数据结构与算法基础-(2)
write in front
大家好,我是Aileen.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流.
本文由Aileen_0v0 原创 CSDN首发 如需转载还请通知⚠️
个人主页:Aileen_0v0—CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏:Aileen_0v0的数据结构与算法学习系列专栏——CSDN博客
我的格言:"没有罗马,那就自己创造罗马~"

目录
"时间复杂度"回顾
空间复杂度
“变位词”判断问题
解法1:逐字检查法
思路:
代码块:
运行过程:编辑
解法2:排序比较
思路:
编辑 代码块:
运行过程:编辑
解法3:暴力法
思路:编辑
解法4:计数比较
思路:
编辑
代码块:
运行过程:
拓展 sort.() 和 sorted的区别
sort()和sorted()的区别
其他类型排序
"时间复杂度"回顾

| 执行次数函数(
Asymptot i c Notation
)举例 |
阶(
Big-0 Notat i o n
) |
非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n^2+2n+1 | O(n^2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n^3+2n^2+3n+4 | O(n^3) | 立方阶 |
| 2^n | O(2^n) | 指数阶 |
由图可知,所消耗的时间从小到大:
O(1) 下图表示常见的时间复杂度 利用程序的空间复杂度可以对程序的运行所需要的内存多少有个预先估计。一个程序执行时除了需要存储空间和存储本身所使用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为现实计算所需信息的辅助空间。 程序执行时所需存储空间包括以下两部分。 (1)固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间)、数据空间《常量、简单变量)等所占的空间。这部分属于静态空间。 例如: 要判断某年是不是闰年,你可能会花一点心思来写一个算法,每给一个年份,就可以通过这个算法计算得到是否闰年的结果。 这样,所谓的判断某一年是否为闰年就变成了查找这个数组某一个元素的值的问题。 第一种方法相比起第二种来说很明显非常节省空间,但每一次查询都需要经过一系列的计算才能知道是否为闰年。 第二种方法虽然需要在内存里存储 2050 个元素的数组,但是每次查询只需要一次索引判断即可。 这就是通过一笔空间上的开销来换取计算时间开销的小技巧。到底哪一种方法好?其实还是要看你用在什么地方~~ 一个算法所需的存储空间用 f(n)表示。 S(n)=O(f(n)) n为问题的规模,S(n)表示空间复杂度。 上方的代码中,当程序调用 reserse()方法时, 要分配的内存空间包括: 引用 a、引用 b、局部变量n、局部变量i。因此 f(n)=4 ,4 为常量。 所以该算法的空间复杂度 S(n)=O(1) 空间复杂度的计算方式和时间复杂度类似 算法:独立解决问题的一种思想 大O数量级(大O记法):评判算法复杂度的指标 “变位词”是指两个词之间存在组成字母的重新排列关系 粗看上去,本算法只有一个循环,最多执行n次,数量级是O(n) 但循环前面的两个sort并不是无代价的~ 排序算法采用不同的解决方案,其运行时间数量级差不多是0(n2)或者0(n log n),大过循环的O(n) 所以本算法时间主导的步骤是排序步骤 python中的sorted()函数对字符串进行排序,判断是否两个字符串排序后相等来判断是否为变位词。 例如,判断字符串"race"和"care"是否为变位词: 在上面的示例中,我们定义了一个名为 (由于它不是一个好方法,所以了解即可) ord()函数:返回的是 字符的 Unicode值 将 对应字符的Unicode - a的Unicode 就能得到 每个字符变成 0 - 25的数字 接收 sort() 的返回值,可以发现是None 输出: None 打印一下排序前、后的「内存地址」,可以发现 地址没有改变! 输出: 1465837605120 sort() 的设计思想就是「修改」原列表,而不是返回新的列表; 输出: [1, 3, 2, 5] 从结果可以看到, sorted() 创建了新的列表,用来保存排序后的列表 sort() 只能对列表排序,而 sorted() 能对可迭代对象排序; 所以,字符串、元组、字典等类型想排序,可以用 sorted(). 输出: ['1', '2', '3'] 从输出结果可以发现,字符串、元组、字典类型排序后,返回的是列表类型;并且字典只对键排序,不对值排序。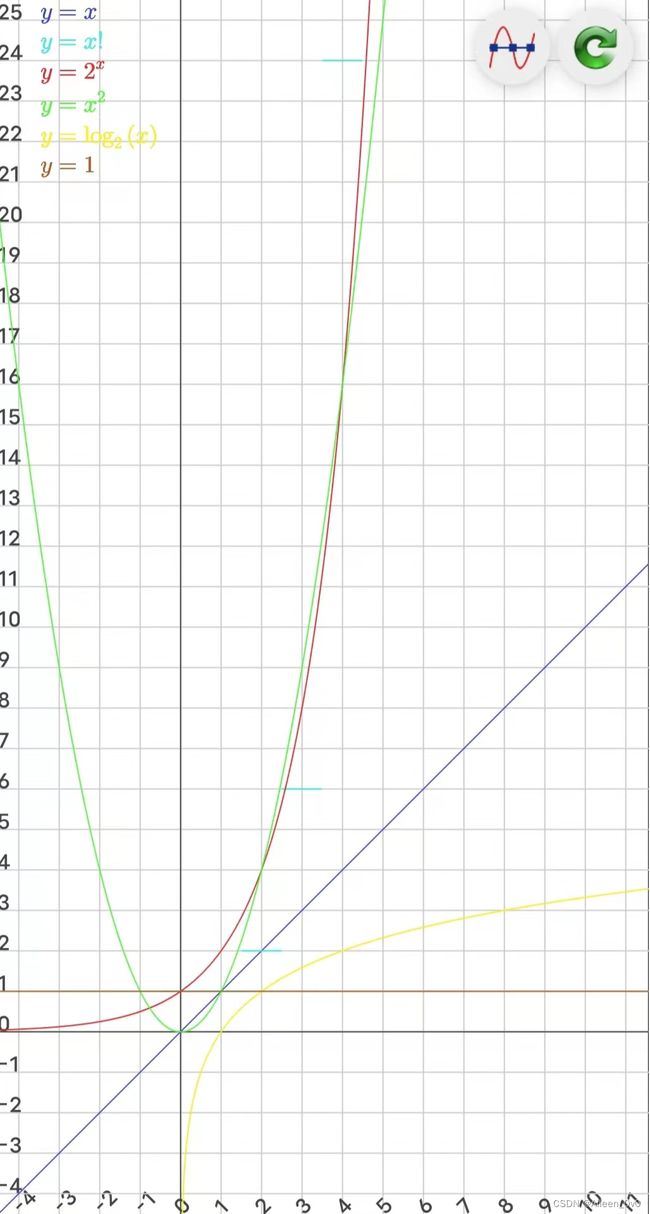
空间复杂度
空间复杂度指运行完一个程序所需内存的大小。
(2)可变空间,这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等这部分的空间大小与算法有关。
另外一种方法是,事先建立一个有 2050 个元素的数组,然后把所有的年份按下标的数字对应,如果是闰年,则此数组元素的值是 1,如果不是元素的值则为 0。# 空间复杂度
def reserve(a,b):
n=len(a)
for i in range(n):
b[i]=a[n-1-i]
“变位词”判断问题⭐
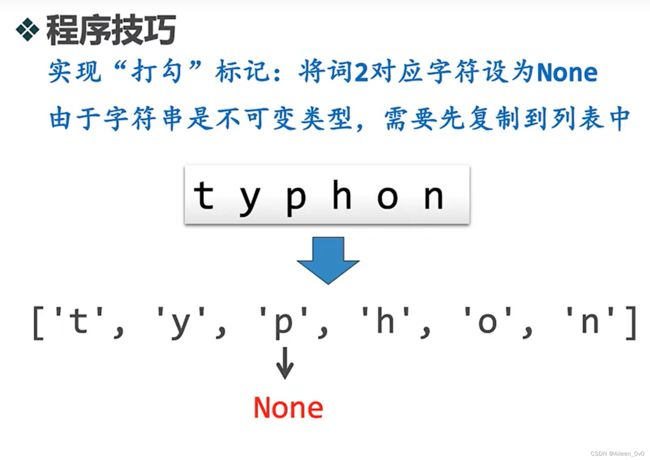
如: heart和earth,python和typhon解法1:逐字检查法
思路:

代码块:
def anagramSolution1(s1,s2):
alist = list(s2)
pos1 = 0
stillOK = True
while pos1 < len(s1) and stillOK:
pos2 = 0
found = False
while pos2 < len(alist) and not found:
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 = pos2 + 1
if found:
alist[pos2] = None #找到就利用None打勾
else:
stillOK = False
pos1 = pos1 + 1
return stillOK
print(anagramSolution1("ad","ca"))运行过程:

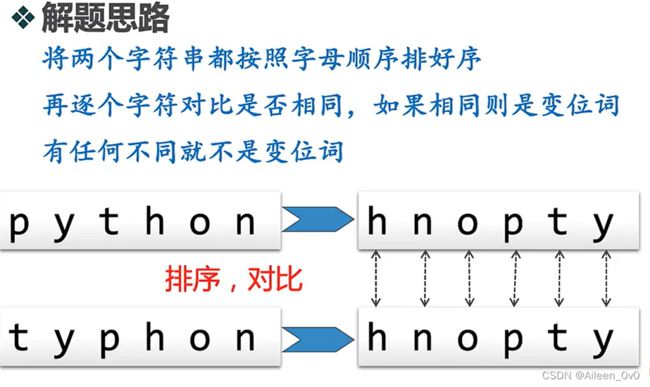
解法2:排序比较法
思路:
 代码块:
代码块:def anagramSolution2(s1,s2):
#转为列表
alist1 = list(s1)
alist2 = list(s2)
#分别排序
alist1.sort()
alist2.sort()
pos = 0
matches = True
while pos < len(s1) and matches:
#逐个对比
if alist1[pos] == alist2[pos]:
pos = pos + 1
else:
matches = False
return matches
print(anagramSolution2("abcde", "edcba"))运行过程:
本算法的运行时间数量级就等于排序过程的数量级O(n log n)str1 = "race"
str2 = "care"
if sorted(str1) == sorted(str2):
print("两个字符串是变位词")
else:
print("两个字符串不是变位词")
def is_anagram(str1, str2):
# 如果两个字符串长度不同,则它们不可能是变位词
if len(str1) != len(str2):
return False
# 两个字符串排序后比较
str1_sorted = sorted(str1)
str2_sorted = sorted(str2)
for i in range(len(str1)):
if str1_sorted[i] != str2_sorted[i]:
return False
return True
# 示例:
print(is_anagram("listen", "silent")) # True
print(is_anagram("python", "java")) # False
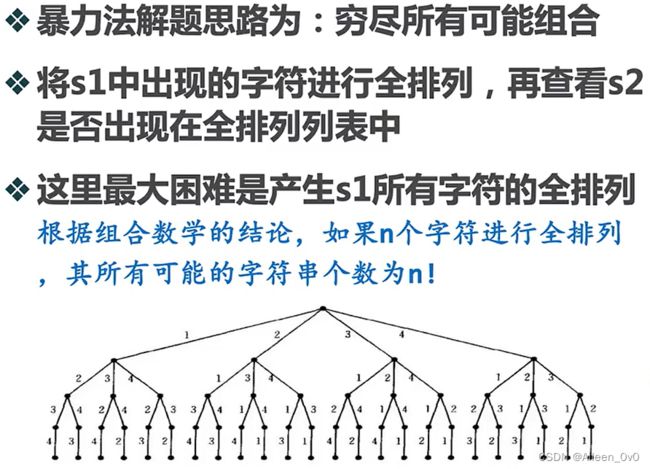
is_anagram 的函数,输入两个字符串 str1和 str2,如果两个字符串的长度不同,则它们不可能是变位词,返回False。并使用Python的sorted函数将这两个字符串排序。对于两个已排序的字符串,我们使用for循环逐个比较它们的字符。如果有任何不相等的字符,则这两个字符串不是变位词。如果所有字符都相等,则这两个字符串是变位词,返回True。 解法3:暴力法
思路:

解法4:计数比较法
思路:

代码块:
def anagraamSolution4(s1,s2):
#计数器1
c1 = [0] * 26
#计数器2
c2 = [0] * 26
#对 s1 进行计数
for i in range (len(s1)):
pos = ord(s1[i]) - ord("a")
c1[pos] = c1[pos] + 1
#对 s2 进行计数
for i in range (len(s2)):
pos = ord(s2[i]) - ord("a")
c2[pos] = c2[pos] + 1
#进行每一位字符的比较
j = 0
stillOK = True
while j < 26 and stillOK:
if c1[j] == c2[j]:
j = j + 1
else:
stillOK = False
return stillOK
print(anagraamSolution4("apple","pleap"))运行过程:


拓展 sort.() 和 sorted的区别
sort()和sorted()的区别✨
list1 = [1, 3, 2, 5]
list2 = list1.sort()
print(list2)
list1 = [1, 3, 2, 5]
print(id(list1))
list1.sort()
print(id(list1))
1465837605120
它不会创建新的列表,从而节省「效率」;
当然,这也意味着原列表被修改了,使用时要留意这一点;
sorted() 是 sort() 的扩展函数,可以对列表的元素排序,同时不会修改原列表。list1 = [1, 3, 2, 5]
list2 = sorted(list1)
print(list1)
print(list2)
[1, 2, 3, 5]其他类型排序✨
str1 = "312"
print(sorted(str1))
tuple1 = (5, 1, 3)
print(sorted(tuple1))
dict1 = {"key1": 1, "key2": 2}
print(sorted(dict1))
[1, 3, 5]
['key1', 'key2']