【Linux】自动化构建工具 —— make/makefile&&Linux第一个小程序 - 进度条

个人主页:@Sherry的成长之路
学习社区:Sherry的成长之路(个人社区)
专栏链接:Linux
长路漫漫浩浩,万事皆有期待
上一篇博客:Linux编译器 gcc/g++的使用&&初识动静态链接库
文章目录
- 一、前言
- 二、概念
- 三、代码实现
- 四、实现原理
-
- 1、依赖关系和依赖方法
- 2、清理
-
- ① .PHONY 伪目标
- ② .PHONY 的取舍
- 3、make 确定是否编译的方法
- 4、完整代码
- Linux第一个小程序 - 进度条
-
- 行缓冲区的概念
- \r和\n
- 进度条代码及效果展示
- 总结:
一、前言
上篇博客,我们学习了 gcc 编译器。学会了如何在 Linux 上编译C语言代码。如果有上百个源文件,难道一个个都用 gcc 编译为 .o 文件,最后将它们一起链接起来?
有没有一种方法,使编译更加快捷,一定程度实现自动化编译?
可以使用 make/makefile 构建一个简单的自动化工具。
二、概念
makefile :
makefile 是一个文件。它是一个工程文件的编译规则,描述了整个工程的编译链接等规则。
写好的 makefile 文件可以使用一行命令来完成 “自动化编译” ,从而完成对工程的编译,极大提高效率。
make :
make 是一个命令工具,用来一个解释 makefile 中文件中的指令。
当已经编写好 makefile 文件后,只需要使用 make ,就可以执行 makefile 中的内容。
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。所以使用好 make/makefile ,可以使得开发更加得心应手。
总结:make 是一条指令,makefile 是一个文件,两个搭配使用,完成项目自动化构建。
三、代码实现
在讲解 make/makefile 之前,我们先写一个小 demo ,以这个 demo 为基准,对其进行讲解。
makefile 文件需要创建在当前工程的目录下,makefile 文件的名称可以为 makefile 或 Makefile
假设当前工程下已经有了一个 test.c ,我们直接开始 demo 的编写:

这样 makefile 就编写好了,就两句话,这时编写的 makefile 可以完成对程序的编译。
我们返回终端,使用 make 就可以对 test.c 进行编译:

使用 make 指令后,makefile 的第二行内容被打印在终端,并且生成了可执行程序 test ,test 程序也是可以执行的。
四、实现原理
1、依赖关系和依赖方法
在 Makefile 文件中,有这样一句话:
test:test.c
刚刚测试过我们知道 test 是目标文件,而 test.c 则是原始文件。
而 test.c 经过 gcc test.c -o test 生成 test 文件。
它们的关系 :
- test 依赖 test.c 生成,所以 test.c 是 test 的依赖文件 。它们之间的关系被称为 依赖关系 。
- test.c 生成 test 需要通过 gcc test.c -o test 指令,这条指令就是 依赖方法 。
依赖关系 和 依赖方法 如何理解呢?
我们通过一个 makefile 理解一下:

在 makefile 文件中,共有四组依赖关系和依赖方法 ,当使用 make 调用 makefile 文件中内容时,便开始执行 makefile 中的内容:
test 依赖于 test.o ,但是 test.o 并不存在,跳转到下一组依赖关系
test.o 依赖于 test.s ,但是 test.s 并不存在,跳转到下一组依赖关系
test.s 依赖于 test.i ,但是 test.i 不存在,跳转到下一组依赖关系
test.i 依赖于 test.c ,test.c 存在,这时开始执行依赖方法
由此开始,逐渐执行上面的依赖方法,一层层回退,逐渐生成 test.i 、test.s 、test.o ,最后生成可执行程序,make 执行完毕。我们发现,这一过程就像 数据结构的栈 。
当目标文件所依赖的文件不存在时,就会将依赖方法入栈,知道依赖关系匹配了,再执行相应的依赖方法,在按照栈的规则,逐渐将栈中的元素出栈,规则满足后进先出。
为了验证这些步骤是否都被执行,我们 make 一下看看:
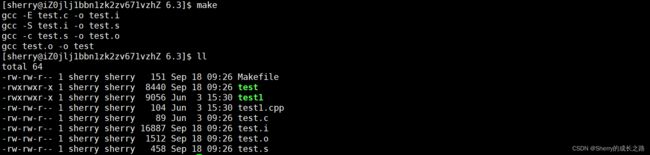
依赖方法对应的文件都产生了,所以依赖关系和依赖方法必须同时具备并正确,缺一不可 。
2、清理
平时写代码时,经常需要反复编译,执行代码。
而在下一次重新编译之前,需要清理一下上次生成的可执行程序。但是清理的时候可能清理错误,不小心把源文件删了,这时又造成了问题。
而上面的步骤,我们也生成了很多附加文件(如 test.i 等)。
所以我们基于 demo 增加一个清理功能:
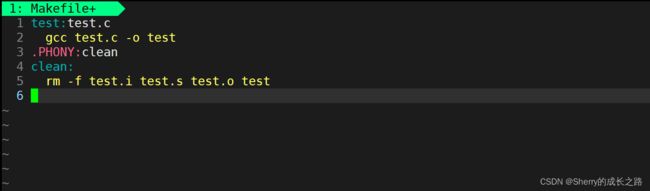
使用 make 测试一下:

文件也都删除了。
这是为什么,新增语句是什么意思?
① .PHONY 伪目标
.PHONY 修饰的对象是伪目标,伪目标的特性是:总是被执行的。
.PHONY 修饰的一定能被反复执行,但是能被反复执行的不一定被 .PHONY 修饰。
多次执行 make 和 make clean 试试:
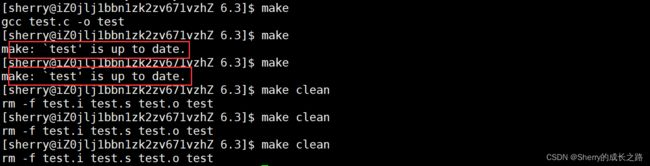
注:makefile 默认从上到下扫描只会执行第一组的依赖关系和依赖方法,所以默认执行第一组,这时使用 make 就可以;而 clean 为第二组,所以需要 make clean ,加上对应的关系。同理,对于第一组,使用 make test 也能执行。
第一组关系没有被 .PHONY 修饰,而不能重复执行。但是第二组 clean 可以重复执行 。
但是怎么证明 .PHONY 修饰对象之后,对象能被反复执行?我们再验证一下,给 test 加上修饰:
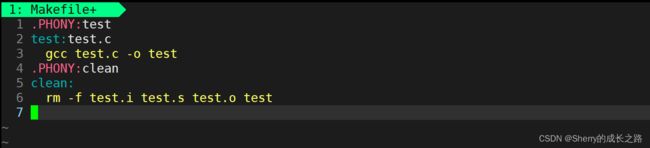
加上 .PHONY 修饰后,make 可以执行多次了,证明了 .PHONY 的作用。

但是能被反复执行的不一定被 .PHONY 修饰,就比如 clean :
当 clean 去掉修饰之后,依然能被反复执行。

② .PHONY 的取舍
一般对于编译来说,是不加 .PHONY 修饰的。
因为编译是十分耗时间,特别是当工程量很大的时候,编译一两小时都不为过。所以防止对未修改的程序反复编译 ,一般编译时不加修饰。
但是 清理clean 是可以多次执行的,因为删除不太浪费时间,且可以反复清理,确认是否清理完毕。并且为了肯定清理可以被多次执行,所以通常用 .PHONY 修饰。
3、make 确定是否编译的方法
上面我们测试 make 时,发现当编译过一次后,继续使用 make 就无法继续编译了。但是 clean 是可以不加修饰反复执行的。 make 是如何确定是否要编译?
对于程序来说,时间有两条线。第一条是源代码时间的一条线,第二条是形成的可执行程序的时间的一条线 。而它们之间的次序,是先有源代码,再有可执行程序。
所以只要可执行程序的最近修改时间比源文件的修改时间晚,就认为当前可执行程序是最新的,为了减少时间和其他开销,于是不执行编译;反之执行编译 。
我们再重新生成可执行程序,并重复 make ,观察它们的时间:
这里就要用到 stat 指令,它的 modify 就是最近修改时间 ,如果对 stat 指令不了解的可以看这一篇:【Linux】基本指令(一) (在 ls 指令部分)

可执行程序 test 的时间明显比 源代码 test.c 晚,所以 make 并不能起作用。
那么基于对这个概念的理解,我们能否用其他方法再次执行 make ?
touch 指令为创建一个文件。若文件不存在则会创建一个文件;若文件存在则会把文件时间更新到最新。
使用 touch 更新一下 test.c 的时间,用 stat 观察时间,并反复 make 试试:


由此,我们发现可以使用 touch 来 “欺骗” make 来反复编译。这也侧面证明了: make 对于是否编译的决策是基于修改时间,而并不是基于文件内容是否修改 。
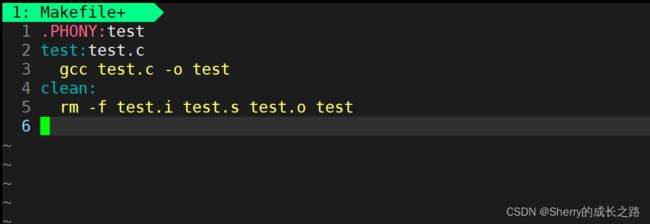
4、完整代码
test:test.c
gcc test.c -o test
.PHONY:clean
clean:
rm -f test.i test.s test.o test
对于依赖关系而言,: 左边为目标文件,: 右边为依赖文件
依赖方法前需要有一个 tab ,为固定格式
: 右边可以有多个依赖文件 ,: 右边通常被称为依赖文件列表
对于 : 右边,目标文件对应的依赖文件列表可以为空 (例如 clean)
makefile 默认执行第一组的依赖关系和依赖方法,对于第一组可以直接使用 make 执行,后面则需要 make + 目标文件
.PHONY 修饰的 伪目标可反复执行 ,但反复执行的不一定是伪目标
Linux第一个小程序 - 进度条
行缓冲区的概念
首先,我们来感受一下行缓冲区的存在,在Linux当中以下代码的运行结果是什么样的?
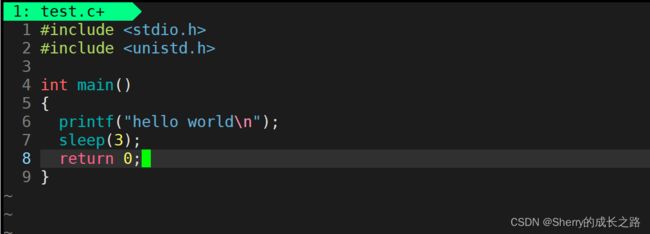
对于此代码,当然是先输出字符串hello world然后休眠3秒之后结束运行。那么对于以下代码呢?
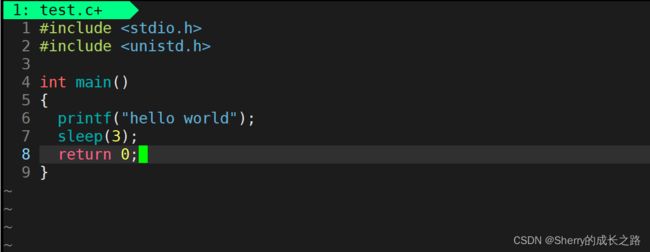
可以看到代码中仅仅删除了字符串后面的’\n’,那么代码的运行结果还与之前相同吗?
答案是不相同,该代码的运行结果是:先休眠3秒,然后打印字符串hello world之后结束运行。该现象就证明了行缓冲区的存在。
显示器对应的是行刷新,即当缓冲区当中遇到’\n’或是缓冲区被写满才会被打印出来,而在第二份代码当中并没有’\n’,所以字符串hello world先被写到缓冲区当中去了,然后休眠3秒后,直到程序运行结束时才将hello world打印到显示器当中。
\r和\n
\r: 回车,使光标回到本行行首。
\n: 换行,使光标下移一格。

而我们键盘上的Enter键实际上就等价于\n+\r。
既然是\r是使光标回到本行行首,那么如果我们向显示器上写了一个数之后再让光标回到本行行首,然后再写一个数,不就相当于将前面一个数字覆盖了吗?但不使用’\n’进行换行怎么将缓冲区当中数据打印出来?
这里我们可以使用fflush函数,该函数可以刷新缓冲区,即将缓冲区当中的数据刷新到显示器中。
对此我们可以编写一个倒计时的程序。

在输出下一个数之前都让光标先回到本行行首,就得到了倒计时的效果。

进度条代码及效果展示
知道了\r这个概念我们就可以实现一个简单的进度条了。
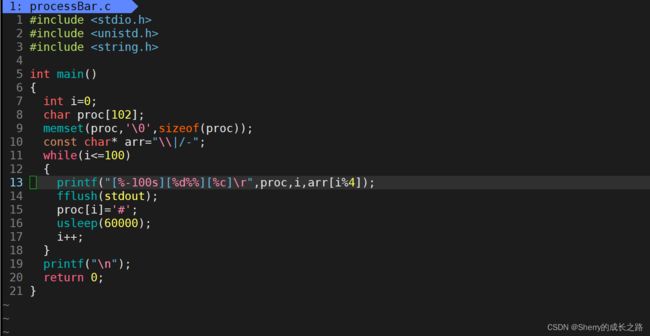
效果展示:
总结:
今天我们学习了自动化构建工具 —— make/makefile ,重点了解了 make/makefile 的规则上。实际开发中,好的 make/makefile 可以让项目开发事半功倍。接下来,我们将继续学习其他Linux环境基础工具的基本使用及配置。希望我的文章和讲解能对大家的学习提供一些帮助。
当然,本文仍有许多不足之处,欢迎各位小伙伴们随时私信交流、批评指正!我们下期见~
