初识Java 10-2 集合
目录
LinkedList
Stack
Queue
Set
Map
新特性:记录(record)类型
本笔记参考自: 《On Java 中文版》
LinkedList
LinkedList同样实现了基本的List接口。相比于ArrayList,LinkedList拥有更快的插入和删除效率,但随机访问的能力会差一些。
由于LinkedList添加了一些方法,它也可以被用作栈、队列或双端队列进行使用。这些被添加的方法大多和其他方法类似,名字的不同只是来自于使用场景的变化。如:
- getFirst():和element()方法完全相同,返回一个列表的头部(第一个元素),且不进行移除。
- peek():和getFirst()类似,但若列表为空,会返回null。
- removeFirst():和remove()完全相同,移除并返回列表的头。
- poll():和removeFirst()类似,但列表为空时,返回null。
import java.util.LinkedList;
public class LinkedListFeatures {
public static void main(String[] args) {
LinkedList pets = new LinkedList<>(new PetCreator().list(5));
System.out.println(pets);
// getFirst()和element()方法完全相同:获取第一个元素
System.out.println("pets.getFirst(): " + pets.getFirst());
System.out.println("pets.element(): " + pets.element());
System.out.println();
// 仅当列表为空时,peek()会和上面两个方法产生区别
System.out.println("pets.peek(): " + pets.peek());
// remove()和removeFirst()方法完全相同:移除并返回第一个元素
System.out.println("pets.remove(): " + pets.remove());
System.out.println("pets.removeFirst(): " + pets.removeFirst());
// 仅当列表为空时,peek()会和上面两个方法产生区别
System.out.println("pets.poll(): " + pets.poll());
System.out.println(pets);
// 在列表的开头插入一个元素
System.out.println();
pets.addFirst(new Rat());
System.out.println("执行addFirst()后: " + pets);
// 在列表的尾部插入一个元素
System.out.println();
pets.offer(new PetCreator().get());
System.out.println("执行offer()后: " + pets);
pets.add(new PetCreator().get());
System.out.println("执行add()后: " + pets);
pets.addLast(new PetCreator().get());
System.out.println("执行addLast()后: " + pets);
// 移除最后一个元素
System.out.println();
System.out.println("pets.removeLast(): " + pets.removeLast());
}
} 程序执行的结果是:

若观察过Queue接口,就会发现element()、offer()、peek()、poll()和remove()方法都被添加到了LinkedList中,所以LinkedList也可以算作是Queue的一个实现。

Stack
栈是一种“后进先出”(LIFO)的集合,也被称为下堆栈。Java 1.0就提供了Stack类,但其设计非常糟糕。而且因为向后兼容的缘故,这种设计错误难以摆脱。Java 6加入了ArrayDeque,提供了直接实现栈的方法:
import java.util.ArrayDeque;
import java.util.Deque;
public class StackTest {
public static void main(String[] args) {
Deque stack = new ArrayDeque<>();
for (String s : "The weather is fine today".split(" "))
stack.push(s);
while (!stack.isEmpty())
System.out.print(stack.pop() + " ");
System.out.println();
}
} 程序执行的结果是:
![]()
尽管Deque在各方面表现都像栈,但我们必须把它声称为Deque。当然,我们可以自己定义一个Stack。
package onjava;
import java.util.ArrayDeque;
import java.util.Deque;
public class Stack {
private Deque storage = new ArrayDeque<>();
public void push(T v) {
storage.push(v);
}
public T peek() {
return storage.peek();
}
public T pop() {
return storage.pop();
}
public boolean isEmpty() {
return storage.isEmpty();
}
@Override
public String toString() {
return storage.toString();
}
} 上述代码通过泛型给出了一个简单的Stack类的定义。类名后的
若只需要栈的行为,在这里使用继承就不合适了,因为这样会得到一个具有ArrayDeque所有方法的类,这很明显是冗余的。若使用组合,我们就可以选择暴露那些方法,以及如何为它们命名。
上面创建的Stack的使用例如下:

若想要在自己的代码中使用自己的Stack,在创建对象时必须指定完整的包名,或者在创建时更改类名,防止和java.util中的Stack冲突(或者在使用时通过全限定名进行特定Stack的指定)。
Queue
队列是一种“先进后出”(FIFO)的集合。LinkedList实现了Queue接口,并提供了支持队列行为的方法,这使得我们可以将LinkedList视为Queue的一种实现进行使用。以下例子会展示Queue接口的特有用法:
import java.util.LinkedList;
import java.util.Queue;
import java.util.Random;
public class QueueDemo {
public static void printQ(Queue queue) {
while (queue.peek() != null)
System.out.print(queue.remove() + " ");
System.out.println();
}
public static void main(String[] args) {
Queue queue = new LinkedList<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++)
queue.offer(rand.nextInt(i + 10));
printQ(queue);
Queue qc = new LinkedList<>();
for (char c : "今天天气真好".toCharArray())
qc.offer(c);
printQ(qc);
}
程序执行的结果如下:
![]()
- 用于插入 —— offer():当无法插入时返回false。
- 用于返回队列的头部元素(不删除元素)—— peek()和element():
- peek():若队列为空,返回null。
- element():若队列为空,抛出NoSuchElementException。
- 用于删除头部元素(并返回该元素)—— poll()和remove():
- poll():若队列为空,返回null。
- remove():若队列为空,抛出NoSuchElementException。
Queue只允许我们访问这个接口中定义的方法,所以LinkedList中的其他方法就无法被访问了。另外,Queue特有的方法都提供了完整且独立的功能。换言之,尽管Queue继承了Collection,但即使不使用Collection中的方法,我们也可以使用一个可用的Queue。
优先级队列说明,下一个要拿出的元素是需求最强烈的元素(优先级最高)。Java 5添加了PriorityQueue,为这一概念提供了一个实现。
若使用offer()将元素放入PriorityQueue中,这个对象会在排序后放入队列。而默认的排序方法是使用对象在队列中的自然顺序,但使用者可以提供了一个Comparator来修改这一顺序。
实际上,优先级队列可能会在插入时排序,也可能在删除时选择最重要的元素。
下面是一个PriorityQueue的使用例:
import java.util.PriorityQueue;
import java.util.Random;
import java.util.Arrays;
import java.util.List;
import java.util.Collections;
import java.util.Set;
import java.util.HashSet;
public class PriorityQueueDemo {
public static void main(String[] args) {
PriorityQueue priorityQueue = new PriorityQueue<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++)
priorityQueue.offer(rand.nextInt(i + 10));
QueueDemo.printQ(priorityQueue);
List ints = Arrays.asList(25, 22, 20, 18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25);
priorityQueue = new PriorityQueue<>(ints);
QueueDemo.printQ(priorityQueue);
priorityQueue = new PriorityQueue<>(ints.size(), Collections.reverseOrder());
priorityQueue.addAll(ints);
QueueDemo.printQ(priorityQueue);
String fact = "TODAY IS A GOOD DAY";
List strings = Arrays.asList(fact.split(""));
PriorityQueue stringPQ = new PriorityQueue<>(strings);
QueueDemo.printQ(stringPQ);
stringPQ = new PriorityQueue<>(strings.size(), Collections.reverseOrder());
stringPQ.addAll(strings);
QueueDemo.printQ(stringPQ);
Set charSet = new HashSet<>();
for (char c : fact.toCharArray())
charSet.add(c);// 自动装箱
PriorityQueue characterPQ = new PriorityQueue<>(charSet);
QueueDemo.printQ(characterPQ);
}
} 程序执行的结果是:

值可以重复,最小的值优先级最高(在String中,空格的也是值,且优先级高于字母)。
在上述程序中,使用了两次Collections.reverseOrder(),通过使用这个方法,生成了一个可以反向排序的Comparator()。
Integer、String和Character之所以配合PriorityQueue进行使用,是因为这些类已经有了自然顺序。若想让自己的类也可以在PriorityQueue中进行使用,就必须包含额外用于生成自然顺序的功能,或提供一个Comparator。
Set
Set中不允许出现重复的对象值。Set最常见的用法是测试成员身份,我们可以轻松检测某个对象是否存在于Set当中。因此,查找通常也是Set最重要的操作(所以HashSet通常是我们的首选)。
Set与Collection有相同的接口,但不同于List添加了额外的功能,Set就是一个行为不同的Collection。
Set是根据对象的“值”来确定成员身份。
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
public class SetOfInteger {
public static void main(String[] args) {
Random rand = new Random(System.currentTimeMillis()); // 使用的参数是一个时间戳
Set intset = new HashSet<>();
for (int i = 0; i < 10000; i++)
intset.add(rand.nextInt(30));
System.out.println(intset);
}
} 程序执行的结果是:
![]()
在早期的Java版本中,HashSet输出的顺序没有明显的规律。因为HashSet会通过哈希来提高效率,这使得HashSet的维护和储存与其他Set都不相同(虽然LinkedHashSet也使用了哈希,但它会通过链表按照顺序维护元素)。
另外,TreeSet是通过红黑树数据结构进行储存的。
不过现在哈希算法变了,因此我们的输出变得有规律了(我们不应该依赖这种行为)。
import java.util.HashSet;
import java.util.Set;
public class SetOfString {
public static void main(String[] args) {
Set colors = new HashSet<>();
for (int i = 0; i < 100; i++) {
colors.add("黄色");
colors.add("蓝色");
colors.add("红色");
colors.add("蓝色");
colors.add("黄色");
colors.add("红色");
colors.add("橙色");
colors.add("紫色");
}
System.out.println(colors);
}
} 程序执行的结果是:
![]()
使用TreeSet可以获得有顺序的数列:

对Set而言,最常见的操作之一是使用contain()来测试Set成员身份:
import java.util.Collection;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
public class SetOperations {
public static void main(String[] args) {
Set set1 = new HashSet<>();
Collections.addAll(set1, "A B C D E F G H I J K L".split(" "));
set1.add("M");
System.out.println("H: " + set1.contains("H"));
System.out.println("N: " + set1.contains("N"));
System.out.println();
Set set2 = new HashSet<>();
Collections.addAll(set2, "H I J K L".split(" "));
System.out.println("set2是否在set1中: " + set1.containsAll(set2));
System.out.println();
set1.remove("H");
System.out.println("set1: " + set1);
System.out.println("set1是否在set2中: " + set2.containsAll(set1));
System.out.println();
set1.removeAll(set2);
System.out.println("删去set1中所有存在于set2中的元素: " + set1);
System.out.println();
Collections.addAll(set1, "X Y Z".split(" "));
System.out.println("将'X Y Z'添加到set1中: " + set1);
}
} 程序执行的结果是:

在读取文件时,一个没有重复元素的列表会非常有用:
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
import java.util.Set;
import java.util.TreeSet;
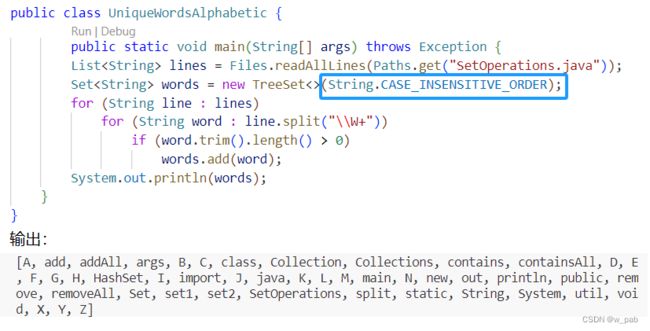
public class UniqueWords {
public static void main(String[] args) throws Exception {
List lines = Files.readAllLines(Paths.get("SetOperations.java"));
Set words = new TreeSet<>();
for (String line : lines)
for (String word : line.split("\\W+"))
if (word.trim().length() > 0)
words.add(word);
System.out.println(words);
}
} 程序执行的结果如下:
![]()
上述程序会依次处理文件中的每一行,以正则表达式\\W+为参数,使用String.split()将其分解为单词。
由于使用的是TreeSet,所以获得的字符串会以字典顺序进行划分,因此大写字母和小写字母没有连续在一起。若需要的是按字母顺序排序,需要将String.CASW_INSENSITIVE_ORDER这个Comparator(比较器,用来建立顺序关系的对象)传递给TreeSet:
Map
Map实现了这样一个概念:将对象映射到其他对象上。例如,现在需要测试Java的Random类的随机性,需要生成大量的随机数,并计算不同区间的数的数量:
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
public class Statistics {
public static void main(String[] args) {
Random rand = new Random(10);
Map m = new HashMap<>();
for (int i = 0; i < 10000; i++) {
// 随机数的范围是0~20
int r = rand.nextInt(20);
Integer freq = m.get(r);
m.put(r, freq == null ? 1 : freq + 1); // 自动装箱机制可以把int转换为Integer
}
System.out.println(m);
}
} 程序执行的结果是:
![]()
上述程序中,若集合中还不存在键r,则get()会返回null。否则get()会返回与键相关联的Integer值。
Map的键不仅可以是这种基本类型,也可以是String等类。另外,Map同样具有各种用于检测的contains方法:
import java.util.HashMap;
import java.util.Map;
public class PetMap {
public static void main(String[] args) {
Map petMap = new HashMap<>();
petMap.put("我的猫", new Cat("汤姆"));
petMap.put("我的狗", new Dog("斯派克"));
petMap.put("我的仓鼠", new Dog("野牛"));
System.out.println(petMap);
Pet dog = petMap.get("我的狗");
System.out.println("petMap.get(\"我的狗\"): " + dog);
System.out.println("通过键进行检测: " + petMap.containsKey("我的狗"));
System.out.println("通过值进行检测: " + petMap.containsValue(dog));
}
} 程序执行的结果是:

与数组和Collection类似,Map也可以扩展为多维:我们可以创建一个值为Map的Map(内部的Map的值可以是其他集合,包括其他Map)。例如:
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import reflection.Person;
public class MapOfList {
public static final Map> petPeople = new HashMap<>();
static {
petPeople.put(new Person("小红"),
Arrays.asList(new Cymric("茉莉"), new Mutt("斑点")));
petPeople.put(new Person("小绿"),
Arrays.asList(new Cat("斯凯特"), new Dog("玛格特")));
petPeople.put(new Person("小黄"),
Arrays.asList(new Pug("路易斯·杜普里"),
new Cat("斯丹福"),
new Cat("粉色可乐")));
}
public static void main(String[] args) {
System.out.println("宠物的主人:" + petPeople.keySet());
System.out.println("宠物:" + petPeople.values());
for (Person person : petPeople.keySet()) {
System.out.println();
System.out.println(person + "的宠物有:");
for (Pet pet : petPeople.get(person))
System.out.println(" " + pet);
}
}
} 程序执行的结果是:

新特性:记录(record)类型
使用Map,可以做到很多具有想象力的事。但如果要让一个类成为Map中的键,首先需要为这个类定义两个函数:equal()和hashCode(),这无疑增加了对这个类的创建和维护成本。
为此,JDK 16最终引入了record关键字。这一关键字定义的是希望成为数据传输对象(也叫数据载体)的类。当使用record关键字时,编译器会自动生成:
- 不可变的字段
- 一个规范的构造器
- 每个元素都有的访问器方法
- equals()
- hashCode()
- toString()
例如:
import java.util.Map;
record Employee(String name, int id) {
}
public class BasicRecord {
public static void main(String[] args) {
var hong = new Employee("小红", 11);
var lan = new Employee("小蓝", 9);
// hong.id = 12; // 错误的使用:id在Employee中的访问权限是private
System.out.println(hong.name()); // 需要使用访问器进行访问
System.out.println(hong.id());
System.out.println(hong);
// Employee可以作为Map中的键
var map = Map.of(hong, "A", lan, "B");
System.out.println(map);
}
}程序执行的结果如下:

record关键字会自动创建规范的构造器,并且会自动添加内部的private final字段name和id。构造器会根据提供的参数列表初始化字段。除此之外,使用record时还需注意:
- record中不能添加字段,但允许静态的成员(方法、字段和初始化器)。
- record的参数列表定义的每个属性都会自动获得自己的访问器
就如之前提到的,record会自动创建合理定义的hashCode()和equals()。这么做的方便之处在于,即使之后对record中的字段进行增删,这个类也可以正常进行工作。
record中可以定义方法,但这些方法只能用于读取字段:
record FinalFields(int i) {
int timesTen() {
return i * 10;
}
/*
// 不能对final变量i进行赋值
void tryToChange() {
i++; // 编译器报错
}
*/
}除此之外,record的参数也可以是其他对象,例如:
record Company(Employee[] e) { // 参数可以是对象
}
// class Conglomerate extends Company { // record不允许继承
// }record不允许被继承,因为它是隐式的final。除此之外,record也不允许继承其他类。但record可以实现接口:
interface Star {
double brightness();
double density();
}
record ImplementingRecord(double brightness) implements Star {
@Override
public double density() {
return 100.0;
}
}
在上述例子中,并没有实现接口的brightness()方法,但编译器没有报错。这是因为在record的参数中存在一个brightness,编译器会自动为这个参数生成对应的访问器,这个访问器刚好可以匹配Star接口中的brightness()。
record也可以被嵌套在类或某个方法中。嵌套和局部的record都是隐式静态的:
public class NestedLocalRecords {
record Nested(String s) {
}
void method() {
record Local(String s) {
}
}
}虽然record会自动构建构造器,但我们依旧可以使用一个紧凑构造器来添加构造器行为,这种构造器常被用于验证参数。这种紧凑构造器是没有参数列表的。:
record PlusTen(int x) {
PlusTen { //无参的
x += 10; // 对字段的调整只能在构造器中进行
}
// 无法在构造器外调整字段
/* void mutate() {
x += 10;
}*/
public static void main(String[] args) {
System.out.println(new PlusTen(10));
}
}程序执行的结果如下:
![]()
编译器会为x创建一个中间的占位符,然后在构造器的最后执行一次赋值,将结果赋值给this.x。若有必要,也可以使用普通构造器语法替换规范构造器:
record Value(int x) {
Value(int x) { // 带有参数的普通构造器
this.x = x;
}
}record会要求这个非紧凑构造器精确复制record的签名,包括标识符的名字。这意味着像Value(int init)之类的语句是不被允许的。除此之外,若使用的是非紧凑构造器,final字段x不会被初始化,所以若不在上述这个构造器中添加语句this.x = x,编译器将会报错。
若需要复制一个record,必须将它的所有字段显式地传递给其构造器:
record R(int a, double b, char c) {
}
public class CopyRecord {
public static void main(String[] args) {
var r1 = new R(11, 2.2, 'z');
var r2 = new R(r1.a(), r1.b(), r1.c());
System.out.println(r2);
}
}程序执行,返回true。
record在提高代码的可读性上也有显著作用。