一篇搞定,Kettle详细教程
文章目录
-
-
- 第一章 Kettle概述
-
- 1.1 Kettle发展历程
- 1.2 Kettle简介
- 1.3 Kettle相关俗语
- 1.4 Kettle设计与组成
- 1.5 Kettle功能模块
- 1.6 Kettle的执行
- Transformation(转换)
- 1.7 Kettle商业和社区版区别
- 1.8 数据集成与ETL
- 1.9 ETL工具比较
- 第二章 Kettle安装部署
-
- 2.1 Window部署Kettle
- 2.2 Mac M1部署Kettle
- 2.3 Linux安装部署
- 2.4 Kettle的界面介绍
- 2.5 Kettle的快速体验
-
- 2.5.1 CSV2Excel
- 2.5.2 插入更新
- 2.5.3 作业执行
- 2.6 Kettle集群部署
-
- 2.6.1 集群部署介绍
- 2.6.2 集群部署
- 2.6.3 集群应用
- 第三章 Kettle操作
-
- 3.1 数据输入
-
- 3.1.1 生成记录
- 3.1.2 生成随机数
- 3.1.3 自定义常量数据
- 3.1.4 获取系统信息
- 3.1.5 文本输入
- 3.1.6 CSV文件输入
- 3.1.7 Excel输入
- 3.1.8 XML输入
- 3.1.8 Json输入
- 3.1.9 表输入
- 3.2 数据转换
-
- 3.2.1 增加常量-序列-字段选择组件
- 3.2.2 常见转换一
- 3.2.3 计算器-数值范围-设置字段值范围
- 2.3.4 列拆分为多行
- 2.3.5 行转列-列转行-扁平化
- 3.3 数据输出
-
- 3.3.1 文件类型输出
- 3.3.2 表类型输出
- 第四章 Kettle高阶操作
-
- 4.1 批量加载
-
- 4.1.1 MySQL批量加载
- 4.1.2 表输出批量加载
- 4.2 Kettle流程
-
- 4.2.1 Switch/case流程
- 4.2.2 过滤记录
- 4.2.3 检测空流-空操作-终止
- 3.2.4 阻塞数据直到步骤都完成
- 4.3 Kettle脚本控件
-
- 4.3.1 执行SQL脚本
- 4.3.2 Java代码介绍
- 4.3.3 Java代码案例一
- 4.3.4 Java代码写Kafka
- 4.4 Kettle查询控件
-
- 4.4.1 HTTP client 和 REST client
- 4.4.2 数据库查询和数据库连接
- 4.4.3 流查询
- 4.5 Kettle连接控件
-
- 4.5.1 多路合并Join
- 4.5.2 合并记录
- 4.5.3 记录集连接
- 4.6 Kettle检验控件
- 4.7 Kettle统计控件
- 4.8 Ketlle映射控件
- 4.9 Kettle应用
- 4.11 Kettle整合大数据
-
- 4.11.1 Kettle整合大数据数据介绍
- 4.11.2 Kettle整合Hadoop与Hive
- 4.12 Kettle Streaming
- 4.13 Kettle作业
- 4.14 Kettle调度
-
- 4.14.1 Start任务调度
- 4.14.2 Crontab定时调度
- 4.15 资源库
-
- 4.15.1 资源库介绍
- 4.15.2 数据资源库
- 4.15.3 文件资源库
- 4.16 Kettle变量与参数
-
- 4.16.1 变量介绍
- 4.16.2 系统变量的定义及应用
- 4.16.3 自定义变量
- 4.16.4 环境变量定义
- 4.16.5 参数介绍
- 4.16.6 位置参数设置及应用
- 4.16.7 命名参数设置和应用
- 4.17 Kettle规范及优化
-
- 4.17.1 Kettle规范
- 4.17.2 Kettle优化
-
第一章 Kettle概述
1.1 Kettle发展历程
Kettle 是 PDI 以前的名称,PDI 的全称是Pentaho Data Integeration-Pentaho数据集成,Kettle 本意是水壶的意思,表达了数据流的含义。
在 2003 年,Kettle 的主作者 Matt就开始了这个项目,在 PDI 的代码里就可以看到最早的日期大概在2003年4月。 从版本2.2开始, Kettle 项目进入了开源领域,并遵守 LGPL 协议。
在 2006年 ,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师。从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle 正式被命名为PDI,加入Pentaho 后Kettle 的发展越来越快了,并有越来越多的人开始关注它了。
在2015年,Pentaho公司被Hitachi Data Systems收购。
在2017年,Hitachi Data Systems更名为Hitachi Vantara,官网地址为:https://www.hitachivantara.com
历史主要版本记录如下:
| 时间 | 主版本号 | 主要变化 |
|---|---|---|
| 2006年4月 | Ketlle 2.2 | Kettle从该版本开始开源 |
| 2006年6月 | PDI 2.3 | Kettle被Pentaho收购后第一个版本 |
| 2007年11月 | PDI 3.0 | 产品整体重新设计,性能提升 |
| 2009年4月 | PDI 3.2 | 加入新功能、可视化与性能优化 |
| 2010年6月 | PDI 4.0 | 加入企业级功能,例如:版本管理 |
| 2013年11月 | PDI 5.0 | 优化大数据支持、转换步骤负载均衡、作业事务性支持、作业断点重启 |
| 2015年12月 | PDI 6.0 | Pentaho Data Service,元数据注入(Metadata Injection),数据血缘追踪 |
| 2016年11月 | PDI 7.0 | 数据管道可视化、Hadoop安全性支持、Spark支持优化、资源库功能完善、元数据注入功能优化 |
| 2017年4月 | PDI 7.1 | 任务下压至Spark集群运行(Adaptive Execution Layer) |
| 2017年11月 | PDI 8.0 | 实时数据对接、AEL优化、大数据格式支持优化 |
| 2018年6月 | PDI 8.3 | 数据源支持优化:Snowflake, RedShift, Kinesis, HCP等 |
| 2020年1月 | PDI 9.0 | 多Hadoop集群支持、大型机(Mainframe)数据对接支持、S3支持优化 |
| 2020年10月 | PDI 9.1 | Google Dataproc支持、数据目录Lumada Data Catalog对接 |
| 2022年5月 | PDI 9.3 | 支持多种云 |
1.2 Kettle简介
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,其中transformation完成针对数据的基础转换,job则完成整个工作流的控制。
1.3 Kettle相关俗语
Job:一个作业,由不同逻辑功能的entry组件构成,数据从一个entry组件传递到另一个entry组件,并在entry组件中进行相应的处理。Transformation:完成针对数据的基础转换,即一个数据转换过程。Entry:实体,即job型组件。用来完成特定功能应用,是job的组成单元、执行单元。Step:步骤,是Transformation的功能单元,用来完成整个转换过程的一个特定步骤。Hop:工作流或转换过程的流向指示,从一个组件指向另一个组件,在kettle源工程中有三种hop,无条件流向、判断为真时流向、判断为假时流向。数据类型:一行数据是零到多个类型的数据组成,具体Ketlle支持的数据类型如下:
①String字符型
②Number双精度浮点数
③Integer带符号整型64
④BigNumber任意精度数据
⑤Date带毫秒精度的日期时间值
⑥Boolean布尔值true false
⑦Binary二进制数据
1.4 Kettle设计与组成
PDI平台是整个Kettle系统的核心,包括插件管理引擎、元数据管理引擎、数据集成引擎和UI模块。
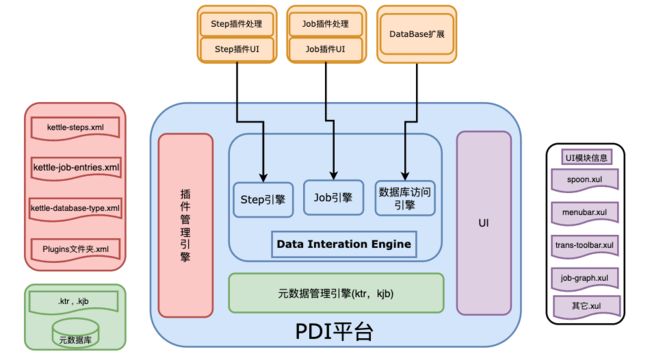
-
插件管理引擎
Kettle是众多“可供插入的地方”(扩展点)和“可以插入的东西”(扩展)共同组成的集合体。在我们的生活中,电源接线板就是一种“扩展点”,很多“扩展”(也就是电线插头)可以插在它上面。
插件管理引擎主要负责插件的注册,在Kettle中不管是以后的扩展还是系统集成的功能,本质上来讲都是插件,管理方式和运行机制是一致的。系统集成的功能点也均实现了对应的扩展接口,只是在插接的说明上略有不同。
Kettle的扩展点包括step插件、job entry插件、Database插件、Partioner插件和debugging插件等。 -
元数据管理引擎
元数据管理引擎管理ktr、kjb或者元数据库,插件通过该引擎获取基本信息,主要包括TransMeta、JobMeta和StepMeta三个类。
- TransMeta类,定义了一个转换(对应一个.ktr文件),提供了保存和加载该文件的方法;
- JobMeta类,同样对应于一个工作(对应一个.kjb文件),提供保存和加载方法;
- StepMeta类,保存的是Step的一些公共信息的类,每个类的具体的元数据将保存在显示了StepMetaInterface的类里面。
-
数据集成引擎
数据集成引擎包括Step引擎、Job引擎和数据库访问引擎三大部分,主要负责调用插件,并返回相应信息。
-
UI模块
UI显示Spoon这个核心组件的界面,通过xul实现菜单栏、工具栏的定制化,显示插件界面接口元素,其中的TransGraph类和JobGraph类是用于显示转换和Job的类。
1.5 Kettle功能模块
Kettle的功能模块很多,其核心主要有:Pan、Spoon、Kitchen和Chef等。

-
Spoon—转换过程设计器
GUI工作,用来设计数据转换过程,创建的转换可以由Pan来执行,也可以被Chef所包含,作为作业中的一个作业项。
- Input-Steps:输入步骤
- Text file input:文本文件输入
可以支持多文件合并,有不少参数,基本一看参数名就能明白其意图。 - Table input:数据表输入
实际上是视图方式输入,因为输入的是sql语句。当然,需要指定数据源(数据源的定制方式在后面讲一下) - Get system info:取系统信息
就是取一些固定的系统环境值,如本月最后一天的时间,本机的IP地址之类。 - Generate Rows:生成多行。
这个需要匹配使用,主要用于生成多行的数据输入,比如配合Add sequence可以生成一个指定序号的数据列。 - XBase Input
- Excel Input
- XML Input
- Text file input:文本文件输入
- Output-Steps: 输出步聚
- Text file output:文本文件输出。这个用来作测试蛮好,呵呵。很方便的看到转换的输出。
- Table output:输出到目的表。
- Insert/Update:目的表和输入数据行进行比较,然后有选择的执行增加,更新操作。
- Update:同上,只是不支持增加操作。
- XML Output:XML输出。
- Look-up:查找操作
- Data Base
- Stream
- Procedure
- Database join
- Transform 转换
- Select values
对输入的行记录数据的字段进行更改 (更改数据类型,更改字段名或删除) 数据类型变更时,数据的转换有固定规则,可简单定制参数。可用来进行数据表的改装。 - Filter rows
对输入的行记录进行指定复杂条件的过滤。用途可扩充sql语句现有的过滤功能。但现有提供逻辑功能超出标准sql的不多。
- Select values
- Sort rows
对指定的列以升序或降序排序,当排序的行数超过5000时需要临时表。 - Add sequence
为数据流增加一个序列,这个配合其它Step(Generate rows, rows join),可以生成序列表,如日期维度表(年、月、日)。 - Dummy
不做任何处理,主要用来作为分支节点。 - Join Rows
对所有输入流做笛卡儿乘积。 - Aggregate
聚合,分组处理 - Group by
分组,用途可扩充sql语句现有的分组,聚合函数。但我想可能会有其它方式的sql语句能实现。 - Java Script value
使用mozilla的rhino作为脚本语言,并提供了很多函数,用户可以在脚本中使用这些函数。 - Row Normaliser
该步骤可以从透视表中还原数据到事实表,通过指定维度字段及其分类值,度量字段,最终还原出事实表数据。 - Unique rows
去掉输入流中的重复行,在使用该节点前要先排序,否则只能删除连续的重复行。 - Calculator
提供了一组函数对列值进行运算,用该方式比用户自定义JAVA SCRIPT脚本速度更快。 - Merge Rows
用于比较两组输入数据,一般用于更新后的数据重新导入到数据仓库中。 - Add constants:
增加常量值。 - Row denormaliser
同Normaliser过程相反。 - Row flattener
表扁平化处理,指定需处理的字段和扃平化后的新字段,将其它字段做为组合Key进行扃平化处理。
除了上述基本节点类型外还定义了扩展节点类型 - SPLIT FIELDS:按指定分隔符拆分字段;
- EXECUTE SQL SCRIPT:执行SQL语句;
- CUBE INPUT:CUBE输入;
- CUBE OUTPUT:CUBE输出。
- Input-Steps:输入步骤
-
Pan—转换的执行工具
命令行执行方式,可以执行由Spoon生成的转换任务,不支持调度。
-
Chef—工作(job)设计器
这是一个GUI工具,操作方式主要通过拖拽。
何谓工作?多个作业项,按特定的工作流串联起来,形成一项工作。正如:我的工作是软件开发。我的作业项是:设计、编码、测试!先设计,如果成功,则编码,否则继续设计,编码完成则开始设计,周而复始,作业完成。-
Chef中的作业项
- 转换:指定更细的转换任务,通过Spoon生成,通过Field来输入参数;
- SQL:sql语句执行;
- FTP:下载ftp文件;
- 邮件:发送邮件;
- 检查表是否存在;
- 检查文件是否存在;
- 执行shell脚本:如dos命令。
- 批处理:(注意:windows批处理不能有输出到控制台)。
- Job包:作为嵌套作业使用。
- JavaScript执行:如果有自已的Script引擎,可以很方便的替换成自定义Script,来扩充其功能;
- SFTP:安全的Ftp协议传输;
- HTTP方式的上传/下载。
-
工作流
工作流是作业项的连接方式,分为三种:无条件,成功,失败。
为了方便工作流使用,KETTLE提供了几个辅助结点单元(也可将其作为简单的作业项):
- Start单元:任务必须由此开始。设计作业时,以此为起点。
- OK单元:可以编制做为中间任务单元,且进行脚本编制,用来控制流程。
- ERROR单元:用途同上。
- DUMMY单元:什么都不做,主要是用来支持多分支的情况。
-
存储方式
支持XML存储,或存储到指定数据库中。
一些默认的配置(如数据库存储位置……),在系统的用户目录下,单独建立了一个.Kettle目录,用来保存用户的这些设置。 -
LogView
可查看执行日志。
-
-
Kitchen—作业执行器
是一个作业执行引擎,用来执行作业。这是一个命令行执行工具,参数如下:
-
rep : Repository name 任务包所在存储名
-
user : Repository username 执行人
-
pass : Repository password 执行人密码
-
job : The name of the job to launch 任务包名称
-
dir : The directory (don’t forget the leading / or /)
-
file : The filename (Job XML) to launch
-
level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志级别
-
log : The logging file to write to 指定日志文件
-
listdir : List the directories in the repository 列出指定存储中的目录结构。
-
listjobs : List the jobs in the specified directory 列出指定目录下的所有任务
-
listrep : List the defined repositories 列出所有的存储
-
norep : Don’t log into the repository 不写日志
-
-
其它
Connection:可以配置多个数据源,在Job或是Trans中使用,这意味着可以实现跨数据库的任务。支持大多数市面上流行的数据库。
1.6 Kettle的执行
Kettle的执行分为两个层次:Transformation和Job。两个层次的最主要区别在于数据传递和运行方式。
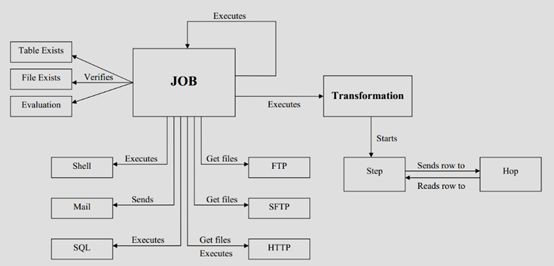
-
Transformation(转换)
Transformation(转换)是由一系列被称之为step(步骤)的逻辑工作的网络。转换本质上是数据流。
下图是一个转换的例子,这个转换从数据输入中读取数据,然后数据过滤,然后数据排序和脏数据记录,最后将数据加载到数据库。本质上,转换是一组图形化的数据转换配置的逻辑结构。
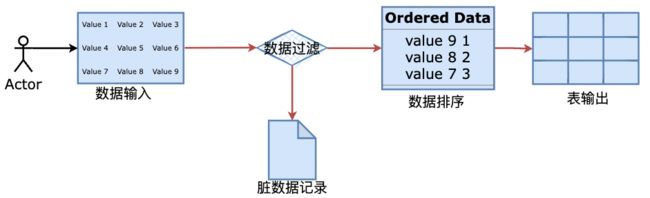
上图中,蓝色的地方就是Setp(步骤),橙色箭头就是Hop。它们也是转换的两个相关的主要组成部分:
step(步骤)和hops(节点连接)。-
转换特征
- 转换文件的扩展名是.ktr。
- 每个转换步骤都是ETL数据流里面的一个任务。
- 转换步骤包括输入、处理和输出。
- 输入步骤从外部数据源获取数据,例如文件或者数据库;
- 处理步骤处理数据流,字段计算,流处理等,例如整合或者过滤。
- 输出步骤将数据写回到存储系统里面,例如文件或者数据库。
-
Steps(步骤)
Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。 -
Hops(节点连接)
Hops(节点连接)是数据的通道,用于连接两个步骤,使得元数据从一个步骤传递到另一个步骤。节点连接决定了贯穿在步骤之间的数据流,步骤之间的顺序不是转换执行的顺序。当执行一个转换时,每个步骤都以自己的线程启动,并不断的接受和推送数据。
注意
- 所有的步骤是同步开启和运行的,所以步骤的初始化的顺序是不可知的。因为我们不能在第一个步骤中设置一个变量,然后在接下来的步骤中使用它。
- 在一个转换中,一个步骤可以有多个连接,数据流可以从一个步骤流到多个步骤。在Spoon中,hops就想是箭,它不仅允许数据从一个步骤流向另一个步骤,也决定了数据流的方向和所经步骤。如果一个步骤的数据输出到了多个步骤,那么数据既可以是复制的,也可以是分发的。
-
-
Jobs(工作)
Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动流程。作业包括一个或多个作业项,作业项以某种顺序来执行。
Jobs(工作)将功能性和实体过程聚合在了一起,由工作节点连接、工作实体和工作设置组成,工作文件的扩展名是.kjb。
下图是一个工作的例子。
-
作业项。作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。作业项的注意点。新步骤的名字应该是唯一的,但是作业项可以有影子拷贝。这样可以把一个作业项放在不同的位置。这些影子拷贝里的信息都是相同的,编辑一份拷贝,其他拷贝也会随之修改。在作业项之间可以传递一个结果对象(result object)。这个结果对象里包含了数据行,它们不是以流的方式来传递的。而是等一个作业项执行完了,再传递给下一个作业项。默认情况下,所有的作业项都是以串行方式执行的,只是在特殊情况下,以并行方式执行。
-
作业跳:作业之间的连线称为作业跳。作业里每个作业项的不同运行结果决定了作业的不同执行路径。对作业项的运行结果判断如下:
-
无条件执行:不论上一个作业项执行成功与否,下一个作业项都会执行。标识为,黑色的连线,上面有一个锁的图标

-
当运行结果为真时执行:标识为,绿色的连线,上面有一个钩号

-
当运行结果为假时执行:标识为,红色的连线,上面有一个红色的停止图标
-
-

1.7 Kettle商业和社区版区别
Pentaho Data Integration分为商业版与开源版。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。


1.8 数据集成与ETL
数据集成是指将来自不同来源、不同格式和不同结构的数据整合到一个统一的数据存储库中,以实现数据的一致性、可访问性和可用性。它的目标是消除数据孤岛,使企业能够更好地利用数据进行分析、决策和业务创新。
ETL(Extract-Transform-Load的缩写,即**抽取(Extract)、转换(Transform)、装载(Load)**的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我要学习的ETL工具是Kettle!
ETL是数据集成常用方法之一,当然还有很多集成平台服务方法做数据集成等。
1.9 ETL工具比较
市面上常用的ETL工具有很多,比如Sqoop,DataX, Kettle, Talend 等,作为一个大数据工程师,掌握其中的两三种即可,原理都很相似,其他的学习成本就相对很低。
| 比较项/ETL产品 | DataPipeline | kettle | Oracle Goldengate | informatica | talend | DataX | Sqoop | 备注 |
|---|---|---|---|---|---|---|---|---|
| 使用场景 | 主要用于各类数据融合、数据交换场景,专为超大数据量、高度复杂的数据链路设计的灵活、可扩展的数据交换平台 | 面向数据仓库建模传统ETL工具 | 主要用于数据备份、容灾 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库的ETL建模工具 | Sqoop已停止更新 |
| 使用方式 | 全流程图形化界面,应用端采用B/S架构,Cloud Native为云而生,所有操作在浏览器内就可以完成,不需要额外的开发和生产发布 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境,线上生产环境没有界面,需要通过日志来调试、debug,效率低,费时费力 | 没有图形化的界面,操作皆为命令行方式,可配置能力差 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境;学习成本较高,一般需要受过专业培训的工程师才能使用; | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境; | DataX是以Json格式脚本的方式执行任务的,其中子项目DataX-Web基于浏览器开发、上线、调度和运维。 | Sqoop基于命令行方式执行,本身没有相关BS或CS的架构,需要依赖别的来调度,几乎仅用于数据库。 | |
| 底层架构 | 分布式集群高可用架构,可以水平扩展到多节点支持超大数据量,架构容错性高,可以自动调节任务在节点之间分配,适用于大数据场景 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 可做集群部署,规避单点故障,依赖于外部环境,如Oracle RAC等 | schema mapping非自动;可复制性比较差;更新换代不是很强 | 支持分布式部署 | 支持单机部署和集群部署两种方式,底层是多线程 | 支持单机或类集群部署,底层依赖MapReduce执行 | |
| 功能 | CDC机制基于日志、基于时间戳和自增序列等多种方式可选 | 基于时间戳、触发器等 | 主要是基于日志 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于触发器、基于时间戳和自增序列等多种方式可选 | 离线批处理 | 离线批处理 | |
| 对数据库的影响 | 基于日志的采集方式对数据库无侵入性 | 对数据库表结构有要求,存在一定侵入性 | 源端数据库需要预留额外的缓存空间 | 基于日志的采集方式对数据库无侵入性 | 有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 |
第二章 Kettle安装部署
Kettle可以在Window、Linux、Unix上运行,绿色无需安装,只需要解压和配置即可使用。Kettle也支持单机模式和集群模式。
注意:
- Kettle是纯Java编写,需要依赖合适的JDK,8.x和9.x几乎jdk1.8即可。
- Windows安装部署一般用于开发和测试。
2.1 Window部署Kettle
-
下载对应的Kettle版本,官网下载地址:https://www.hitachivantara.com/en-us/products/pentaho-platform/data-integration-analytics/pentaho-community-edition.html 或 https://www.hitachivantara.com/en-us/products/pentaho-platform/data-integration-analytics/download-pentaho.html
-
安装合适的JDK,且保障JDK可正常使用,本步骤忽略。
-
解压1步骤中下载好的Kettle压缩包到任意安装目录。解压后目录如下:



-
然后打开解压目录(data-integration)下的Spoon.bat文件。
-
观察是否会出错
-
启动过程会弹出Spoon的操作界面,具体如下图所示:
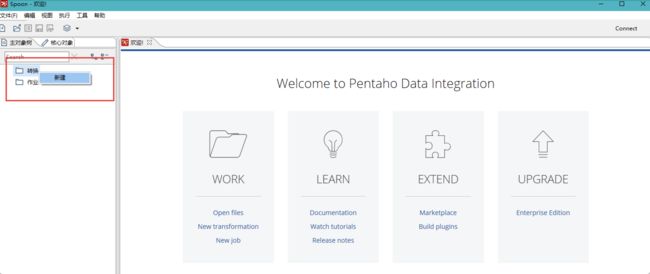
到此为止,Windows中的Kettle就安装部署成功。
2.2 Mac M1部署Kettle
因为Kettle没有专门用于 M1的程序,需要下载并安装x86_64架构的JDK及依赖软件,并 强制在Intel模式下运行shell 的方式来实现 Kettle 的正常运行。
-
配置Termina
首先,配置一个新的 Terminal 描述文件,网上资料一般都命名为“Rosetta",当然也可以命名为“Terminal(Intel)”之类,只要自己能记住这个描述文件是专门为 x86模式准备的即可。
- 配置“窗口-标题”为“Terminal(Intel)”,以易于辨识;
- 配置“Shell-启动“,勾选“运行命令:“,填入
env /usr/bin/arch -x86_64 /bin/zsh --login,取消勾选“在shell中运行”。 - 启动新的 Terminal(Intel)窗口,执行
arch命令,如果输出的是i386,则表示已经运行在Intel模式下。
注意:
如果不执行1,2步骤,也必须要讲2中的
env /usr/bin/arch -x86_64 /bin/zsh --login放到命令行执行,然后再基于该命令行执行kettle相关操作。 -
安装合适的JDK,且保障其可用,本步骤忽略。JDK下载地址:https://www.azul.com/downloads/?version=java-8-lts&os=macos&architecture=x86-64-bit&package=jdk#zulu
-
下载对应的Kettle版本,暂时没有特定的Mac M1芯片的安装包。官网下载地址:https://www.hitachivantara.com/en-us/products/pentaho-platform/data-integration-analytics/pentaho-community-edition.html
-
解压Kettle的压缩包到任意一个目录中。
-
替换libswt依赖的jar包。
接下来,要用eclipse提供的SWT图形工具套件(适配macos的x86_64版本的)来替代 kettle自带的 swt.jar。
- 从maven 下载eclipse最新jar ,如下图示:
 2. 将下载好的jar包替换 kettle 安装
2. 将下载好的jar包替换 kettle 安装 data-integration/libswt/osx64/目录下的swt.jar即可。 -
打开 Terminal(Intel) 终端窗口,切换到data-integration目录下,执行
sh spoon.sh命令,来启动 spoon(kettle的图形化界面),如下图所示:
到此为止,Mac m1的Kettle安装部署成功。
注意:
一定要安装x86_64-bit架构的JDK,否则会报错。
2.3 Linux安装部署
- 从Kettle官方网站上下载安装包(ZIP或者*.tar.gz格式)。官网下载地址:https://www.hitachivantara.com/en-us/products/pentaho-platform/data-integration-analytics/pentaho-community-edition.html
- 解压下载的文件到任意目录中。
- 根据你的操作系统,进入解压后的目录。
- 运行
sh ./spoon.sh文件进行测试,确保Kettle正确安装。 - 如果测试成功,可以继续在Kettle中创建和运行自己的ETL作业测试。
注意
通常Linux环境都没有安装图形化界面,所以运行
sh ./spoon.sh作用主要是看是否会出错,没有安装图形化界面几乎会报错org.eclipse.swt.SWTError: No more handles [gtk_init_check() failed],如果没有别的错,忽略该错误即可。
2.4 Kettle的界面介绍
Spoon是Kettle的可视化界面,只需要在Kettle安装成功后,启动Spoon服务,该界面即可自动打开,如下则是Spoon界面。

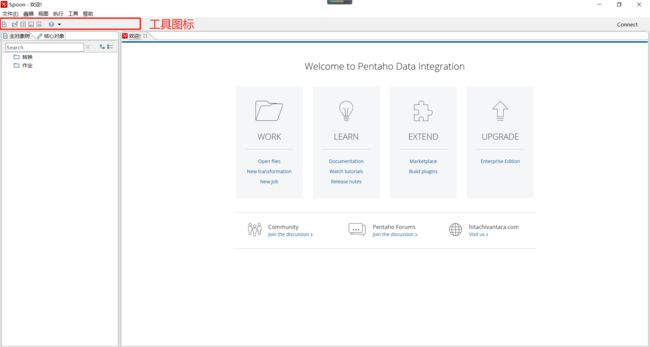
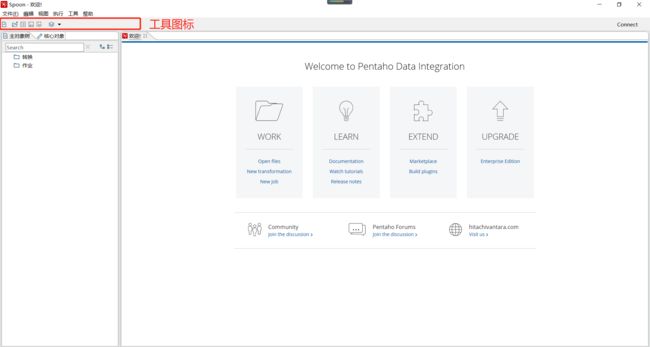


注意:
如上是Windows中的Spoon界面,和Mac系统中的Spoon的界面在显示上,稍微有区别。
2.5 Kettle的快速体验
2.5.1 CSV2Excel
使用Kettle实现,将CSV文件复制到Excel文件中。
-
首先,在Spoon界面左上脚—>文件—>新建—>转换—>核心对象—>输入—>CSV文件输入—>将该图标拖拽到工作区域—>双击CSV文件输入图标—>修改步骤的名称、csv文件路径、参数和获取字段等内容—>点击确定。

-
核心对象—>输出—>Excle输出—>将该图标拖拽到工作区域—>双击图标—>修改步骤的名称、excle文件路径等内容—>点击确定。
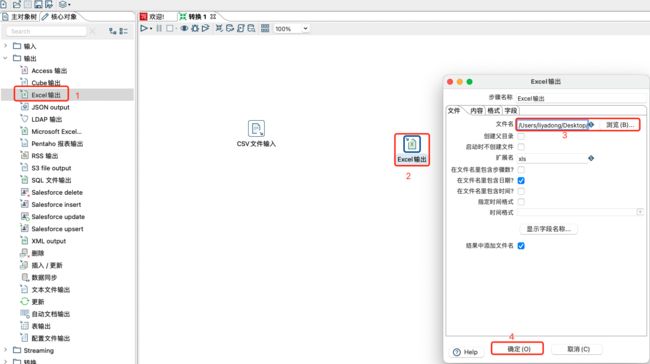
-
按住shift拖动鼠标,划线,将CVS文件输入和Excel输出连到一起。

-
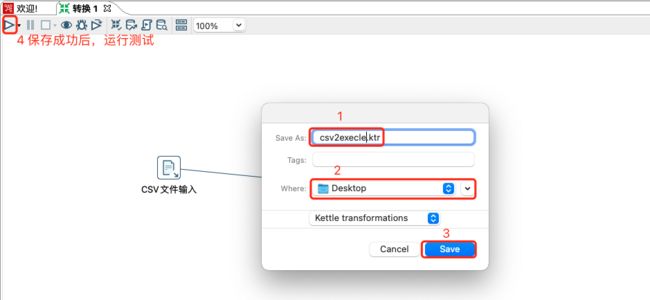
按住ctrl+s,将转换保存,编写转换名字和存储路径即可。
-
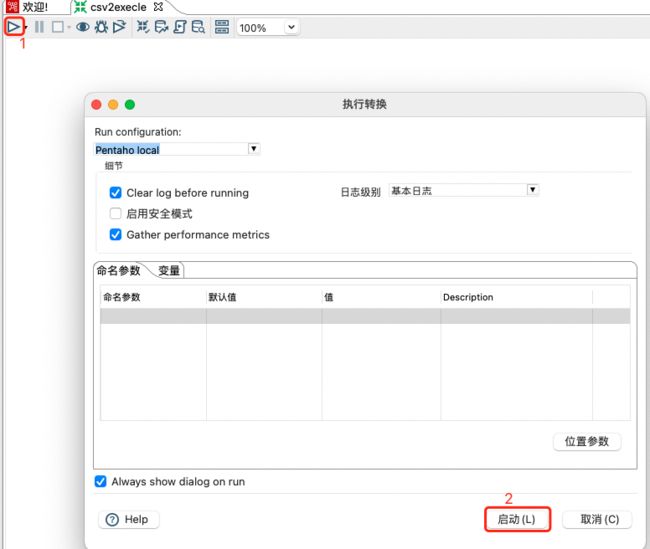
启动测试
-
测试结果
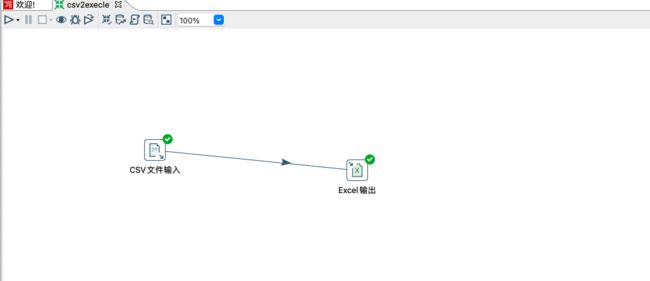
运行成功后,查看excel的输出位置是否有对应的数据,如果有数据,则运行成功,否则需要排查问题。
到此为止,csv转换excle测试完成。
2.5.2 插入更新
-
准备数据库中的数据
-- 把stu1的数据按id同步到stu2,stu2有相同id则更新数据 -- 在mysql中创建两张表 use test; create table test.stu1( id int, name varchar(20), age int ); create table test.stu2( id int, name varchar(20) ); -- 往两张表中插入一些数据 insert into stu1 values(1001,'tom',20),(1002,'shery',18), (1003,'jack',23); insert into stu2 values(1001,'eric'); -
添加MySQL相应的驱动包(
mysql-connector-java-8.0.26.jar)到kettle安装目录下的lib目录中,并重启kettle的spoon服务 -
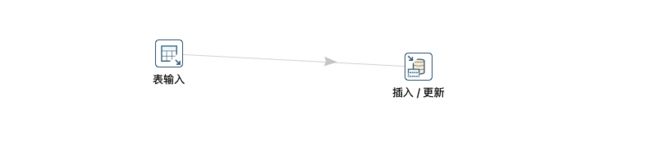
新建转换—>核心对象—>输入—>表输入;输出—>插入/更新;并按住shift拖拽,将输入和输出连接。
-
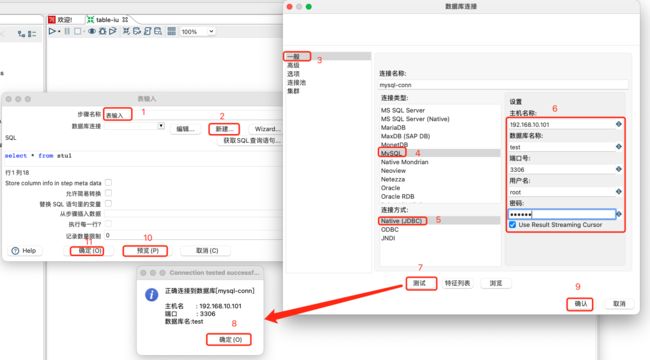
双击表输入图标,填写数据库相关配置,测试是否成功
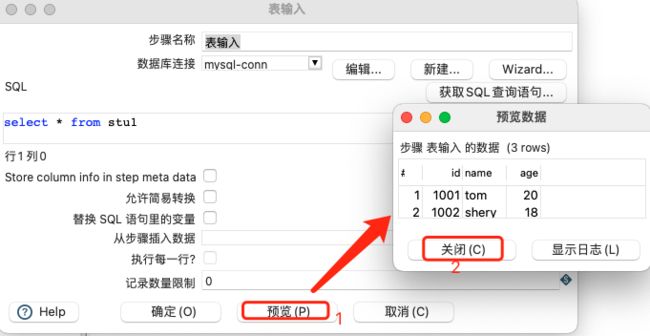
预览数据如下:
-
双击更新/插入图标,填写相关配置信息

-
保存转换

-
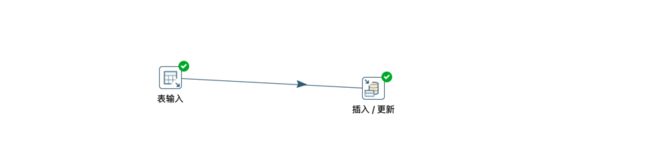
测试转换
-
查看执行结果

-
执行结果及相关信息
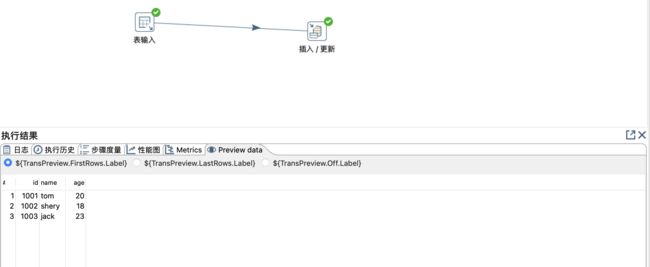
- 日志:转换执行日志信息,如有错误,这儿可以观察到。
- 执行历史:
- 步骤度量:执行中,每个步骤的读、写、输入、输出、更新、错误、时间和速度等相关情况。
- 性能图:记录相关步骤的执行情况,比如总共运行时间等。
- Metrics:转换的相关度量值。
- Preview data:预览数据
2.5.3 作业执行
使用作业执行2.4.2转换,并且额外在表stu2中添加一条数据。
-
新建一个作业,拖拽相关组件如下:
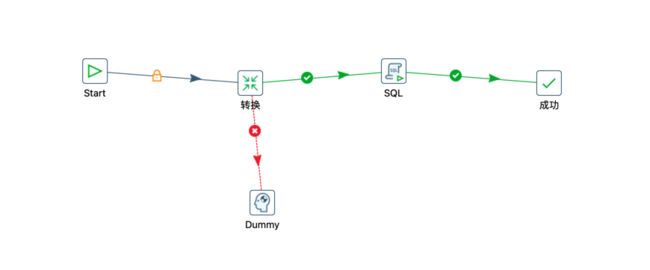
-
双击Start,编辑相关内容,此处不需要进行任何修改。

-
双击转换,选择2.4.2中保存的文件。

-
双击SQL,进行编辑
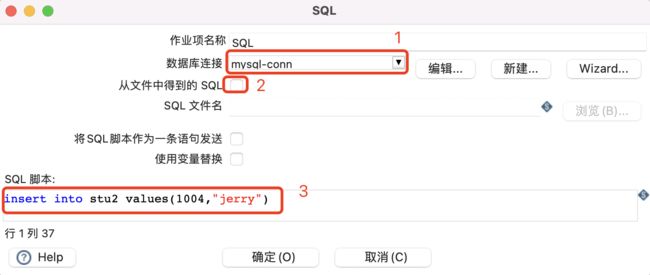
-
成功和Dummy不需要做任何的修改。
-
作业中相关的Hop说明
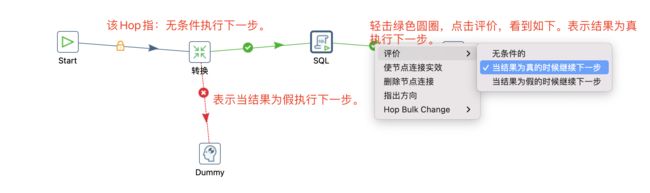
-
保存作业
-
运行作业

到此为止,作业执行完成。
2.6 Kettle集群部署
2.6.1 集群部署介绍
-
集群原理
Kettle集群是由一个主carte服务器和多个从carte服务器组成的,类似于master-slave结构,不同的是’master’处理具体任务,只负责任务的分发和收集运行结果。
Master carte结点收到请求后,把任务分成多个部分交给slave carte执行,slave执行完毕后把结果交给mater 进行汇总,再由mster返回结果。
-
优缺点
-
优点
多服务器运行,加快处理速度,对于大数据量的操作更明显
防单点失败,一台服务器故障后其它服务器还可以运行
-
缺点
采用主从结构,不具备自动切换主从的功能。所以一旦主节点宕机,整个系统不可用
对网络要求高,节点之间需要不断的传输数据
需要更多的服务器,而且主节点没有处理能力
-
-
应用场景
需求kettle能时刻保持正常运行的场景
大批量处理数据的场景
2.6.2 集群部署
-
集群规划
环境为:操作系统centos 7.9、pdi-9.3.0-ce
主机名 ip 服务 bj-zjk-001 172.24.86.96 master bj-zjk-002 172.24.86.97 slave1 bj-zjk-003 172.24.86.98 slave2 -
集群安装配置
-
master服务器节点解压pdi
tar -zxvf /home/ /opt/install/ -
分发安装目录到slave1和slave2服务器
[root@bj-zjk-001 data-integration]# scp -r /opt/install/data-integration/ bj-zjk-002:/opt/install/ [root@bj-zjk-001 data-integration]# scp -r /opt/install/data-integration/ bj-zjk-003:/opt/install/ -
master节点配置
首先确认本机8080端口是否被占用,因为kettle集群的master默认采用8080端口,如被占用,则自定义其他未被使用的端口即可;编辑安装目录下的data-integration/pwd/carte-config-master-8080.xml文件。
[root@bj-zjk-001 data-integration]# vim ./pwd/carte-config-master-8080.xml
<slave_config> <slaveserver> <name>mastername> <hostname>bj-zjk-001hostname> <port>18080port> <master>Ymaster> slaveserver> slave_config>注意:
username和password并不是指主机的登陆账号和密码,是集群的账号密码,该账号密码是集群连接的依据,账号密码是通过混淆的方式保存在pwd文件,kettle默认的账号密码是cluster/cluster,所以,在本机开发的时候,为了方便,账号密码都不用修改,都使用cluster即可。
-
slave1节点配置
slave节点的配置和master节点配置类似,其中masters标签中,name、hostname、port需要和carte-config-master-8080.xml中完全一致。slaveserver标签则是当前slave1的配置信息。
[root@bj-zjk-002 data-integration]# vim ./pwd/carte-config-8081.xml
<slave_config> <masters> <slaveserver> <name>mastername> <hostname>bj-zjk-001hostname> <port>18080port> <username>clusterusername> <password>clusterpassword> <master>Ymaster> slaveserver> masters> <report_to_masters>Yreport_to_masters> <slaveserver> <name>slave1name> <hostname>bj-zjk-002hostname> <port>8081port> <username>clusterusername> <password>clusterpassword> <master>Nmaster> slaveserver> slave_config> -
slave2节点配置
配置和slave1完全类似,照着修改即可。
[root@bj-zjk-003 data-integration]# vim ./pwd/carte-config-8081.xml
<slave_config> <masters> <slaveserver> <name>mastername> <hostname>bj-zjk-001hostname> <port>18080port> <username>clusterusername> <password>clusterpassword> <master>Ymaster> slaveserver> masters> <report_to_masters>Yreport_to_masters> <slaveserver> <name>slave2name> <hostname>bj-zjk-003hostname> <port>8081port> <username>clusterusername> <password>clusterpassword> <master>Nmaster> slaveserver> slave_config>
-
-
启动集群
通常需要先启动master,否则slave监听不到master。slave之间的启动没有顺序。
[root@bj-zjk-001 data-integration]# ./carte.sh ./pwd/carte-config-master-8080.xml ...... 2023/09/09 12:47:01 - Carte - Installing timer to purge stale objects after 1440 minutes. 2023/09/09 12:47:02 - Carte - 创建 web 服务监听器 @ 地址: bj-zjk-001:18080 [root@bj-zjk-002 data-integration]# carte.sh ./pwd/carte-config-8081.xml ...... 2023/09/09 12:47:13 - Carte - Installing timer to purge stale objects after 1440 minutes. 2023/09/09 12:47:14 - Carte - Registered this slave server to master slave server [master] on address [bj-zjk-001:18080] 2023/09/09 12:47:14 - Carte - Registered this slave server to master slave server [master] on address [bj-zjk-001:18080] 2023/09/09 12:47:14 - Carte - 创建 web 服务监听器 @ 地址: bj-zjk-002:8081 [root@bj-zjk-003 data-integration]# carte.sh ./pwd/carte-config-8081.xml ...... 2023/09/09 13:07:26 - Carte - Installing timer to purge stale objects after 1440 minutes. 2023/09/09 13:07:26 - Carte - Registered this slave server to master slave server [master] on address [bj-zjk-001:18080] 2023/09/09 13:07:26 - Carte - Registered this slave server to master slave server [master] on address [bj-zjk-001:18080] 2023/09/09 13:07:26 - Carte - 创建 web 服务监听器 @ 地址: bj-zjk-003:8081 -
访问master节点
访问地址:http://172.24.86.96:18080/

登陆成功,点击show status链接如下:
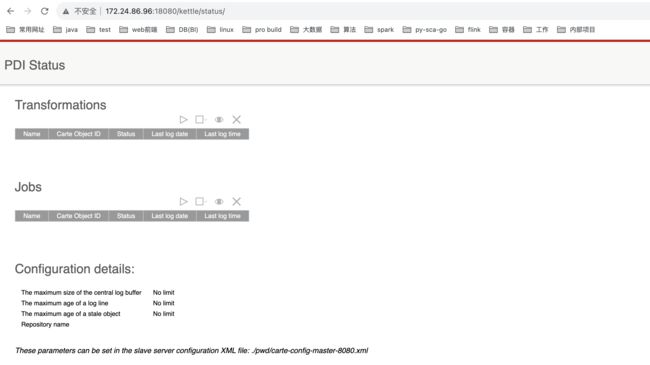
-
访问slave1节点
访问地址:http://172.24.86.97:8081/

登录成功,点击show status链接如下:

2.6.3 集群应用
-
在宿主机开发环境中启动kettle的spoon
-
新建一个转换
生成记录在输入分类中,写日志在应用分类中。

新建好转换后,保存即可。
-
新建子服务器
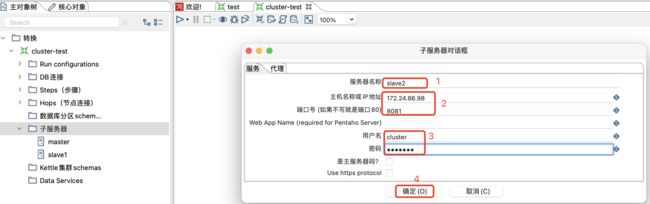
然后在新建的转换中选择主对象树-子服务器-新建子服务器。
新建主节点子服务器如下:
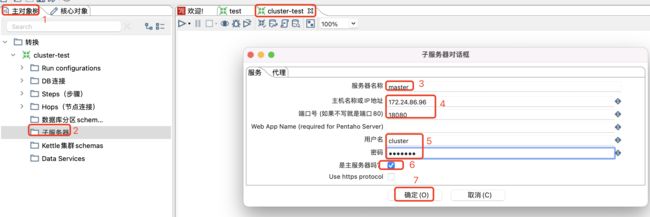
注意:
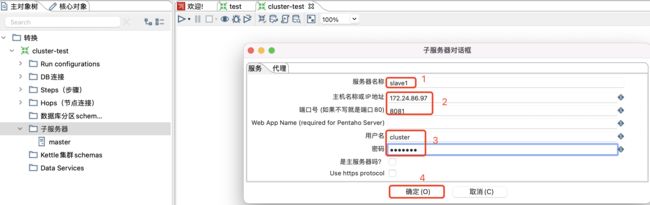
服务器名称、主机名、端口号、用户名和密码都需要和服务器上的配置一样。
新建slave1子服务器,和主节点子服务器建立一样,如下:
-
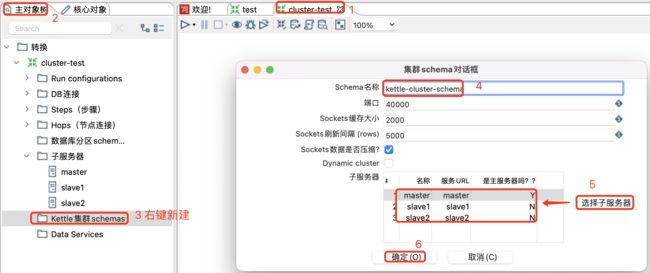
配置Schema信息
选择主对象树-集群schema-新建schema,然后将刚刚配置的子服务器都添加进入
-
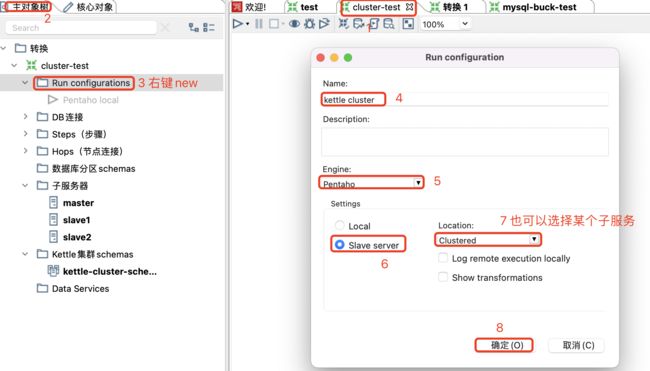
配置run configurations
选择主对象树 - run configurations - new
-
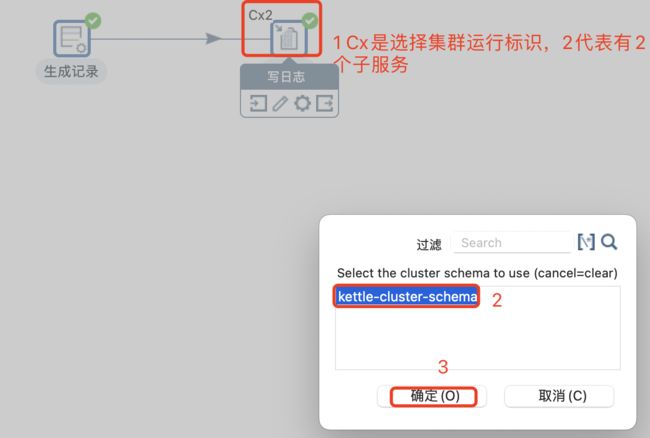
为转换配置shchema信息
为了测试,对trans进行集群测试,如下图。在写日志的时候右键,在弹框中,选择集群,选择配置好的集群,该步骤右上方会有一个Cx2标识,表示有2台子服务器的集群。
-
提交集群运行测试
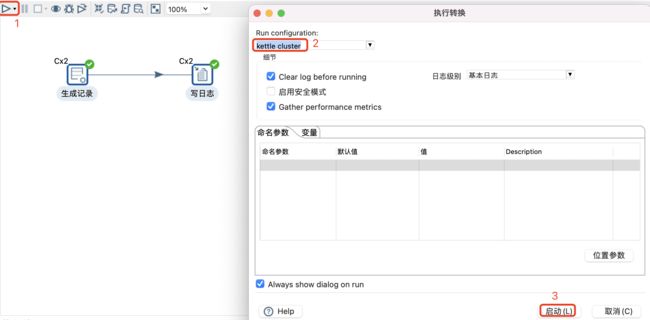
-
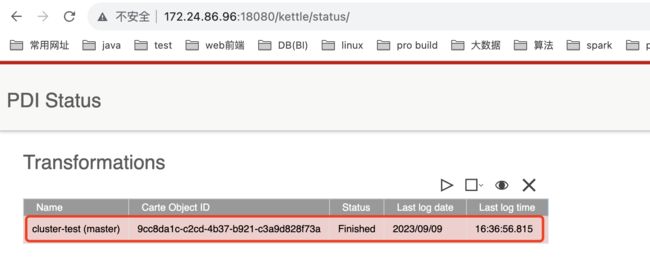
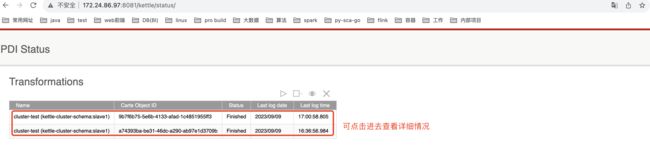
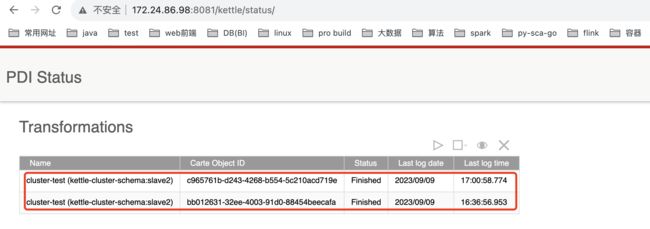
查看执行情况
查看主节点网页信息:
查看slave1节点网页信息:
查看slave2节点网页信息:
查看子服务器的某个任务详细:
选中某个转换,然后点击transformations的列表右上方的view标识。
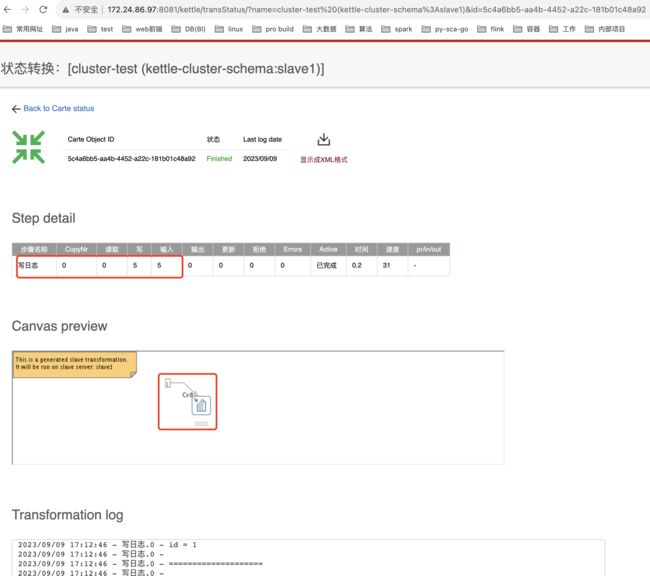
注意:
- 也可以查看服务器上子服务的日志相关信息。
- 整个job或者job中的某个转换也可以设置远程集群运行。
第三章 Kettle操作
在数据仓库技术中,ETL 是必不可少,Kettle 作为 ETL 的经典工具,通过图形界面设计实现做什么业务,无需写代码去实现,可视化界面开发,也是非常简单的。它的输入、输出和转换等功能非常丰富。
3.1 数据输入
输入指将外部数据(文件和表等)或生成的数据作为kettle的数据源,相当于source,是数据起源地,即数据的抽取过程。比如,我们可以从数据库的表中获取或文件(文本,EXCEL,CSV,XML,Json等文件)中获取,或从URL中选择获取,也可以只在kettle中模拟数据,或者获取系统中的参数等,总之Kettle的数据源很多,大约30余种,总有你需要的,如果超过了你需要的,可以选择其他组件空控件或者自定义插件作为输入。
3.1.1 生成记录
该控件生成一些固定字段的记录,主要用来模拟一些数据进行测试;
注意:
如果【生成记录】前面还有其他转换操作,前面的记录是无法正确读取的。所以该控件一般作为开始控件。
创建生成记录控件如下:
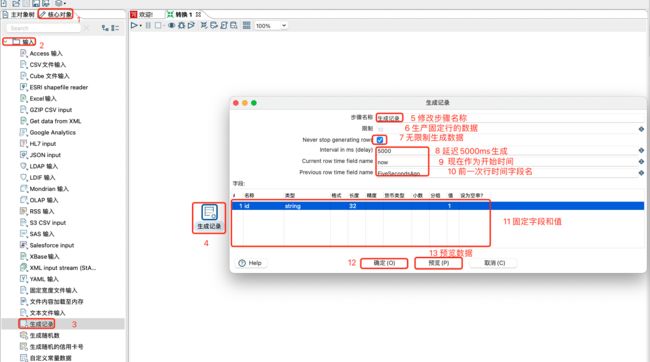
生成记录步骤详解:
-
步骤名称:步骤的名称,在单一转换中,名称必须唯一,建议按照统一规范编写即可。
-
限制:生成固定行的数据。
-
Nerver stop generating row:永不停止生成行数据,即无限制生成数据。勾选该选项后,限制参数将失效。该选项将配合生成数据的延迟、当前时间、上一行时间等。
-
字段设置信息如下:
-
名称:一行中字段名称。
-
类型:指定字段类型:字符串、日期、数字、布尔值、整数、BigNumber、可序列化或二进制。
-
格式:格式化字符串时需要。例如需要格式化日期与时间(timestamp类型),那么可以用yyyy-MM-dd HH:mm:ss.XXX。
-
长度:对于数字:数字的有效长度;对于字符串:字符串的总长度;对于日期:字符串的打印输出长度(例如,输入4只会返回年份)。
-
精度:对于数字:小数位数。
-
货币类型:货币符号,主要用在财务场景,一般放在货币金额数字的前缀或者后缀。例如人民币一般用的¥,美元一般用$,欧元一般用€。该控件对于步骤本身不产生影响,只是对该字段的货币类型进行备注。
-
小数:这里应属于翻译错误,翻译为“小数点符号”更为合适。在字符型转小数型(BigNumber)时,识别字符串中的小数点。如字符串“123,456.789”和“123456.789”转BigNumber型时,设置十进制为“.”,则能转变为123456.789。有意思的是这里除了能识别“.”,还能适配其他字符,如“,”、“|”、“_”、甚至字母“a”都可以。只要字符被替换成“.”之后整个字符串是符合数字格式的就行。
注:不管设置多长的字符串,这里始终只取第一个字符作为小数点符号。_
-
分组:在字符型转小数型(BigNumber)时,识别字符串中的分隔符(常见的千位分隔符)。如字符串“6,123,456.789”转BigNumber型时,设置分组为“,”,则能转变为6123456.789。有意思的是这里除了能识别“,”,还能适配其他字符,如“.”、“|”、“”、甚至字母“a”都可以。只要字符被转换后整个字符串是符合数字格式的就行。另外分组可以结合小数点符号做一些更有意思的事情,如有一个字符串如“123.456,789”,将小数点符号设为“,”,将分组设为“.”,可转换为“123,456.789”。
-
值:为该字段指定一个固定值。
-
设为空串:选择下拉菜单中的“是”或“否”。默认设置为“否”,当选择为“是”时,则该字段会输出一个空的字符串。
注:空的字符串类型不能被后续步骤的数字型字段接收,如果要输出数字类型的空值,请设置该字段类型为Number,且设为空串处设为“否”。
-
预览生成时间及固定值数据如下:

注意
- 固定值很简单,就生成指定行数的字读值。
- 无论固定还是周期性生成固定值,都必须要指定字段及其类型及其值,否则预览或者生成的数据为空。
- 周期性生成数据,预览必须要取消才能看到数据,否则一直生成没办法预览数据。
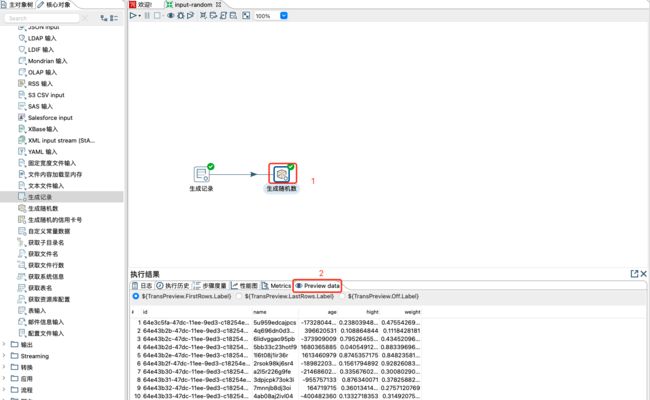
3.1.2 生成随机数
该控件主要生成一些随机值,比如随机整数、随机数字(0-1之间)、随机字符串(64位长度)、随机UUID等类型的值,也主要用于测试。主要避免生成记录中的固定值的现象。
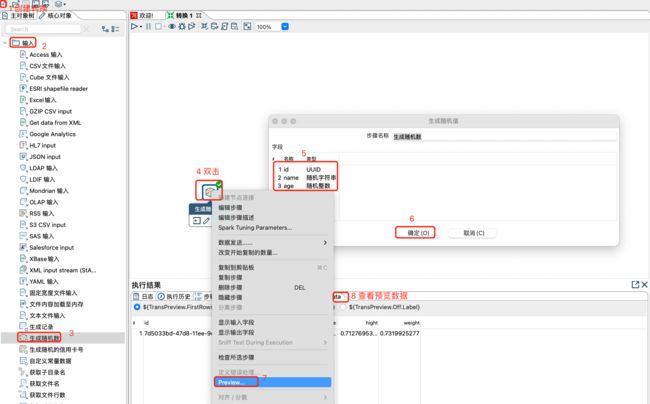
注意:
单独的随机数步骤,只能生存1行数据。
获取多行随机数或者周期性生成随机数,需要和生成行记录搭配应用。
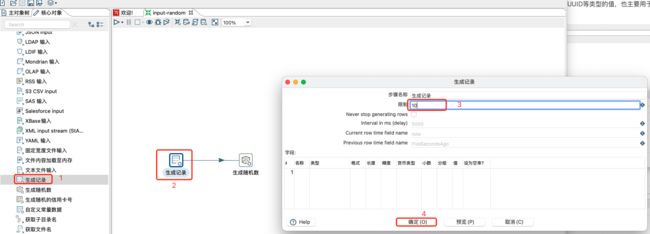
保存,执行转换,查看数据如下:
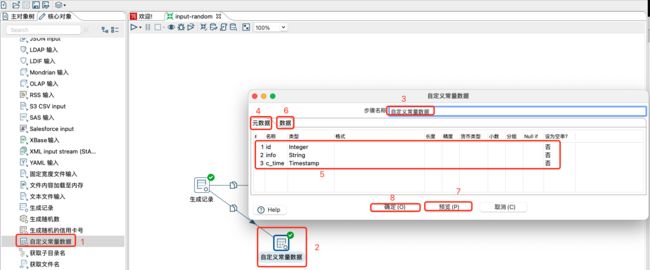
3.1.3 自定义常量数据
自定义常量数据步骤主要用于增加自定义字段和对应数据到流中,可增加多个字段并为每个字段赋予值,然后在数据流的下游应用。
自定义了c_time、id、info三个常量字段配置如下图所示:
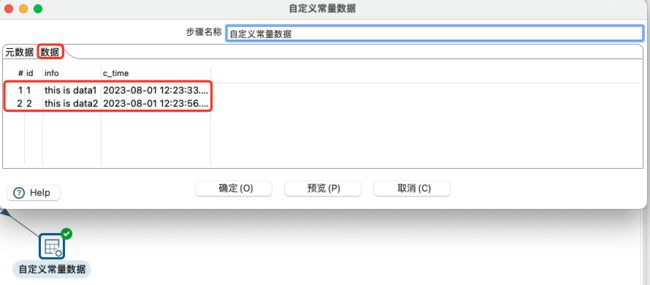
配置的常量数据如下:
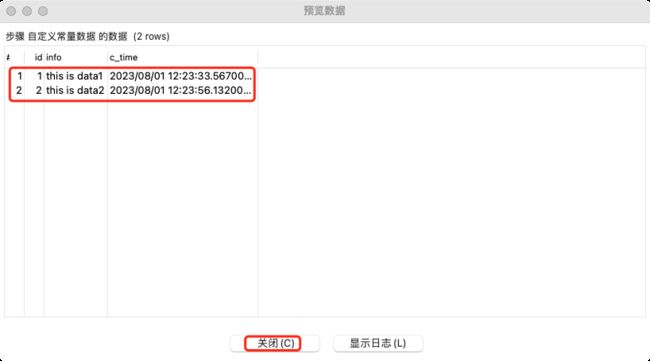
预览数据如下:
3.1.4 获取系统信息
获取系统信息步骤包括命令行输入的参数,操作系统时间(),ip 地址,一些特殊属性,kettle 版本等。
此步骤生成单行,其中包含所请求信息的字段。同时,它还接受数据流上游的输入行。
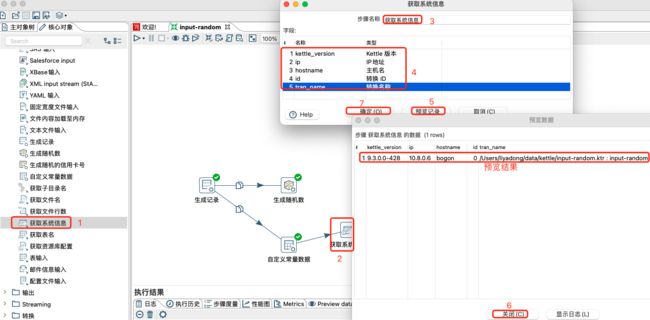
3.1.5 文本输入
提取服务器上的日志信息是公司里 ETL开发很常见的操作,日志信息基本上都是文本类型,因此文本文件输入控件是kettle中常用的一个输入控件。
文件选项卡配置:
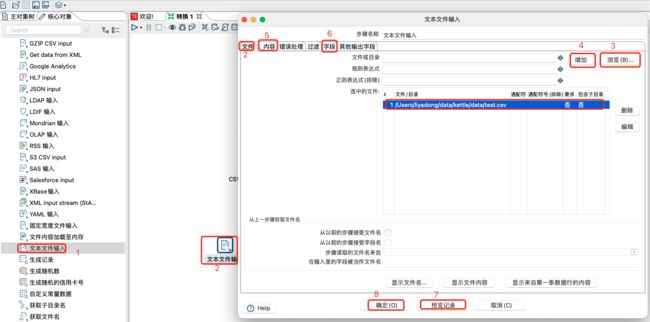
内容编辑:

添加字段,并预览数据:

3.1.6 CSV文件输入
CSV 文件是一个用逗号分隔的固定格式的文本文件,这种文件后缀名为.csv,可以用Excel或者文本编辑器打开。在企业里面一般最常见的。ETL 需求就是将 csv 文件转换为 excel 文件或者加载到库表中,如果用 Kettle 来做这个ETL工作,变得就像对很简单了。具体操作如下:
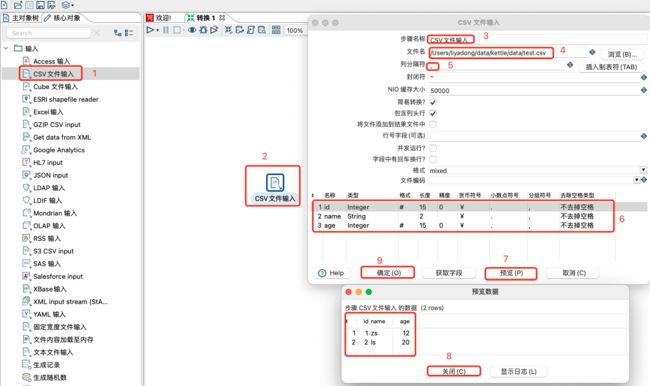
- 步骤名称:可以修改,但是在同一个转换里面要保证唯一性, 建议按照规范修改即可。
- 文件名:选择对应的csv文件和路径,mac m1系统中不能选择,直接输入对应的路径即可。
- 列分隔符:默认是逗号(不用改)
- 封闭符:结束行数据的读写(不用改)
- NIO 缓存大小:文件如果行数过多,需要调整此参数
- 简易转换?:将尝试避免不必要的数据类型转换,如果可能的话,可以显著提高性能。比如从一个文本读取并写入另外一个文本。
- 包含列头行:意思是文件中第一行是字段名称行,表头不进行读写
- 行号字段(可选):如果文件第一行不是字段名称或者需要从某行开始读写,可在此输入行号。
- 并发运行? :选择并发,可提高读写速度
- 字段中有回车换行? :不要选择,会将换行符当成数据读出
- 格式:指定文件格式,有DOS、Unix和Mixed三种可选。dos文本格式换行是\r\n;unix文本格式换行是\n;Mixed格式为混合格式。
- 文件编码:指定要读取的文件的编码。如果预览数据出现乱码,可更换文件编码。
- 获取字段:单击以根据当前设置(即分隔符,Enclosure等)从目标文件返回字段列表。所有标识的字段都将添加到字段表中。
- 预览:单击以预览来自目标文件的数据。
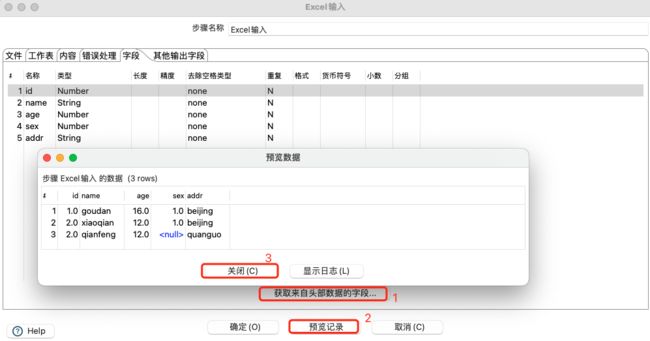
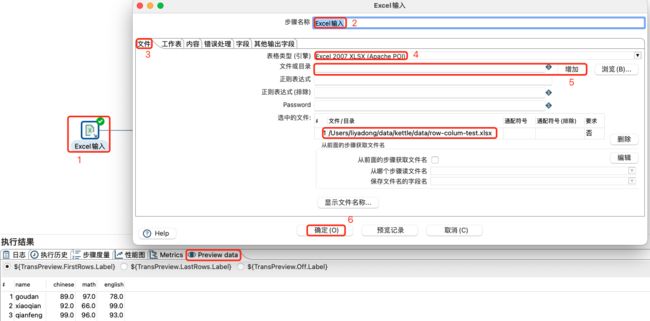
3.1.7 Excel输入
Excel 步骤为提供了从Microsoft Excel读取数据的功能,是数据分析和处理中常见的一种数据文件格式。
注意:
默认的电子表格类型(引擎)设置为Excel 97-2003 XLS。当读取其他文件类型(如OpenOffice ODS或Excel 2007)并使用特殊功能(如受保护的工作表)时,需要相应地更改Content选项卡中的电子表格类型(引擎)。
excel文件设置:

工作表选择和添加:

字段获取及数据预览:
3.1.8 XML输入
该步骤提供了使用XPath规范从任何类型的XML文件读取数据的能力。
XPath即为XML路径语言(XML Path Language),它是一种用于在XML和HTML文档中定位元素的语言。XPath基于XML或HTML的树状结构,提供在数据结构树中找寻节点的能力。XPath使用路径表达式在XML文档中选取节点,常用于爬虫数据选取和xml文件数据选取等。下面列出了常用的XPath路径表达式:
| xpath路径 | 描述 | 备注 |
|---|---|---|
| / | 从根节点开始选取 | |
| // | 模糊查找标签,也就是不考虑他们的位置,只要找到复合标签名称的标签就行 | 一般定位元素,都是使用模糊查找,因为这样更加灵活 |
| . | 选取当前节点 | |
| … | 选取当前节点的父节点 | 使用…/…/…/data 等可以找到data的父节点的父节点 |
| @标签属性名 | 选取标签属性名称的属性值 | |
| 标签名 | 选取节点值 |
注意:
早期有XML步骤,但不建议使用XML输入步骤。建议使用从Get data from XML或XML input stream(StAX)获取数据步骤。
读取节点案例:
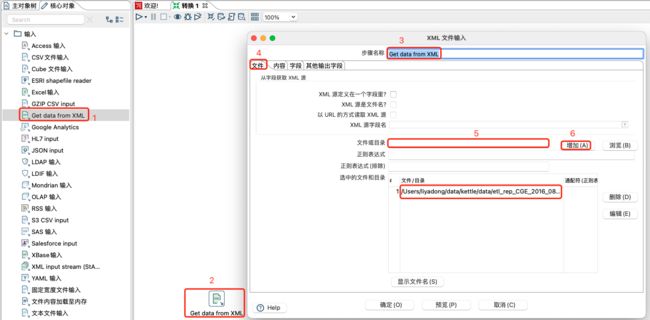
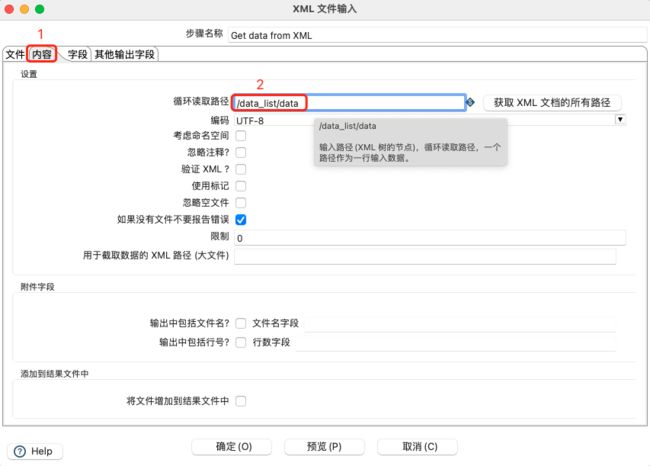
设置内容,建议获取 xml文档的所有路径,设置合适的循环读取路径:
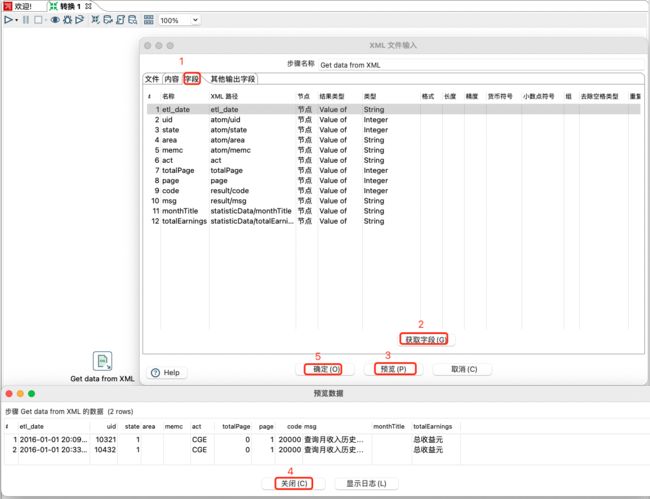
获取或添加自己想要的字段,设置相应的属性,并预览数据如下:
读取节点及属性案例:
准备数据如下:
<database>
<item id="111" clientName="xiaoqian1">
<detail child_id="1">
<name>Bisoprololname>
<amount>2amount>
detail>
<detail child_id="2">
<name>Aspirinename>
<amount>20amount>
detail>
item>
<item id="112" clientName="xiaoqian2">
<detail child_id="1">
<name>Libitorname>
<amount>1amount>
detail>
item>
database>
设置xml路径:
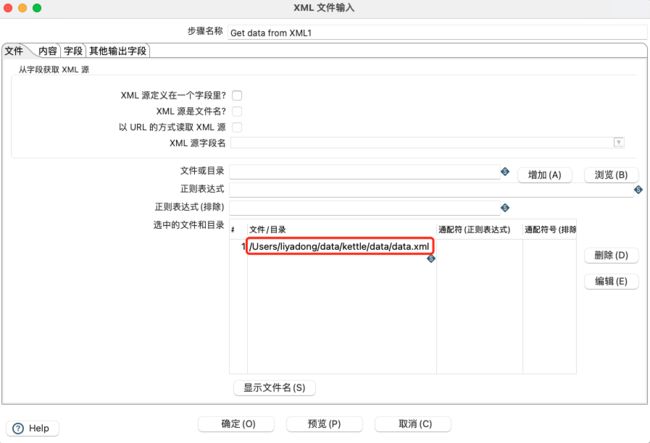
设置循环读取路径:
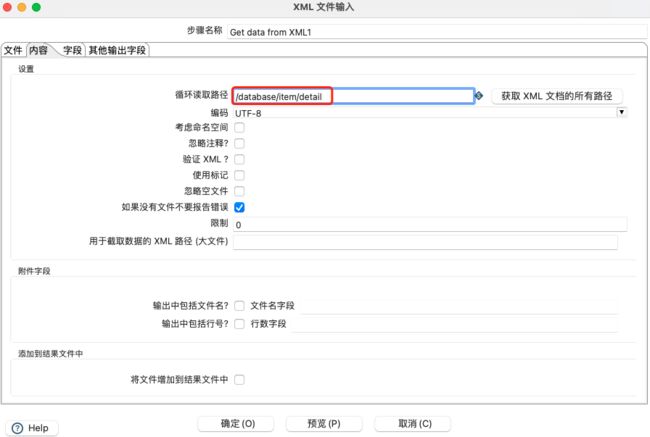
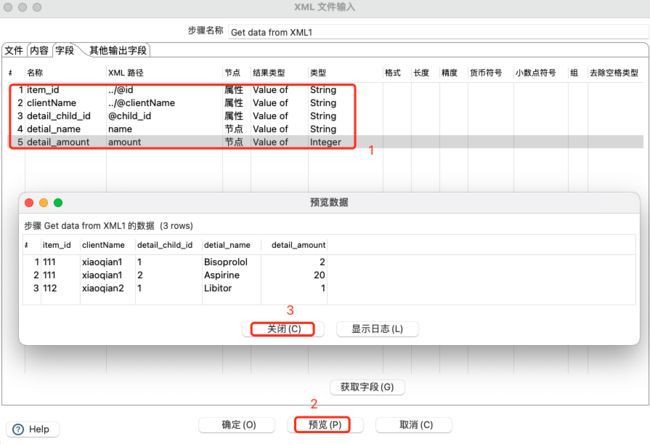
添加获取节点及属性字段,并预览数据:
3.1.8 Json输入
使用JSONPath表达式从JSON结构、文件或传入字段读取数据,以提取数据和输出行。JSONPath表达式可以使用点表示法或方括号表示法。表示如下:
- 点表示法:
$.store.book[0].title - 括号表示法:
$['store']['book'][0]['title']
JsonPath表达式总是引用JSON结构,就像XPath表达式与XML文档结合使用一样。JsonPath中的“根成员对象”总是被称为$,无论它是对象还是数组。
JsonPath中常用的操作如下:
| Operator | Description |
|---|---|
$ |
要查询的根元素。这是所有路径表达式的开始。 |
@ |
过滤器谓词正在处理的当前节点。 |
* |
通配符。可用于任何需要名称或数字的地方。 |
.. |
深度扫描。可用于任何需要名称的地方。 |
. |
孩子节点,即子属性 |
[' |
用括号标记的一个或多个子节点 |
[ |
用括号标记的一个或多个数组索引 |
[start:end] |
数组切片运算符 |
[?( |
筛选器表达式。表达式必须计算为布尔值。 |
json数据如下:
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
创建json输入:
添加字段,并预览数据:
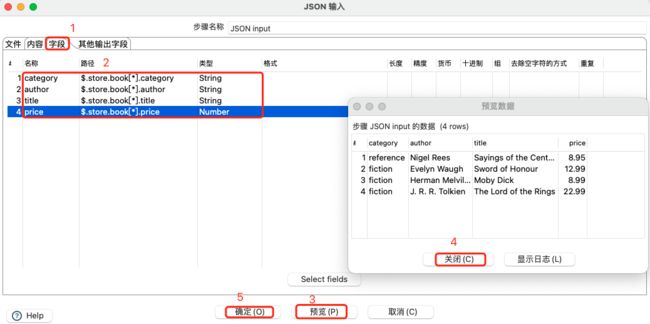
注意:
带*方式的字段或与贷*组合的字段都要注意,很多不能被解析或者会出现解析错误,需要修改写法。
3.1.9 表输入
Table Input步骤使用SQL语句从连接的数据库读取信息。通过单击Get SQL选择语句按钮,可以自动生成基本SQL语句。
表输入可以说是kettle中用到最多的一种输入控件,因为企业中大部分的数据都会存在数据库中。kettle可以连接市面上常见的各种数据库,比如Oracle,Mysql,SqlServer等。但是在连接各个数据库之前,我们需要先配置好对应的数据库驱动,将其放到安装目录下的lib目录中。如下事表输入步骤:
-
添加MySQL相应的驱动包(
mysql-connector-java-8.0.26.jar)到kettle安装目录下的lib目录中,并重启kettle的spoon服务,使其驱动生效。 -
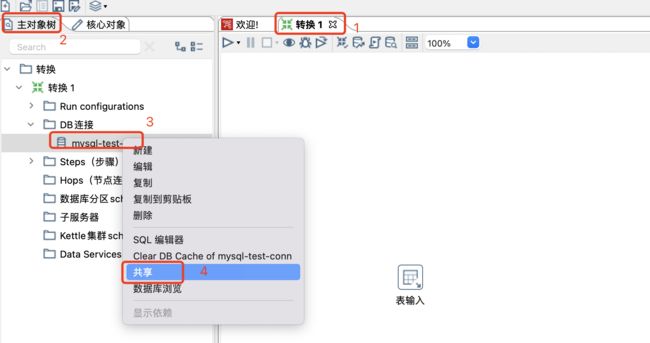
创建表输入步骤,并创建数据库连接
-
编辑SQL或获取SQL查询语句,并预览数据如下
-
共享数据库连接,因为数据库连接默认只对本转换有效,换一个转换以后,这个连接就没法用了,还需要新建数据库连接,所以我们需要将建好的这个数据库连接进行共享下,共享以后,其他的转换也能用我们提前建好的这个数据库连接了。
-
数据库连接池也是集成数据时常用连接方式,如下针对MySQL数据库连改造连接池
kettle数据输入空步骤到此结束,当然还有很多数据输入,大家可以根据自己的需求进行操作。
3.2 数据转换
转换时ETL中的T,也是将数据抽取到后进行的数据的清洗操作。主要包括:Concat fields组件、值映射组件、增加常量组件、增加序列组件、字段选择组件、计算器组件、剪切字符串组件、字符串替换组件、字符串操作组件、去除重复记录与排序记录组件、拆分字段组件、列拆分多行组件、列转行组件、行转列组件、行扁平化组件等。
3.2.1 增加常量-序列-字段选择组件
增加常量:该组件的作用,主要是用来,为当前的数据再增加一列,里面的内容是固定值。
增加序列:增加序列组件与增加常量组件,都是用来增加字段信息的,但是区别的是增加序列的值是按序可变,增加常量组件值是固定值。
字段选择组件:该组件可以从数据中筛选字段也可以改变字段的名称和数据类型
案例:
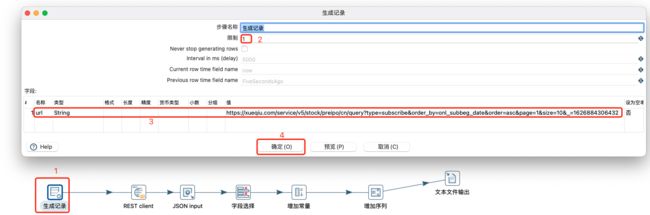
通过生成记录生成url,使用rest client将url进行请求,返回json格式数据,然后利用字段选择对应的json中的字段,然后添加常量,添加序列,最后将数据输出到文本中,具体操作如下:
生成记录步骤:
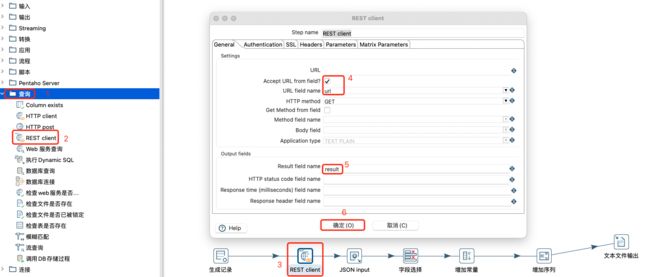
REST client查询:
Json input输入:
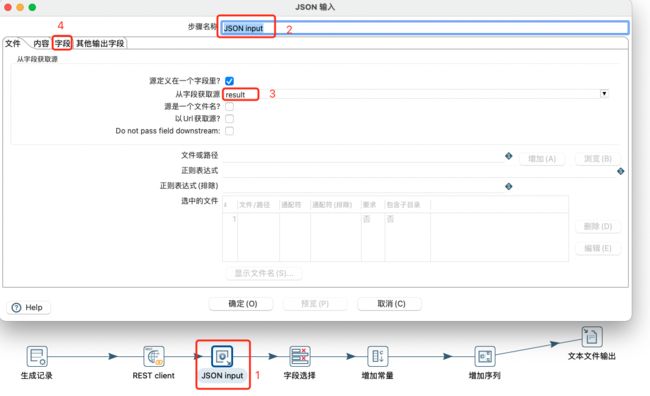
设置Json输入的字段:
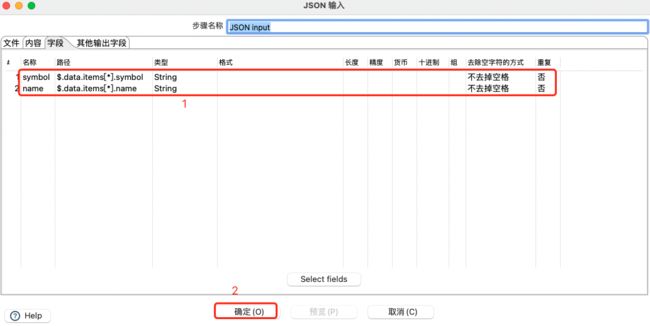
选择字段转换:
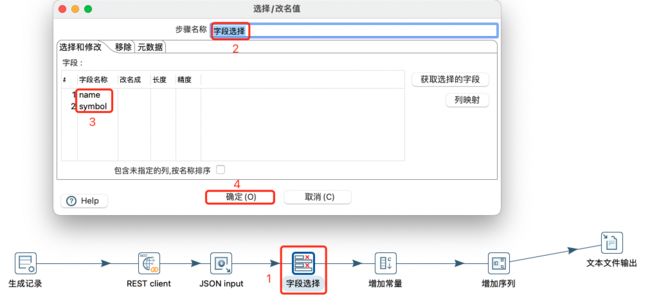
添加常量转换:

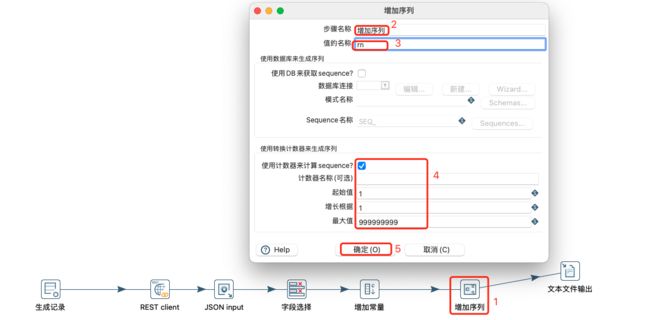
添加序列转换:
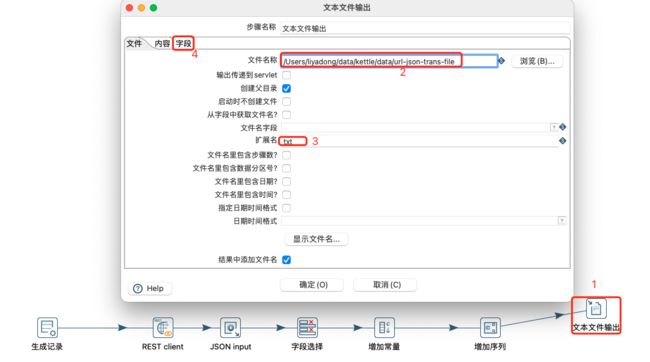
文本输出设置:
选择输出字段:
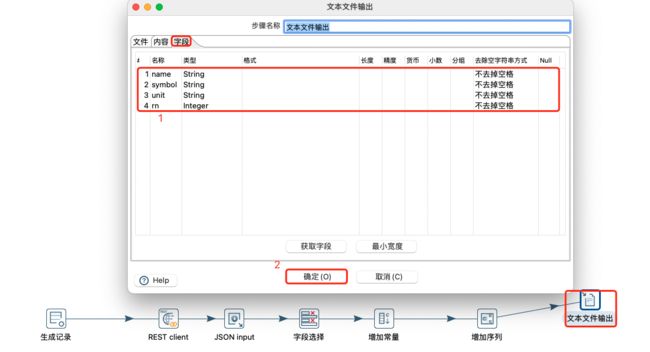
保存运行如下:

3.2.2 常见转换一
-
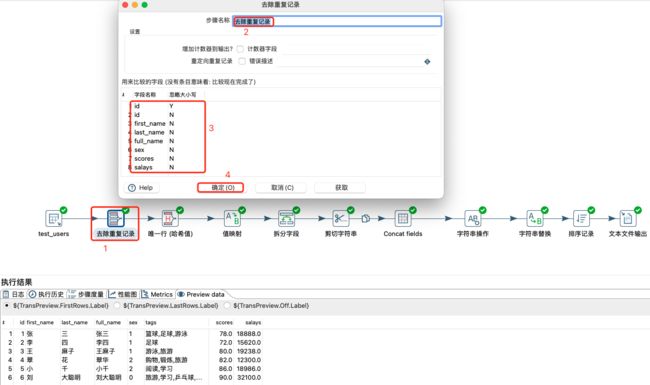
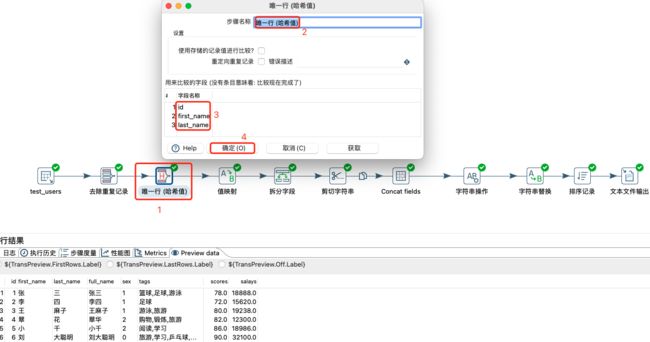
去除重复记录
根据指定字段去掉重复的数据记录。
-
唯一行(哈希值)
唯一行(哈希值)组件,与去除重复记录组件的作用都是一样的,都是去重行,但是两者实现的原理不一样,唯一行(哈希值)组件的效率要高一些。 -
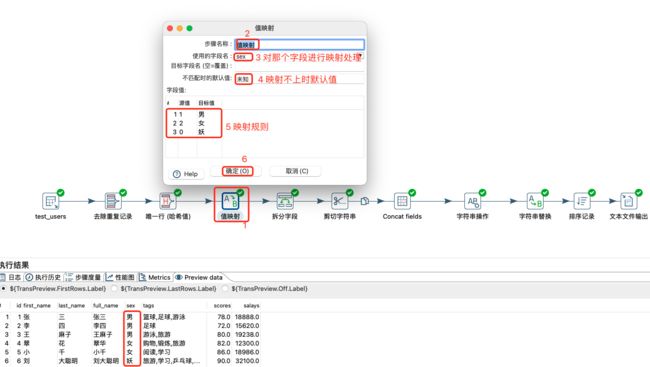
值映射
将某字段某些值替换成统规定的值。很多时候,多系统数值不规范时,可以利用该方式来进行统一映射,使数据达到统一。
-
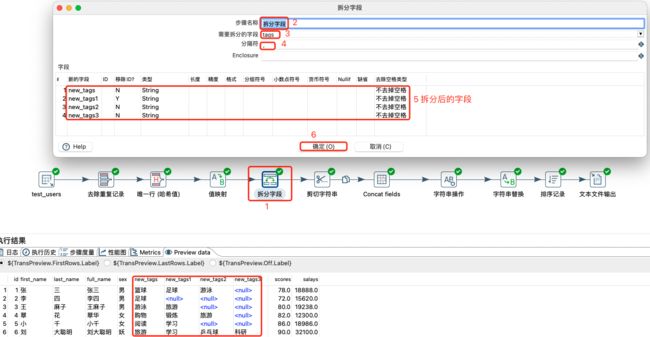
拆分字段
将
一个字段的值,拆分成多个字段。 -
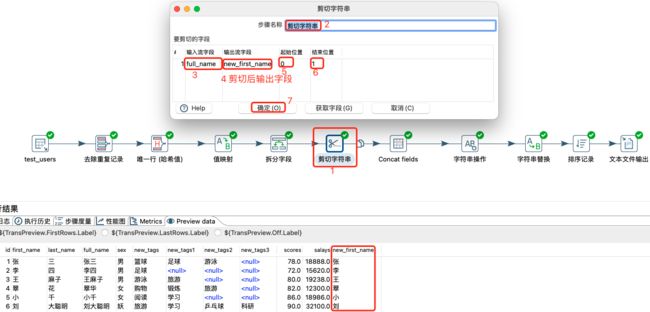
剪切字符串
将一个字符串中的一部分单独提取出来,类似于字符串的截取操作。
-
Concat fields
该组件的作用很简单,类似于SQL语言中的concat或concat_ws拼接字符串,就是把多个字段的值拼接成一个新的字符串。
-
字符串操作
对字符串进行去除空格、转大小写、补齐和移除指定分隔符等操作,输出新的字段。
-
字符串替换
将某字段某字符串替换为新的字符串,支持正则表达式。
-
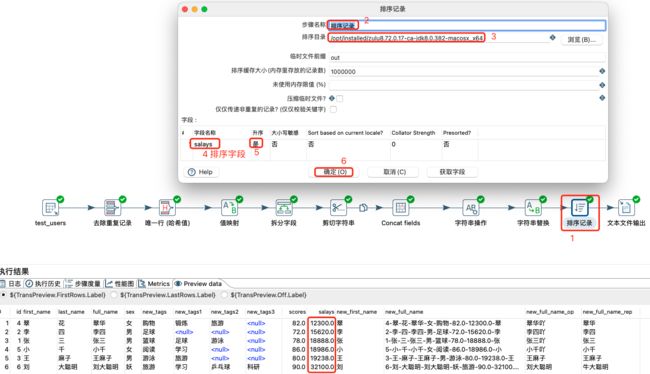
排序记录
根据某字段或多个字段进行数据排序,通常根据数值类型进行升序或降序。
准备数据库数据如下:
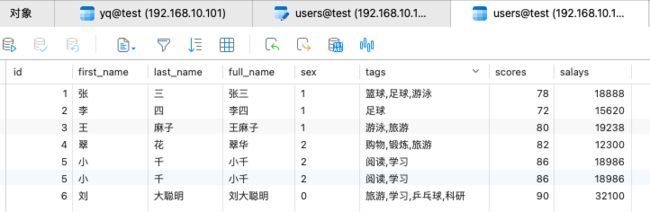
案例:
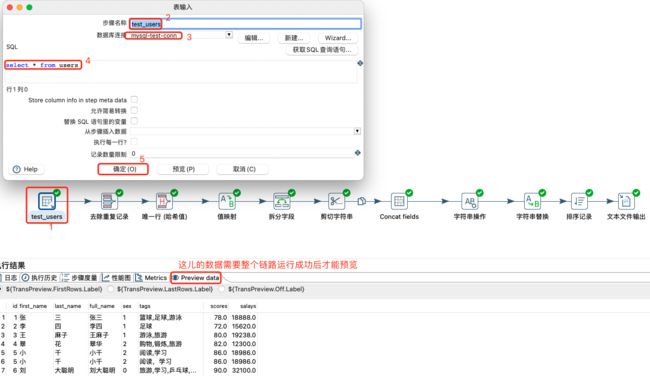
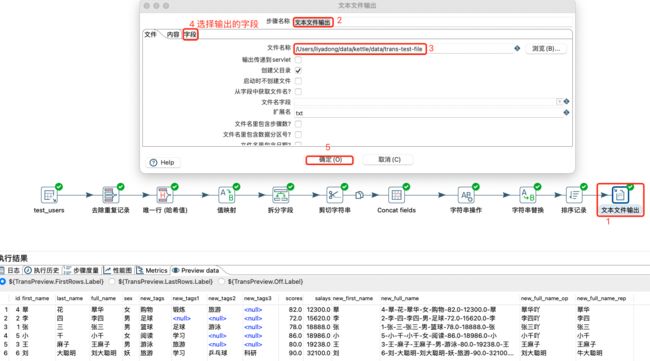
将上述数据作为表输入;然后进行除tags字段外的所有字段去重;然后使用id、first_name和last_name进行唯一行去重;在进行sex值的映射;在对tags字段进行拆分;然后对full_name进行剪切,提取姓;然后对所有字段进行连接;然后对字符串进行补齐等操作;然后对字符串字符进行替换;然后对数据按照salays升序排序;最后将所有转换的数据输出到文本中。具体操作如下:
表输入及数据:
去除重复记录:
注意:
去除重复行记录,需要根据指定字段将数据排序,如果没有将数据排序,则只考虑相同行数据。
唯一行(哈希值):
值映射:
拆分字段:
剪切字符串:
连接字段值:
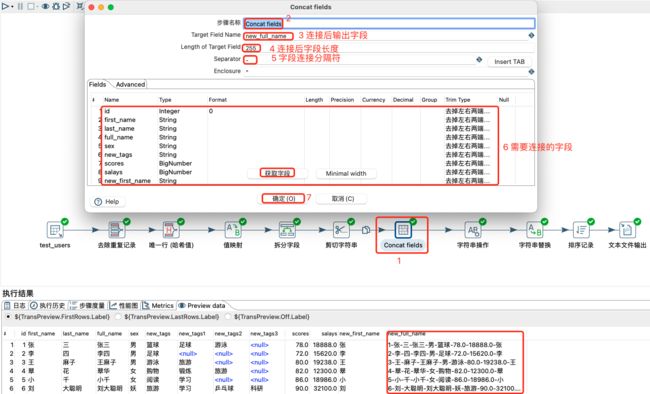
字符串操作:
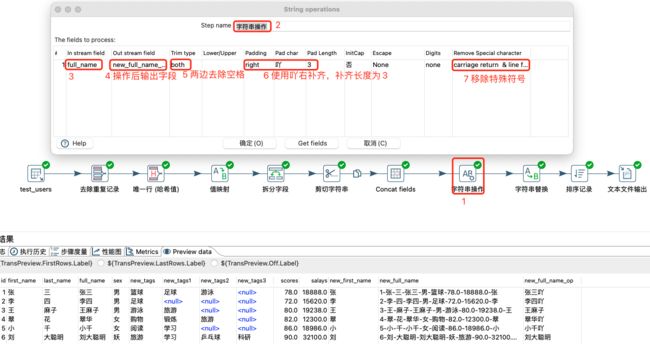
字符串替换:

排序记录:
文本文件输出:
3.2.3 计算器-数值范围-设置字段值范围
计算器转换主要用于对输入数据执行计算,可以结合函数进行计算。要使用,需要指定要执行和返回结果的函数的输入字段和类型,也可以指定一个字段,以便在计算完所有值后从结果(输出)中删除,这对于删除临时值很有用。
数值范围转换主要是根据字段值和范围的上下界关系,设定值。类似于映射和case when等现象。
设置字段值转换主要指某字段值为其他字段值,类似于替换操作。
常见的计算器转换支持的运算如下:
| 功能 | 描述 | 必填 |
|---|---|---|
| - | 空(不做处理,返回值为NULL) | A |
| Set field to constant A | 创建一个常量值的字段。 | A |
| Create a copy of field A | 创建具有给定字段值的字段的副本。 | A |
| A + B | A加B。 | A and B |
| A - B | A减B。 | A and B |
| A * B | A乘B。 | A and B |
| A / B | A除B。 | A and B |
| A * A | A的平方。 | A |
| SQRT( A ) | A的平方根。 | A |
| 100 * A / B | A在B中的百分比。 | A and B |
| A - ( A * B / 100 ) | 减去A的B%。 | A and B |
| A + ( A * B / 100 ) | 将B%添加到A。 | A and B |
| A + B *C | A加B乘以C。 | A, B and C |
| SQRT( A* A + B* B ) | 计算(A平方+B平方)的平方根. | A and B |
| ROUND( A ) | 返回最接近参数的Integer。通过将结果加1/2,取下限,并将结果转换为int类型,将结果舍入为整数。换句话说,结果等于表达式的值:floor(a + 0.5)。如果需要舍入方法“将一半舍入为偶数”,请使用以下方法ROUND(A,B),不带小数位(B = 0)。 | A |
| ROUND( A, B ) | 将A舍入到最接近的偶数,并用B小数表示。使用的舍入方法为“半舍入到偶数舍入”,也称为无偏舍入,收敛舍入舍入,统计学家舍入,荷兰舍入,高斯舍入,奇偶舍入,银行家舍入或零舍入舍入,并广泛用于簿记中。这是IEEE 754计算函数和运算符中使用的默认舍入模式。在德国,它通常被称为“ Mathematisches Runden”。 | A and B |
| STDROUND( A ) | 将A舍入到最接近的整数。使用的舍入方法是“从零开始舍入一半”,也称为标准或通用舍入。在德国,它被称为“kaufmännischeRundung”(在DIN 1333中定义)。 | A |
| STDROUND( A, B ) | 与STDROUND(A)中使用的舍入方法相同,但十进制为B。 | A and B |
| CEIL( A ) | 上限函数将数字映射到后面的最小整数。 | A |
| FLOOR( A ) | 底函数将数字映射到最大的先前整数。 | A |
| NVL( A, B ) | 如果A不为NULL,则返回A,否则返回B。请注意,有时您的变量将不是null而是空字符串。 | A and B |
| Date A + B days | 在日期字段A中添加B天。 | A and B |
| Year of date A | 计算日期字段A的年份。 | A |
| Month of date A | 计算日期字段A的月份。 | A |
| Day of year of date A | 计算日期A在一年中的某天(1-365)。 | A |
| Day of month of date A | 计算日期A在一个月中的某天(1-31)。 | A |
| Day of week of date A | 计算星期几(1-7)。 | A |
| Week of year of date A | 计算一年中的星期(1-54)。 | A |
| ISO8601 Week of year of date A | 计算一年中的星期ISO8601样式(1-53)。 | A |
| ISO8601 Year of date A | 计算年份ISO8601样式。 | A |
| Byte to hex encode of string A | 将字符串中的字节编码为十六进制表示形式。 | A |
| Hex encode of string A | 以自己的十六进制表示形式编码字符串。 | A |
| Char to hex encode of string A | 将字符串中的字符编码为十六进制表示形式。 | A |
| Hex decode of string A | 从其十六进制表示形式解码字符串(当A为奇数长度时,添加前导0)。 | A |
| Checksum of a file A using CRC-32 | 使用CRC-32计算文件的校验和。 | A |
| Checksum of a file A using Adler-32 | 使用Adler-32计算文件的校验和。 | A |
| Checksum of a file A using MD5 | 使用MD5计算文件的校验和。 | A |
| Checksum of a file A using SHA-1 | 使用SHA-1计算文件的校验和。 | A |
| Levenshtein Distance (Source A and Target B) | 计算Levenshtein距离:http://en.wikipedia.org/wiki/Levenshtein_distance | A and B |
| Metaphone of A (Phonetics) | 计算单词A的变音位(语音学),用于将单词按照英文发音进行索引。详见:http : //en.wikipedia.org/wiki/Metaphone | A |
| Double metaphone of A | 计算A的双重音位:http : //en.wikipedia.org/wiki/Double_Metaphone | A |
| Absolute value ABS(A) | 计算A的绝对值。 | A |
| Remove time from a date A | 删除A的时间值。 | A |
| Date A - Date B (in days) | 计算A日期字段和B日期字段之间的天数差异。 | A and B |
| A + B + C | A加B加C。 | A, B, and C |
| First letter of each word of a string A in capital | 转换字符串中每个单词的第一个字母。 | A |
| UpperCase of a string A | 将字符串转换为大写。 | A |
| LowerCase of a string A | 将字符串转换为小写。 | A |
| Mask XML content from string A | 转义XML内容;用&value替换字符。 | A |
| Protect (CDATA) XML content from string A | 指示XML字符串是常规字符数据,而不是非字符数据或具有更特定的受限结构的字符数据。给定的字符串将包含在<![CDATA [String]]>中。 | A |
| Remove CR from a string A | 从字符串中删除回车符。 | A |
| Remove LF from a string A | 从字符串中删除换行符。 | A |
| Remove CRLF from a string A | 从字符串中删除回车符/换行符。 | A |
| Remove TAB from a string A | 从字符串中删除制表符。 | A |
| Return only digits from string A | 仅输出仅输出字符串中的数字(0-9)。 | A |
| Remove digits from string A | 从字符串中删除所有数字(0-9)。 | A |
| Return the length of a string A | 返回字符串的长度。 | A |
| Load file content in binary | 将给定文件的内容(在字段A中)加载为二进制数据类型(例如图片)。 | A |
| Add time B to date A | 将时间添加到日期,将日期和时间作为一个值返回。 | A and B |
| Quarter of date A | 返回日期的季度(1到4)。 | A |
| variable substitution in string A | 将变量替换为字符串。 | A |
| Unescape XML content | 从字符串取消转义XML内容。 | A |
| Escape HTML content | 在字符串中转义HTML。 | A |
| Unescape HTML content | 在字符串中取消转义HTML。 | A |
| Escape SQL content | 转义字符串中的字符以适合传递给SQL查询。 | A |
| Date A - Date B (working days) | 计算日期字段A和日期字段B之间的差异(仅工作日为星期一至星期五)。 | A and B |
| Date A + B Months | 在日期字段A中添加B个月。 | A |
| Check if an XML file A is well formed | 验证XML文件输入。 | A |
| Check if an XML string A is well formed | 验证XML字符串输入。 | A |
| Get encoding of file A | 猜测给定文件的最佳编码(UTF-8)。 | A |
| Dameraulevenshtein distance between String A and String B | 计算字符串之间的Dameraulevenshtein距离:http : //en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance | A and B |
| NeedlemanWunsch distance between String A and String B | 计算字符串之间的NeedlemanWunsch距离:http : //en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm | A and B |
| Jaro similitude between String A and String B | 返回两个字符串之间的Jaro相似系数。 | A and B |
| JaroWinkler similitude between String A and String B | 返回两个字符串之间的Jaro相似系数:http : //en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance | A and B |
| SoundEx of String A | 将字符串编码为Soundex值。 | A |
| RefinedSoundEx of String A | 检索给定字符串对象的RefinedSoundEx代码。注意:Metaphone,Double Metaphone, Soundex和RefinedSoundEx:这些算法都是利用单词的发音来做匹配,也称为语音算法。这些语音算法的缺点是以英语为基础,所以基本不能用于法语,西班牙语,荷兰语等其他语种。 | A |
| Date A + B Hours | 在日期字段A中添加B小时 | A and B |
| Date A + B Minutes | 在日期字段A中添加B分钟 | A and B |
| Date A - Date B (milliseconds) | 从日期字段A减去B毫秒 | A and B |
| Date A - Date B (seconds) | 从日期字段A减去B秒 | A and B |
| Date A - Date B (minutes) | 从日期字段A减去B分钟 | A and B |
| Date A - Date B (hours) | 从日期字段A中减去B小时 | A and B |
| Hour of Day of Date A | 提取给定日期的小时部分 | A |
| Minute of Hour of Date A | 提取给定日期的分钟部分 | A |
| Second of Hour of Date A | 提取给定日期的秒部分 | A |
案例如下:
从表中输入数据;然后使用计算器对绩效和总薪资进行计算(总薪资=(薪资/2) + *绩效/100* (薪资/2) );然后对总薪资进行数值范围处理;最后设置字段值。具体操作如下:
表输入设置及数据预览(需要提前将链路执行成功才能预览数据):
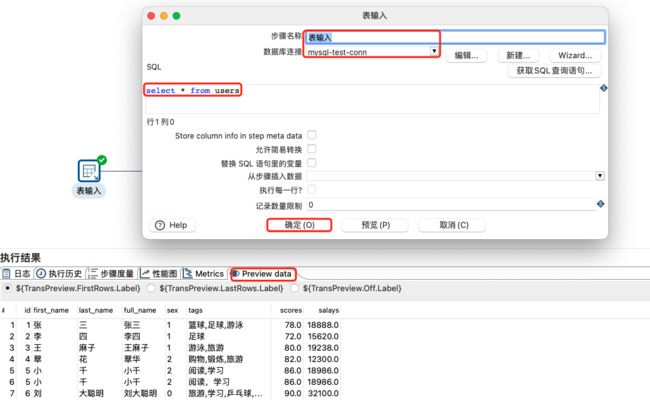
对数据进行计算器处理:
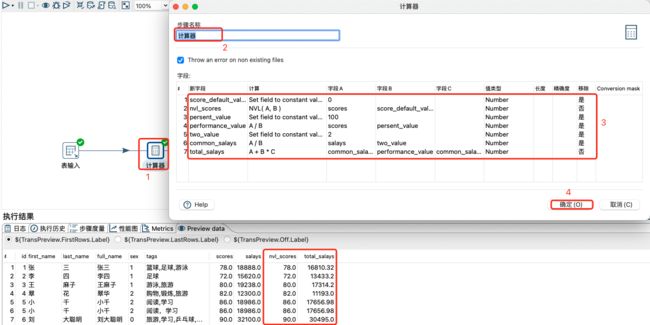
设置数值范围:
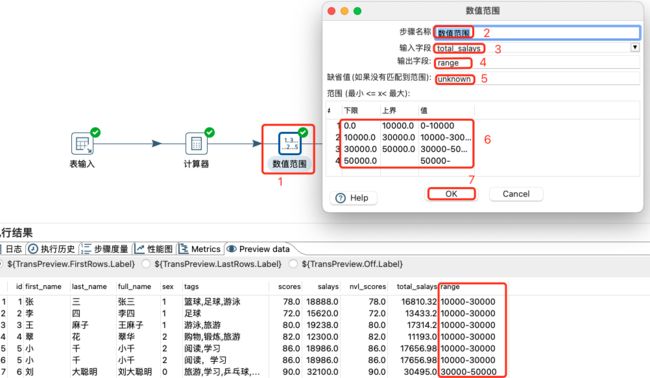
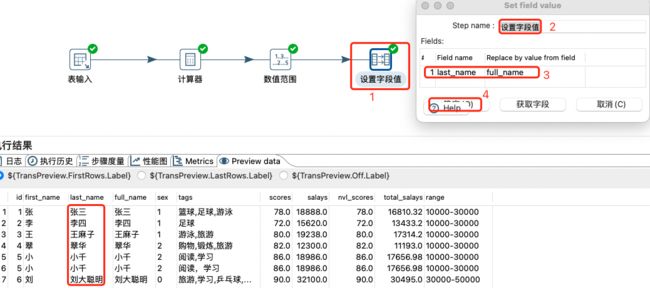
设置字段值:
2.3.4 列拆分为多行
列拆分为多行就是把某个字段按照指定分隔符拆分成多行数据,同时可以输出行号,类似于SQL中的炸裂函数。
配置表输入及数据预览:
配置列拆分为多行及数据预览:
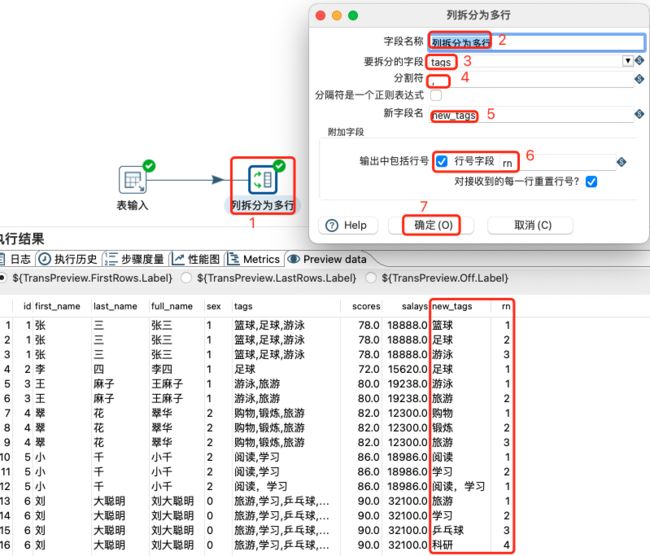
2.3.5 行转列-列转行-扁平化
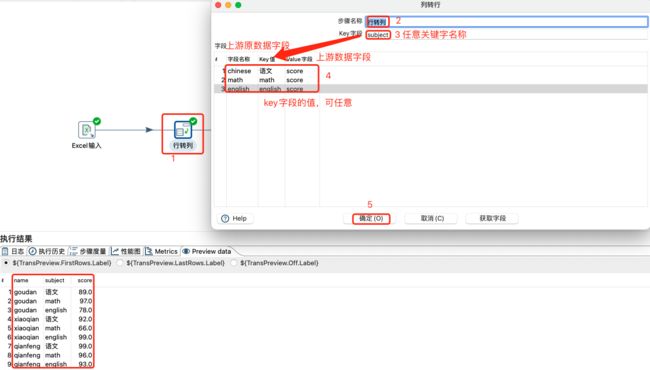
行转列是将原本一行多列转换成多行一列,不需要分组,只需要按照规则转换即可。
列转行是将原本的一列多行转换成一行多列,必须要进行分组,将组内一列多行数据转换为一行多列。
扁平化是把同一组的多行数据合并为一行。
注意:
- 扁平化只有数据流的同类数据数据行记录一致的情况才可使用。
- 扁平化数据流必须进行排序,否则结果会不正确。
excel数据输入、工作表设置、字段设置和数据预览:
工作表输入为sheet1,字段为预览数据显示的所有字段,不再截图。
行转列设置及数据预览:
列转行设置及数据预览:

数据选择及预览:
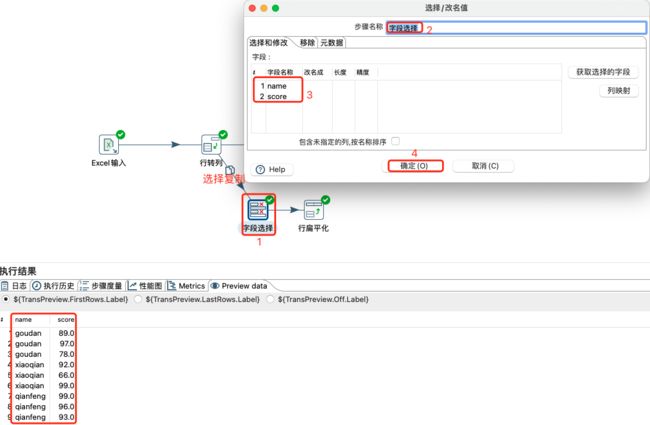
扁平化设置和数据预览:
3.3 数据输出
数据输出是ETL中重要环节,相当于L(装载)操作,kettle支持丰富的数据输出组件。常用的输出组件如下:
- 文件类型
- Excel输出
- JSON output
- SQL文件输出
- XML output
- 文本文件输出
- 数据库类型
- 数据同步
- 表输出
- 插入/更新
- 删除
3.3.1 文件类型输出
文件类型的数据输出主要以将数据存储为响应格式的文件为主。对应格式为:
- Excel输出:将上游数据输出到excel格式的文件中,默认后缀为xls。
- JSON output:将上游数据输出到json格式的文件中,默认后缀为js。
- SQL文件输出:将上游数据输出成SQL插入语句的脚本,默认后缀为sql。
- XML output输出:将上游数据输出成XML格式的文件,默认后缀为xml。
- 文本文件输出:将上游数据输出成普通文本文件,默认后缀为txt。
所有文件类型的输出中,出了SQL文件输出不需要指定输出字段,其他均需要指定输出字段,其中除文本文件输出和XML output外,其它都不支持压缩输出。
表数据输入配置及数据预览:

excel输出设置:

JSON output输出设置:
SQL文件输出设置:

XML output设置:
文本文件输出设置:
3.3.2 表类型输出
表类型的输出也是数据输出中常见的一种输出形式,通常是将集成或者处理好的结果数据入库或者进行相关操作。
- 数据同步:将上游数据按照条件进行插入、更新和删除操作。常见的条件通常是在高级中设置,也必须设置,可以理解为插入更新的升级版本。
- 表输出:将上游数据按照指定字段输出到表中。没有所谓的更新、删除等操作。
- 插入/更新:将上游数据中符合条件的进行更新操作,不符合条件的则进行插入操作。常见的条件就是判断表中的 某字段 和流(上一个步骤的结果,可以理解为内存)中的 某字段 是否相等,相等则更新,反之,则插入。该方式通常用于增了数据加载。
- 删除:将上游输入数据全部删除,要求指定所有字段,否则无法删除。
数据同步设置:

高级设置如下:
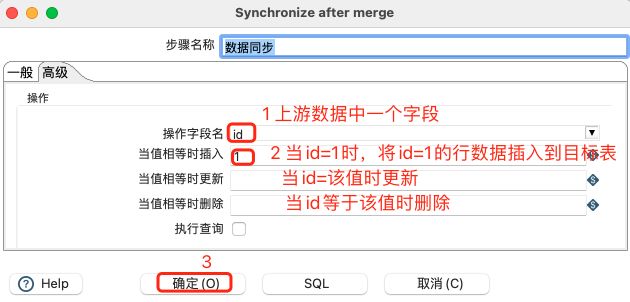
注意:
当插入、更新和删除都有对应值时,将是从上往下匹配。
表输出设置:
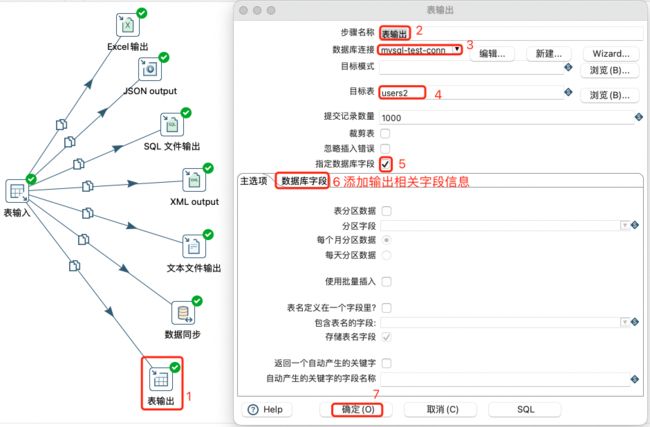
注意:
同步的数据乱码
原因是:查看了表输入的预览,数据是正常的,表输出未设置字符设置。
在配置mysql数据库连接时在【选项】中添加参数:
useCursorFetch=true
characterEncoding=utf8
mysql表输出的时候出现减速的原因可能是因为网络链接的属性设置
在配置mysql数据库连接时在【选项】中添加参数:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
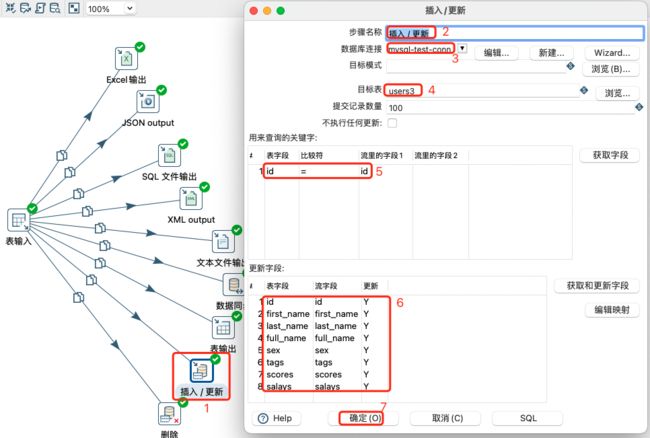
插入/更新设置:
删除设置:
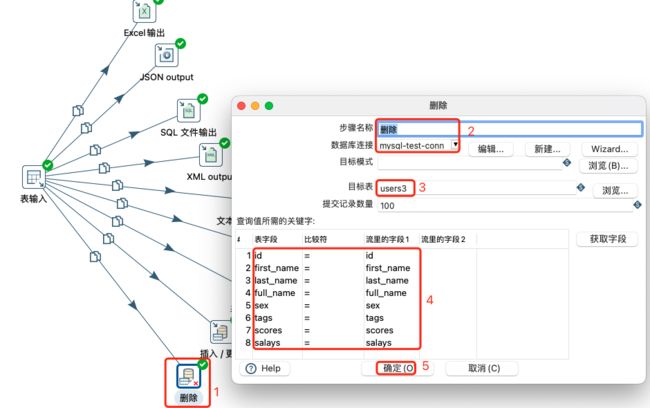
注意:
- 需要查询所有关键字,才能实现删除上游所有数据。
- 表中原有的数据不会被删除。
第四章 Kettle高阶操作
4.1 批量加载
通常情况下,对于几千条甚至几十万条记录的数据迁移而言,采取DML(即数据操纵语言)的INSERT语句能够很好地将数据迁移到目标数据库中。然而,当数据迁移量过于庞大时,就不能使用INSERT语句,因为执行INSERT、UPDATE以及DELETE语句的操作都会生成事务日志,事务日志的生成会减慢加载的速度,故需要针对数据采取批量加载操作。批量加载通常有多种方式:
-
采用表输出:再表输出的设置中设置批量为万级单位。
-
采用MySQL批量加载:采用MySQL得load local data infile方式来加载数据,也称之为桶装载,这种通常是在大规模或超大规模数据时候使用可以提升效率。
注意:
-
批量加载方式,在window和mac宿主机都是无法执行,会报错为: - MySQL 批量加载.0 - Loading local data is disabled; this must be enabled on both the client and server sides 。将其设置后也会任然报错。
-
由于对命名管道使用mkfifo,这实际上在Windows系统中不起作用。如果要操作,可以使用Windows的GNU核心实用程序(但这不是官方支持的)。
-
Kettle批量加载支持也很丰富,常用的有如下:
- Greenplum load
- infobright批量加载
- ingres VectorWise批量加载
- MonetDB批量加载
- MySQL批量加载
- Oracle批量加载
- PostgreSQL批量加载
- Teradata Fastload批量加载
- Teradata TDT bulk loader
- Vertica bulk loader
4.1.1 MySQL批量加载
MySQL的批量加载器将流数据从Kettle内部发送到一个命名的管道,使用“LOAD data INFILE ‘FIFO文件’ INTO TABLE …”进入数据库。
本案例采用7个字段,随机生成100万条记录,使用MySQL批量方式加载,批次大小为10000条,测试写时间。
-
设置或者确保MySQL数据库支持infile
编辑MySQL得配置文件 /etc/my.cf,添加或修改如下配置:
[mysqld] local_infile=1 [mysql] local_infile=1 [client] local_infile=1保存配置文件,重启MySQL服务。
查看local_infile变量状态为ON or OFF
[root@qianfeng01 data-integration]# vim /etc/my.cnf [root@qianfeng01 data-integration]# mysql -uroot -p mysql> show global variables like 'local_infile'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | local_infile | ON | +---------------+-------+ 1 row in set (0.01 sec) -
MySQL批量加载步骤
生成100万条记录设置:
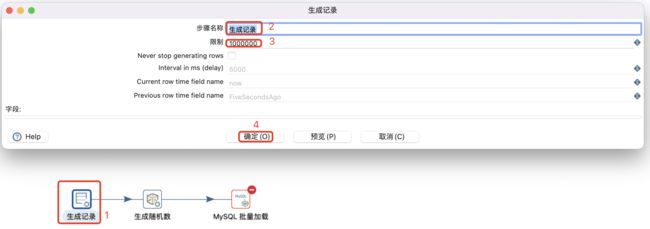
生成100万条随机数设置:
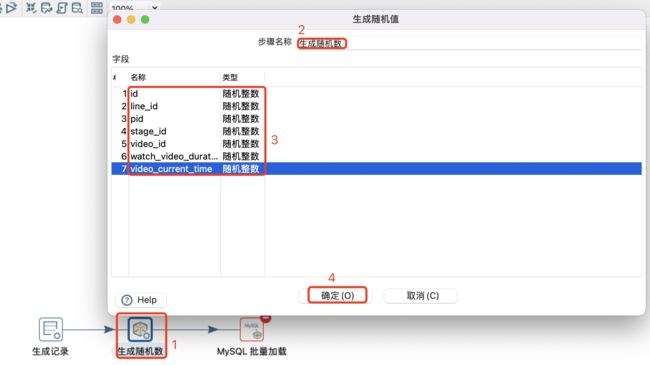
MySQL批量加载设置:
运行结果如下:
服务器桶装载 9s 2023/09/06 22:38:01 - Pan - 开始运行. 2023/09/06 22:38:01 - mysql-bucket-load-test - 为了转换解除补丁开始 [mysql-bucket-load-test] 2023/09/06 22:38:02 - MySQL 批量加载.0 - Creating fifo using this command - null 2023/09/06 22:38:02 - MySQL 批量加载.0 - Setting FIFO file permissings using this command - null 2023/09/06 22:38:02 - MySQL 批量加载.0 - Connected to null 2023/09/06 22:38:02 - MySQL 批量加载.0 - Starting the null bulk Load in a separate thread - LOAD DATA LOCAL INFILE '/tmp/fifo' IGNORE INTO TABLE test.student_watch_video_record FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\' (id,line_id,pid,stage_id,video_id,watch_video_duration,video_current_time); 2023/09/06 22:38:02 - MySQL 批量加载.0 - Opening fifo /tmp/fifo for writing. ................................. 2023/09/06 22:38:10 - MySQL 批量加载.0 - Starting the null bulk Load in a separate thread - LOAD DATA LOCAL INFILE '/tmp/fifo' IGNORE INTO TABLE test.student_watch_video_record FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\' (id,line_id,pid,stage_id,video_id,watch_video_duration,video_current_time); 2023/09/06 22:38:10 - MySQL 批量加载.0 - Opening fifo /tmp/fifo for writing. 2023/09/06 22:38:10 - 生成随机数.0 - 完成处理 (I=0, O=0, R=1000000, W=1000000, U=0, E=0) 2023/09/06 22:38:10 - MySQL 批量加载.0 - 完成处理 (I=0, O=1000000, R=1000000, W=1000000, U=0, E=0) 2023/09/06 22:38:10 - Carte - Installing timer to purge stale objects after 1440 minutes. 2023/09/06 22:38:10 - Pan - 完成! 2023/09/06 22:38:10 - Pan - 开始=2023/09/06 22:38:01.953, 停止=2023/09/06 22:38:10.953 2023/09/06 22:38:10 - Pan - 9 秒后处理结束. 2023/09/06 22:38:10 - mysql-bucket-load-test - 2023/09/06 22:38:10 - mysql-bucket-load-test - 进程 生成随机数.0 成功结束, 处理了 1000000 行. ( 111111 行/秒) 2023/09/06 22:38:10 - mysql-bucket-load-test - 进程 MySQL 批量加载.0 成功结束, 处理了 1000000 行. ( 111111 行/秒) 2023/09/06 22:38:10 - mysql-bucket-load-test - 进程 生成记录.0 成功结束, 处理了 1000000 行. ( 111111 行/秒)
4.1.2 表输出批量加载
本案例前置条件和MySQL批次加载一样,只是采用表输出来批次加载数据,测试表输出和批次加载的性能比。
生成100万条数据设置,生成随机数设置和MySQL批量加载设置一摸一样,复制即可。
表输出批量加载设置:
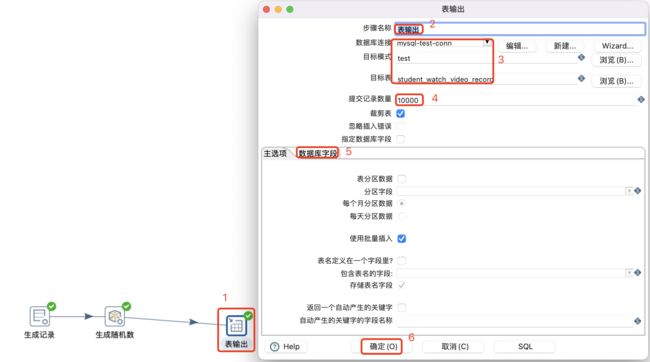
运行结果如下:
自己电脑10000批次 2m4s
2023/09/06 22:15:52 - Spoon - 正在打开转换 [mysql-bucket-load-test1]...
2023/09/06 22:15:52 - Spoon - 开始执行转换.
2023/09/06 22:15:52 - mysql-bucket-load-test1 - 为了转换解除补丁开始 [mysql-bucket-load-test1]
2023/09/06 22:15:53 - 表输出.0 - Connected to database [mysql-test-conn1] (commit=10000)
2023/09/06 22:15:55 - 生成记录.0 - 行号: 50000
2023/09/06 22:15:59 - 表输出.0 - linenr 50000
2023/09/06 22:16:02 - 生成记录.0 - 行号: 100000
...............
2023/09/06 22:17:53 - 表输出.0 - linenr 950000
2023/09/06 22:17:56 - 生成记录.0 - 行号: 1000000
2023/09/06 22:17:56 - 生成记录.0 - 完成处理 (I=0, O=0, R=0, W=1000000, U=0, E=0)
2023/09/06 22:17:57 - 生成随机数.0 - 完成处理 (I=0, O=0, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:17:59 - 表输出.0 - linenr 1000000
2023/09/06 22:17:59 - 表输出.0 - 完成处理 (I=0, O=1000000, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:17:59 - Spoon - 转换完成!!
自己电脑50000批次 2m8s
2023/09/06 22:20:34 - Spoon - 正在打开转换 [mysql-bucket-load-test1]...
2023/09/06 22:20:34 - Spoon - 开始执行转换.
2023/09/06 22:20:34 - mysql-bucket-load-test1 - 为了转换解除补丁开始 [mysql-bucket-load-test1]
2023/09/06 22:20:34 - 表输出.0 - Connected to database [mysql-test-conn1] (commit=50000)
2023/09/06 22:20:34 - 生成记录.0 - 行号: 50000
.....
2023/09/06 22:22:35 - 表输出.0 - linenr 950000
2023/09/06 22:22:35 - 生成记录.0 - 行号: 1000000
2023/09/06 22:22:35 - 生成记录.0 - 完成处理 (I=0, O=0, R=0, W=1000000, U=0, E=0)
2023/09/06 22:22:35 - 生成随机数.0 - 完成处理 (I=0, O=0, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:22:42 - 表输出.0 - linenr 1000000
2023/09/06 22:22:42 - 表输出.0 - 完成处理 (I=0, O=1000000, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:22:42 - Spoon - 转换完成!!
服务器10000批次 2m36s
2023/09/06 22:32:15 - Pan - 开始运行.
2023/09/06 22:32:16 - mysql-bucket-load-test1 - 为了转换解除补丁开始 [mysql-bucket-load-test1]
2023/09/06 22:32:16 - 表输出.0 - Connected to database [mysql-test-conn] (commit=10000)
2023/09/06 22:32:20 - 生成记录.0 - 行号: 50000
2023/09/06 22:32:25 - 表输出.0 - linenr 50000
2023/09/06 22:32:28 - 生成记录.0 - 行号: 100000
....
2023/09/06 22:34:44 - 表输出.0 - linenr 950000
2023/09/06 22:34:48 - 生成记录.0 - 行号: 1000000
2023/09/06 22:34:48 - 生成记录.0 - 完成处理 (I=0, O=0, R=0, W=1000000, U=0, E=0)
2023/09/06 22:34:49 - 生成随机数.0 - 完成处理 (I=0, O=0, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:34:52 - 表输出.0 - linenr 1000000
2023/09/06 22:34:52 - 表输出.0 - 完成处理 (I=0, O=1000000, R=1000000, W=1000000, U=0, E=0)
2023/09/06 22:34:52 - Carte - Installing timer to purge stale objects after 1440 minutes.
2023/09/06 22:34:52 - Pan - 完成!
2023/09/06 22:34:52 - Pan - 开始=2023/09/06 22:32:16.146, 停止=2023/09/06 22:34:52.903
2023/09/06 22:34:52 - Pan - Processing ended after 2 minutes and 36 seconds (156 seconds total).
2023/09/06 22:34:52 - mysql-bucket-load-test1 -
2023/09/06 22:34:52 - mysql-bucket-load-test1 - 进程 生成记录.0 成功结束, 处理了 1000000 行. ( 6410 行/秒)
2023/09/06 22:34:52 - mysql-bucket-load-test1 - 进程 生成随机数.0 成功结束, 处理了 1000000 行. ( 6410 行/秒)
2023/09/06 22:34:52 - mysql-bucket-load-test1 - 进程 表输出.0 成功结束, 处理了 1000000 行. ( 6410 行/秒)
4.2 Kettle流程
流程控件主要用来控制数据流程和数据流向。比如数据流的分支、空数据流检测、数据流阻塞和数据流终止等。常用的流程控件如下:
- Switch/case
- 检测空流
- 数据流优先级排序
- 识别流的最后一行
- 过滤记录
- 追加流
- 阻塞数据直到步骤都完成
- Blocking step
- 空操作(什么也不做)
- 终止
4.2.1 Switch/case流程
Switch/case实现了流行编程语言(如Java)中的switch/case语句,PDI实现根据指定字段中的比较值将一行数据路由到目标步骤。
表输入设置及数据预览:
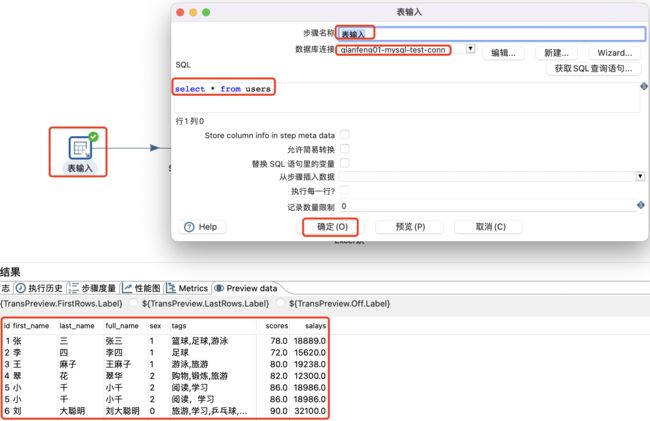
Switch/case设置:
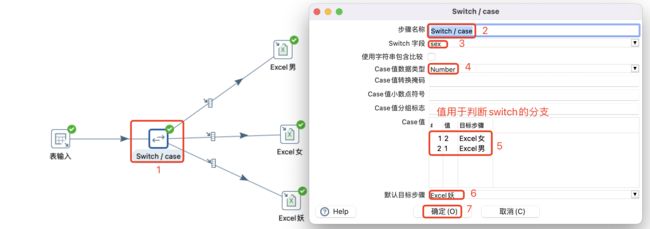
注意:
- Case值不能写大于,小于,不等于等表达式,只能写值。
- Case值目标步骤和默认目标步骤,必须要先连接Hop才能选择,或者连接好后自动添加。
Excel输出设置和连线:
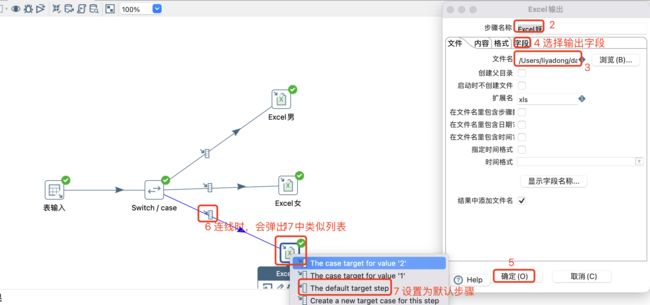
其他两个输出操作类似操作即可。
4.2.2 过滤记录
与Switch/case做对比的话,过滤记录相当于if-else,可以自定义输入一个判断条件,然后将数据流中的数据分为两路。
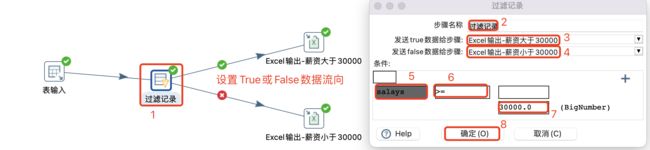
4.2.3 检测空流-空操作-终止
- 检测空流:如果输入流为空(即输入流不包含任何行),此步骤将输出一行。输出行将具有与输入行相同的字段,但所有字段值将为空(null)。如果输入流不为空,则不会输出任何内容。
- 空操作:不做任何事情。它的主要功能是作为测试目的的占位符。例如,要进行转换,至少需要两个相互连接的步骤,充当一个虚拟步骤。
- 终止:终止步骤可用于根据输入数据停止转换,对于错误处理特别有用。例如,可以使用此步骤,终止检测到错误后,转换将在指定的行数处停止处理。
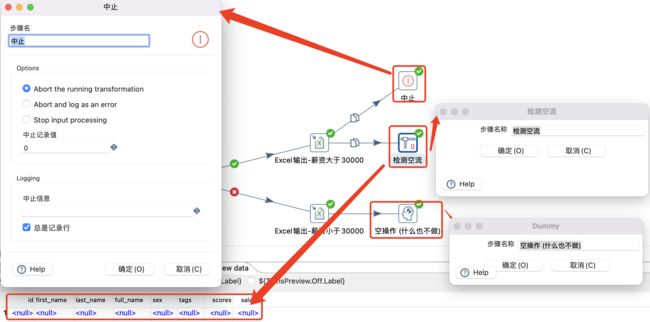
3.2.4 阻塞数据直到步骤都完成
阻塞只需等待对话框中指定的所有并行步骤完成,可以使用它来避免在转换步骤并行之间存在的自然并发性(并行性)。
注意:
当步骤(跳)之间的缓冲区已满时,这可能导致转换死锁。通常的方案是增加“行集中的行数”(设置→选项)或使用“阻塞”步骤来避免。
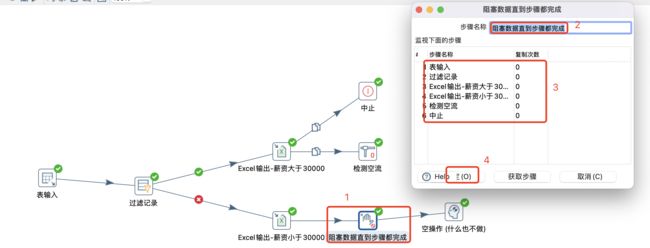
通过运行,可以观察到阻塞数据直到步骤都完成和空操作步骤是最后执行,说明这步骤及后续步骤被阻塞了。
4.3 Kettle脚本控件
脚本主要是通过写程序代码完成一些复杂的操作。ketlle提供了丰富的控件,常用如下:
- Java代码:主要是编写Java代码处理数据。
- Java Script代码:主要使用Java Script代码处理数据,包含很多数据类型的转换函数。
- 公式:相当于是提供一些数据类型的函数,将上游数据应用到这些函数,从而将数据进行处理。
- 执行SQL脚本:使用SQL代码进行数据处理。
- 执行SQL脚本(字段流替换):与执行SQL差不多,只是这里,采用从文件中去获取SQL代码。
- 正则表达式:将上游字段应用于正则表达式,然后将满足正则表达式的数据组按需求提取数据。
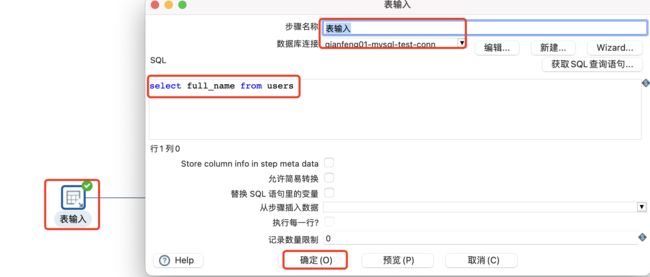
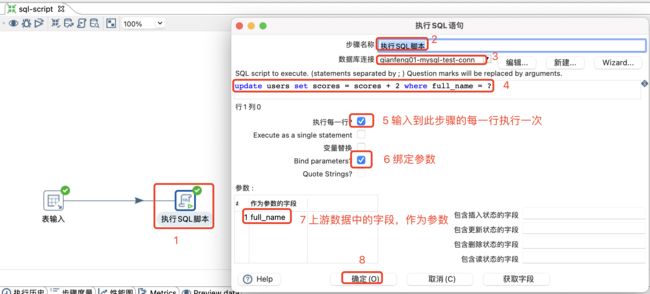
4.3.1 执行SQL脚本
可以使用以下两种方法执行SQL脚本:
-
在转换的初始化阶段执行一次SQL脚本。
-
对于发送到此步骤的每个输入行执行一次SQL脚本。
注意:
-
由于此步骤的脚本是动态操作,不使用准备好的SQL语句,这可能会对转换性能产生不利影响。如果需要最佳性能,那么Pentaho建议使用专用步骤,如表输出、表输入、更新或删除。
-
如果转换意外停止,请验证是否对每一行执行了Execute ?如果执行每一行选项被选中,要使SQL在转换的初始化阶段启动。
-
-
设置表输入
-
对于发送到此步骤的每个输入行执行一次SQL脚本
-
执行一次SQL脚本
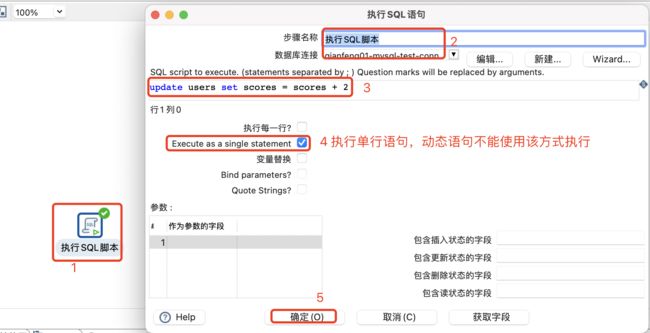
注意:
动态的语句通常是有占位符和参数绑定,也需要勾选绑定参数。否则,只有占位符和参数,但没有勾选参数绑定也会报错。
4.3.2 Java代码介绍
Java代码步骤,属于脚本类别转换,是指对上游数据使用Java代码处理之后往下游发送。Java代码步骤,适用于熟悉Java语言的开发人员,用好这个步骤,需要对类、接口、多线程等语言相关知识有所掌握,并且需要对Kettle的基础框架有所理解。Kettle转换的执行,通常有以下三个核心的阶段:
-
初始化
Kettle转换在执行前,会有一个各步骤的初始化动作,为步骤执行前的准备工作创造机会。为提高初始化的性能,Kettle为每个步骤启用一个初始化线程,从而并行完成所有步骤的初始化。初始化的主要内容就是调用一次步骤的以下方法:
public boolean init(StepMetaInterface stepMetaInterface, StepDataInterface stepDataInterface) { return parent.initImpl(stepMetaInterface, stepDataInterface); }此方法包含两个参数。其中,meta为元数据,data为数据。如果返回true,那么代表初始化成功,否则代表初始化失败。任何一个步骤初始化失败,都会导致整个转换停止执行(在停止前,会调用每一个转换的资源释放方法dispose)。
-
执行
执行阶段是每一个步骤实现特定操作的时候,操作通常就是指Main函数中的行数据处理,行处理核心代码如下:
/** 从输入行集中判断是否第一行,判断目的是将其标识,第一行需要特定处理,然后将新的行放入输出行集中。 从输入行集中取数据可以调用getRow方法。 如果getRow方法返回值不为null,则步骤应将该行数据进行处理,并调用putRow方法将处理结果存入输出行集,然后返回true,以继续为下一行输入数据处理提供机会。 如果getRow方法返回null,代表输入行集已经处理完毕,这时可以调用setOutputDone,标识本步骤执行完毕,并返回false,以结束本工作线程的执行。 */ public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException { if (first) { first = false; } Object[] r = getRow(); if (r == null) { setOutputDone(); return false; } r = createOutputRow(r, data.outputRowMeta.size()); putRow(data.outputRowMeta, r); return true; }为提高效率,Kettle为每一个步骤单独启动一个工作线程来执行任务。线程一直在执行步骤的processRow方法,直到出现以下情况:
- processRow方法返回false,代表工作已经正常完成
- isStopped方法返回true,代表步骤被强制停止
- processRow方法执行过程中出现异常,代表执行过程中出现错误,Kettle将调用stopAll方法,从而导致整个转换的所有工作线程停止执行。
-
资源释放
Kettle为每一个步骤单独启动一个工作线程来执行任务,不管工作线程是正常执行完毕还是异常执行完毕,最终会调用dispose方法来释放资源。方法如下:
public void dispose(StepMetaInterface smi, StepDataInterface sdi) { parent.disposeImpl(smi, sdi); }
通常情况下,我们只需要重写Main中的processRow()方法即可满足需求,如果用到了一些重量级的资源,最好在init方法中初始化,并在dispose方法中释放。
由于Kettle使用Janino框架为自定义Java转换步骤类动态定义了类名,并指定父类为TransformClassBase,所以在编写Java代码时,只需要提供类的内容即可,无需class声明。既然自动建立了父类,那么父类的成员、方法等都可以在代码中重用。
父类常用的成员包括以下三个实例:
- parent:代表容器对象
- meta:代表容器元数据对象
- data:代表容器数据对象
常用的方法包括:
- getRow:从输入行集中取一行数据
- putRow:存一行数据到输出行集
- stopAll:停止所有工作线程
- setOutputDone:标记本步骤工作完成
- logBasic:输出基本日志
- logError:输出错误日志
- getInputRowMeta:得到输入行的元数据
- createOutputRow:创建一个输出行数据
其实,常用的方法,基本上都在Java代码步骤属性对话框左侧Code Snippits中,如下图所示:
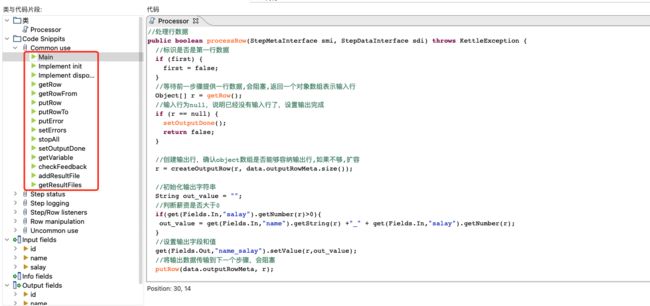
一般情况下,可以双击其中的Main节点,从processRow方法的重写开始,需要其他代码时,在左侧找到对应代码块,双击即可加入。
4.3.3 Java代码案例一
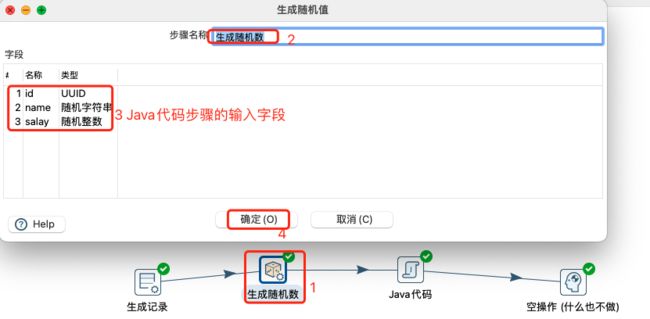
生成100行随机数,然后根据salay字段,判断其值大于0,则输出,否则输出为空。
生成100行随机数设置:
Java代码逻辑、设置及数据预览:
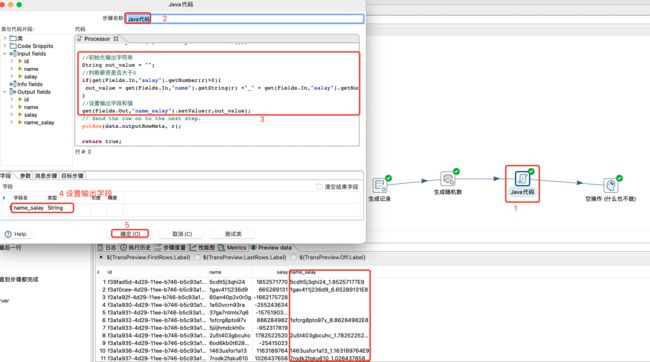
上述Java代码完整如下:
//处理行数据
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
//标识是否是第一行数据
if (first) {
first = false;
}
//等待前一步骤提供一行数据,会阻塞,返回一个对象数组表示输入行
Object[] r = getRow();
//输入行为null,说明已经没有输入行了,设置输出完成
if (r == null) {
setOutputDone();
return false;
}
//创建输出行,确认object数组是否能够容纳输出行,如果不够,扩容
r = createOutputRow(r, data.outputRowMeta.size());
//初始化输出字符串
String out_value = "";
//判断薪资是否大于0
if(get(Fields.In,"salay").getNumber(r)>0){
out_value = get(Fields.In,"name").getString(r) +"_" + get(Fields.In,"salay").getNumber(r);
}
//设置输出字段和值
get(Fields.Out,"name_salay").setValue(r,out_value);
//将输出数据传输到下一个步骤,会阻塞
putRow(data.outputRowMeta, r);
//返回行数据处理是否成功
return true;
}
注意:
- get(Fields.In,“name”):Fields.In代表输入;这个"name"从前一个步骤获取,通常根据上游字段获取即可,当然,也可以在这个步骤下方的参数中设置,设置如:xx,将代码改为get(Fields.In,xx);
- get(Fields.Out, “name_salay”) :Fields.Out代表输出;这个"name_salay"就是下方的字段中设置的name_salay。
- 输入输出字段名都可以在下方的参数设置,用getParameter(“name”)获取到name的值。
4.3.4 Java代码写Kafka
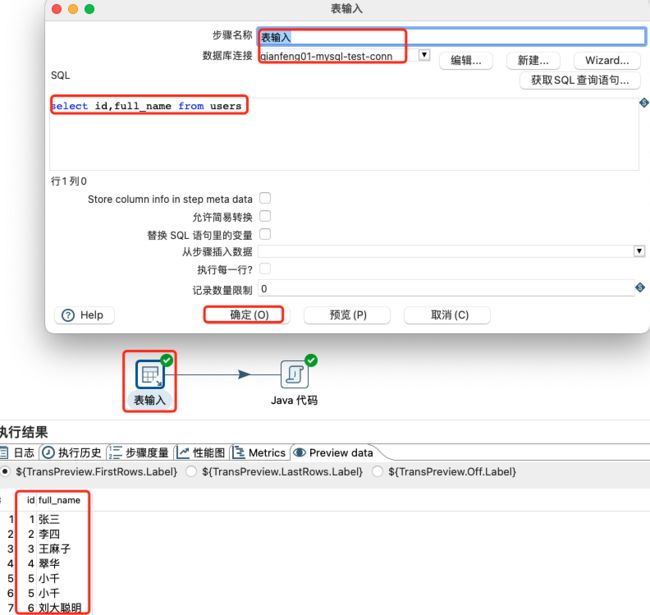
读取MySQL中表输入数据,然后将其字段进行拼接,然后写入kafka中的kettle-test主题。
表输入设置及数据预览:
Java代码写Kafka配置:
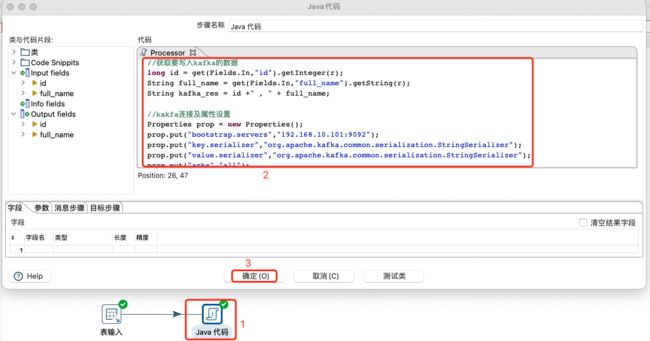
完整代码如下:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r = createOutputRow(r, data.outputRowMeta.size());
//获取要写入kafka的数据
long id = get(Fields.In,"id").getInteger(r);
String full_name = get(Fields.In,"full_name").getString(r);
String kafka_res = id +" , " + full_name;
//kakfa连接及属性设置
Properties prop = new Properties();
prop.put("bootstrap.servers","192.168.10.101:9092");
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("acks","all");
prop.put("retries",0);
prop.put("batch.size",16384);
prop.put("linger.ms",1);
prop.put("buffer.memory",33554432);
//写kafka
String topic ="kettle-test";
KafkaProducer producer = new KafkaProducer(prop);
producer.send(new ProducerRecord(topic,kafka_res));
//关闭
producer.close();
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
测试结果如下:
#消费kafka对应的主题数据
[root@qianfeng01 kafka_2.12-2.4.1]# ./bin/kafka-console-consumer.sh --bootstrap-server qianfeng01:9092 --topic kettle-test
1 , 张三
2 , 李四
3 , 王麻子
4 , 翠华
5 , 小千
5 , 小千
6 , 刘大聪明
注意:
该操作不需要添加kafka的依赖,因为本身已经内置kafka的客户端包,默认客户端版本为0.10.2.2。
4.4 Kettle查询控件
查询控件主要是查询数据源里面的数据,并将其合并到主数据流中。常见的查询控件:
- HTTP client
- HTTP post
- REST client
- 执行动态SQL
- 数据库查询
- 数据库连接
- 检查文件是否存在
- 检查表是否存在
- 流查询
- 调用DB存储过程
4.4.1 HTTP client 和 REST client
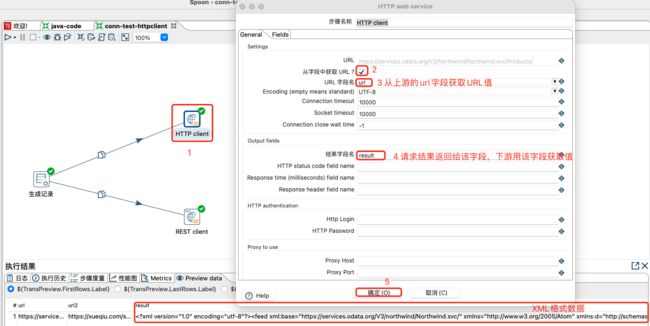
给定2个url,然后将其数据使用http和rest方式请求出来,后续根据数据类型,可以使用XML或JSON作为输入等。两个url分别为:
url(XML格式数据):https://services.odata.org/V3/Northwind/Northwind.svc/Products/
url2(JSON格式数据):https://xueqiu.com/service/v5/stock/preipo/cn/query?type=subscribe&order_by=onl_subbeg_date&order=asc&page=1&size=10&_=1626884306432
设置两个URL的常量及数据预览:

HTTP client查询设置及数据预览:
REST client设置及数据预览:
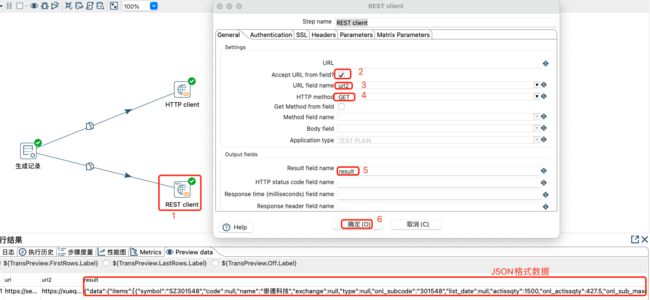
无论HTTP还是REST查询出来的数据,都会继续对接下游相应格式的输入数据类型,比如:JSON input 或 Get data from XML 等输入,进行数据的提取等操作。
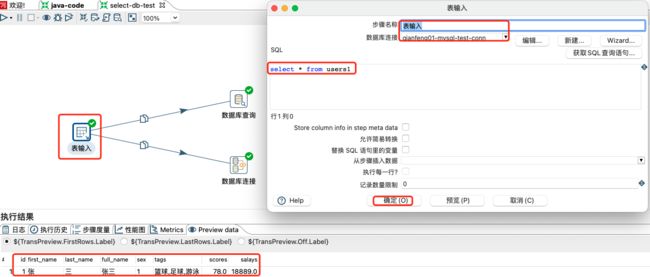
4.4.2 数据库查询和数据库连接
数据库查询:指从数据库里面查询出数据,然后跟数据流中的数据进行左连接的一个过程。左连接是指数据流为左,数据查询为右,即数据流中原本的数据全部有,但是数据库查询控件查询出来的数据不一定全部会列出,只能按照输入的匹配条件来进行关联。该方式不能写SQL,直接是数据流结果和数据查询左连接。
数据库连接:Database Join指从数据库里面查询的数据和上游的数据进行笛卡尔积查询(SQL不加任何过滤条件时),可以使用SQL,SQL可以使用占位符号,同时允许上游的输出作为下游的参数来查询出最终数据。
表输入设置及数据预览:
数据查询设置及预览:

数据库连接设置及数据预览:
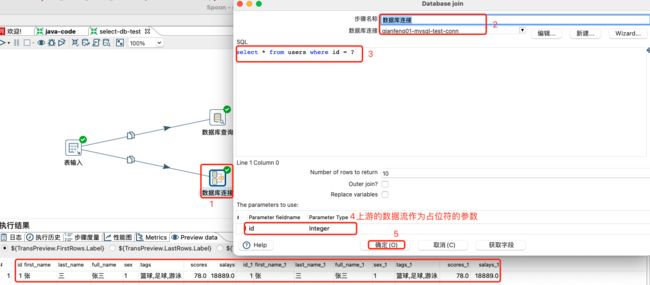
注意:
- 将数据库连接中SQL的过滤条件和where都去除掉,则查询出来的数据就是笛卡尔积。
- 数据库连接中SQL允许多表连接查询。
4.4.3 流查询
流查询控件就是查询两条数据流中的数据,然后按照指定的字段做等值匹配。同时,流查询在查询前把数据都加载到内存中,并且只能进行等值查询。
流查询设置及数据预览:
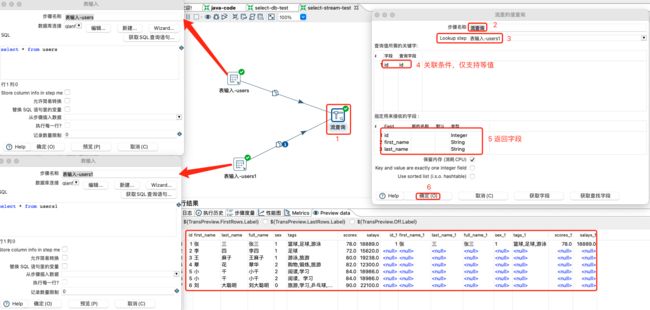
注意:
当Lookup step源自一个表时,请考虑使用Database Lookup步骤。在这种情况下,使用Database Lookup步骤并启用预加载缓存的表中的所有数据选项会更快。
4.5 Kettle连接控件
连接控件主要是将多个数据集通过关键字进行连接成一个数据集。kettle提供多种连接控件:
- Multiway merge join:多路合并join,支持多路上游数据流按照指定key进行连接,提供inner和full outer两种连接方式。
- XML join:将两个XML数据集进行连接。
- 合并记录:将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。
- 排序合并:
- 记录关联(笛卡尔积输出):
- 记录集连接:和Multiway merge join类似,该连接只支持2路数据集进行连接,连接条件更加灵活,支持的连接类型有Inner、left outer、right outer、full outer。
4.5.1 多路合并Join
多路合并join,支持多路上游数据流按照指定key进行连接,提供inner和full outer两种连接方式。
多路合并Join设置及数据预览:
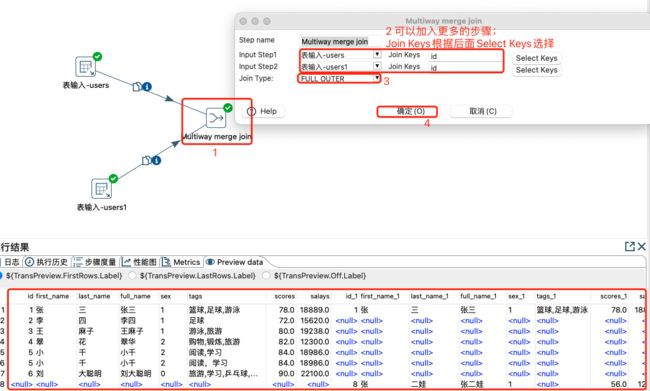
注意:
上游多路数据流也推荐排序,不排序可能结果不准。
4.5.2 合并记录
合并记录是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
注意:
旧数据和新数据需要事先按照关键字段排序,并且旧数据和新数据要有相同的字段名称。不排序会警告,同时数据结果可能不准确。
两份数据排序设置及新数据预览:
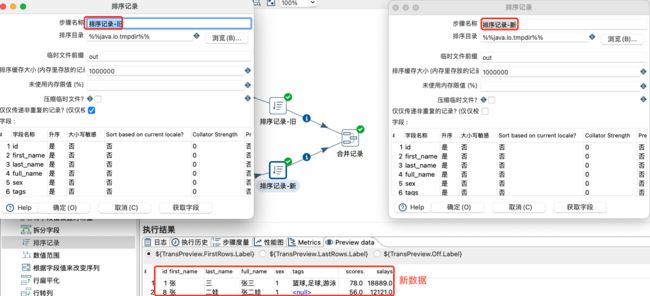
合并记录设置及数据预览:
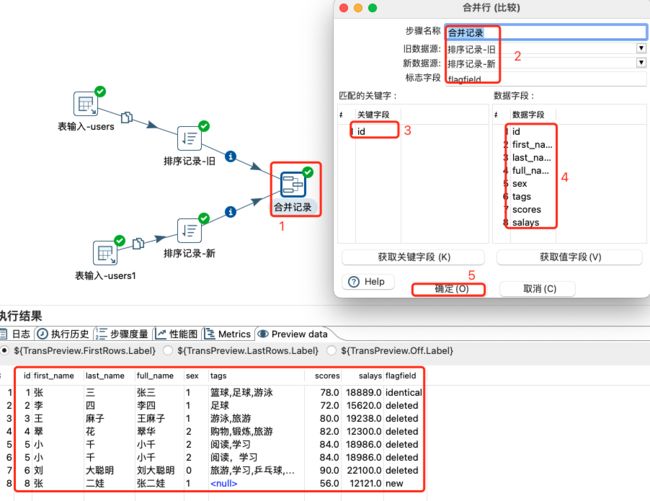
注意:
标识字段共计有4种,分别如下:
- identical : 旧数据和新数据一样
- changed: 新数据发生了变化
- new: 新数据中有而旧数据中没有的数据
- deleted:旧数据中有而新数据中没有的记录
4.5.3 记录集连接
记录集连接配置及数据预览:
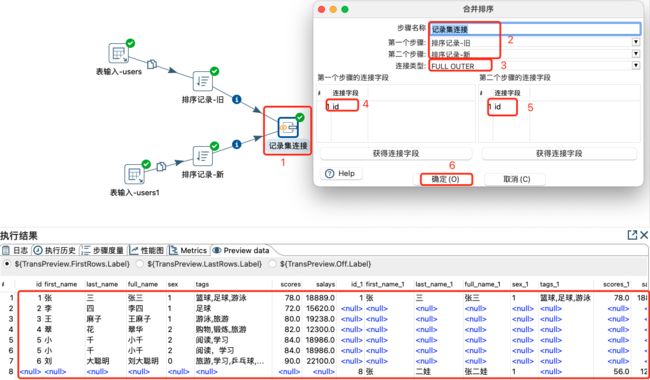
注意:
上游多路数据流也推荐排序,不排序可能结果不准。
4.6 Kettle检验控件
检验控件是对上游输出的数据进行检查,确保更加高质量的数据。kettle常用数据检验控件有:
- 数据检验
- 检验信用卡号码是否有效
- 检验邮件地址
数据检验:通常用于确保传入的数据具有一定的质量。验证可能由于各种原因而发生,例如,如果传入的数据质量不高,或数据和理想不一致。
- Data Validator步骤允许定义简单的规则来描述字段中的数据应该是什么样子。这可以是一个值范围、一个不同的值列表或数据长度。
- Data Validator允许在单个步骤中对传入数据应用无限数量的验证规则。
检验邮件地址:用于验证邮箱格式是否合规,通常不验证其可用性。
常量数据设置及预览:
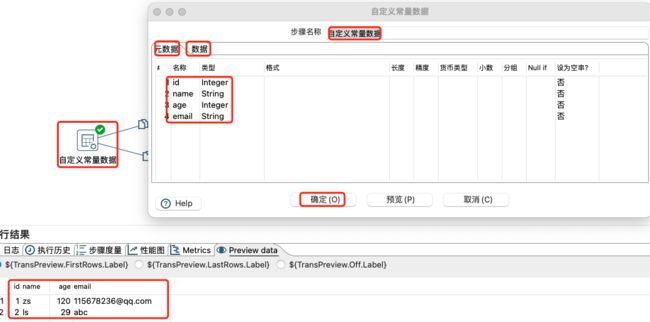
数据检验设置及预览:

注意:
数据校验不通过,将会报错,导致其他步骤也不能执行。
邮件地址检验设置及数据预览:
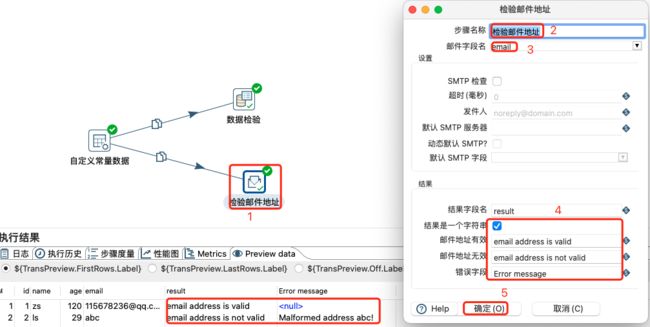
注意:
- 默认邮件检验结果是boolean类型,返回的是Y/N。
- 当结果为字符串时,正确的邮件地址错误信息为。
4.7 Kettle统计控件
分组:根据指定的字段或字段集合对源中的行进行分组。为每个组生成一个新行。它还可以为组生成一个或多个聚合值。
注意:
- Group By步骤是为排序输入而设计的。如果未对输入进行排序,则只有双连续行被正确分组。
- 如果在PDI之外对数据进行排序,则字段中数据的大小写敏感性可能会产生意想不到的分组结果。
内存分组:对来自源步骤的内存中的行进行分组。生成的行根据指定的字段或字段集合进行分组。为每个组生成一个新行。此步骤与Group By步骤不同,它处理内存中的所有行,并且设计用于处理未排序的输入。如果要分组的行数太大,内存无法容纳,则必须使用“排序行”和“按顺序分组”步骤的组合。
数据采样:允许在输入行的总数事先未知的情况下,从传入数据流中采样固定数量的行。步进采用均匀采样;所有进入的行都有相同的机会被选中。这个步骤在与ARFF输出步骤结合使用时特别有用,以便生成一个大小合适的数据集供数据挖掘使用。
分组、内存分组和数据采样步骤设置,及排序+分组数据预览:
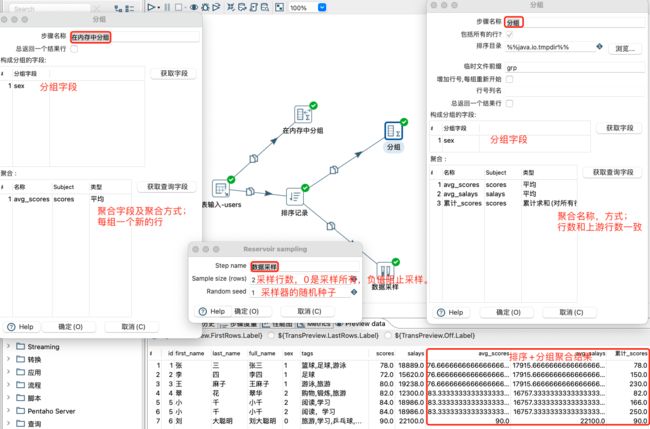
4.8 Ketlle映射控件
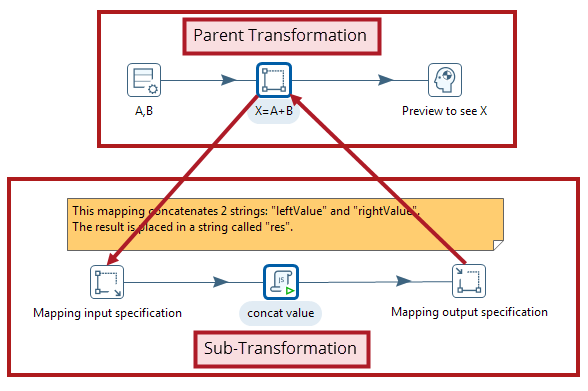
在构建转换时,通常会构建重复的一系列步骤,这个重复的部分可以转换成映射,即映射控件主要用于封装和重用。
映射是具有占位符输入和输出步骤的转换。映射转换是通过父转换中的mapping步骤执行的。因为父转换通过一个特定的步骤运行一个单独的转换,所以映射转换通常被称为子转换。子转换必须包含以下输入和输出步骤:
-
映射输入规范:一个占位符,映射期望来自父转换的输入。
-
映射输出规范:一个占位符,指示父转换可以从映射子转换读取数据。
当希望重用转换中的某个步骤序列时,请使用映射。下图说明了映射和父元素之间的关系:
映射(子转换)设置:
映射子转换通常在其上游需要加入映射输入规范(父转换的输入字段,由调用的父转换转换输入),在其下游添加映射输出规范(向调用的转换输出所有列,不做任何处理)。
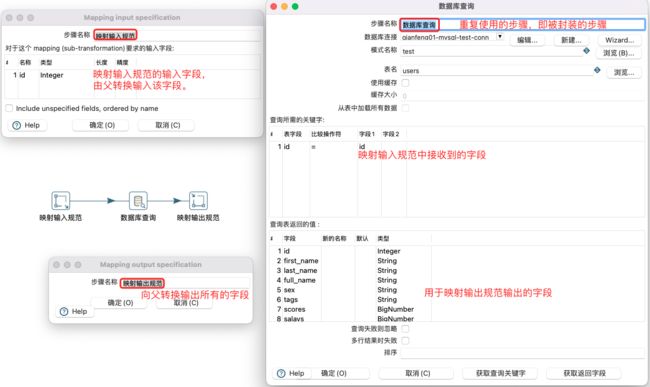
注意:
映射子转换不单独运行,需要其他转换来调用。
父转换(调用映射子转换)设置:
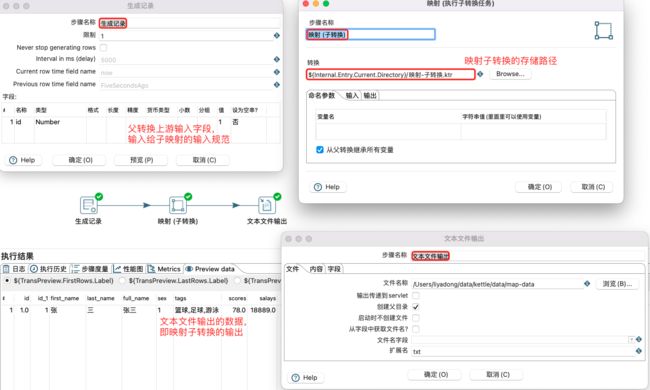
4.9 Kettle应用
发送邮件:该步骤使用SMTP服务器发送包含上一步数据的电子邮件。
注意:
邮件转换步骤类似于邮件作业条目,只是该步骤接收来自流字段的所有数据。
写日志:将该步骤或者上游的数据输出到日志信息中,该步骤主要用于开发或者测试阶段,一般不用于生产环境。
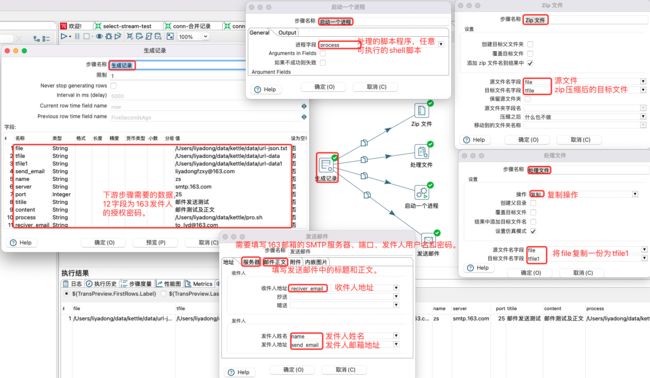
启动一个进程:可以使用Execute a process步骤在将要运行作业的主机上执行shell脚本。该步骤类似于作业条目Shell,但可以在转换中用于对每一行执行。
文件处理:对文件数据进行复制、删除和移动等处理。该步骤复制的时候是文件到文件。
Zip文件:对文件数据进行Zip压缩处理。该步骤需要给定数据文件。
Clone row:对上游数据进行克隆一份或者多份。
发送邮件:对该步骤中的数据发送邮件,一般对于重要数据偶使用,因为通常结果数据也不需要发送邮件。
克隆和写日志步骤设置,预览克隆数据:
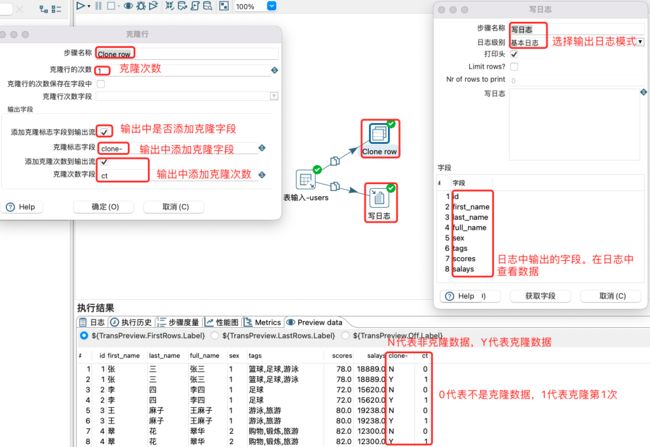
Zip文件、处理文件、启动一个进程和发送邮件步骤的设置:
4.11 Kettle整合大数据
4.11.1 Kettle整合大数据数据介绍
Kettle作为传统的ETL工具,通常需要将ETL数据与大数据组件交互,比如与HDFS、Hive、HBase和Spark等大数据组件集成,此时需要大数据相关组件支持,但因为Kettle因为独自是可以成体系,所以对大数据相关组件的兼容就不是特别好,通常都需要自己去做一些配置即可完成和大数据组件的整合。
Kettle目前支持大数据组件有:
- Avro input
- Avro output
- Cassandra input
- cassandra output
- HBase input
- HBase output
- Hadoop file input
- Hadoop file output
- MapReduce input
- MapReduce output
- ORC input
- ORC output
- Parquet input
- Parquet output
4.11.2 Kettle整合Hadoop与Hive
-
环境
- Jdk:1.8.0_321
- Hadoop:apache hadoop-3.3.1
- Hive:apche hive-3.1.2
-
需求
将hive表的数据输出到hdfs
- 修改解压目录下的/opt/installed/data-integration/plugins/pentaho-big-data-plugin/plugin.properties
active.hadoop.configuration=hdp30
- 将hadoop/hive配置目录下的*-site.xml拷贝到指定目录下
/opt/installed/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp30
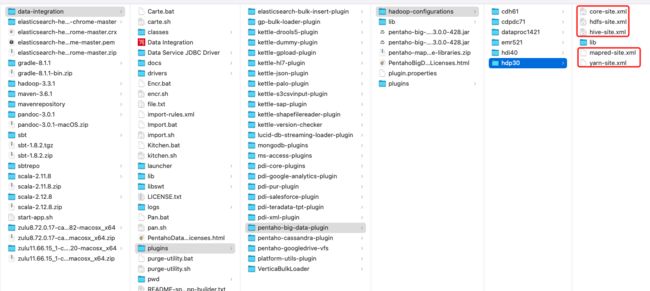
-
将Hive的安装目录下的依赖包拷贝到kettle安装目录下的lib或者软连接到lib目录
╭liyadong at ~ ╰$ ln -s /Users/liyadong/Desktop/lib/*.jar /opt/installed/data-integration/lib ln: /opt/installed/data-integration/lib/commons-cli-1.2.jar: File exists ln: /opt/installed/data-integration/lib/commons-dbcp-1.4.jar: File exists ln: /opt/installed/data-integration/lib/commons-lang-2.6.jar: File exists ln: /opt/installed/data-integration/lib/commons-math3-3.6.1.jar: File exists ln: /opt/installed/data-integration/lib/javassist-3.20.0-GA.jar: File exists ln: /opt/installed/data-integration/lib/javax.servlet-api-3.1.0.jar: File exists ln: /opt/installed/data-integration/lib/libthrift-0.9.3.jar: File exists ln: /opt/installed/data-integration/lib/mysql-connector-java-8.0.26.jar: File exists注意:
… File exists存在没有问题,证明原本包里面有这个jar包。如果拷贝方式,那就跳过即可。
-
启动启动hdfs,yarn集群的所有进程,启动hiveserver2服务
-
进入beeline,查看10000端口开启情况
-
创建两张表dept和emp
DROP DATABASE IF EXISTS hue CASCADE;
CREATE DATABASE IF NOT EXISTS hue;
CREATE TABLE hue.dept(
deptno int,
dname string,
loc string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
CREATE TABLE hue.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
- 插入数据
insert into hue.dept values(10,'Java','Beijing'),(20,'Bigdata','Shanghai'),(30,'Html5','Hangzhou'),(40,'UI','Chongqing');
insert into hue.emp values(7369,'qianfeng','CLERK',7902,'1980-12-17',800,NULL,20),(7499,'rock','SALESMAN',7698,'1980-12-17',1600,300,30),(7521,'lee','SALESMAN',7698,'1980-12-17',1250,500,30),(7566,'narudo','MANAGER',7839,'1980-12-17',2975,NULL,20);
- 按下图建立流程图

- 设置表输入,连接hive
1. 这里连接hive一定直接死翘翘。因为我们的cdh版本是5.7.6。我们使用的kettle默认的cdh版本5.14.0。所以,里面的某些jar包需要我们自己手动指定。
2. 第一先将kettle的D:\DevelopProgram\kettle\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh514下的*-site.xml使用服务器的配置文件替换
3. 修改D:\DevelopProgram\kettle\data-integration\plugins\pentaho-big-data-plugin目录下的plugins.properties文件:active.hadoop.configuration=cdh514
4. 下载cdh5.7.6的hadoop的jar和hive的jar,替换lib目录下的hive和hadoop
-
建立Hive连接如下
-
从Hive中读取数据,然后排序,然后连接的设置如下
-
设置Hadoop文件输出
-
保存并运行查看hdfs
4.12 Kettle Streaming
-
Streaming组件介绍
大数据中,数据源非常之多,有很多数据是在消息队列中,比如Kafka、JMS和MQTT等,此时就需要采用Streaming组件,去对接消息队列中的数据。不过,因为Kettle主打还是离线场景,目前Streaming部分应用还相对较少。
-
Kettle整合Kafka案例
将数据库表中的数据作为输入,然后写入到Kafka的主题中,其配置如下:
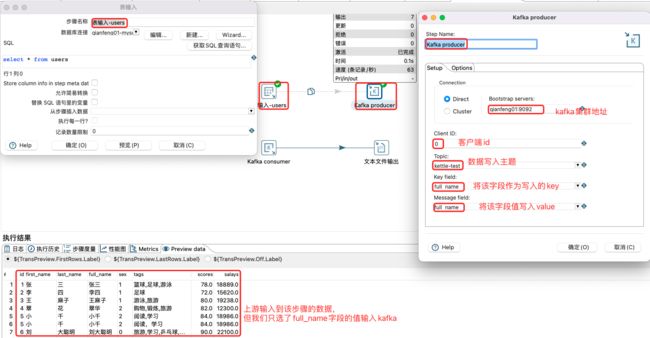
消费kafka的主题数据,然后将消费的数据输出到文本文件中子转换配置下(单独配置一个或者在Kafka consumer转换中新建一个保存成如下即可):
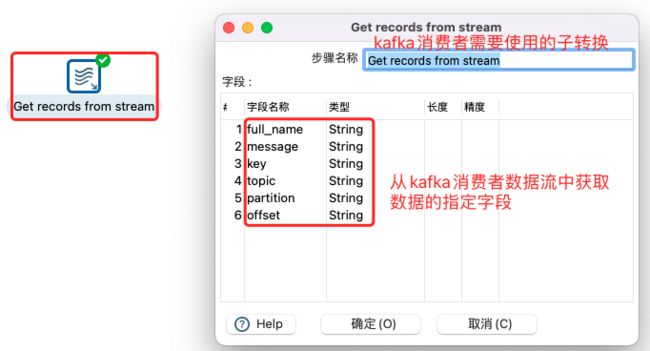

注意:
kafka消费输出到文本文件转换,由于kafka消费实时运行,所以输出结果只能kafka消费者结束或者转换停止才能将数据写入文本文件。即战时不支持实时回滚落地文件。
4.13 Kettle作业
-
作业介绍
大多数ETL项目都需要完成各种各样的维护工作。例如,如何传送文件;验证数据库表是否存在等等。而这些操作都是按照一定顺序完成。因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。下图是一个工作的例子。

-
作业项。作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。作业项的注意点。新步骤的名字应该是唯一的,但是作业项可以有影子拷贝。这样可以把一个作业项放在不同的位置。这些影子拷贝里的信息都是相同的,编辑一份拷贝,其他拷贝也会随之修改。在作业项之间可以传递一个结果对象(result object)。这个结果对象里包含了数据行,它们不是以流的方式来传递的。而是等一个作业项执行完了,再传递给下一个作业项。默认情况下,所有的作业项都是以串行方式执行的,只是在特殊情况下,以并行方式执行。
-
作业跳:作业之间的连线称为作业跳。作业里每个作业项的不同运行结果决定了作业的不同执行路径。对作业项的运行结果判断如下:
-
无条件执行:不论上一个作业项执行成功与否,下一个作业项都会执行。标识为,黑色的连线,上面有一个锁的图标

-
当运行结果为真时执行:标识为,绿色的连线,上面有一个钩号

-
当运行结果为假时执行:标识为,红色的连线,上面有一个红色的停止图标

-
-
-
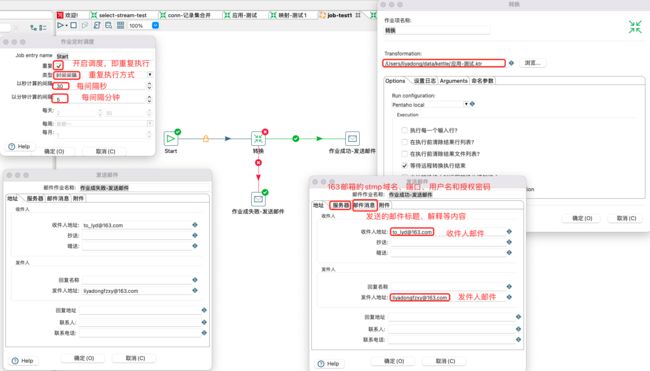
作业案例
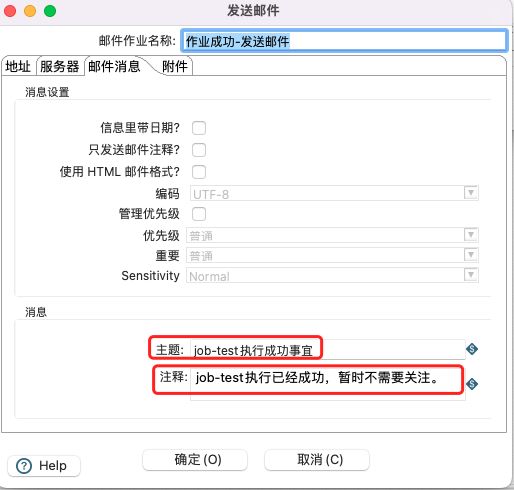
配置作业开始、转换和邮件告警:
邮件stmp服务器配置:

邮件消息配置:
4.14 Kettle调度
kettle作为一款ETL工具,主要负责将数据从源到ODS,或者在从ODS层处理至DWD层,负责数据的清洗、转换工作。kettle其实只有2个功能组合即转换和作业,转换负责组件间的协调配合,作业负责任务的执行,但是怎么能让kettle自动将任务跑起来,自己完成数据的清洗和转换。Kettle常用的作业调度有3种方式:
- 使用kettle自带的start组件调度
- 使用操作系统的crontab定时调度
- 自研或者三方平台的调度
4.14.1 Start任务调度
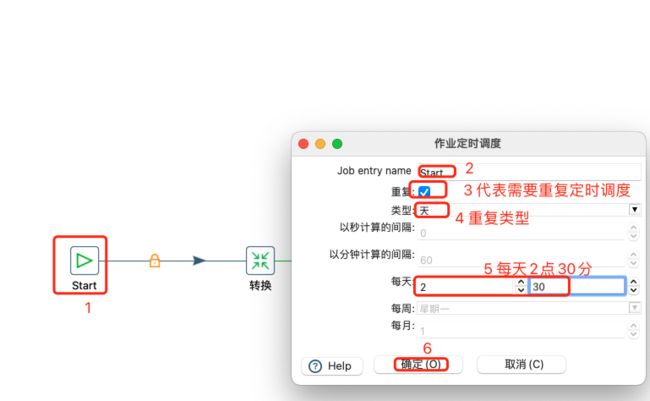
当刚接触kettle时,为了方便测试和演示作业的效果,常常通过Start组件来定时完成作业的调度。 在我作业里,我们选择通用,然后选择一个START组件,双击打开,就可以看到,START组件可以通过勾选重复,按照我们的要求来定时运行我们的作业。
每天2点30分定时任务定时调度设置如下:
Start调度,操作简单,随时可以监控到运行情况,但需要打开kettle软件才能运行,且长时间运行,会因为出现错误导致,定时任务失败,一般用于测试和调度读取CSV和EXCEL文件的数据源场景。
4.14.2 Crontab定时调度
Linux的crontab定时器来制作简易调度系统是一个比较简便的解决方案,针对小型简单的Kettle任务可以采用该方式进行定时调度,具体步骤如下:
-
上传转换、作业到指定目录下
#存放脚本资源 mkdir -p /opt/kettle/scripts #存放作业 mkdir -p /opt/kettle/scripts/jobs #存放转换 mkdir -p /opt/kettle/scripts/trans #存放调度脚本 mkdir -p /opt/kettle/scheduler #存放日志 mkdir -p /opt/kettle/logs #上传脚本 ╰$ scp /Users/liyadong/Desktop/job-test1.kjb root@bj-zjk-001:/opt/kettle/scripts/jobs ╰$ scp /Users/liyadong/Desktop/应用-测试.ktr root@bj-zjk-001:/opt/kettle/scripts/trans -
编写Shell脚本
调度脚本代码:
vim /opt/kettle/scheduler/test.sh
#!/bin/bash # 定义变量 export JAVA_HOME=/usr/local/jdk1.8.0_152/ export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH} #kettle任务模板配置 # job路径配置 jobs_path=/opt/kettle/scripts/jobs/job-test1.kjb #kettle脚本路径配置(根据kettle工具安装位置配置) kitchen_sh=/opt/install/data-integration/kitchen.sh #执行 ${kitchen_sh} -file=${jobs_path} -
使用Crontab定时调度
编辑调度器:
# crontab -e 00 12 * * * sh /opt/kettle/scripts/scheduler/test.sh >> /opt/kettle/logs/job-test1.log
4.15 资源库
4.15.1 资源库介绍
在Kettle中,开发创建的转换和作业是直接保存在本地,分别是转换文件ktr 和作业文件kjb 。
如果是多人团队开发的话,除了使用SVN等版本控制软件,还可以使用Kettle的资源库,它会将转换和作业相关的信息保存在数据库中。
-
kettle存储方式
- xml形式存储(在开发过程中,以此形式存储)
- 以资源库方式存储(分为数据库资源库和文件资源库)
-
资源库类型
kettle常见的资源库有3种:数据库资源库、文件资源库、pentaho资源库。
-
Database Repository(数据库资源库):将转换和作业相关的信息保存到一个数据库中,安全性更高,支持团队开发,多个用户可以共用这个资源库,真实环境常用。
-
File Repository(文件资源库):将转换和作业相关的信息保存到本地的指定文件夹中,就是作为文件保存,不支持团队开发。
-
pentaho资源库:它是一个插件(kettle企业版中有),实际是一个内容管理系统(CMS),它具备一个理想的资源库的所有特性,包括版本控制和依赖完整性检查。
-
4.15.2 数据资源库
创建Database Repository(数据库资源库)的资源库,具体步骤如下:
-
点击右上角connect,选择Other Resporitory
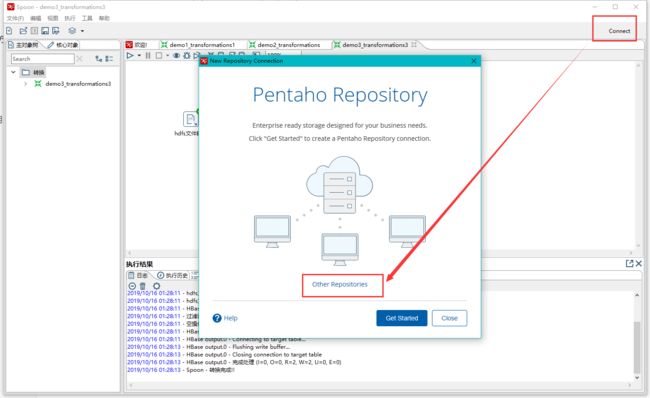
-
选择Database Repository
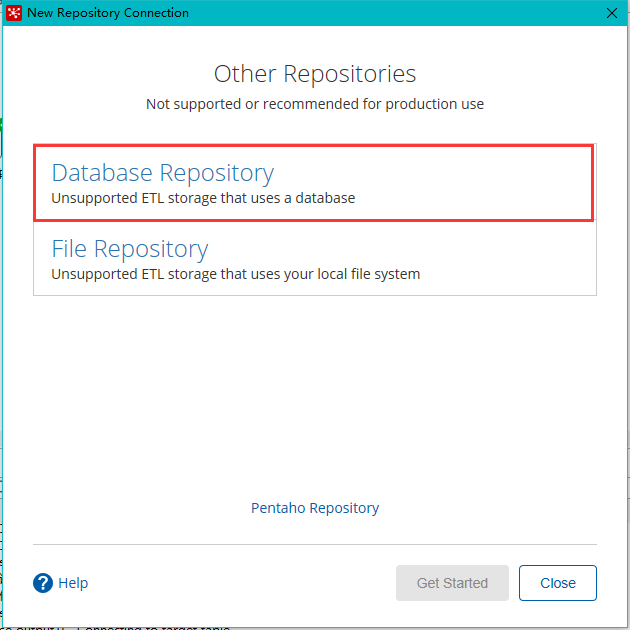
-
新建连接
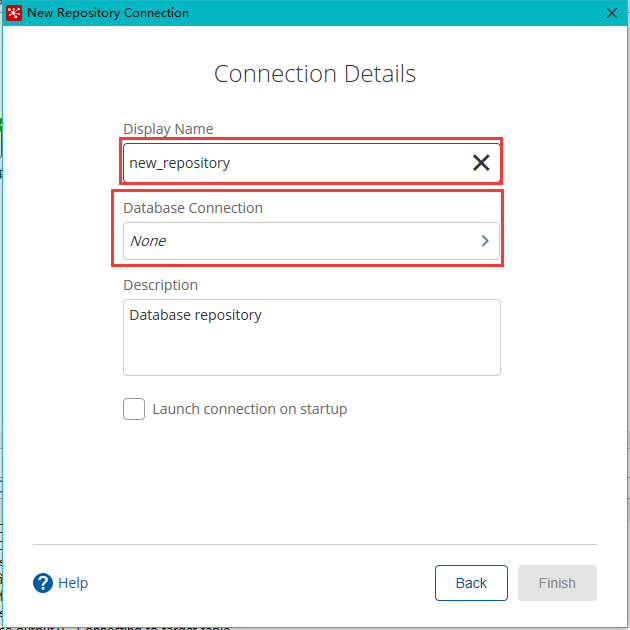
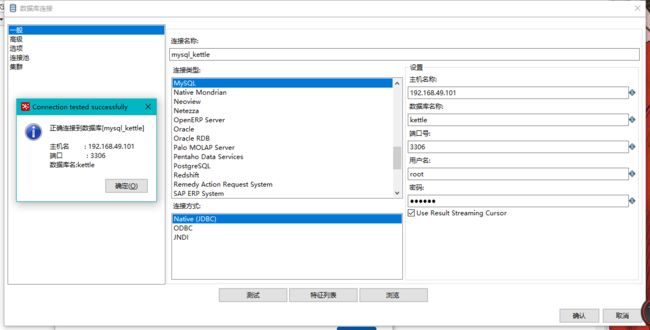
-
填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成

-
连接资源库,默认账号密码为admin
-
将之前做过的转换导入资源库
选择从xml文件导入
随便选择一个转换
点击保存,选择存储位置及文件名
打开资源库查看保存结果
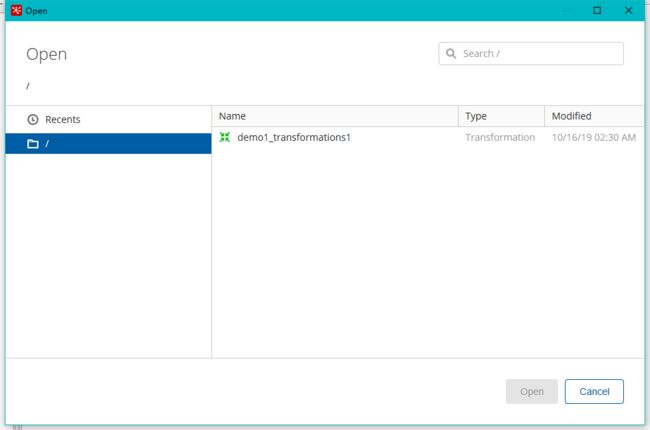
4.15.3 文件资源库
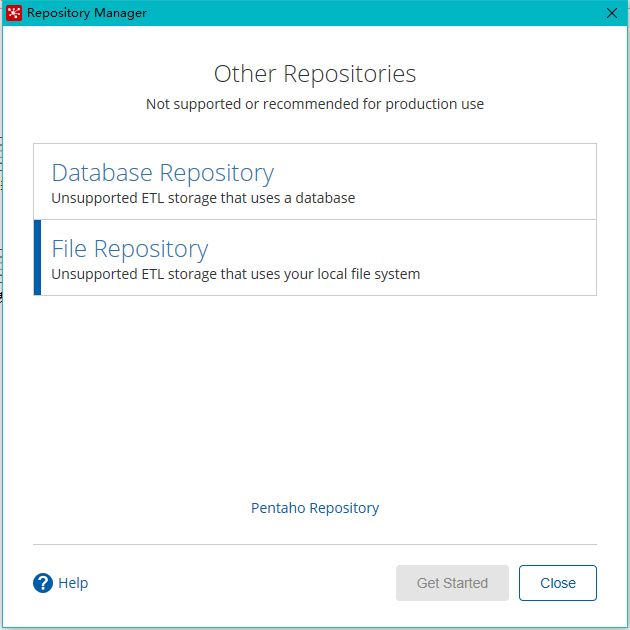
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样。创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨平台使用比较麻烦。
-
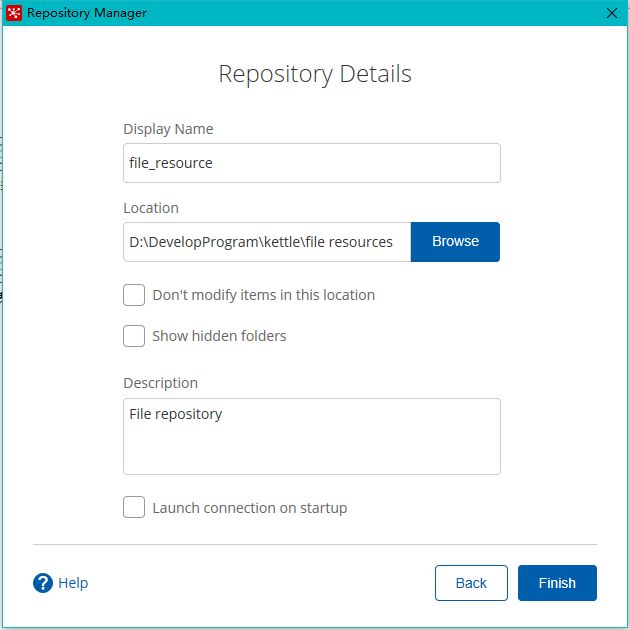
选择connect,选择文件资源库
-
填写信息
4.16 Kettle变量与参数
4.16.1 变量介绍
-
变量分类
在Kettle中变量一共可以分为3类:
-
系统变量(对应“kettle.properties”文件)
系统配置文件中定义过的。kettle.properties文件默认在/用户名/.kettle/下,即
/Users/liyadong/.kettle/kettle.properties -
自定义变量(对应“设置变量”组件)
自定义变量是局部变量
-
环境变量,其中系统变量是全局变量
环境变量指的是当前脚本文件中出现的所有变量,包括系统变量、自定义变量以及环境变量自身定义的变量。
注意:
系统变量和自定义变量的最大区别:系统变量是在文件中定义的,对所有脚本文件都始终有效;自定义变量是在脚本中定义的,只有定义后才能使用,其有效范围和范围参数有关。
-
-
变量的使用
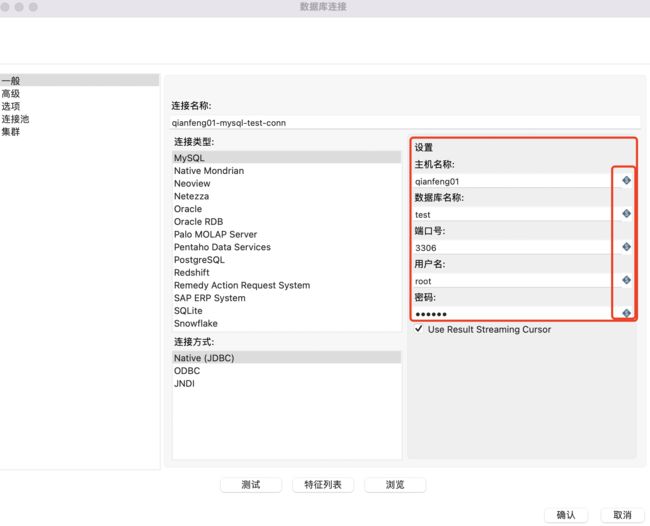
在Kettle中凡是带有“$”符号的输入框都可以使用变量和参数。
例如数据库连接时的主机名称、数据库名称、端口号、用户名、密码等。如下图所示:
例如“表输入”组件,SQL输入框和记录数量限制输入框都可以使用变量,其中SQL输入框内容包含变量时,必须勾选“替换SQL语句里的变量”这句话。
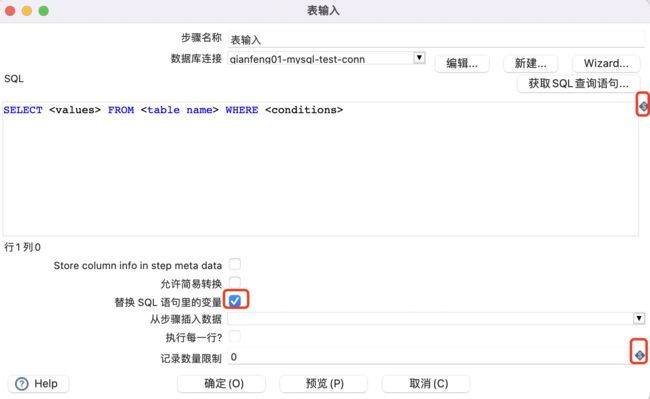
-
变量的使用
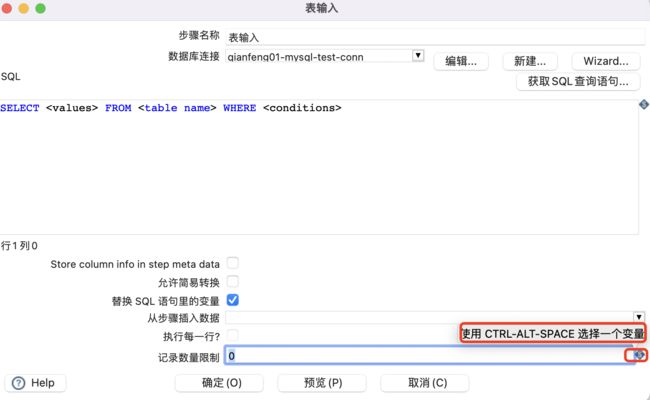
变量的使用格式为%%name%%或者${name},效果一样,其中name为变量的名称,Kettle默认使用${name}格式。
对于系统变量,在使用时,可以按照格式直接填写;也可以同时按下CTRL-ALT-SPACE快捷键,使系统变量在下拉框中显示,然后选择需要的变量名称;把鼠标指针放在“$”符号,就会有快捷键使用提示。
注意:
对于带有“$”符号的输入框,不要求必须使用变量,我们在填写时可以不使用变量,也可以只使用变量,当然也可以使用非变量和变量的组合内容。
4.16.2 系统变量的定义及应用
系统变量包含两类,一类是系统自带的,一类是用户通过配置文件添加的。
-
查看和编辑系统自带变量
Spoon客户端打开后,通过鼠标点击"编辑" ->“编辑kettle.properties文件”,可以打开"kettle.properties"文件的编辑界面。
在这里,我们可以对所有的系统变量进行编辑、新增和删除,操作后的结果会保存在"kettle.properties"文件里。
-
用户添加系统变量
用户可以通过直接编辑配置文件"/Users/liyadong/.kettle/kettle.properties"来添加变量,例如数据库连接信息或者邮件发送信息等:
email.host=SMTP.163.com email.port=25 [email protected] [email protected] [email protected] email.password=123456 -
系统变量应用

另外,在脚本中或者被多环境使用的字段,都可以使用系统变量方式来设置和获取。
4.16.3 自定义变量
在转换和作业中都可以自定义变量。
-
转换中自定义变量
转换—>核心对象—>作业—>设置变量:
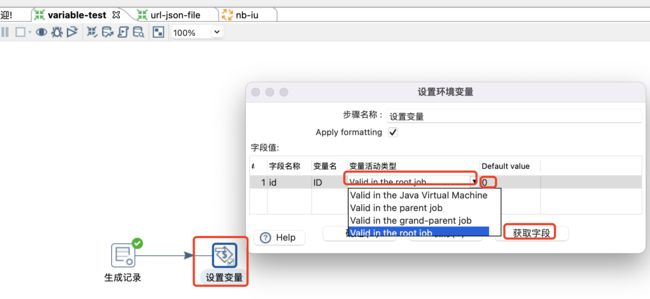
该方式一般需要一个上游组件来为变量赋值。变量名一般默认是上游字段的大写,变量活动类型如下:
变量活动类型 作用域 备注 Valid in the Java Virtuai Matchine 在同一个Java虚拟机下运行的作业和转换生效 系统级 Valid in the parent job 在当前作业下生效 作业级 Valid in the grand-parent job 在当前作业的父作业下生效 作业级 Valid in the root job 根作业下运行的作业和转换生效 作业级 注意:
-
含有"设置变量"组件的转换无法单独运行调试,因为最低是作业级,转换没有任何作业信息,即还没有指定"parent job",需要在后面的作业脚本中进行整体调试。
-
使用转换中的"设置变量"组件时,一般有两种用法:1、保存前一步骤的结果值,在其他步骤中使用;2、在循环执行中通过对变量赋值实现遍历操作。
-
-
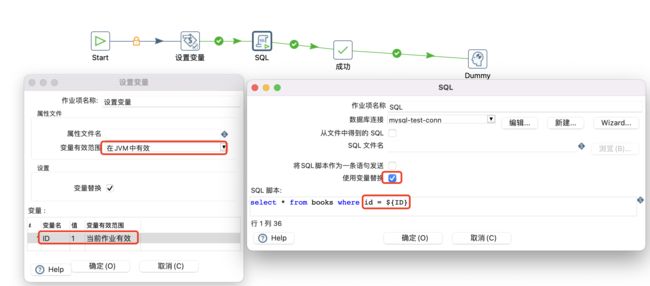
作业中自定义变量
在作业中定义变量和在转换中定义的区别:1、变量值不需要从前一步骤获取,需要直接输入;2、变量定义后在当前文件就可以使用。流程为作业—>通用—>设置变量:
注意:
- 当作业以及作业包含的子作业、子转换中的组件,需要使用同一个变量值时,可以通过在作业中设置变量实现。
4.16.4 环境变量定义
在Kettle中环境变量指的是当前脚本文件中出现的所有变量,包括系统变量、自定义变量以及环境变量自身定义的变量。
通过下面的操作可以设置环境变量和查看环境变量:
注意:
- 在当前作业也可以定义环境变量,定义好环境变量后,在当前作业、子转换和子作业中都可以正常使用。
- 转换中定义的环境变量,则是在转换中的所有步骤都可以正常使用。
4.16.5 参数介绍
-
参数分类
在Kettle中参数主要可以分为2类:
-
位置参数(Argument):位置参数没有参数名称,只能通过参数的位置顺序进行识别。
-
命名参数(Parameter):命名参数有具体的参数名称,是通过参数名称进行识别的。
注意:
-
命名参数像变量一样,可以在有效范围内被多次使用;
-
位置参数只能被其后的步骤使用一次,或通过“设置变量”组件把其转化为变量。
-
变量可以在脚本文件执行过程中进行动态创建和赋值,而参数和变量的最大不同就是
需要在脚本文件执行前指定参数值,然后才能在程序内部执行时进行使用,也就是我们常说的“传参”。如下图所示: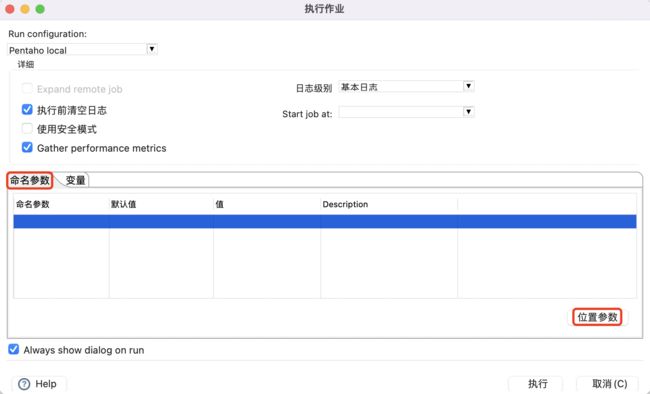
传参的好处就是,我们可以根据具体的业务需求动态地指定对应的参数值,而不需要重新去编辑脚本文件,操作相对简单,且有利于执行程序的稳定和复用。
当然,对于命名参数,为了程序的高效运行,我们可以给其指定常用的默认值。位置参数在日常的使用频次相对较低,目前不支持默认值设置。
-
-
参数的使用
-
位置参数和流字段(数据流中的字段)的使用类似,区别就是其是在程序执行前赋值的。
-
命名参数的使用和变量类似,在Kettle中带有“$”符号的输入框基本都可以使用,需要注意的是其使用范围,
只能在程序执行中引用,像数据库连接配置等场景就不能使用。
-
4.16.6 位置参数设置及应用
位置参数可以在作业启动或者转换中设置。例如,在作业的转换组件上设置:
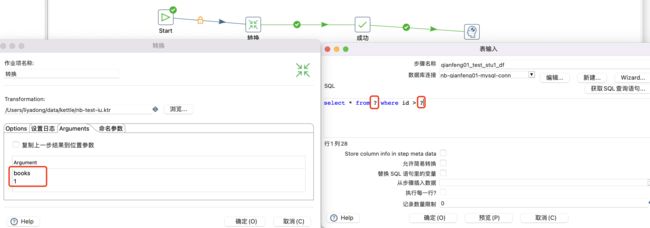
位置参数的值传递给后面的"表输入"组件,通过"?"匿名引用位置参数。
注意:
通过把位置参数通过“设置变量”步骤转换为变量,提升了参数值使用的灵活度。
上述作业中,位置参数是在转换中设置的,而该转换又是作业文件的一部分,因此位置参数的赋值有两种方式,分别是:1、在作业文件启动时赋值;2、在"转换"组件上赋值。如果两种赋值方式同时使用的话,最终第2种方式生效,即在作业文件启动时赋予的值会被覆盖。

Linux下作业命令行举例:
/opt/kettle/scripts/scheduler/test.sh >> /opt/kettle/logs/job-test1.log
./kitchen.sh -file=/opt/kettle/scripts/jobs/test.kjb books 1 -level=Minimal >> /opt/kettle/logs/test.log
Linux下转换命令行举例:
./pan.sh -file=/opt/kettle/scripts/trans/test.ktr books 1 >> /opt/kettle/logs/test.log
4.16.7 命名参数设置和应用
命名参数在转换文件和作业文件中均可以设置。
命名参数需要在"转换属性"或者"作业属性"里设置,操作方法基本一样。在新增命名参数时,命名参数的名称为必填项,默认值推荐填写;如果通过参数名称不太容易了解参数的业务含义,建议参数描述也填写下。如下图某转换设置命名参数所示:
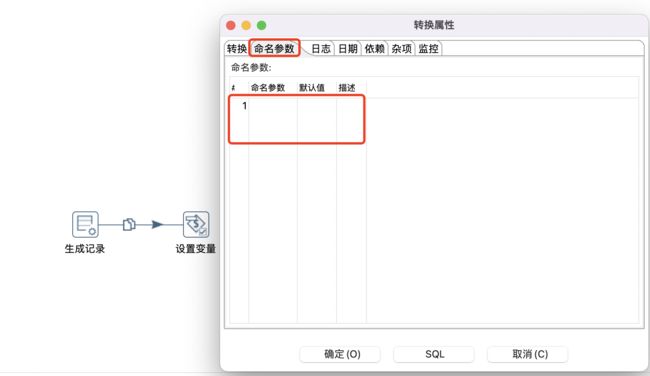
命名参数在定义和赋值后就可以使用了,使用格式和和变量一样,为%%name%%或者${name},两者效果一样,其中name为参数的名称,Kettle默认使用${name}格式。
父作业->子转换
默认情况下,命名参数的有效范围为当前转换或当前作业。但对于作业文件来说,在作业中定义的命名参数,是可以传递给其子转换的,只需要勾选"将所有参数值都传递到子转换"就可以了。
注意:
越靠近程序的赋值优先级越高。如,作业设置,转换也设置,则转换设置的覆盖作业设置的参数值。
子转换->子转换
这里需要注意的是,在上一步的子转换中需要使用"复制记录到结果"组件。
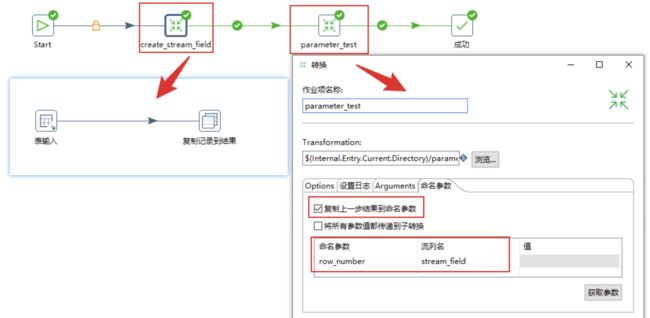
Linux下作业命令行举例:
/opt/kettle/scripts/scheduler/test.sh >> /opt/kettle/logs/job-test1.log
./kitchen.sh -file=/opt/kettle/scripts/jobs/test.kjb -param:table_name=books -param:id=1 -level=Minimal >> /opt/kettle/logs/test.log
Linux下转换命令行举例:
./pan.sh -file=/opt/kettle/scripts/trans/test.ktr -param:table_name=books -param:id=1 >> /opt/kettle/logs/test.log
4.17 Kettle规范及优化
4.17.1 Kettle规范
-
命名规范
避免将命名规范规则设计得过于复杂或完全没有命名规则或完全不按照规则命名等。关于作业和转换建议的命名规则:
-
转换命名规则:tr_${阶段名}_${业务名}_di/df
-
作业命名规则:jb_${阶段名}_${表名}_${业务名}_调度周期
-
临时转换和作业:tmp_…
注意:
- 不同目录下的转换及文件名不建议使用相同的名字,避免混淆。
- 转换中参与运算的临时列名,不参与输出的,建议使用tmp_为前缀;参与输出的列按照数据仓库设计规范即可。
- 每个trans、jobs的名称都应该和文件名一致。在使用资源库的时候,不是按照文件名生成对象,而是按照名称属性生成。所以如果有名称属性相同的就会冲突。
-
-
调度规范
统一的调度平台非常有必要,避免crontab调度、kettle自带调度或第三方调度混杂一起。调度建议如下:
- 尽量避免使用Kettle自带的开始节点的调度。Spoon或kitchen进程会长期驻留,容易产生OOM错误。
- 建议使用操作系统的调度,通过操作系统的调度直接执行Kitchen命令行,Kitchen执行万会退出,不会长期驻留,避免OOM问题
- 可以使用第三方调度机制,传递给第三方命令行。
- 可以自己开发Kettle的调度平台,统一调度kettle任务。
-
错误处理规范
建议在每个主作业流里都配置告警功能,目前仅支持邮件告警。建议如下:
- 错误发生后,通常是告警,然后人工修复,重新跑作业,但这容易不及时,可以二次开发,支持电话。
- 在作业中增加循环判断,一般用于检测某个条件,比如数据文件是否存在、表是否存在或设定循环次数,来进行自动容错。
4.17.2 Kettle优化
-
调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。
if [ -z "$PENTAHO_DI_JAVA_OPTIONS" ]; then PENTAHO_DI_JAVA_OPTIONS="-Xms1024m -Xmx2048m" fi参数参考如下:
-
-Xmx2048m:设置JVM最大可用内存为2048M。
-
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-
-
调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来提高批次大小,其设置Commitsize:10000-50000,实际值根据多次测试平均后来选择。
-
尽量使用数据库连接池及一些高级配置。选项中配置如下参数:
#关闭服务器端编译,sql语句在客户端编译好再发送给服务器端。如果为true,sql会采用占位符方式发送。 useServerPrepStmts=false #常用于数据库连接为mysql。要批量执行的话,JDBC连接URL字符串中需要新增一个参数:rewriteBatchedStatements=true,并保证5.1.13以上版本的驱动,才能实现高性能的批量插入。默认情况下会无视executeBatch()语句,把批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL。另外这个选项对INSERT/UPDATE/DELETE都有效。 rewriteBatchedStatements=true #压缩数据传输,优化客户端和MySQL服务器之间的通信性能。 useCompression=true连接池参数:当然也需要根据数据量,一般情况下,采用默认即可,如果数据量比较大,则是当提升其线程池数量。
-
尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)
-
Kettle的底层是Java,尽量用大一点的内存参数启动Kettle
-
能使用SQL的尽量使用SQL操作,比如:Group , merge , stream lookup,split field这些操作都是比较慢的,尽量使用SQL来替代,从而避免它们。
-
尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert。
-
能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建。
-
尽量减小输入的数据集的大小(增量更新也是为了这个目的)。
-
尽量使用数据库原生的桶装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤),这将会快几十上百倍。
-
SQL操作数据库时,尽量使用其索引的优势,但索引使用注意事项如下:
-
当插入的数据为数据表中的记录数量10%以上时,首先需要删除该表的索引来提高数据的插入效率,当数据全部插入后再建立索引,通常建议全量采集的时候先删除索引,提高采集效率。这将能提高至少2倍以上的写性能。
-
避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描。
-
避免在索引列上使用 NOT和 “!=”,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到NOT和 “!=”时,就会停止使用索引转而执行全表扫描。
-
索引列上用 >=替代 >
高效:select * from temp where deptno>=5
低效:select * from temp where deptno>4
两者的区别在于,前者DBMS将直接跳到第一个deptno等于5的记录而后者将首先定位到DEPTNO=4的记录并且向前扫描到第一个deptno大于4的记录。
-