python爬取腾讯新闻统计数据——新型冠状病毒引发肺炎实况(selenium实现)
我和大家都一样都被关在家里处于癫疯的边缘,闲来无事就爬这个网站来关注我们祖国的病情怎么样了。
起先网站一直在改版,对于这种定向爬虫来说,spider只能在这张网上行动觅食,如果这张网改变了那么我的“蜘蛛”必须得改变了,没办法这是个因果关系,因为这样所以必须这样了。
一、分析网页
明确了任务后,对网页进行简单分析。分析之后,首先本想直接requests请求网页源代码,response回来的没有数据,失败;然后打开开发者工具试图找出“藏匿”有数据的链接地址,直接requests这个数据源或许能成功,试着...失败;最后逼得我放大招,使用selenium自动化测试工具,虽然效率低一点,但是对于这种小剂量的抽取数据还是莫问题滴,随后直接写一部分看是否能得到自己想要的数据,一试即可,欧了。
二、上代码测试
按部就班的有条不理的把代码写完,一运行得到部分数据。这样残缺的数据拿来有何用,查问题,发现只将可视的数据获取下来了,上解决办法:给点儿动作让网页动起来(from selenium.webdriver.common.action_chains import ActionChains)点击藏有数据元素,让它无处藏匿。最终成功。
三、定时可控制
定个时让程序每天抓数据,连续性才能分析出看出点儿东西,所以定个时每天爬一下。
def main():#定时函数
h=8#可改时间小时
m=0#可改时间分钟,秒就算了,没必要要这么精确的时间
while True:
now = datetime.datetime.now()
if now.hour==h and now.minute == m:
feiyan_spider()
time.sleep(60)
四、完整代码
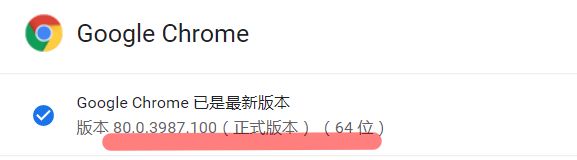
以下代码是在环境配置好的情况下才能运行。最主要的是chrome的版本(80.0.3987.xxx)和webdriver的版本(这个网址里有chrome对应的驱动版本https://chromedriver.storage.googleapis.com/index.html)是相匹配的。
![]()
 (我现在用的chrome版本是80.0.3987.100,80.0.3987.xxx的webdriver就可以驱动浏览器运行。)
(我现在用的chrome版本是80.0.3987.100,80.0.3987.xxx的webdriver就可以驱动浏览器运行。)
#utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import re
import time
import datetime
import csv
# 设置谷歌驱动器的环境
options = webdriver.ChromeOptions()
# 设置chrome不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(options=options,executable_path='D:\Python37\Scripts\chromedriver.exe')#executable_path是驱动器chromedriver的路径
browser.minimize_window()#最小化窗口,方便输入要检索的页数和关键词
url="https://news.qq.com//zt2020/page/feiyan.htm"
def feiyan_spider():
now = datetime.datetime.now()
browser.get(url)
# WebDriverWait(browser, 1000)
time.sleep(10)
# response = browser.page_source#获取源码
# //*[@id="charts"]/div[6]/div[38]
with open('D:\Python_DATA/'+str(now.date())+'.csv', 'a', encoding='utf-8', newline='') as csvfile:#'改为你的路径'+str(now.date())+'.csv'
writer = csv.writer(csvfile)
xpath1='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[1]/div[2]'#累计确诊#
xpath2='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[2]/div[2]'#累积治愈
xpath3='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[3]/div[2]'#累计死亡
xpath4='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[4]/div[2]'#现有确诊
xpath5='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[5]/div[2]'#现有疑似
xpath6='//*[@id="app"]/div[2]/div[2]/div[1]/div[2]/div[6]/div[2]'#现有重症
icbar_now_confirm=browser.find_element_by_xpath(xpath1)
icba_confirm=browser.find_element_by_xpath(xpath2)
icbar_suspect=browser.find_element_by_xpath(xpath3)
icba_server=browser.find_element_by_xpath(xpath4)
icbar_cure=browser.find_element_by_xpath(xpath5)
icbar_dead=browser.find_element_by_xpath(xpath6)
writer.writerow(("累计确诊", "累计治愈","累计死亡", "现有确诊","现有疑似", "现有重症"))
print(icbar_now_confirm.text,icba_confirm.text, icbar_suspect.text, icba_server.text,icbar_cure.text, icbar_dead.text)
writer.writerow((icbar_now_confirm.text,icba_confirm.text, icbar_suspect.text, icba_server.text,icbar_cure.text, icbar_dead.text))
writer.writerow(("城市", "新增确诊","累积确诊","治愈", "死亡"))
for i in range(1,35):#有没有新增地区的控制区间
path='//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr[1]/th/span'
select=browser.find_element_by_xpath(path)
ActionChains(browser).click(select).perform()
for i in range(1,35):
j = 1
while True:
xpath_name = '//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr['+str(j)+']/th/span'
xpath_ac_add ='//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr['+str(j)+']/td[1]'
xpath_confirm ='//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr['+str(j)+']/td[2]'
xpath_heal ='//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr['+str(j)+']/td[3]'
xpath_dead ='//*[@id="listWraper"]/table[2]/tbody['+str(i)+']/tr['+str(j)+']/td[4]'
try:
name = browser.find_element_by_xpath(xpath_name)
ac_add = browser.find_element_by_xpath(xpath_ac_add)
confirm = browser.find_element_by_xpath(xpath_confirm)
heal = browser.find_element_by_xpath(xpath_heal)
dead = browser.find_element_by_xpath(xpath_dead)
with open('D:\Python_DATA/' + str(now.date()) + '.csv', 'a', encoding='utf-8',newline='') as csvfile: # '改为你的路径'+str(now.date())+'.csv'
writer = csv.writer(csvfile)
writer.writerow((name.text,ac_add.text,confirm.text,heal.text,dead.text))
print(name.text,ac_add.text,confirm.text,heal.text,dead.text)
j+=1
except Exception as error:
print(error)
break
# while True:
# xpath='//*[@id="listWraper"]/table[2]/tbody[1]/tr[21]/th/span'
# name = browser.find_elements_by_xpath(xpath)
# num=len(name)
# if num==0:
# break
# print(name[0].text)
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[1]/th/span
#//*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/th/span
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[3]/th/span
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[4]/th/span
# ......
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[18]/th/span
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[19]/th/span
'''
for i in range(1,35):
xpath='//*[@id="charts"]/div[5]/div[7]/div['+str(i)+']/div/'
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/th/span/text()
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/td[1]/text()
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/td[2]/text()
# //*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/td[3]/text()
#//*[@id="listWraper"]/table[2]/tbody[1]/tr[2]/td[4]/text()
# //*[@id="listWraper"]/table[2]/tbody[2]/tr[1]/th/span/text()
xpath_name=xpath+'h2'
xpath_ac_add = xpath + 'div[1]'
xpath_confirm=xpath+'div[2]'
xpath_heal=xpath+'div[3]'
xpath_dead=xpath+'div[4]'
name=browser.find_elements_by_xpath(xpath_name)
ac_add=browser.find_elements_by_xpath(xpath_ac_add)
confirm=browser.find_elements_by_xpath(xpath_confirm)
heal=browser.find_elements_by_xpath(xpath_heal)
dead=browser.find_elements_by_xpath(xpath_dead)
print(len(name))
# print(type(name))
with open('D:\Python_DATA/'+str(now.date())+'.csv', 'a', encoding='utf-8', newline='') as csvfile:#'改为你的路径'+str(now.date())+'.csv'
writer = csv.writer(csvfile)
for i in range(len(name)):
# heal_ = re.sub(',', "", heal[i].text)
# dead_ = re.sub(',',"",dead[i].text)
# print(name[i].text)
# print(ac_add[i])
writer.writerow((name[i].text, ac_add[i].text,confirm[i].text,heal[i].text,dead[i].text))
print(name[i].text,ac_add[i].text,confirm[i].text, heal[i].text, dead[i].text)
'''
def main():
h=8
m=0
while True:
now = datetime.datetime.now()
if now.hour==h and now.minute == m:
feiyan_spider()
time.sleep(60)
if __name__=="__main__":
# main()
feiyan_spider()#任何时间都可以运行
browser.close()
五、部分数据
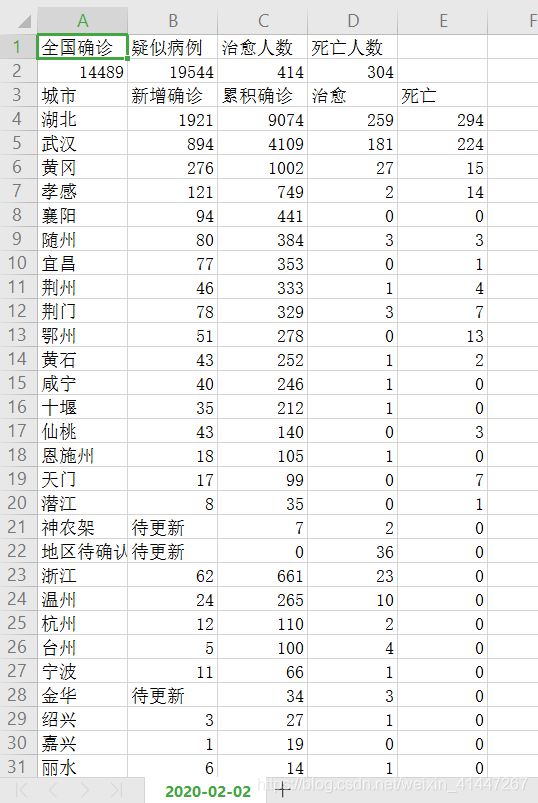
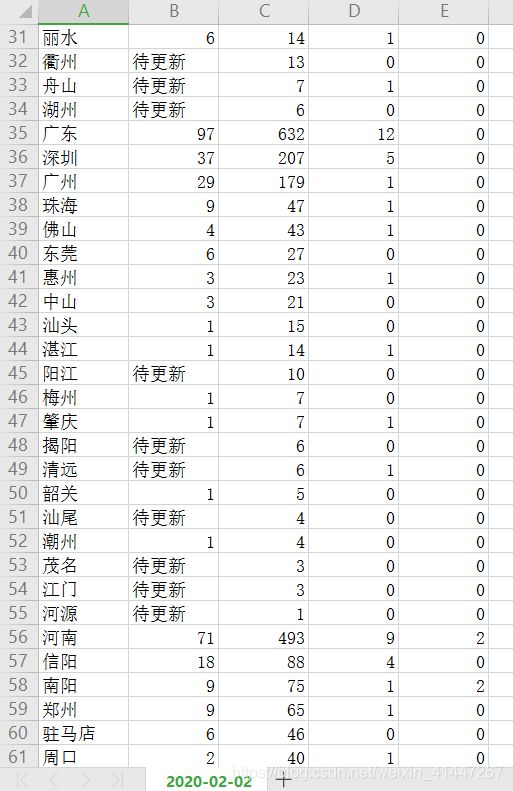
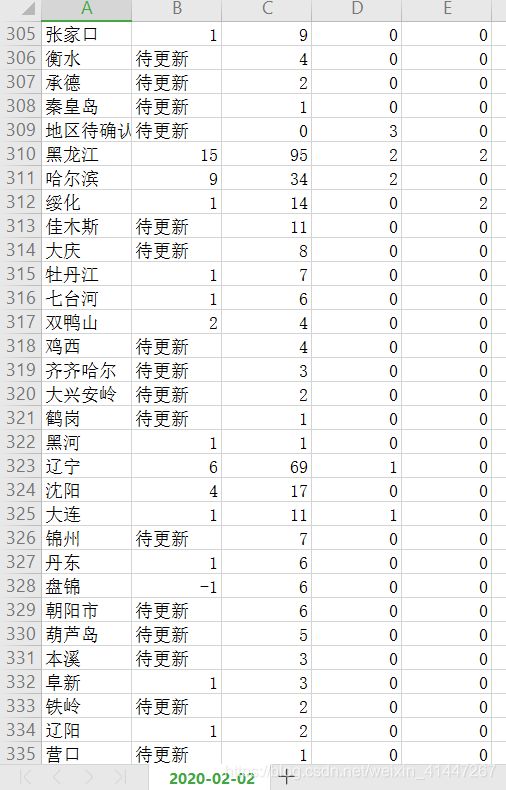
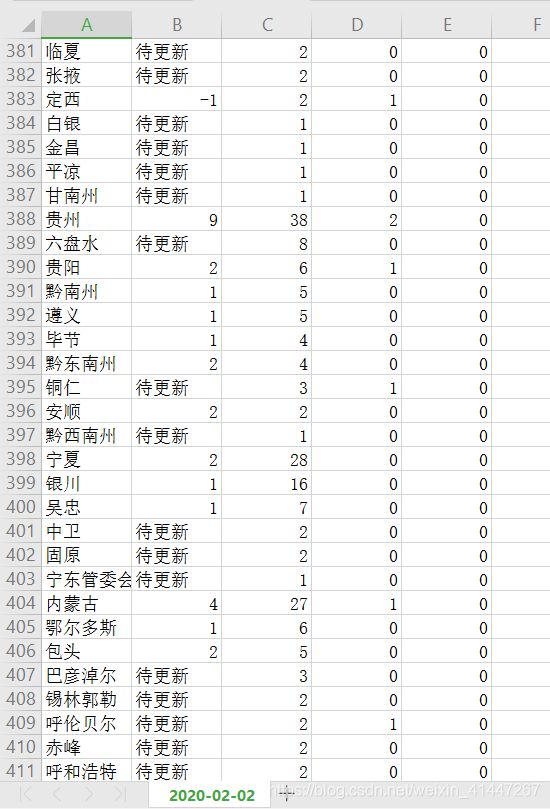
数据保存为csv格式方便对数据进行操作。
六、总结
这个网站写完后一直不稳定,网站中大大小小的一直在改变,所以这必将影响到我的爬虫的生命力。到最近网站的是相较稳定过后我才写下这篇文章。直到现在网站的有一处div标签对儿的位置还在时不时的改变,但是它的改变不会影响spider的全身瘫痪,只需对代码修改一处即可。所以说现在网站才相较以前较稳定。
************************************************************************************************************************************************
新冠肺炎预防须知
个人清洁
- 经常保持双手清洁,尤其在触摸口、鼻或眼之前。
- 经常用洗手液和清水清洗双手,搓手最少20秒,并用纸巾擦干。
- 打喷嚏或咳嗽时应用纸巾掩盖口鼻,把用过的纸巾弃置于有盖垃圾箱内,然后彻底清洁双手。
尽量避免
- 减少前往人流密集的场所。如不可避免,应戴上外科口罩。
- 避免到访医院。如有必要到访医院,应佩戴外科口罩及时刻注重个人和手部卫生。
- 避免接触动物(包括野味)、禽鸟或其粪便;避免到海鲜、活禽市场或农场。
- 切勿进食野味及切勿光顾有提供野味的餐馆。
- 注意食物安全和卫生,避免进食或饮用生或未熟透的动物产品,包括奶类、蛋类和肉类。
尽快就诊
- 如有身体不适,特别是有发烧或咳嗽,应戴上外科口罩并尽快就诊。
*************************************************************************************************************************************************

作者:诚长ing
2020.02.13