【学习笔记】尚硅谷大数据项目之Flink实时数仓---DWD和DIM
DWD和DIM
- 1. 需求分析及实现思路
-
- 1.1 分层需求分析
- 1.2 每层的职能
- 1.3 DWD 层数据准备实现思路
- 2. 环境搭建
- 3. 准备用户行为日志DWD层
-
- 3.1 主要任务
-
- 3.1.1 识别新老用户
- 3.1.2 利用侧输出流实现数据拆分
- 3.1.3 将不同流的数据推送下游的 Kafka 的不同 Topic 中
- 3.2 代码实现
-
- 3.2.1 接收 Kafka 数据,并进行转换
- 3.2.2 识别新老访客
- 3.2.3 利用侧输出流实现数据拆分
- 3.2.4 将不同流的数据推送到下游 kafka 的不同 Topic(分流)
- 3.3 总体代码实现
- 4. 准备业务数据DWD层
-
- 4.1 主要任务
-
- 4.1.1 接收 Kafka 数据,过滤空值数据
- 4.1.2 实现动态分流功能
- 4.1.3 把分好的流保存到对应表、主题中
- 4.2 代码实现
-
- 4.2.1 接收 Kafka 数据,过滤空值数据
- 4.2.2 根据 MySQL 的配置表,动态进行分流
- 4.2.3 分流 Sink 之保存维度到 HBase(Phoenix)
- 4.2.4 分流 Sink 之保存业务数据到 Kafka 主题
- 4.2.5 BaseDBApp
- 5. 总结
1. 需求分析及实现思路
1.1 分层需求分析
在之前介绍实时数仓概念时讨论过,建设实时数仓的目的,主要是增加数据计算的复用性。每次新增加统计需求时,不至于从原始数据进行计算,而是从半成品继续加工而成。
我们这里从 Kafka 的 ODS 层读取用户行为日志以及业务数据,并进行简单处理,写回到 Kafka 作为 DWD 层
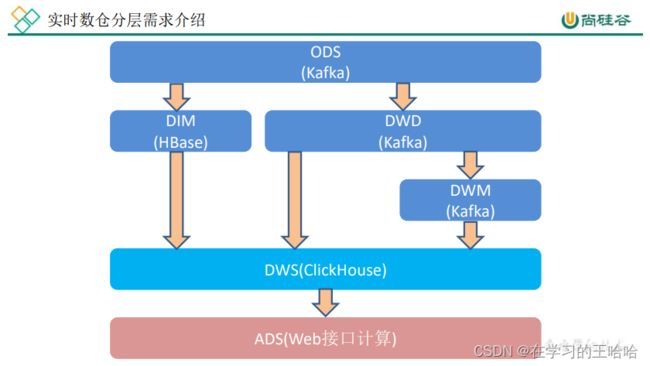
1.2 每层的职能

1.3 DWD 层数据准备实现思路
➢ 功能 1:环境搭建
➢ 功能 2:计算用户行为日志 DWD 层
➢ 功能 3:计算业务数据 DWD 层
2. 环境搭建
gmall2021-realtime
3. 准备用户行为日志DWD层
我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 Kafka 的ODS 层读取的日志数据分为 3 类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回 Kafka 不同主题中,作为日志 DWD 层。
页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光侧输出流
3.1 主要任务
3.1.1 识别新老用户
本身客户端业务有新老用户的标识,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。
3.1.2 利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为 3 类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流
3.1.3 将不同流的数据推送下游的 Kafka 的不同 Topic 中
dwd_page_log
dwd_start_log
dwd_display_log
3.2 代码实现
3.2.1 接收 Kafka 数据,并进行转换
- 在 Kafka 的工具类中提供获取 Kafka 消费者的方法(读)
package com.atguigu.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class MyKafaUtil {
private static String brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
public static FlinkKafkaProducer<String> getKafkaProducer(String topic){
return new FlinkKafkaProducer<String>(brokers
,topic
,new SimpleStringSchema() );
}
public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic , String groupId){
Properties properties = new Properties();
给配置信息对象添加配置项
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
//获取 KafkaSource
return new FlinkKafkaConsumer<String>(topic,
new SimpleStringSchema(),
properties);
}
}
- Flink 调用工具类读取数据的主程序
3.2.2 识别新老访客
保存每个 mid 的首次访问日期,每条进入该算子的访问记录,都会把 mid 对应的首次访问时间读取出来,只有首次访问时间不为空,则认为该访客是老访客,否则是新访客。
同时如果是新访客且没有访问记录的话,会写入首次访问时间。、
3.2.3 利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为 3 类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流
3.2.4 将不同流的数据推送到下游 kafka 的不同 Topic(分流)
- 程序中调用 Kafka 工具类获取 Sink
- 测试
➢ IDEA 中运行 BaseLogApp 类
➢ 运行 logger.sh,启动 Nginx 以及日志处理服务
➢ 运行 rt_applog 下模拟生成数据的 jar 包
➢ 到 Kafka 不同的主题下查看输出效果
3.3 总体代码实现
package com.atguigu.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.utils.MyKafaUtil;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
// 数据流:web/app --> Nginx --> SpringBoot --> Kafka(ods) -> FlinkApp -> Kafka(dwd)
// 程 序: mocklog -> Nginx --> Logger.sh --> Kafka(ZK) --> BaseLogApp -> Kafka
public class BaseLogApp {
public static void main(String[] args) throws Exception {
// TODO 1. 获取执行环境
// 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 设置checkpoint 和 状态后端
// 1.1 开启ck checkpoint 并且指定状态后端为 FS
//Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点
//续传,需要从 Checkpoint 或者 Savepoint 启动程序
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink/ck")); // 设置状态后端
// 开启 Checkpoint,每隔 5 秒钟做一次 CK
//env.enableCheckpointing(5000L);// 5秒钟触发一次checkpoint
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //指定 CK 的一致性语义
//nv.getCheckpointConfig().setCheckpointTimeout(10000L); // 10 秒的超时事件
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.failureRateRestart()); 新版本不用配
// TODO 2. 消费 ods_base_log 主题数据创建流
String sourceTopic = "ods_base_log";
String groupId = "base_log_app";
DataStreamSource<String> kafkaDS = env.addSource(MyKafaUtil.getKafkaConsumer(sourceTopic, groupId));
// TODO 3. 将每行数据转换为JSON对象
// kafkaDS.map(line -> {
// return JSON.parseObject(line);
// })
// kafkaDS.map(JSON::parseObject);
// 用process可以把数据保留下来, 把脏数据 输出到测输出流中
// 用到测输出流只能用到process
OutputTag<String> outputTag = new OutputTag<String>("Dirty") {
};
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String s, ProcessFunction<String, JSONObject>.Context context, Collector<JSONObject> collector) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(s);
collector.collect(jsonObject);
} catch (Exception e) {
// 发生异常 ,将数据写入测输出流
context.output(outputTag, s);
}
}
});
// 打印脏数据
jsonObjDS.getSideOutput(outputTag).print("Dirty>>>>>>>>>>");
// TODO 4. 新老用户校验 状态编程
SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlagDS = jsonObjDS.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid"))
.map(new RichMapFunction<JSONObject, JSONObject>() {
private ValueState<String> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<String>
("value-state", String.class));
}
@Override
public JSONObject map(JSONObject jsonObject) throws Exception {
// 获取数据中的“is_new"标记
String isNew = jsonObject.getJSONObject("common").getString("is_new");
// 判断isnew 标记是否为1
if ("1".equals(isNew)) {
// 获取状态数据
String state = valueState.value();
if (state != null) {
// 修改isNew标记
jsonObject.getJSONObject("common").put("is_new", "0");
} else {
valueState.update("1");
}
}
return jsonObject;
}
});
// TODO 5. 分流 测输出流 页面: 主流 启动: 测输出流 曝光:测输出流
OutputTag<String> startOutPutTag = new OutputTag<String>("start"){};
OutputTag<String> displayTag = new OutputTag<String>("display") {
};
SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlagDS.process(new ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject value, ProcessFunction<JSONObject, String>.Context context, Collector<String> collector) throws Exception {
// 获取启动日志字段
String start = value.getString("start");
if (start != null && start.length() > 0) {
// 将数据写入启动日志测输出流
context.output(startOutPutTag, value.toJSONString());
} else {
// 将数据写入页面日志
collector.collect(value.toJSONString());
// 取出数据中的曝光数据
JSONArray displays = value.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
// 获取页面id
String pageID = value.getJSONObject("page").getString("page_id");
for (int i = 0; i < displays.size(); i++) {
JSONObject display = displays.getJSONObject(i);
// 添加页面ID
display.put("page_id", pageID);
// 将数据写出到曝光的测输出流
context.output(displayTag, display.toJSONString());
}
}
}
}
});
// TODO 6. 提取测输出流
DataStream<String> startDS = pageDS.getSideOutput(startOutPutTag);
DataStream<String> displayDS = pageDS.getSideOutput(displayTag);
// TODO 7. 将三个流进行打印并输出到对应的Kafka主题中
startDS.print("start>>>>>>>>>");
pageDS.print("page>>>>>>>>>");
displayDS.print("display>>>>>>>>>");
startDS.addSink(MyKafaUtil.getKafkaProducer("dwd_start_log"));
pageDS.addSink(MyKafaUtil.getKafkaProducer("dwd_page_log"));
displayDS.addSink(MyKafaUtil.getKafkaProducer("dwd_display_log"));
// TODO 8. 启动任务
env.execute("BaseLogApp");
}
}
4. 准备业务数据DWD层
业务数据的变化,我们可以通过 FlinkCDC 采集到,但是 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从 Kafka 的业务数据 ODS 层读取数据,经过处理后,将维度数据保存到 HBase,将事实数据写回 Kafka 作为业务数据的 DWD 层。
4.1 主要任务
4.1.1 接收 Kafka 数据,过滤空值数据
对 FlinkCDC 抓取数据进行 ETL,有用的部分保留,没用的过滤掉
4.1.2 实现动态分流功能
由于 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这样显然不利于日后的数据处理。
所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
➢ 一种是用 Zookeeper 存储,通过 Watch 感知数据变化;
➢ 另一种是用 mysql 数据库存储,周期性的同步 select * ;
➢ 另一种是用 mysql 数据库存储,使用广播流。
这里选择第二种方案,主要是 MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
所以就有了如下图:

4.1.3 把分好的流保存到对应表、主题中
业务数据保存到 Kafka 的主题中
维度数据保存到 HBase 的表中
4.2 代码实现
4.2.1 接收 Kafka 数据,过滤空值数据
4.2.2 根据 MySQL 的配置表,动态进行分流
- 引入 pom.xml 依赖
- 在 Mysql 中创建数据库
- 在 gmall2021_realtime 库中创建配置表 table_process
- 在 MySQL 配置文件中增加 gmall2021_realtime 开启 Binlog
- 创建配置表实体类TableProcess
- 编写操作读取配置表形成广播流’
- 程序流程分析
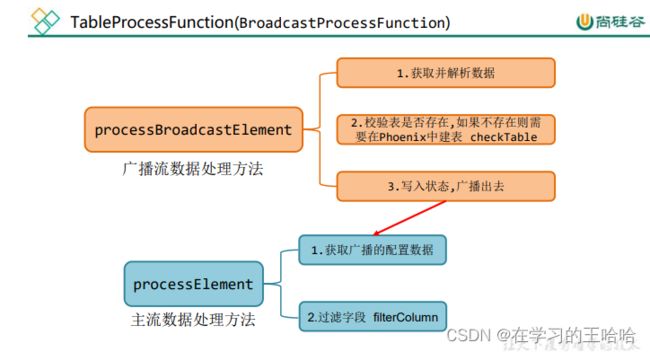
- 定义一个项目中常用的配置常量类 GmallConfig
- 自定义函数 TableProcessFunction
- 自定义函数 TableProcessFunction-open
- 自定义函数 TableProcessFunction-processBroadcastElement
- 自定义函数 TableProcessFunction-checkTable
- 自定义函数 TableProcessFunction-processElement()
核心处理方法,根据 MySQL 配置表的信息为每条数据打标签,走 Kafka 还是 HBase - 自定义函数 TableProcessFunction-filterColumn()
校验字段,过滤掉多余的字段 - 主程序 BaseDBApp 中调用 TableProcessFunction 进行分流
GmallConfig
package com.atguigu.common;
public class GmallConfig {
//Phoenix 库名
public static final String HBASE_SCHEMA = "GMALL2021_REALTIME";
//Phoenix 驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
//Phoenix 连接参数
public static final String PHOENIX_SERVER =
"jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
}
TableProcessFunction
package com.atguigu.app.function;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.bean.TableProcess;
import com.atguigu.common.GmallConfig;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.List;
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {
private Connection connection;
private OutputTag<JSONObject> objectOutputTag;
private MapStateDescriptor<String, TableProcess> mapStateDescriptor;
public TableProcessFunction(OutputTag<JSONObject> objectOutputTag, MapStateDescriptor<String, TableProcess> mapStateDescriptor) {
this.objectOutputTag = objectOutputTag;
this.mapStateDescriptor = mapStateDescriptor;
}
@Override
public void open(Configuration parameters) throws Exception {
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
// value: {"db":"","tn":"","before":{}, "after":{}, "type":""}
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<JSONObject, String, JSONObject>.Context context, Collector<JSONObject> collector) throws Exception {
// 1. 获取并解析数据
JSONObject jsonObject = JSON.parseObject(value);
String data = jsonObject.getString("after");
TableProcess tableProcess = JSON.parseObject(data, TableProcess.class);
// 2. 建表
if (TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())) {
checkTable(tableProcess.getSinkTable()
, tableProcess.getSinkColumns()
, tableProcess.getSinkPk()
, tableProcess.getSinkExtend());
}
// 3. 写入状态,广播出去
BroadcastState<String, TableProcess> broadcastState = context.getBroadcastState(mapStateDescriptor);
String key = tableProcess.getSourceTable() + "-" + tableProcess.getOperateType();
broadcastState.put(key, tableProcess);
}
// 建表语句: create table if noe exists ab.tn(id varchar primary key, tm_name varchar) XXX;
private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend) {
PreparedStatement preparedStatement = null;
try {
if (sinkPk == null) {
sinkPk = "id";
}
if (sinkExtend == null) {
sinkExtend = "";
}
StringBuilder create_table_sql = new StringBuilder("create table if not exists ")
.append(GmallConfig.HBASE_SCHEMA)
.append(".")
.append(sinkTable)
.append("(");
String[] fields = sinkColumns.split(",");
for (int i = 0; i < fields.length; i++) {
String field = fields[i];
// 判断是否为主键
if (sinkPk.equals(field)) {
create_table_sql.append(field).append(" varchar primary key");
} else {
create_table_sql.append(field).append(" varchar");
}
// 判断是否为最后一个字段, 如果不是,则添加“,”
if (i < fields.length - 1) {
create_table_sql.append(",");
}
}
create_table_sql.append(")").append(sinkExtend);
// 打印建表语句
System.out.println(create_table_sql);
// 预编译sql
preparedStatement=connection.prepareStatement(create_table_sql.toString());
// 执行
preparedStatement.execute();
} catch (SQLException e) {
throw new RuntimeException("Phoenix表" + sinkTable+ "建表失败");
}finally {
if(preparedStatement != null){
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
// value: {"db":"","tn":"","before":{}, "after":{}, "type":""}
@Override
public void processElement(JSONObject value, BroadcastProcessFunction<JSONObject, String, JSONObject>.ReadOnlyContext readOnlyContext, Collector<JSONObject> collector) throws Exception {
// 1. 获取状态数据
ReadOnlyBroadcastState<String, TableProcess> broadcastState = readOnlyContext.getBroadcastState(mapStateDescriptor);
String key = value.getString("tableName") + "-" + value.getString("type");
TableProcess tableProcess = broadcastState.get(key);
if (tableProcess != null) {
// 2. 过滤字段
JSONObject data = value.getJSONObject("after");
filterColumn(data, tableProcess.getSinkColumns());
// 3. 分流
// 将输出表/主题信息写入Value
value.put("sinkTable", tableProcess.getSinkTable());
String sinkType = tableProcess.getSinkType();
if (TableProcess.SINK_TYPE_KAFKA.equals(sinkType)) {
// kafka数组写入主流
collector.collect(value);
} else if (TableProcess.SINK_TYPE_HBASE.equals(sinkType)) {
// Hbase写入测输出流
readOnlyContext.output(objectOutputTag, value);
}
} else {
System.out.println("该组合key" + key + "不存在!");
}
}
/**
* data {"id":"11","tm_name":"atguigu","logo_url":"aaa}
* sinkSinkColumns id, tm_name
* {"id":"11","tm_name":"atguigu"}
*/
private void filterColumn(JSONObject data, String sinkColumns) {
String[] fleids = sinkColumns.split(",");
// 数组变成集合
List<String> columns = Arrays.asList(fleids);
// Iterator> iterator = data.entrySet().iterator();
// while (iterator.hasNext()){
// Map.Entry next = iterator.next();
// if(!columns.contains(next.getKey())){
// iterator.remove();
// }
// }
data.entrySet().removeIf(next -> !columns.contains(next.getKey()));
}
}
4.2.3 分流 Sink 之保存维度到 HBase(Phoenix)
- 程序流程分析
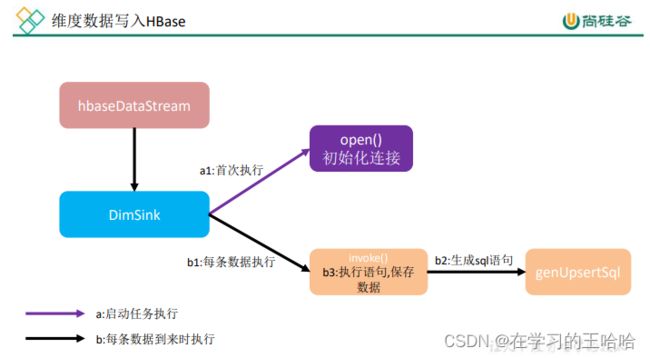
- 因为要用单独的 schema,所以在程序中加入 hbase-site.xml
注意:为了开启 hbase 的 namespace 和 phoenix 的 schema 的映射,在程序中需要加这
个配置文件,另外在 linux 服务上,也需要在 hbase 以及 phoenix 的 hbase-site.xml 配置
文件中,加上以上两个配置,并使用 xsync 进行同步。 - 在 phoenix 中执行
create schema GMALL2021_REALTIME;
- DimSink
package com.atguigu.app.function;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.common.GmallConfig;
import org.apache.commons.lang.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Collection;
import java.util.Set;
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
// 加载驱动
Class.forName(GmallConfig.PHOENIX_DRIVER);
// 重新赋值
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
connection.setAutoCommit(true);
}
// value: {"sinkTable":"dwd_order_info",
// "database":"gmall-flink",
// "before":{},
// "after":{"user_id":2021,"id":26450},
// "type":"insert",
// "tableName":"order_info"}
// SQL: upsert into db.tn(id,tm_name) values(..,...)
@Override
public void invoke(JSONObject value, Context context) throws Exception {
PreparedStatement preparedStatement = null;
try {
// 获取sql语句
String upsertSql = genUpsertSql(value.getString("sinkTable"),
value.getJSONObject("after"));
System.out.println(upsertSql);
// 预编译sql
preparedStatement = connection.prepareStatement(upsertSql);
// 执行插入操作
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(preparedStatement != null){
preparedStatement.close();
}
}
}
// data: "after":{"user_id":2021,"id":26450},
// SQL: upsert into db.tn(id,tm_name) values('..','...')
private String genUpsertSql(String sinkTable, JSONObject data) {
Set<String> keySet = data.keySet();
Collection<Object> values = data.values();
return "upsert into " + GmallConfig.HBASE_SCHEMA+"."+sinkTable+"("+
StringUtils.join(keySet,",")+")values('"+
StringUtils.join(values,"','")+"')";
}
}
- 测试

4.2.4 分流 Sink 之保存业务数据到 Kafka 主题
- 在 MyKafkaUtil 中添加如下方法
private static String brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
private static String default_topic = "default";
public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema){
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaProducer<T>(default_topic,
kafkaSerializationSchema
, properties
, FlinkKafkaProducer.Semantic.NONE );
}
-
在 MyKafkaUtil 中添加属性定义
-
两个创建 FlinkKafkaProducer 方法对比
➢ 前者给定确定的 Topic
➢ 而后者除了缺省情况下会采用 DEFAULT_TOPIC,一般情况下可以根据不同的业务
数据在 KafkaSerializationSchema 中通过方法实现。 -
在主程序 BaseDBApp 中加入新 KafkaSink
-
测试

4.2.5 BaseDBApp
BaseDBApp
package com.atguigu.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.atguigu.app.function.CustomerDeserialization;
import com.atguigu.app.function.DimSinkFunction;
import com.atguigu.app.function.TableProcessFunction;
import com.atguigu.bean.TableProcess;
import com.atguigu.utils.MyKafaUtil;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.flink.util.OutputTag;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
// 数据流 : web/app -- nginx -- springboot -- mysql -- flinkapp -- kafka(ods) -- flinkapp -- kafka(dwd)/phoenix(dim)
// 程序: mockDB -- Mysql -- FlinkCDC -- kafka -- BaseDBApp -- -> Kafka/Phoenix(hbase,zk,hdfs)
public class BaseDBApp {
public static void main(String[] args) throws Exception {
// TODO 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/dwd_log/ck"));
//1.2 开启 CK
//env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(60000L);
// TODO 2. 消费Kafka ods_base_db 主题数据创建流
String sourceTopic = "ods_base_db";
String groupID = "BaseDBApp";
DataStreamSource<String> kafkaDS = env.addSource(MyKafaUtil.getKafkaConsumer(sourceTopic, groupID));
// TODO 3. 将每行数据转换为JSON对象并过滤(delete) 主流
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject)
.filter(new FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
// 取出数据的操作类型
String type = value.getString("type");
return !"delete".equals(type);
}
});
// TODO 4. 使用FlinkCDC消费配置表并处理成 广播流
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-realtime")
.tableList("gmall-realtime.table_process")
// 应该有哪些字段:表名,操作类型(为了区分新增及变化数据), 输出类型(hbase,kafka),sinkTable, sinkColumns, pk,
// sourceTable type sinkType sinkTable
// base_trademark insert hbase dim_xxxx(Phnoeix表名)
// order_info insert kafka dwd_xxxx(主题名)
// 需要一个主键来查到信息 表名+操作类型 作为联合主键
// Phnoeix表需要自动创建, 还需要以下字段 sinkColumns 字段,pk 主键, extend 额外信息
.startupOptions(StartupOptions.initial())
.deserializer(new CustomerDeserialization())
.build();
DataStreamSource<String> tableProcessStrDS = env.addSource(sourceFunction);
// 主流根据 表名+操作类型 可以获取到相关信息 tableprocess 拿到一行数据
MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("map-state",
String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = tableProcessStrDS.broadcast(mapStateDescriptor);
// TODO 5. 连接主流和广播流
BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);
// TODO 6. 分流 处理数据 广播流数据,主流数据(根据广播流数据进行处理)
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>("hbase-tag") {
};
SingleOutputStreamOperator<JSONObject> kafka = connectedStream.process(new TableProcessFunction(
hbaseTag,mapStateDescriptor));
// TODO 7. 提取Kafka流数据和Hbase数据
DataStream<JSONObject> hbase = kafka.getSideOutput(hbaseTag);
// TODO 8. 将Kafka数据写入Kafka主题, 将Hbase数据写入Phoenix表中
kafka.print("kafka>>>>>>>>>>>");
hbase.print("Hbase>>>>>>>>>>>");
hbase.addSink(new DimSinkFunction());
kafka.addSink(MyKafaUtil.getKafkaProducer(new KafkaSerializationSchema<JSONObject>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
return new ProducerRecord<byte[], byte[]>(jsonObject.getString("sinkTable"),
jsonObject.getString("after").getBytes());
}
}));
// TODO 9. 启动任务
env.execute("BaseDBApp");
}
}
5. 总结
DWD 的实时计算核心就是数据分流,其次是状态识别。在开发过程中我们实践了几个灵活度较强算子,比如 RichMapFunction, ProcessFunction, RichSinkFunction。 那这几个我们什么时候会用到呢?如何选择?
