Python学习_3(数据类型)
文章目录
-
- 一、字符串
-
-
- 1. 转义字符
- 2. 字符串的操作
- 3. 字符串函数
-
- 3.1 字符转换与检测
- 3.2 字符串查找与操作
-
- 二、数据类型详解
-
-
- 1. 列表
-
- 1.1 列表的基本操作
- 1.2 列表切片操作
- 1.3 列表的相关函数
- 1.4 深拷贝与浅拷贝
- 1.5 列表推导式
- 1.6 列表推导式的练习
- 2. 元组
-
- 2.1 基本定义和切片操作
- 2.2 元组推导式 (生成器)
- 2.3 生成器与yield关键字
- 2.4 元组练习
- 3. 字典
-
- 3.1 字典的定义和基本操作
- 3.2 字典的相关函数
- 3.3 字典推导式
- 4. 集合
-
- 4.1 集合的定义和基本操作
- 4.2 集合推导式
- 4.3 集合运算
-
一、字符串
字符串的定义方式:
- 单引号定义字符串 ’ ’
- 双引号定义字符串 " "
- 三引号定义字符串 ‘’‘xxx’’‘或者’’’’’‘xxx’’’’’’
- 字符串定义时,引号可以互相嵌套
1. 转义字符
一个普通的字符出现在转义符 \ 后面时,实现了另外一种意义
- \ 转义符,续行符
- 作为转义符时,在 \ 后面出现的字符可能会实现另外一种意义
- 作为续行符时,在行尾使用了 \ 后,可以换行继续书写内容
'''
转义字符
\n 代表一个换行符
\r 代表光标的位置(从\r出现的位置开始作为光标的起点)
\t 水平制表符(table缩进)
\b 退格符
\\ 一个\是转义符,在这个符号前再定义一个\就会取消转义,输出一个普通的\
# 把转义字符作为普通字符使用,在字符串前面加 r / R
'''
# 续行符
vars = '123' \
'456'
# 转义符
# 把转义字符作为普通字符使用,在字符串前面加r
vars = R'岁月是把杀猪刀,\n但是它拿长得丑的人一定办法都没有。。。'
print(vars)
2. 字符串的操作
vara = "君不见,黄河之水天上来,奔流到海不复回"
varb = "可爱"
# 字符串的拼接
print(varb+"的我") # 可爱的我
# 字符串乘法
print(varb*5) # 可爱可爱可爱可爱可爱
- 切片
'''
字符串[] 切片操作
str[开始值:结束值:步进值]
'''
# 字符串的索引操作,只能使用[]下标访问,不能修改
print(vara)
print(vara[4]) # 黄
print(vara[2:5]) # 见,黄 从2开始取值,到下标5之前
print(vara[2:8:2]) # 见黄之
print(vara[::-1]) # 回复不海到流奔,来上天水之河黄,见不君
print(vara[::1]) # 君不见,黄河之水天上来,奔流到海不复回
- 字符串的格式方法
format()
# 1.普通方法
a = '李白'
vars = '{}乘舟将欲行,忽闻岸上{}'.format(a,'踏歌声')
print(vars)
# 2.通过索引传参
vars1 = '{2}乘舟将欲行,忽闻岸上{1}'.format('a','b','c')
print(vars1)
# 3.关键字传参
vars2 = '{a}乘舟将欲行,忽闻岸上{b}'.format(a='李白',b='踏歌声')
print(vars2)
# 容器类型数据传参
vars3 = '豪放派:{0[0]},婉约派:{0[1]},蛋黄派:{0[2]}'.format(['李白','辛弃疾','达利园'])
print(vars3) # 豪放派:李白,婉约派:辛弃疾,蛋黄派:达利园
date = {'a':'杜甫','b':'香芋派'}
vars4 = '{a}乘舟将欲行,忽闻岸上{b}'.format(**date)
print(vars4)
# 3.7中新增的格式化方法 -- 方法
vars5 = f'{date["a"]}乘舟将欲行,忽闻岸上{date["b"]}'
print(vars5) # 杜甫乘舟将欲行,忽闻岸上香芋派
3. 字符串函数
3.1 字符转换与检测
- 大小写转换
'''大小写转换'''
varstr = 'i love you'
# str.capitalize() 返回原字符的副本,其首个字符大写,其余为小写
res = varstr.capitalize()
print(res) # I love you
# str.title() 返回原字符的副本,把字符中的每个单词首字母大写
print(varstr.title()) # I Love You
# str.upper() 把字符串中的英文字母全部转为大写
print(varstr.upper()) # I LOVE YOU
# str.lower() 把字符串中的英文字母全部转为小写
print(varstr.lower()) # i love you
# str.swapcase() 返回原字符的副本,其中大写字符转小写,小写转大写
vars = "IlOveYouTwo"
print(vars.swapcase()) # iLoVEyOUtWO
- 字符检测
'''字符检测函数'''
varnew = 'I我Love喜欢You你123'
varnew2 = 'I我Love喜欢You你'
varnew3 = '12345'
# 检测当前字符中的英文字符是否全部为大写字符组成
res = varnew.isupper()
print(res) # False
# 检测当前字符中的英文字符是否全部为小写字符组成
print(varnew.islower()) # False
# 检测当前字符中的英文字符是否符合title要求
print(varnew.istitle()) # True
# str.isalnum() 检测当前的字符是否由字符(中文、英文字符、数字)组成
print(varnew.isalnum()) # True
# str.isalpha() 检测当前的字符是否由中英文字符组成(不包含数字和其他字符)
print(varnew2.isalpha()) # True
# str.isdigit() 检测当前的字符是否由数字字符组成
print(varnew3.isdigit()) # True
# str..isspace() 检测当前的字符是否由空格字符组成
print(' '.isspace()) # True
# str.startswith() 检测一个字符串是否由指定的字符开头
print(varnew.startswith('I')) # True`在这里插入代码片`
print(varnew.startswith('我',1)) # True
# str.endswith() 检测一个字符串是否由指定的字符结尾,也可以指定开始和结束的位置
print(varnew.endswith('123')) # True
print(varnew.endswith('Love',0,6)) # True
3.2 字符串查找与操作
# 检测一个字符串是否存在于一个字符串中
print('love' in vars) # True
# 获取字符串的长度 len()
print(len(vars)) # 21
- 字符串查找
'''查找'''
# str.find(sub[, start[, end]]) 从左向右获取指定字符在字符串中第一次出现的索引位置,未找到则返回-1
print(vars.find('you')) # 5
print(vars.find('you',10,21)) # 17
# str.rfind() 从右向左获取指定字符在字符串中第一次出现的索引位置,未找到则返回-1
print(vars.rfind('you')) # 17
print(vars.rfind('you',0,10)) # 5
# str.index(sub[, start[, end]]) 类似于 find(),但在找不到子类时会引发 ValueError
# res = vars.index('yous') # ValueError: substring not found
res = vars.rindex('yous')
print(res) # 17
# str.count(sub[, start[, end]]) 统计字符串出现的次数
print(vars.count('i')) # 3
print(vars.count('you')) # 2
- 字符串操作
split()
varstr = 'user_admin_id_123'
varstr2 = 'uid=213&type=ab&kw=sss'
# str.split() 按照指定的字符进行分隔,把一个字符串分割成一个列表
res = varstr.split('_')
print(res) # ['user', 'admin', 'id', '123']
print(res[3]) # 123
res = varstr2.split('&')
for i in res:
r = i.split('=')
print(r.pop()) # 213 ab sss
# 可以指定分割的次数
res = varstr.split('_',2)
print(res) # ['user', 'admin', 'id_123']
# str.rsplit() 与split()类似
res = varstr.rsplit('_')
print(res) # ['user', 'admin', 'id', '123']
print(varstr.rsplit('_',2)) # ['user_admin', 'id', '123']
# str.strip() 可以去除字符串左右两侧的指定字符
varstr3 = '#####这是一个文章#的标题########'
res = varstr3.strip('#')
print(varstr3,len(varstr3)) # #####这是一个文章#的标题######## 23
print(res,len(res)) # 这是一个文章#的标题 10
# str.lstrip()去除字符串左侧的指定字符 str.rstrip()去除字符串右侧的指定字符
print(varstr3.lstrip('#')) # 这是一个文章#的标题########
print(varstr3.rstrip('#')) # #####这是一个文章#的标题
join()
arr = ['user','admin','id','123']
# str.join(iterable) 按照指定的字符,把容器类型中的数据连接成一个字符串
res = '**'.join(arr)
print(res) # user**admin**id**123
replace()
# str.replace() 替换
varstr4 = 'iloveyou tosimida iloveyou'
print(varstr4.replace('love','hate')) # ihateyou tosimida ihateyou
print(varstr4.replace('love','hate',1)) # 限制次数 ihateyou tosimida iloveyou
# 了解
varstr5 = 'love'
print(varstr5.center(11,'*')) # ****love***
print(varstr5.ljust(11,'*')) # love*******
print(varstr5.rjust(11,'*')) # *******love
二、数据类型详解
1. 列表
列表是一组有序的数据组合,列表中的数据可以被修改
列表的定义
- 可以使用中括号 [ ] 进行定义
- 可以使用
list函数定义 - 列表中的元素可以是任意类型,但一般都会存储同类型的数据
1.1 列表的基本操作
# 列表的定义
varlist1 = [1,2,3,4]
varlist2 = ['a','b','c','d']
# 列表的拼接,把多个列表的元素拼接成一个列表
res = varlist1 + varlist2
print(res) # [1, 2, 3, 4, 'a', 'b', 'c', 'd']
# 列表元素的重复
res = varlist1 * 3
print(res) # [1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]
# 检测元素是否存在于列表中
res = 'a' in varlist2
print(res) # True
# 列表的索引操作
print(varlist2[2]) # c
# 通过下标修改元素,但不能通过下标来添加元素
varlist2[2] = 'cc'
print(varlist2) # ['a', 'b', 'cc', 'd']
# 向列表中追加元素
varlist2.append('ff')
print(varlist2) # ['a', 'b', 'cc', 'd', 'ff']
# 获取列表的长度
print(len(varlist2)) # 5
# 列表元素的删除,通过下标进行元素的删除
del varlist2[2]
print(varlist2) # ['a', 'b', 'd', 'ff']
# pop() 默认删除最后一个
res = varlist2.pop()
print(res) # ff
print(varlist2) # ['a', 'b', 'd']
1.2 列表切片操作
varlist = ['刘德华','张学友','张国荣','黎明','郭富城','小沈阳','刘能','赵四','宋小宝']
'''
列表[开始索引:结束索引:步进值]
- 列表[开始索引:] 从开始索引到列表的最后
- 列表[:结束值] 从开始到指定的结束索引之前
- 列表[开始索引:结束索引] 从开始索引到指定结束索引之前
- 列表[开始索引:结束索引:步进值] 从开始索引到指定结束索引之前,按指定的步进进行取值切片
- 列表[:] 或者 列表[::] 获取所有元素的切片
'''
res = varlist[2:]
print(res) # ['张国荣', '黎明', '郭富城', '小沈阳', '刘能', '赵四', '宋小宝']
print(varlist[:2]) # ['刘德华', '张学友']
print(varlist[2:6]) # ['张国荣', '黎明', '郭富城', '小沈阳']
print(varlist[2:6:2]) # ['张国荣', '郭富城']
print(varlist[:])
print(varlist[::])
# 倒序输出
print(varlist[::-1])
# 使用切片方法,对列表元素进行更新和删除
print(varlist)
# 从指定下标开始,到指定下标结束,并替换成对应的数据(如果是容器类似数据,会拆分成每个元素进行赋值)
# varlist[2:6] = ['a','b','c']
print(varlist) # ['刘德华', '张学友', 'a', 'b', 'c', '刘能', '赵四', '宋小宝']
varlist[2:6:2] = ['a','b'] # 需要与要更新的元素个数对应
print(varlist) # ['刘德华', '张学友', 'a', '黎明', 'b', '小沈阳', '刘能', '赵四', '宋小宝']
# 切片删除
del varlist[2:6]
print(varlist) # ['刘德华', '张学友', '刘能', '赵四', '宋小宝']
1.3 列表的相关函数
varlist = ['刘德华','张学友','张国荣','黎明','郭富城','小沈阳','刘能','赵四','宋小宝']
# len() 获取列表长度 -- 元素的个数
print(len(varlist))
# count() 检测当前列表中指定元素出现的次数
res = varlist.count('张学友') # 1
''' 添加元素 '''
# append() 向列表的尾部追加新的元素,返回值为none
res = varlist.append('泡泡')
print(varlist) # ['刘德华', '张学友', '张国荣', '黎明', '郭富城', '小沈阳', '刘能', '赵四', '宋小宝', '泡泡']
# insert(index,obj) 可以向列表中指定的的索引位置添加新的元素,超出索引添加到末尾,索引为负则从后插入
varlist.insert(1,'aa')
print(varlist)
''' 删除元素 '''
# pop() 可以对指定索引位置上的元素做 出栈 操作,返回出栈的元素
res = varlist.pop() # 默认弹出列表的最后一个元素
print(res) # 泡泡
print(varlist.pop(5)) # 郭富城
# remove() 指定列表中的元素进行删除,没有返回值,只删除找到的第一个元素,没有则报错
varlist1 = [1,2,3,4,11,22,33,44,1,2,3,4]
varlist1.remove(1)
# varlist1.remove(10) ValueError: list.remove(x): x not in list
print(varlist1) # [2, 3, 4, 11, 22, 33, 44, 1, 2, 3, 4]
# clear() 清空列表内容
varlist.clear()
print(varlist) # []
# index() 查找指定元素在列表中第一次出现的位置
res = varlist1.index(3)
print(res) # 1
res = varlist1.index(3,2,11) # 在指定的索引范围内查找元素的索引位置
print(res) # 9
# extend() 接收一个容器类型的数据,把容器中的元素追加到原列表中
varlist1.extend('aaa')
print(varlist1) # [2, 3, 4, 11, 22, 33, 44, 1, 2, 3, 4, 'a', 'a', 'a']
# reverse() 列表翻转
varlist1.reverse()
print(varlist1) # ['a', 'a', 'a', 4, 3, 2, 1, 44, 33, 22, 11, 4, 3, 2]
''' 列表元素的排序 '''
varlist2 = [-6,5,-4,3,-2,1]
# sort() 对列表进行排序
res = varlist2.sort()
print(varlist2) # [-6, -4, -2, 1, 3, 5] 默认从小到大排序
res = varlist2.sort(reverse=True) # 从大到小
print(varlist2) # [5, 3, 1, -2, -4, -6]
# 可以传递一个函数,按照函数的处理结果进行排序
res = varlist2.sort(key=abs)
print(varlist2) # [1, -2, 3, -4, 5, -6]
''' 列表的复制 '''
# cpoy() 拷贝、赋值当前的列表
res = varlist2.copy()
print(res)
# 定义 多维列表
varlist3 = ['a','b','c',[11,22,33]]
res = varlist3.copy()
# del res[1] 对一维列表进行操作,没有问题
print(res) # ['a', 'c', [11, 22, 33]]
del res[3][1]
# 对多位列表中的元素进行操作,则出现了全部改变的情况
print(res) # ['a', 'b', 'c', [11, 33]]
print(varlist3) # ['a', 'b', 'c', [11, 33]]
1.4 深拷贝与浅拷贝
'''
浅拷贝: 只能拷贝当前列表,不能拷贝列表中的多维列表元素
深拷贝: 不仅拷贝当前的列表,同时把列表中的多维元素也拷贝一份
'''
varlist4 = [1,2,3]
# 简单的拷贝 就可以把列表复制一份
newlist = varlist4.copy()
print(varlist4,id(varlist4)) # [1, 2, 3] 16588712
print(newlist,id(newlist)) # [1, 2, 3] 16588136
# 对新拷贝的列表进行操作,也是独立的
del newlist[1]
print(newlist) # [1,3]
# 多维列表
varlist5 = [1,2,3,['a','b','c']]
print(varlist5) # [1, 2, 3, ['a', 'b', 'c']]
print(len(varlist5)) # 4
# 使用copy函数 拷贝一个多维列表
newlist = varlist5.copy()
print(newlist,id(newlist)) # [1, 2, 3, ['a', 'b', 'c']] 21896200
print(varlist5,id(varlist5)) # [1, 2, 3, ['a', 'b', 'c']] 21896232
# 如果是一个拷贝的列表,对它的多维列表元素进行操作时,会导致原列表中的多维列表也发生了改变
del newlist[3][1]
print(newlist,id(newlist)) # [1, 2, 3, ['a', 'c']] 27401224
print(varlist5,id(varlist5)) # [1, 2, 3, ['a', 'c']] 27401256
# 在使用copy函数时,只能拷贝外层的列表元素,这种方式也叫浅拷贝
print('newlist:',id(newlist[3][1]),'varlist5:',id(varlist5[3][1])) # newlist: 7690464 varlist5: 7690464
# 深拷贝:使用copy模块中的 deepcopy 方法
import copy
varlist6 = [1,2,3,['a','b','c']]
newlist = copy.deepcopy(varlist6)
del newlist[3][1]
print(varlist6) # [1, 2, 3, ['a', 'b', 'c']]
print(newlist) # [1, 2, 3, ['a', 'b', 'c']]
print('newlist:',id(newlist[3][1]),'varlist6:',id(varlist6[3][1])) # newlist: 18766048 varlist6: 18863104
1.5 列表推导式
'''
列表推导式
列表推导式提供了一个更简单的创建列表的方法。常见的用法是把某种操作应用于序列或可迭代对象的每个元素上,
然后使用其结果来创建列表,或者通过满足某些特定条件元素来创建子序列
- 采用一种表达式的当时,对数据进行过滤或处理,并且把结果组成一个新的列表
'''
# 计算平方列表
varlist = []
for i in range(10):
res = i**2
varlist.append(res)
print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 使用map函数和list函数
squares = list(map(lambda x:x**2,range(10)))
print(squares)
# 使用列表推导式完成
varlist = [i**2 for i in range(10)]
print(varlist)
varstr = '1234'
test = [int(i) for i in varstr]
print(test)
# 带有判断条件的列表推导式
# 变量 = [变量或变量的处理结果 for i in 容器类型数据 条件表达式]
newlist = [i for i in range(10) if i%2==0]
print(newlist)
# 带有条件判断的多循环的推导式
newlist = []
for x in [1,2,3]:
for y in [3,1,5]:
if x != y:
newlist.append((x,y))
print(newlist)
test1 = [(x,y) for i in [1,2,3] for y in [3,1,4] if x!=y]
print(test1)
# 矩阵横转竖
arr = [
[1,2,3,4],
[5,6,7,8],
[9,10,11,12]
]
newlist = [[row[i] for row in arr] for i in range(4)]
print(newlist) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
# 矩阵横转竖
arr = [
[1,2,3,4],
[5,6,7,8],
[9,10,11,12]
]
newlist = [[row[i] for row in arr] for i in range(4)]
print(newlist) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
1.6 列表推导式的练习
# 1.九九乘法表
jiu = [[str(y)+'*'+str(x)+'='+str(x+y) for y in range(1,x+1)] for x in range(1,10)]
print(jiu)
for i in jiu:
print(i)
# 2.使用列表推导式将字典中的键值对转换成 key=value 的数据格式
dict = {'user':'admin','age':20,'phone':123}
for k,v in dict.items(): # items()可以取字典的键和值
print(k,'=',v)
list = [key+'='+str(dict[key]) for key in dict]
print(list) # ['user=admin', 'age=20', 'phone=123']
print('&'.join(list)) # user=admin&age=20&phone=123
# 3.转小写
dict2 = ['AAAAA','bbBb','CCCccc']
dict3 = [i.lower() for i in dict2]
print(dict3) # ['aaaaa', 'bbbb', 'cccccc']
# 4.x是0-5之间偶数,y是0-5之间的奇数,将x,y组成元组放在列表中
newlist= []
for x in range(6):
for y in range(6):
if x % 2 == 0 and y % 2 == 1:
newlist.append((x,y))
print(newlist) # [(0, 1), (0, 3), (0, 5), (2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)]
list4 = [(x,y ) for y in range(6) for x in range(6) if x%2==0 and y%2==1]
print(list4)
# 5.九九乘法表
# 正序
list5 = [f'{i}*{j}={i*j}' for i in range(1,10) for j in range(1,i+1)]
print(list5)
# 倒序
list6 = [f'{i}*{j}={i*j}' for i in range(9,0,-1) for j in range(i,0,-1)]
print(list6)
# 6.求 M,N中矩阵和元素的乘积
M = [
[1,2,3],
[4,5,6],
[7,8,9]
]
N = [
[2,2,2],
[3,3,3],
[4,4,4]
]
list7 = [M[x][y]*N[x][y] for y in range(3) for x in range(3)]
list8 = [[M[x][y]*N[x][y] for y in range(3)] for x in range(3)]
print(list7) # [2, 12, 28, 4, 15, 32, 6, 18, 36]
print(list8) # [[2, 4, 6], [12, 15, 18], [28, 32, 36]]
2. 元组
元组和列表一样,都是一组有序的数据的集合,元组中的元素一旦定义不可以修改,因此元组又称为不可变数据类型。
2.1 基本定义和切片操作
'''
一、元组的定义
定义空元组:变量=() 或者 变量=tuple()
定义含有数据的元组 变量=(1,2,3)
注意:如果元组中只有一个元素时,必须加逗号 变量=(1,)
特例:变量=1,2,3 这种方式也可以定义为一个元组
二、元组的相关操作
由于元组是不可变的数据类型,因此只能使用索引进行访问,不能进行其他操作
元组可以和列表一样使用切片方式获取元素
'''
- 切片操作
# 切片操作 [起始:结束:步长]
res = vart[:] # (1, 2, 3, 4, 5)
res = vart[::] # (1, 2, 3, 4, 5)
res = vart[1:] # (2, 3, 4, 5)
res = vart[1:3] # (2, 3)
res = vart[1:5:2] # (2, 4)
res = vart[:3]
res = vart[::3] # (1, 4)
print(res)
- 其他操作
vart = 1,2,3,4,5
# 获取元组的长度 len()
print(vart,type(vart),len(vart)) # (1, 2, 3, 4, 5) 5
# 统计一个元素在元组中出现的次数
print(vart.count(5)) # 1
# 检测一个元素是否存在于元组中
res1 = 2 in res # True
res2 = 2 not in res # False
vart1 = ('张学友','吴孟达','柳岩','古龙','吴孟达')
# 获取一个元素在元组中的索引值
print(vart1.index('吴孟达')) # 1
print(vart1.index('吴孟达',2)) # 4 指定从下标2开始查找
print(vart1.index('吴孟达',2,5)) # 4 在指定的索引区间中查找
# 元组的加运算,合并元组,组成新的元组
res = (1,2,3)+('a','b') # (1, 2, 3, 'a', 'b')
res = (1,2,3)*3 # (1, 2, 3, 1, 2, 3, 1, 2, 3)
print(res)
2.2 元组推导式 (生成器)
- 列表推导式的结果返回了一个列表,元组推导式返回的是生成器
元组推导式
语法:
元组推导式 ==> (变量运算 for i in 容器) ==> 结果是一个生成器
生成器是什么
生成器是一个特殊的迭代器,生成器可以自定义,也可以使用元组推导式去定义
生成器是按某种算法去推算下一个数据或结果,只需要往内存中存储一个生成器,节约内存消耗,提升性能
语法:
(1) 里面是推导式,外面是一个()结果就是一个生成器
(2) 自定义生成器,含有 yield 关键字的函数就是生成器
含有yield关键字的函数,返回的结果是一个迭代器,换句话说,生成器函数就是一个返回迭代器的函数
如何使用操作生成器?
生成器是迭代器的一种,因此可以使用迭代器的操作方法来操作生成器
# 列表推导式
varlist = [1,2,3,4,5,6,7,8,9]
newlist = [i**2 for i in varlist]
print(newlist) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
# 元组推导式 -- generator
newt = (i**2 for i in varlist)
print(newt) # at 0x01C9F060>
# 使用next函数去调用
print(next(newt)) # 1
print(next(newt)) # 4
# 使用 list 或者 tuple 函数进行获取 (一次性提取数据)
# print(list(newt)) # [9, 16, 25, 36, 49, 64, 81]
# print(tuple(newt)) # (9, 16, 25, 36, 49, 64, 81)
# 使用 for 进行遍历
for i in newt:
print(i)
2.3 生成器与yield关键字
yield 关键字使用在 生成器函数中
- yield 和函数中的 return 有点像
共同点:执行到这个关键字后会把结果返回
不同点:
return 会把结果返回,并结束当前函数的调用
yield 会把结果返回,并记住当前代码执行的位置,下一次调用时会从上一次离开的位置继续向下执行
- 使用yield 定义一个 生成器函数
# 使用yield 定义一个 生成器函数
def hello():
print('hello',1) # next 执行到此先输出
yield 1 # 遇到yield会将结果返回
print('world',2) # 下一次从这里开始执行
yield 2
- 调用生成器函数,返回一个迭代器
# 调用生成器函数,返回一个迭代器
res = hello() # 调用后无结果,只是返回一个迭代器
print(res) # 2.4 元组练习
# 使用生成器改写 斐波那契数列
# 1 1 2 3 5 8
def fei(n):
if n == 1:
yield 1
if n == 2:
yield 1
yield next(fei(n-1))+next(fei(n-2))
res = fei(6)
res = next(res)
print(res)
# ========= 老师的写法 ===========
'''
def feibo(num):
a,b,i = 0,1,0
while i < num:
print(b,end=',')
a,b = b,a+b
i+=1
feibo(7) # 1,1,2,3,5,8,13,
'''
# 使用生成器函数改写
def feibo(num):
a,b,i = 0,1,0
while i < num:
yield b
a,b = b,a+b
i+=1
res = feibo(10)
print(res) # 3. 字典
字典也是一种数据的集合,由键值对组成的数据集合,字典中的键不能重复
字典中的键必须是不可变的数据类型,常用的键主要是:字符串,整形…
3.1 字典的定义和基本操作
- 字典的定义:
- 字典可以通过将以逗号分隔的
键:值对列表包含于花括号之内来创建 - 可以通过
dict构造器来创建
# 使用 {} 定义
vardict = {'a':1,'b':2,'c':3}
# 使用 dict{key=value,key=value}函数进行定义
vardict = dict(name='张三',sex='男',age=22) # key不需要加引号,类似关键字传参的写法
print(vardict) # {'name': '张三', 'sex': '男', 'age': 22}
# 数据类型的转换 dict(二级容器类型)列表或元祖,并且是耳机容器才可以转换
vardict = dict([['a',1],['b',2]])
print(vardict) # {'a': 1, 'b': 2}
# zip压缩函数,dict转类型
var1 = [1,2,3,4]
var2 = ['a','b','c','d']
vardict = dict(zip(var1,var2))
print(vardict) # {1: 'a', 2: 'b', 3: 'c', 4: 'd'}
- 字典的操作
- 增删改查
var1 = {'a':1,'b':2,'c':3}
var2 = {1: 'a', 2: 'b', 3: 'c', 4: 'd'}
# res = var1+var2 TypeError 字典不可拼接
# res = var1*2 TypeError 不可乘
# 获取元素
res = var1['a']
print(res) # 1
# 修改元素
res = var1['a'] = 111
print(res) # 111
# 删除元素
del var1['a']
print(var1) # {'b': 2, 'c': 3}
# 添加元素
var1['aa'] = 'AA'
print(var1) # {'b': 2, 'c': 3, 'aa': 'AA'}
# 如果字典中的key重复,则会覆盖(可以理解为修改)
var1['aa'] = 'aa'
print(var1)
- 数据获取
# 成员检测,只检测key,不检测value
res = 'aa' in var1
print(res) # True
# 获取当前字典的长度,只能检测档测当前有多少键值对
res = len(var1)
print(res) # 3
# 获取当前字典中的所有 key
res = var1.keys()
print(res) # dict_keys(['b', 'c', 'aa'])
# 获取当前字典中的所有 value
res = var1.values()
print(res) # dict_values([2, 3, 'aa'])
# 获取字典中的所有 键值对
res = var1.items()
print(res) # dict_items([('b', 2), ('c', 3), ('aa', 'aa')])
- 字典的遍历
for i in var1:
print(i) # 在遍历当前字典时,只能获取当前的key (或者写成var1.keys())
print(var1[i]) # 通过key获取对应的value
for i in var1.values(): # 遍历值
print(i)
# 遍历字典时 使用items()函数,可以在遍历中获取key和value
for k,v in var1.items():
print(k) # key
print(v) # value
3.2 字典的相关函数
# iter(d) 返回以字典的键为元素的迭代器。 这是 iter(d.keys()) 的快捷方式
vardict = {'a':1,'b':2,'c':3}
res = iter(vardict)
print(res)
print(next(res)) # a
# dict.pop() 通过key从当前字典中弹出键值对 (删除)
res = vardict.pop('a')
print(res) # 1
print(vardict) # {'b': 2, 'c': 3}
# dict.popitem() LIFO: last in, first out,后进先出
res = vardict.popitem() # 把最后加入到字典中的键值对删除,并返回一个元组
print(res) # ('c', 3)
# 字典中使用key获取一个不存在的元素会报错,但是使用get不会
res = vardict.get('aa')
# res = vardict['aa'] KeyError
print(res) # 默认返回None
# dict.update() 更新字典,key存在则更新,key不存在则添加
vardict = {'a':1,'b':2,'c':3}
print(vardict)
vardict.update(a=11,b=22)
vardict.update({'c':33,'d':44})
print(vardict) # {'a': 11, 'b': 22, 'c': 33, 'd': 44}
# dict.setdefault() 存在key则返回值,不存在则插入值为default的key,并返回default,default默认为none
res = vardict.setdefault('a') # 存在 1
res = vardict.setdefault('aa') # 不存在 --> default --> 默认none
res = vardict.setdefault('bb',111) # 不存在 --> default --> 设置为111 --> 返回111
print(res) # 111
print(vardict) # {'a': 11, 'b': 22, 'c': 33, 'd': 44, 'aa': None, 'bb': 111}
3.3 字典推导式
'''字典推导式'''
# 把字典中的键值对的位置进行交换
vardict = {'a':1,'b':2,'c':3}
# 普通方法实现 字典中的键值交换
newdict = {}
for k,v in vardict.items():
newdict[v] = k
print(newdict) # {1: 'a', 2: 'b', 3: 'c'}
# 使用字典推导式完成键值交换
newdict = {v:k for k,v in vardict.items()}
# 注意:以下推导式,返回的结果是一个集合,集合推导式
# newdict = {v for k,v in vardict.items()} {1, 2, 3}
print(newdict) # {1: 'a', 2: 'b', 3: 'c'}
# 把以下字典中的值是偶数的,保留下来,并交换键值对的位置
vardict = {'a':1,'b':2,'c':3,'d':4}
newdict = {v:k for k,v in vardict.items() if v%2 == 0 }
print(newdict)
4. 集合
确定的一组无序的数据的组合
- 确定的:当前集合中的元素的值不能重复
- 由多个数据组合的复合型数据(容器类型数据)
- 集合中的数据没有顺序
- 功能:成员检测、从序列中去除重复项以及数学中的集合类计算,例如交集、并集、差集与对称差集等等
4.1 集合的定义和基本操作
- 集合的定义
集合的定义:
可以使用{}来定义
可以使用set()进行集合的定义和转换
使用集合推导式完成集合的定义
注意:集合中的元素不能重复,集合中存放的数据:Number,String,Tuple,冰冻集合
- 集合的基本操作
# 定义一个集合
vars = {True,1,2,3,'abd','love',(1,2,3),0,False,3.14159,123}
# 1.无序 2.去重 123 (False = 0, True = 1 只存在一个)
print(vars) # {0, True, 2, 3, 3.14159, (1, 2, 3), 'love', 'abd', 123}
# 检测集合中的值
res = 123 in vars
print(res)
# 获取集合中元素的个数 (不重复)
print(len(vars)) # 9
# 集合的遍历
for i in vars:
print(i,type(i))
- 增删
# 向集合中追加元素 add()
vars.add('def') # 无返回值
print(vars)
# 删除集合中的元素
res = vars.pop() # 随机删
print(res) # 0 返回删除的值
print(vars)
# 指定删除集合中的元素 remove(),删除的值不存在,返回KeyError
vars.remove('def') # 无返回值
# vars.remove(0) 删除的值不存在,返回KeyError
print(vars) # {True, 2, 3, 3.14159, (1, 2, 3), 'love', 123, 'abd'}
# discard 指定删除集合中的元素,不存在的元素删除不报错
vars.discard('aa')
print(vars)
# 清空集合
# res = vars.clear()
print(vars) # set()
# update() 更新集合
res = vars.update({1,2,3,4,5})
print(vars) # {True, 2, 3, 3.14159, 4, (1, 2, 3), 5, 'abd', 123, 'love'}
- copy
'''
返回当前集合的浅拷贝,不存在深拷贝的问题
因为集合中的元素都是不可变的,包括元组和冰冻集合
不存在拷贝后,对集合中的二级容器进行操作的问题
'''
res = vars.copy()
print(res)
- 冰冻集合
frozenset()
'''
冰冻集合
语法:定义冰冻集合,只能使用frozenset() 函数进行定义
+ 冰冻集合一旦定义不能修改
+ 冰冻集合只能做集合相关的运算:求交集,差集...
+ frozenset() 本身就是一个强制转换类的函数,可以把其他任何容器类型的数据转为冰冻集合
'''
# 冰冻集合 frozenset([iterable])
v = frozenset({1,2,3})
v = frozenset((1,2,3))
print(v) # frozenset({1, 2, 3})
# 遍历
for i in v:
print(i)
# 冰冻集合的推导式
res = frozenset({i<<2 for i in range(6)})
print(res) # frozenset({0, 16, 4, 20, 8, 12})
# 冰冻集合可以和普通集合一样,进行集合的运算,交集...
res1 = res.copy()
print(res1) # frozenset({0, 16, 4, 20, 8, 12})
4.2 集合推导式
# (1) 普通推导式
varset = {1,2,3,4}
newset = {i<<1 for i in varset}
print(newset) # {8, 2, 4, 6}
# (2) 带有条件表达式的推导式
newset = {i<<1 for i in varset if i%2==0}
print(newset) # {8, 4}
# (3) 多循环的集合推导式
vars1 = {1,2,3}
vars2 = {4,5,6}
newset = set()
for i in vars1:
for j in vars2:
newset.add(i+j)
print(newset) # {5, 6, 7, 8, 9}
newset = {i+j for i in vars1 for j in vars2}
print(newset) # {5, 6, 7, 8, 9}
# (4) 带条件表达式的多循环的集合推导式
newset = {i+j for i in vars1 for j in vars2 if i%2==0 and j%2==0}
print(newset) # {8,6}
4.3 集合运算
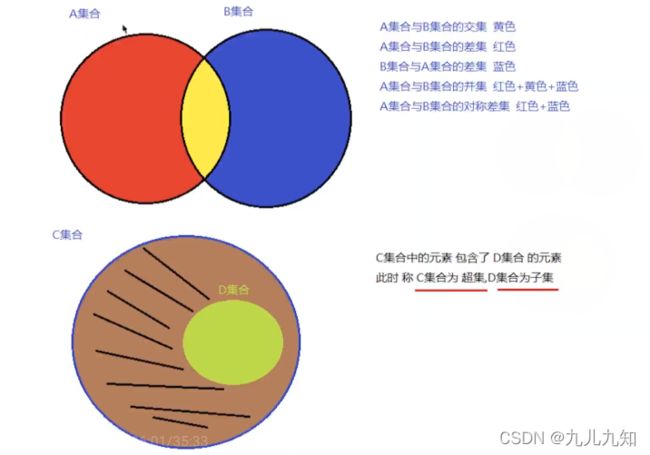
'''
集合的主要运算:
交集 & set.intersection() set.intersection_update()
并集 | union() update()
差集 - difference() difference_update()
对称差集 ^ symmetric_difference() symmetric_difference_update()
'''
vars1 = {'郭富城','刘德华','张学友','黎明','都敏俊'}
vars2 = {'赵四','刘能','小沈阳','宋小宝','都敏俊'}
- 交集
# 求集合的交集 &
res = vars1 & vars2
print(res) # {'都敏俊'}
# intersection() 返回交集集结果 --> 新的集合
res = vars1.intersection(vars2)
print(res) # {'都敏俊'}
# intersection_update() 把交集的结果,重新赋值给第一个集合
res = vars1.intersection_update(vars2)
print(res) # None
print(vars1) # {'都敏俊'}
- 并集
# 求集合的并集 | (集合中的所有元素,去重)
res = vars1 | vars2
print(res) # {'刘德华', '黎明', '郭富城', '刘能', '都敏俊', '宋小宝', '张学友', '赵四', '小沈阳'}
# 并集运算函数
# union()
res1 = vars1.union(vars2)
print(res1) # 返回并集结果 --> 新的集合
# {'刘德华', '小沈阳', '都敏俊', '赵四', '刘能', '郭富城', '张学友', '宋小宝', '黎明'}
# update()
res2 = vars1.update(vars2)
print(res2) # None
# 求并集运算,并且把结果赋值给第一个集合
print(vars1) # {'黎明', '小沈阳', '宋小宝', '刘能', '都敏俊', '张学友', '郭富城', '刘德华', '赵四'}
- 差集
# 求集合的差集 -
res1 = vars1 - vars2 # 1 有 2 没有
res2 = vars2 - vars1 # 1 有 2 没有
print(res1) # {'张学友', '郭富城', '刘德华', '黎明'}
print(res2) # {'赵四', '宋小宝', '小沈阳', '刘能'}
# 求差集的函数
# set.difference() 返回差集结果,新的集合
res = vars1.difference(vars2)
print(res) # {'黎明', '郭富城', '刘德华', '张学友'}
# set.difference_update() 把差集的结果,重新赋值给第一个集合
res = vars1.difference_update(vars2)
print(res) # None 无返回值
print(vars1) # {'张学友', '刘德华', '黎明', '郭富城'}
- 对称差集
# 求集合的对称差集 ^ (求不想交的部分)
res = vars1 ^ vars2
print(res) # {'黎明', '刘德华', '宋小宝', '郭富城', '刘能', '张学友', '赵四', '小沈阳'}
# symmetric_difference() 返回对称差集结果,新的集合
res = vars1.symmetric_difference(vars2)
print(res) # {'张学友', '刘德华', '刘能', '宋小宝', '黎明', '小沈阳', '赵四', '郭富城'}
# symmetric_difference_update() 把对称差集的结果,重新赋值给第一个集合
res = vars1.symmetric_difference_update(vars2)
print(res) # None
print(vars1) # {'张学友', '刘德华', '刘能', '宋小宝', '黎明', '小沈阳', '赵四', '郭富城'}
- 超集和子集
vars1 = {1,2,3,4,5,6,7,8,9}
vars2 = {1,2,3}
# 检测超集和子集
# issuperset() 检测是否为超集
res = vars1.issuperset(vars2)
print(res) # True vars1 是 vars2 的超集
# issubset() 检测是否为子集
res = vars2.issubset(vars1)
print(res) # True vars2 是 vars1 的子集
# 检测两个集合是否不相交,不相交返回True,相交返回False
vars3 = {5,6,7}
res = vars1.isdisjoint(vars2) # False
# res = vars2.isdisjoint(vars3) # True
print(res)