DWD 层接入时使用,可以有效防止重复消费数据。
-
Aggregate 模型用作聚合。在 Doris 中,Aggregate 支持如 Sum、Replace、Min 、Max 4 种方式的聚合模型,聚合的过程中使用 Aggregate 底层模型可以减少很大部分 SQL 代码量,不再需要自己做 Sum、Min、Max 等动作,对于从 DWD 层到 DWS/ADS 层较为友好。
Doris 使用门槛低,查询效率高:
-
支持 MySQL 协议,支持标准 SQL,查询语法高度兼容 MySQL,对分析人员较为友好。
-
支持物化视图与 Rollup 物化索引。物化视图底层类似 Cube 的概念与预计算的过程,与 Kylin 中以空间换时间的方式类似,均是在底层生成特殊的表,在查询中命中物化视图时将快速响应。
特别提示:物化视图虽然很有帮助,但在过多使用时,每个物化视图均需要占用额外的存储空间,数据导入时将会导致效率下降。
Doris 极简的系统架构,运维成本低:
-
系统只有 BE 和 FE 两个模块,不依赖如 Zookeeper 等三方组件,部署简单。
-
针对 FE 和 BE 的操作进行了监控配置,发生异常时会进行及时性重启。
Doris 经验总结

图4.1 如何更友好地使用Doris
在使用 Apache Doris 的过程中,我们整理了一部分经验,帮助开发人员更友好地使用 Doris 。对于开发人员,最关注的地方有以下几点:
-
开发方面:如何将外部数据接入 Doris 并快速实现 ETL 开发,这会影响开发人员的报表产出速度。
-
调度管理:开发人员不希望在开发完成并上线任务后,出现报错或不稳定的情况,需要保证任务调度的稳定性以及调度恢复能力。
-
数据查询:由于生产与办公网络中间有隔断,办公网络不能直接使用生产网络的连接,并且无法通过客户端的形式解决网络隔断,只能通过 Web 形式解决,如何安全便捷地进行查询和分析成为开发人员关注的问题。
-
集群管理:集群出现异常状况时能够及时进行捕捉及自动化处理。
总而言之,我们希望建设一个高效率、高质量,高稳定性的平台。
Doris 开发优化
根据开发者关注的几个问题,我们进行了一些开发优化。
数据接入
数据接入方面进行了半自动化相关工作并做了快速生成组件,可以根据数据源/表生成 Routine Load 脚本,只要对 Kafka 的 Broker 或 Topic 进行修改就可以快速形成 Routine Load 任务。Broker Load 任务与 Routine Load 类似,在选择数仓源之后就可以及时生成 Broker Load 所需脚本。在接入 Doris 时需要提前创建表,对于这方面也可以进行类似操作,通过源快速生成创建语句。
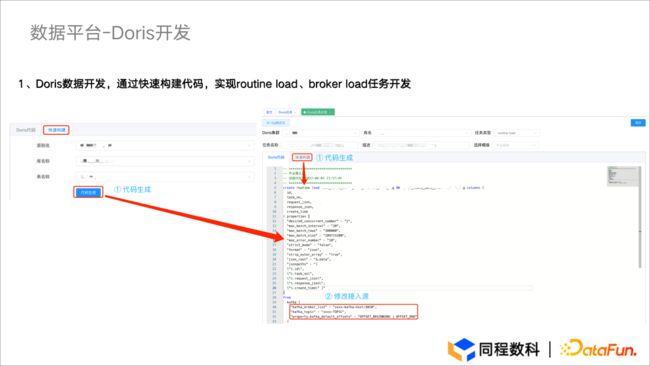
图5.1 数据平台- Doris开发
上述主要运用了底层元数据,根据不同的数据源拿到不同的元数据后就可以对任务进行快速生成。
提交动作和维护管理
在任务生成后,我们在 Routine Load 方面进行了封装。由于 Routine Load 是常驻进程,我们只需要再进行一次提交,状态就会变成 Running ,若出现异常状态会被检测出来,监控方面在后续会向大家进行展示。
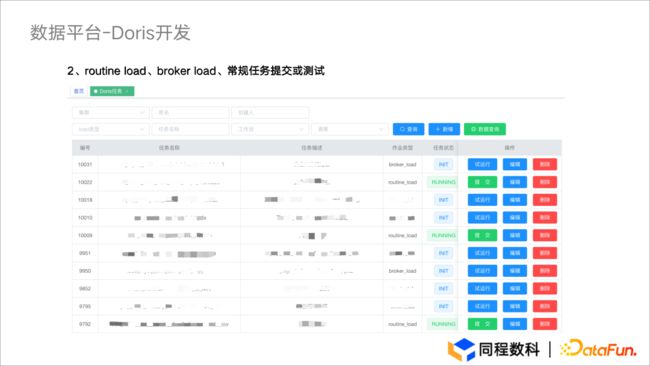
图5.2 数据平台- Doris开发
监控与管理
我们可以在对提交的 Routine Load 进行查询并检查是否存在异常,同时可以将我们需要关注的 Routine Load 加入监控中,监控会定期对任务进行自动扫描,发生问题时会进行提示并尝试将任务重新拉起。
Broker Load 同样可以对任务进行监测。针对于 Broker Load Label 名称不能重复的问题,我们采取生成 UUID 的方式进行解决,以此更好地帮助大家提升使用体验。
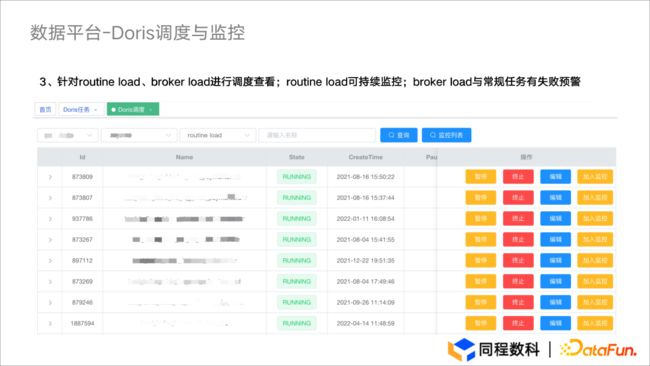
图5.3 数据平台- Doris开发
如上图展示,我们可以在 Routine Load 中进行暂停和终止的动作,帮助大家更好地使用开发的作业与管理。
自研查询页面,集成 Doris Help 功能
由于生产与办公网段隔离,我们只能通过 Web 进行查询。之前我们曾尝试使用 Hue 集成 Doris 进行查询的方案,Doris 支持通过 MySQL 协议连接到 Hue ,但如果我们集成 Hue 的话,所有人都可以通过 Hue 查询 Doris 的数据,安全性问题无法保证,无法满足我们对权限的要求。

图5.4 数据平台-Doris数据查询
所以我们在自己的平台内开发了查询页面来解决此问题。图中左边部分可以根据 DB 列出下面所有的表,右边部分是查询分析页面与查询结果,是我们自行开发的类似于 Navicat 的客户端软件。
同时我们对 Doris Help 功能进行了功能集成,在大家在不知道如何使用 Doris 时提供帮助。通过集成 Doris Help,我们可以通过关键字搜索的功能进行语法和示例查询解决问题。
即使没有集成 Doris Help,也可以在 FE 节点自带的 Web 页面进行查看,FE 节点内置可以查看整个集群信息且具备 Help 功能的 Web 页面。在我们实现自研查询页面并集成 Doris Help 后,可以直接使用,从而跳过需要使用 Admin 账号连接才可以使用 FE 的步骤。
Doris 集群监控页面
同时我们开发了 Doris 集群监控页面,在集群监控页面中可以看到 FE 、BE 以及 Broker 的节点状况。当集群发生异常状况时,监控系统会发送自动提醒并尝试将集群拉起,同时也可以通过页面化的形式观察节点的健康度情况。
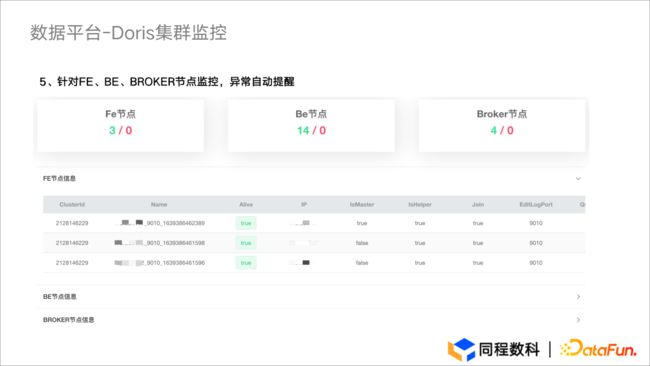
图5.5 数据平台- Doris集群监控
对于 Doris 上层应用而言,主要还是依赖 Doris 提供的 API 与指令完成 Doris 上层的应用动作,我们做的只是将 Doris 提供的指令针对使用者进行更友好地集成以及页面化展示。
新架构的收益

图6.1 新架构收益
-
数据接入:在早期通过 SteamSets 进行数据接入的过程中需要手动建立 Kudu 表。由于缺乏工具,整个建表和创建任务的过程需要 20-30 分钟。如今可以通过平台与快速构建语句实现数据快速接入,每张表的接入过程从之前的20-30分钟缩短到现在的 3-5 分钟,性能提升了 5-6 倍。
-
数据开发:在早期架构中进行聚合或其他动作时,需要写大量长篇幅 SQL 代码。使用 Doris之后,我们可以直接使用 Doris 中自带的 Unique、Aggregate 等数据模型及可以很好支持日志类场景的 Duplicate 模型,在 ETL 过程中大幅度加快开发过程。
-
查询分析:Doris 底层带有物化视图及 Rollup 物化索引等功能,可以提升查询效率,同时 Doris 底层对于大表关联进行了诸多优化策略,如 Runtime Filter 以及其他 Join 和自定义优化策略。相较于 Doris,Apache Kudu 则需要有较为深入的优化经验才能更好地使用。
-
数据报表:最初使用 Kudu 报表查询需要 1-2 分钟才能够完成渲染,而 Doris 则是秒级甚至是毫秒级的响应速度。
-
环境维护:Doris 没有 Hadoop 生态系统的复杂度,整个链路较为清晰,维护成本远低于 Hadoop,尤其是在集群迁移过程中,Doris 的运维便捷性尤为突出。
未来展望

图7.1 未来展望
-
尝试引入 Doris Manager:社区中正在进行关于 Doris Manager 宣导,后续我们也准备引入并积极参与 Doris Manager 进行集群维护与管理。
-
实现基于 Flink CDC 的数据接入:当前架构中没有引入 Flink CDC ,而是继续沿用了 Canal 采集到 Kafka 后再采集到 Doris 中的架构,链路相对来说较长。采用 Flink CDC 虽然可以继续精简整体架构,但是还需要写一定代码量,对于 BI 人员直接使用感受并不友好,我们希望数仓人员只需要 SQL 或在页面上完成操作就可以使用。在 3.0 架构的规划中,我们计划引入 Flink CDC 功能并对上层应用进行扩充。Flink CDC 的引入为大家带来“快就是慢,慢就是快”的思想理念,当然Flink社区的发展速度很快,只有在充分学习大家的经验后,才可以更友好地引入,并在学习经验的过程中对架构进行迭代与优化。
-
紧跟社区迭代计划:我们正在使用的 Doris 版本相对较老,现在新版本 Doris 在内存管理、查询性能等方面有了较大幅度的提升,后续我们将紧跟社区迭代节奏对集群进行升级并体现新特性。
-
强化建设相关体系:我们现在的指标体系管理如报表元数据、业务元数据等维护与管理依旧有待提高。数据质量监控方面,虽然目前包含了数据质量监控功能,但对于整个平台监控与数据自动化监控方面还需要强化与改善。
加入社区
欢迎更多热爱开源的小伙伴加入 Apache Doris 社区,参与社区建设,除了可以在 GitHub 上提 PR 或 Issue 之外,也欢迎大家积极参与到社区日常建设中来,比如:
参加社区征文活动,进行技术解析、应用实践等文章产出;作为讲师参与 Doris 社区的线上线下活动;积极参与 Doris 社区用户群的提问与解答等。
最后,欢迎更多的开源技术爱好者加入 Apache Doris 社区,携手成长,共建社区生态。



SelectDB 是一家开源技术公司,致力于为 Apache Doris 社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于 Apache Doris 研发的新一代云原生实时数仓 SelectDB,运行于多家云上,为用户和客户提供开箱即用的能力。
相关链接:
SelectDB 官方网站:
SelectDB - 基于 Apache Doris 的云原生实时数据仓库
Apache Doris 官方网站:
Apache Doris
Apache Doris Github:
GitHub - apache/doris: Apache Doris is an MPP-based interactive SQL data warehousing for reporting and analysis.
Apache Doris 开发者邮件组:
dev@doris.apache.org