python中match/case & 析构
前言
python3.10 版本增加了 match/case 模式匹配功能,可以替换我们常用的 if/elif/elif/.../else 代码块,并且支持析构:一种更强大的 拆包 功能。模式匹配是一种强大的工具,借助析构可以处理 嵌套的映射和序列 等结构化记录。下面是从书本中整理借鉴的内容,供大佬们学习参考:
一、序列模式匹配
序列包括字符串、列表、字节序列、数组、XML元素和数据库查询结果,这些序列在操作上有很多共同之处,都支持迭代、切片、排序和拼接操作。
1、序列的几种类型:
- 容器序列:存放的是所包含对象的引用,对象可以是任何类型,其中包括嵌套容器。示例:
list、uple和collections.deque。 - 扁平序列:可存放一种简单类型的项,在自己的内存空间中存储所含内容的值,而不是各自不同的 Python 对象,扁平序列更加紧凑,但是只能存放原始机器值,例如字节、整数和浮点数。示例:
str、bytes和array.array。 - 可变序列:list、bytearray、array.array、collections.deque
- 不可变序列:tuple、str、bytes
可变序列继承了不可变序列的所有方法。
2、嵌套拆包
拆包的对象可以嵌套,例如(1, 2, (3, 4))= a, b, c,那么结果就是a = 1,b = 2,c = (3,4)是个元组。如果值的嵌套结构是相同的,则 Python 能正确处理,先举一个嵌套拆包的metro_test示例,供后续模式匹配使用:
# metro_test.py
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)), # 每个元组是一个四字段记录,最后一个字段是坐标对
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for name, _, _, (lat, lon) in metro_areas: # 把最后一个字段赋值给一个嵌套元组,拆包坐标对
if lon <= 0: # lon <= 0:测试条件只选取西半球的城市
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__ == '__main__':
main()
输出结果:
| latitude | longitude
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
São Paulo | -23.5478 | -46.63583、match/case 使用
下面是使用 match/case 处理序列的第一个示例。假设收到的消息为 ERROR 403 3。经过拆分和解析之后,得到消息 ['BEEPER', 440, 3]。
# test_match.py
def handle_command(self, message):
match message: # 1
case ['BEEPER', frequency, times]: # 2
self.beep(times, frequency)
case ['NECK', angle]: # 3
self.rotate_neck(angle)
case ['LED', ident, intensity]: # 4
self.leds[ident].set_brightness(ident, intensity)
case ['LED', ident, red, green, blue]: # 5
self.leds[ident].set_color(ident, red, green, blue)
case _: # 6
raise InvalidCommand(message)- 注释1: match 关键字后面的表达式(即message)是匹配对象(subject),即各个 case 子句中的模式尝试匹配的数据。
- 注释2: 这个模式匹配一个含有 3 项的序列。第一项必须是字符串 'BEEPER'。第二项和第三项任意,依次绑定到变量 frequency 和 times 上。
- 注释3: 这个模式匹配任何含有两项,而且第一项为 'NECK' 的序列。
- 注释4: 这个模式匹配第一项为 'LED',共有 3 项的序列。如果项数不匹配,则 Python 继续执行下一个 case 子句。
- 注释5: 这个模式也匹配第一项为 'LED' 的序列,不过一共有 5 项。
- 注释6: 这是默认的 case 子句,前面所有模式都不匹配时执行。_ 是特殊的变量,稍后讲解。
表面上看,match/case 与C语言中的 switch/case 语句很像,但只是表象,与 switch 相比,match 的一大改进是支持析构,是一种高级的拆包形式。
因此,处理序列的 switch/case 语句完全可以替换成 if/elif/elif/.../else 代码块。这样做可以避免“落空”(fallthrough)和“ else垂悬”问题。
下面使用析构的方式,处理metro_test例子:
# 析构处理metro_test
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record: # 1
case [name, _, _, (lat, lon)] if lon <= 0: # 2
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')- 注释1:这里 match 的匹配对象是 record,即metro_areas中的各个元组。
- 注释2:一个 case 子句由两部分组成:一部分是模式,另一部分是使用 if 执行的卫语句(guard clause 可选,仅当匹配模式时才运行)
一般情况下,匹配对象需同时满足以下条件才能匹配序列模式:
- 匹配对象是序列。
- 匹配对象和模式的项数相等。
- 对应的项相互匹配,包括嵌套的项。
如上面的例子中 [name, _, _, (lat, lon)] 匹配一个含有4项的序列,最后一项必须是一个含有两项的序列。
序列模式可以写成元组或列表,或者任意形式的嵌套元组和列表,使用哪种句法都没有区别,因为在序列模式中,方括号和圆括号的意思是一样的。示例中的模式写成列表形式,其中嵌套的序列则写成元组形式,这样做只是为了避免重复使用方括号或圆括号。
在match/case 上下文中,str、bytes 和 bytearray实例不作为序列处理。match把这些类型视为“原子值”,就像整数789整体被视为一个值,而不是数字序列。如果想把这些类型的对象视为序列,则需要在 match 子句中进行转换,如:tuple(phone)
match tuple(phone):
case ['1', *rest]: # 匹配1
...
case ['2', *rest]: # 匹配2
...
case ['3' | '4', *rest]: # 匹配3或4标准库中与序列模式兼容的类型包括:list、memoryview、array.array、tuple、range、collections.deque
与拆包不同的是,模式不析构序列以外的可迭代对象(如:迭代器)
_ 符号在模式中有特殊意义:匹配相应位置上的任何一项,但不绑定匹配项的值。并且 _ 是唯一可在模式中多次出现的变量。
模式中的任何一部分均可以使用as关键字绑定到变量上:
case [name, _, _, (lat, lon) as coord]:如:上述模式可以匹配 ['Shanghai', 'CN', 24.9, (31.1, 121.3)],并绑定以下变量
| 变量 | 对应的值 |
| name | 'Shanghai' |
| lat | 31.1 |
| lon | 121.3 |
| coord | (31.1, 121.3) |
添加类型可以让模式更具体,也可以在运行时起到类型检查的作用:
case [str(name), _, _, (float(lat), float(lon))]:上面代码中,表达式str(name) 和 float(lat)看起来像是前者把 name 转换成 str,后者把 lat 转换成float。其实在模式上下文中,这种句法的作用是在运行时检查类型。前面的模式将匹配一个4项序列,其中第一项必须是一个字符串,第四项必须是一对浮点数。而且,第一项中的字符串将绑定到 name 变量上,第四项中的一对浮点数将分别绑定到 lat 和 lon 变量上。
并且,如果想匹配任何以字符串开头、以嵌套两个浮点数的序列结尾的序列,可以用下面的模式:
case [str(name), *_, (float(lat), float(lon))]:*_ 匹配任意数量的项,而且不绑定变量。但如果把 *_ 换成 *extra,匹配的零项或多项将作为列表绑定到 extra 变量上。
二、映射匹配模式
match/case 语句的匹配对象可以是映射。映射的的模式看似 dict 字面量,其实可以匹配collections.abc.Mapping的任何子类或虚拟子类。
示例:从匹配对象中提取作者
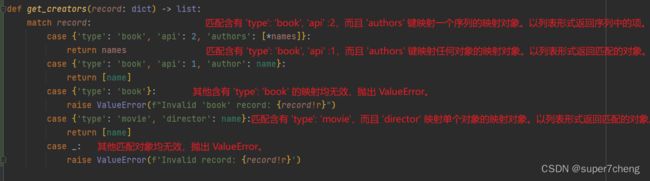
代码如下:
def get_creators(record: dict) -> list:
match record:
case {'type': 'book', 'api': 2, 'authors': [*names]}: ❶
return names
case {'type': 'book', 'api': 1, 'author': name}: ❷
return [name]
case {'type': 'book'}: ❸
raise ValueError(f"Invalid 'book' record: {record!r}")
case {'type': 'movie', 'director': name}: ❹
return [name]
case _: ❺
raise ValueError(f'Invalid record: {record!r}')通过示例可以看出处理半结构化数据(例如 JSON 记录)的几点注意事项:
- 包含一个描述记录种类的字段(例如 'type' : 'movie');
- 包含一个标识模式版本的字段(例如 'api' : 2),方便公开 API 版本更迭;
- 包含处理特定无效记录(例如 'book' )的 case 子句,以及兜底 case 子句。
下面测试一下 get_creators 函数。
# 测试 1
b1 = dict(api=1, author='Douglas Hofstadter',
type='book', title='Gödel, Escher, Bach')
print(get_creators(b1))
# 结果
['Douglas Hofstadter']# 测试 2
from collections import OrderedDict
b2 = OrderedDict(api=2, type='book',
title='Python in a Nutshell',
authors='Martelli Ravenscroft Holden'.split())
print(get_creators(b2))
# 结果
['Martelli', 'Ravenscroft', 'Holden']# 测试 3
print(get_creators({'type': 'book', 'pages': 770}))
>>Traceback (most recent call last):
File "D:\function.py", line 619, in
print(get_creators({'type': 'book', 'pages': 770}))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:function.py", line 614, in get_creators
raise ValueError(f"Invalid 'book' record: {record!r}")
ValueError: Invalid 'book' record: {'type': 'book', 'pages': 770} # 测试 4
print(get_creators('Spam, spam, spam'))
>>Traceback (most recent call last):
File "D:\function.py", line 620, in
print(get_creators('Spam, spam, spam'))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\function.py", line 618, in get_creators
raise ValueError(f'Invalid record: {record!r}')
ValueError: Invalid record: 'Spam, spam, spam' 注意:映射模式匹配中键的顺序无关紧要。即便测试2中的b2 是一个OrderedDict,也可以作为匹配对象。
与序列模式不同,就算只有部分匹配,映射模式也算是成功匹配,在上述测试案例中,b1和b2两个对象中都有 'title' 键,虽然任何 'book' 模式中都没有这个键,但依旧可以匹配成功。
如果不使用其他的键值的话,就没必要使用 **extra 匹配多余的键值对,若想把多余的键值对存起来,可以在变量前加**,并放在模式最后。切记 **_是无效的。
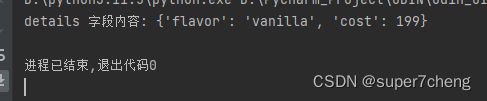
food = dict(category='ice cream', flavor='vanilla', cost=199)
match food:
case {'category': 'ice cream', **details}:
print(f'details 字段内容: {details}')结果:
最后,对于模式匹配而言,仅当匹配对象在运行 match 语句之前已经含有所需的键才能匹配成功,模式匹配不会自动处理缺失的键,因为模式匹配使用 dict.get(key, sentinel) 方法。其中,sentinel是特殊的标记值,不会出现在用户数据中。