Flink SQL
标准SQL分类
DML(Data Manipulation Language):数据操作语言,用来定义数据库中的记录
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别
DQL(Data Query Language):数据查询语言,用来查询记录
DDL(Data Definition Language):数据定义语言,用来定义数据库中的对象
Flink Table API实现了DQL数据查询,Flink SQL实现了DML、DDL、DQL
Flink SQL的优势
-
FlnkSQL比DataStreamAPI、DataSetAPI实现简单、方便
-
TableAPI和SQL是流批通用的,代码可以完全复用
-
TableAPI和SQL可以使用Calcite的SQL优化器,可以实现自动程序优化更容易写出执行效率高的应用
Flink1.9版本引入了阿里巴巴的Blink实现流批一体
Apache Calcite
Apache Calcite是一款使用Java编程语言编写的开源动态数据管理框架,它具备很多常用的数据库管理需要的功能,比如:SQL解析、SQL校验、SQL查询优化、SQL生成以及数据连接查询,目前使用Calcite作为SQL解析与优化引擎的有Hive、Drill、Flink、Phoenix和Storm。
Calcite中提供了RBO(Rule-Based Optimization:基于规则)和CBO(Cost-Based Optimization:基于代价)两种优化器,在保证语义的基础上,生成执行成本最低的SQL逻辑树。
RBO:根据预先制定好的规则进行优化
CBO:根据成本(CPU和内存)进行优化
Flink SQL应用于流
流批处理的异同
| 输入表 | 处理逻辑 | 结果表 | |
|---|---|---|---|
| 批处理 | 静态表:输入数据有限、是有界集合 | 批式计算:每次执行查询能够访问到完整的输入数据,然后计算,输出完整的结果数据 | 静态表:数据有限 |
| 流处理 | 动态表:输入数据无限,数据实时增加,并且源源不断 | 流式计算:执行时不能够访问到完整的输入数据,每次计算的结果都是一个中间结果 | 动态表:数据无限 |
要将 SQL 应用于流式任务的三个要解决的核心点:
1.SQL 输入表:分析如何将一个实时的,源源不断的输入流数据表示为 SQL 中的输入表。
2.SQL 处理计算:分析将 SQL 查询逻辑翻译成什么样的底层处理技术才能够实时的处理流式输入数据,然后产出流式输出数据。
3.SQL 输出表:分析如何将 SQL 查询输出的源源不断的流数据表示为一个 SQL 中的输出表。
两种技术方案:
1.动态表:源源不断的输入、输出流数据映射到 动态表
2.连续查询:实时处理输入数据,产出输出数据的实时处理技术
动态表
如果把有界数据集当作表,那么无界数据集(流)就是一个随着时间变化持续写入数据的表,Flink中使用动态表表示流,使用静态表表示传统的批处理中的数据集。
流是Flink DataStream中的概念,动态表是Flink SQL中的概念,两者都是无界数据集。动态表在Flink中抽象为Table API
连续查询
将SQL查询应用于动态表,会持续执行而不会终止,因为数据会持续的产生,所以连续查询不会给出一个最终结果,而是持续不断地更新结果,实际上给出的总是中间结果。
流上的SQL查询运算与批处理中的SQL查询运算在语义上完全相同,对于相同的数据集计算结果也是相同的。

从概念上来说:
1.流转换为动态表
2.在动态表上执行连续查询,生成新的动态表
3.生成的动态表转换回流
从开发上来说:
1.将DataStream注册为Table
2.在Table上应用SQL查询语句,结果为一个新的Table
3.将Table转换为DataStream
第一步-流转换为表
第二步-更新和追加查询
1.向结果表中插入新记录、更新旧的记录
2.只会向结果表中插入新记录
同时包含插入(Insert)、更新(Update)的查询必须维护更多的State,消耗更多的CPU、内存资源。
流上使用SQL的限制:
1.需要维护的状态太大
2.计算更新的成本太高
第三步-表转换为流
动态表分为三种类型:
1.只有更新行为,表中的结果被持续更新
2.只有插入行为,没有UPDATA和DELETE行为的结果表
3.既有更新行为又有插入行为的结果表
不同的表类型会转换为不同的流对外输出。
Append流
只支持写入行为,输出的结果只有 INSERT 操作的数据。
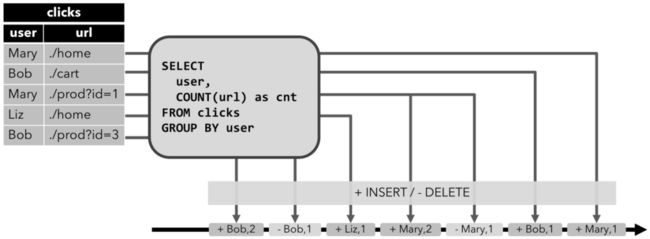
Retract流
Retract 流包含两种类型的 message: add messages 和 retract messages 。
将 INSERT 操作编码为 add message
将 DELETE 操作编码为 retract message
将 UPDATE 操作编码为更新先前行的 retract message 和更新(新)行的 add message,从而将动态表转换为 retract 流。
Retract 流写入到输出结果表的数据有 -,+ 两种,分别 - 代表撤回旧数据,+ 代表输出最新的数据。这两种数据最终都会写入到输出的数据引擎中。
如果下游还有任务去消费这条流的话,要注意需要正确处理 -,+ 两种数据,防止数据计算重复或者错误。
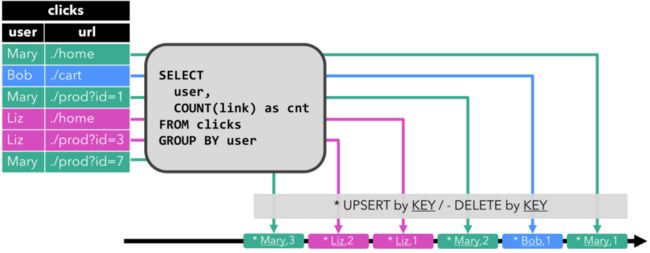
Upsert流
Upsert 流包含两种类型的 message: upsert messages 和 delete messages。转换为 upsert 流的动态表需要唯一键(唯一键可以由多个字段组合而成)。
将 INSERT 和 UPDATE 操作编码为 upsert message
将 DELETE 操作编码为 delete message
Upsert流写入到输出结果表的数据每次输出的结果都是当前根据唯一键的最新结果数据,不会有 Retract流中的 - 回撤数据。
如果下游还有一个任务去消费这条流的话,消费流的算子需要知道唯一键(即 user),以便正确地根据唯一键(user)去拿到每一个 user 当前最新的状态。
其与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。
Flink 中的窗口操作
窗口概述
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。
-
一个Window代表有限对象的集合。一个窗口有一个最大的时间戳,该时间戳意味着在其代表的某时间点——所有应该进入这个窗口的元素都已经到达
-
Window就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。
-
在Table API & SQL中,主要有两种窗口:Group Windows 和 Over Windows。
-
Group Windows 根据时间或行计数间隔将组行聚合成有限的组,并对每个组计算一次聚合函数
-
Over Windows 窗口内聚合为每个输入行在其相邻行范围内计算一个聚合
-
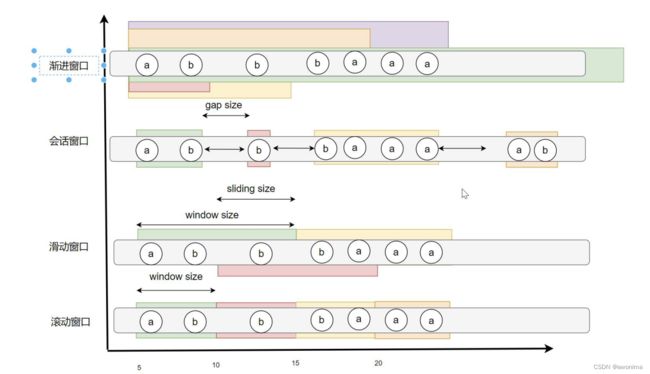
滚动窗口
滚动窗口定义:滚动窗口将每个元素指定给指定窗口大小的窗口。滚动窗口具有固定大小,且不重叠。例如,指定一个大小为 5 分钟的滚动窗口。在这种情况下,Flink 将每隔 5 分钟开启一个新的窗口,其中每一条数都会划分到唯一一个 5 分钟的窗口中:
应用场景:常见的按照一分钟对数据进行聚合,计算一分钟内 PV,UV 数据
滑动窗口
滑动窗口定义:滑动窗口也是将元素指定给固定长度的窗口。与滚动窗口功能一样,也有窗口大小的概念。不一样的地方在于,滑动窗口有另一个参数控制窗口计算的频率(滑动窗口滑动的步长)。因此,如果滑动的步长小于窗口大小,则滑动窗口之间每个窗口是可以重叠。在这种情况下,一条数据就会分配到多个窗口当中。举例,有 10 分钟大小的窗口,滑动步长为 5 分钟。这样,每 5 分钟会划分一次窗口,这个窗口包含的数据是过去 10 分钟内的数据,如下图所示:
在流模式下,时间属性字段必须是事件或处理时间属性。
应用场景:比如计算同时在线的数据,要求结果的输出频率是 1 分钟一次,每次计算的数据是过去 5 分钟的数据(有的场景下用户可能在线,但是可能会 2 分钟不活跃,但是这也要算在同时在线数据中,所以取最近 5 分钟的数据就能计算进去了)
Session 窗口
Session 窗口定义:Session 时间窗口和滚动、滑动窗口不一样,其没有固定的持续时间,如果在定义的间隔期(Session Gap)内没有新的数据出现,则 Session 就会窗口关闭。
基于DataStream编程
Session window的窗口大小,则是由数据本身决定
DataStream input = …DataStream result = input.keyBy() .window(SessionWindows.withGap(Time.seconds()) .apply() // or reduce() or fold
渐进式窗口
渐进式窗口定义:渐进式窗口在其实就是 固定窗口间隔内提前触发的的滚动窗口,其实就是 Tumble Window + early-fire 的一个事件时间的版本。
在流模式下,时间属性字段必须是事件或处理时间属性。 在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP _LTZ类型的属性。CUMULATE的返回值是一个新的关系,它包括原始关系的所有列,以及另外3列“window_start”、“window_end”、“window_time”,以指示指定的窗口。原始时间属性“timecol”将是窗口TVF之后的常规时间戳列。 CUMULATE接受四个必需参数,一个可选参数: CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
-
data: 是一个表参数,可以是与时间属性列的任何关系
-
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到累积窗口。
-
step: 是指定连续累积窗口结束之间增加的窗口大小的持续时间
-
size: 是指定累积窗口的最大宽度的持续时间。size必须是 的整数倍step。
-
offset: 是一个可选参数,用于指定窗口起始位置的偏移量。
渐进式窗口目前只有 Windowing TVF 方案(1.14 只支持 Streaming 任务,1.15版本开始支持 Batch\Streaming 任务):
其中包含四部分参数:
第一个参数 TABLE source_table 声明数据源表;
第二个参数 DESCRIPTOR(row_time) 声明数据源的时间戳;
第三个参数 INTERVAL '60' SECOND 声明渐进式窗口触发的渐进步长为 1 min。
第四个参数 INTERVAL '1' DAY 声明整个渐进式窗口的大小为 1 天,到了第二天新开一个窗口重新累计。
Over Windows
Over 聚合定义(支持 Batch\Streaming):可以理解为是一种特殊的滑动窗口聚合函数。
-
窗口聚合:不在 group by 中的字段,不能直接在 select 中拿到
-
Over 聚合:能够保留原始字段
Over 聚合的语法:
-
ORDER BY:必须是时间戳列(事件时间、处理时间)
-
PARTITION BY:标识了聚合窗口的聚合粒度,如上述案例是按照 product 进行聚合
-
range_definition:这个标识聚合窗口的聚合数据范围,在 Flink 中有两种指定数据范围的方式。第一种为 按照行数聚合,第二种为 按照时间区间聚合。