【计算机网络笔记五】应用层(二)HTTP报文
HTTP 报文格式

HTTP 协议的请求报文和响应报文的结构基本相同,由四部分组成:
- ① 起始行(start line):描述请求或响应的基本信息;
- ② 头部字段集合(header):使用
key-value形式更详细地说明报文; - ③ 空行 + CRLF回车换行
- ④ 消息正文(body):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
HTTP 是一个 “纯文本” 的协议,所以头数据都是 ASCII 码的文本,可以很容易地用肉眼阅读。
请求报文格式:

响应报文格式:

请求报文的请求行
请求行简要地描述了客户端想要如何操作服务器端的资源。
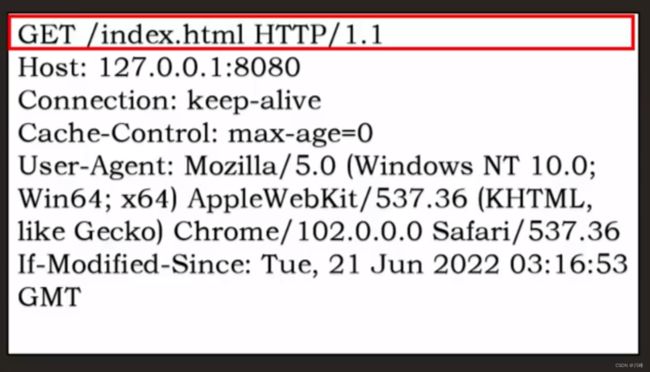
请求行由三部分组成:请求方法 + 空格 + URI + 空格 + 版本号 + CRLF回车换行
- ① 请求方法:是一个动词,如 GET/POST,表示对资源的操作方式;
- ② 请求目标:请求目标的路径 path,通常是一个 URI,标记了请求方法要操作的资源;
- ③ 版本号:表示报文使用的 HTTP 协议版本,如 HTTP/1.1 。
这三个部分通常使用空格(space)来分隔:

URI:统一资源标识符(Uniform Resource Identifier)
响应报文的状态行
在这里它不叫“响应行”,而是叫“状态行”(status line),意思是服务器响应的状态。

状态行由三部分组成:版本号 + 空格 + 状态码 + 空格 + 原因 + CRLF回车换行
- ① 版本号:表示报文使用的 HTTP 协议版本,如 HTTP/1.1;
- ② 状态码:一个 3 位数字,表示处理的结果,比如 200-成功,500-服务器错误,404-资源不存在;
- ③ 原因描述:作为数字状态码补充,是更详细的解释文字,帮助人理解原因。
头部字段
HTTP协议规定了非常多的头部字段,实现各种各样的功能,但基本上可以分为四大类:
-
① 通用字段:在请求头和响应头里都可以出现;比如
Date、Connection -
② 请求字段:仅能出现在请求头里,进一步说明请求信息或者额外的附加条件;比如
Host、Accept等 -
③ 响应字段:仅能出现在响应头里,补充说明响应报文的信息;比如
Server等 -
④ 实体字段:它实际上属于通用字段,但专门描述 body 的额外信息。比如
Content-Length等
对 HTTP 报文的解析和处理实际上主要就是对头字段的处理,理解了头字段也就理解了 HTTP 报文。
常用头字段 - Host 字段
-
Host 是一个请求字段,只能出现在请求头里。
-
Host 同时也是唯一一个 HTTP/1.1 规范里要求必须出现的字段,也就是说,如果请求头里没有 Host,那这就是一个错误的报文。
-
Host 字段其实是在告诉服务器这个请求应该由哪个主机来处理。

常用头字段 - User-Agent 字段
-
User-Agent 是一个请求字段,只出现在请求头里。
-
它使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以依据它来返回最合适此浏览器显示的页面。

常用头字段 - Date 字段
- Date 字段是一个通用字段,但通常出现在响应头里,表示 HTTP 报文创建的时间,客户端可以使用这个时间再搭配其他字段决定缓存策略。
常用头字段 - Server 字段
-
Server 字段是一个响应字段,只能出现在响应头里。 它告诉客户端当前正在提供 Web 服务的软件名称 和 版本号。
-
Server 字段也不是必须要出现的,因为这会把服务器的一部分信息暴露给外界,如果这个版本恰好存在bug,那么黑客就有可能利用 bug 攻陷服务器。所以,有的网站响应头里要么没有这个字段,要么就给出一个完全无关的描述信息。
常用头字段 - Content-Length 字段
-
实体字段里要说的一个是 Content-Length,它表示报文里 body 的长度,也就是请求头或响应头空行后面数据的长度。
-
服务器看到这个字段,就知道了后续有多少数据,可以直接接收。如果没有这个字段,那么 body 就是不定长的,需要使用 chunked 方式分段传输。
body 相关的头部字段

-
Accept: 表示客户端可解析的数据类型,可以用逗号分隔列出多个类型
-
Accept-Encoding: 表示客户端支持的压缩格式,可省略(不压缩)
-
Accept-Language: 客户端支持的语言
-
Accept-Charset: 通常不发送,浏览器都支持多种字符集
-
Content-Type: 响应实体的真实类型,可以出现在请求头和响应头中
-
Content-Encoding: 服务端告诉客户端响应实体使用了哪种压缩算法,可省略(不压缩)
-
Content-Language: 服务端通常不发送,表示使用的语言,一般可以由 Content-Type 中的字符集推断出来,如 Content-Type:text/html; charset=utf-8
-
Transfer-Encoding: chunked:表示分块传输,每个块包含两部分:长度头和数据块,最后一个块长度为 0 表示结束,即"0\r\n\r\n"
Transfer-Encoding: chunked 和 Content-Length 两个字段是互斥的,响应报文中这两个字段不能同时出现。
body 数据类型
HTTP 常用的四类数据包括:text、image、audio/video、application
每个大类下再细分出多个子类,形式是“type/subtype”的字符串
-
①
text: 文本格式的可读数据,如text/html超文本,text/plain纯文本,text/css样式表等 -
②
image: 图像文件,如image/gif、image/jpeg、image/png等 -
③
audio/video: 音频和视频数据,如audio/mpeg、video/mp4等 -
⑤
application:格式不固定,可以是文本或二进制,必须由上层应用来解释,常见的有application/json、application/javascript、application/pdf等如果不知道数据是什么类型就用
application/octet-stream即不透明的二进制数据
body 数据压缩

压缩算法:
- ①
gzip: GUN zip 压缩格式,互联网上最流行的压缩算法 - ②
deflate:zlib压缩格式 - ③
br: 一种专门为 http 优化的新压缩算法
压缩对应的头部字段:

-
Accept 字段标记的是客户端可解析的数据类型,可以用
,做分隔符列出多个类型,让服务器有更多的选择余地上图中的 Accept 字段含义是在告诉服务器:“我能够看懂 HTML、json 的文本,还有 webp 和 png的图片,请给我这四类格式的数据”
-
Accept-Encoding 字段标记的是客户端支持的压缩格式
-
Content-Encoding:服务器可以选择 Accept-Encoding 字段描述的压缩格式的其中一种来压缩数据,实际使用的压缩格式放在响应头的 Content-Encoding 字段里

Accept-Encoding 和 Content-Encoding 都可以省略,即不压缩。
body 语言类型/字符集编码
对应的头字段:
不过现在的浏览器都支持多种字符集,通常不会发送 Accept-Charset,而服务器也不会发送 Content-Language,因为使用的语言完全可以由字符集推断出来,所以请求头里一般只会有 Accept-Language 字段,响应头里只会有 Content-Type 字段。
body 内容协商的质量值
在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的 “q” 参数表示权重来设定优先级,这里的 “q” 是 “quality factor” 的意思。
权重的最大值是 1,最小值是0.01,默认值是1,如果值是0就表示拒绝。具体的形式是在数据类型或语言代码后面加一个 “;”,然后后面跟上 “q=value”。

它表示浏览器最希望使用的是 html 文件,权重是1,其次是xml文件,权重是0.9,最后是任意数据类型*/*,权重是0.8。
服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML。
分块传输
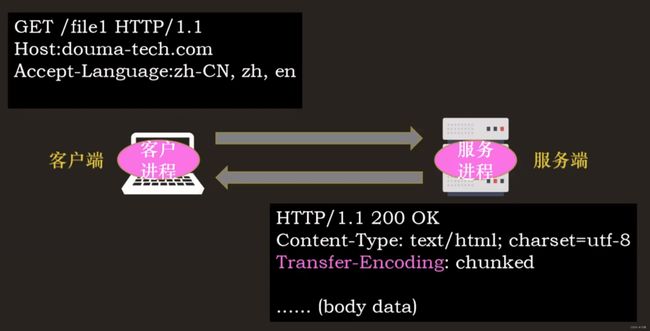
“Transfer-Encoding: chunked” 意思是报文里的 body 部分不是一次性发过来的,而是分成了许多的块(chunk)逐个发送。
注意:“Transfer-Encoding: chunked” 和 “Content-Length” 两个字段是互斥的,响应报文中这两个字段不能同时出现,因为一个响应报文的长度要么是已知的,要么是未知的(chunked)。
按范围取数据
- Accept-Range: bytes 响应报文中出现,表示服务器支持按字节来取范围数据
- Range: bytes=
- Content-Range:
主要用途:断点续传、多线程下载。
HTTP 请求方法
目前 HTTP/1.1 规定了八种请求方法,单词都必须是大写的形式:
- ① GET:获取资源,可以理解为读取或者下载数据;
- ② HEAD:获取资源的元信息;
- ③ POST:向资源提交数据,相当于写入或上传数据;
- ④ PUT:类似 POST;
- ⑤ DELETE:删除资源;
- ⑥ CONNECT:建立特殊的连接隧道;
- ⑦ OPTIONS:列出可对资源实行的方法;
- ⑧ TRACE:追踪请求 — 响应的传输路径。
GET 和 HEAD
-
GET 的含义是请求从服务器获取资源,这个资源既可以是静态的文本、页面、图片、视频,也可以是由 PHP、Java 动态生成的页面或者其他格式的数据。
-
HEAD 方法与 GET方法类似,也是请求从服务器获取资源,服务器的处理机制也是一样的,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的“元信息”。
比如,想要检查一个文件是否存在,只要发个 HEAD 请求就可以了,没有必要用 GET 把整个文件都取下来。再比如,要检查文件是否有最新版本,同样也应该用 HEAD,服务器会在响应头里把文件的修改时间传回来。
POST 和 PUT
-
POST 也是一个经常用到的请求方法,使用频率应该是仅次于 GET,应用的场景也非常多,只要向服务器发送数据,用的大多数都是 POST。
-
PUT 的作用与 POST 类似,也可以向服务器提交数据,但与 POST 存在微妙的不同,通常 POST 表示的是“新建”“create”的含义,而 PUT 则是“修改”“update”的含义。
在实际应用中,PUT 用到的比较少。而且,因为它与 POST 的语义、功能太过近似,有的服务器甚至就直接禁止使用 PUT 方法,只用 POST 方法上传数据。
响应状态码
目前 RFC 标准里规定的状态码是三位数,所以取值范围就是[000~999]
RFC 标准把状态码分成了五类,用数字的第一位表示分类,而0~99不用,这样状态码的实际可用范围就大大缩小了,由 [000~999] 变成了 [100~599]。
这五类的具体含义是:
- 1xx:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2xx:成功,报文已经收到并被正确处理;
- 3xx:重定向,资源位置发生变动,需要客户端重新发送请求;
- 4xx:客户端错误,请求报文有误,服务器无法处理;
- 5xx:服务器错误,服务器在处理请求时内部发生了错误。
状态码详表
| 状态码 | 状态信息 | 含义 |
|---|---|---|
| 100 | Continue | 初始的请求已经接受,客户应当继续发送请求的其余部分。(HTTP 1.1新) |
| 101 | Switching Protocols | 服务器将遵从客户的请求转换到另外一种协议(HTTP 1.1新) |
| 102 | Processing | 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。 |
| 200 | OK | 一切正常,对GET和POST请求的应答文档跟在后面。 |
| 201 | Created | 服务器已经创建了文档,Location头给出了它的URL。 |
| 202 | Accepted | 已经接受请求,但处理尚未完成。 |
| 203 | Non-Authoritative Information | 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝(HTTP 1.1新)。 |
| 204 | No Content | 没有新文档,浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。 |
| 205 | Reset Content | 没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容(HTTP 1.1新)。 |
| 206 | Partial Content | 客户发送了一个带有Range头的GET请求,服务器完成了它(HTTP 1.1新)。 |
| 207 | Multi-Status | 由WebDAV(RFC 2518)扩展的状态码,代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。 |
| 300 | Multiple Choices | 客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。 |
| 301 | Moved Permanently | 客户请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。 |
| 302 | Found | 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。注意,在HTTP1.0中对应的状态信息是“Moved Temporatily”。 出现该状态代码时,浏览器能够自动访问新的URL,因此它是一个很有用的状态代码。 注意这个状态代码有时候可以和301替换使用。例如,如果浏览器错误地请求http://host/~user(缺少了后面的斜杠),有的服务器返回301,有的则返回302。 严格地说,我们只能假定只有当原来的请求是GET时浏览器才会自动重定向。请参见307。 |
| 303 | See Other | 类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)。 |
| 304 | Not Modified | 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。 |
| 305 | Use Proxy | 客户请求的文档应该通过Location头所指明的代理服务器提取(HTTP 1.1新)。 |
| 306 | Switch Proxy | 在最新版的规范中,306状态码已经不再被使用。 |
| 307 | Temporary Redirect | 和 302(Found)相同。许多浏览器会错误地响应302应答进行重定向,即使原来的请求是POST,即使它实际上只能在POST请求的应答是303时才 能重定向。由于这个原因,HTTP 1.1新增了307,以便更加清除地区分几个状态代码:当出现303应答时,浏览器可以跟随重定向的GET和POST请求;如果是307应答,则浏览器只 能跟随对GET请求的重定向。(HTTP 1.1新) |
| 400 | Bad Request | 请求出现语法错误。 |
| 401 | Unauthorized | 客户试图未经授权访问受密码保护的页面。应答中会包含一个WWW-Authenticate头,浏览器据此显示用户名字/密码对话框,然后在填写合适的Authorization头后再次发出请求。 |
| 402 | Payment Required | 该状态码是为了将来可能的需求而预留的。 |
| 403 | Forbidden | 资源不可用。服务器理解客户的请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置导致。 |
| 404 | Not Found | 无法找到指定位置的资源。这也是一个常用的应答。 |
| 405 | Method Not Allowed | 请求方法(GET、POST、HEAD、DELETE、PUT、TRACE等)对指定的资源不适用。(HTTP 1.1新) |
| 406 | Not Acceptable | 指定的资源已经找到,但它的MIME类型和客户在Accpet头中所指定的不兼容(HTTP 1.1新)。 |
| 407 | Proxy Authentication Required | 类似于401,表示客户必须先经过代理服务器的授权。(HTTP 1.1新) |
| 408 | Request Timeout | 在服务器许可的等待时间内,客户一直没有发出任何请求。客户可以在以后重复同一请求。(HTTP 1.1新) |
| 409 | Conflict | 通常和PUT请求有关。由于请求和资源的当前状态相冲突,因此请求不能成功。(HTTP 1.1新) |
| 410 | Gone | 所请求的文档已经不再可用,而且服务器不知道应该重定向到哪一个地址。它和404的不同在于,返回407表示文档永久地离开了指定的位置,而404表示由于未知的原因文档不可用。(HTTP 1.1新) |
| 411 | Length Required | 服务器不能处理请求,除非客户发送一个Content-Length头。(HTTP 1.1新) |
| 412 | Precondition Failed | 请求头中指定的一些前提条件失败(HTTP 1.1新)。 |
| 413 | Request Entity Too Large | 目标文档的大小超过服务器当前愿意处理的大小。如果服务器认为自己能够稍后再处理该请求,则应该提供一个Retry-After头(HTTP 1.1新)。 |
| 414 | Request URI Too Long | URI太长(HTTP 1.1新)。 |
| 415 | Unsupported Media Type | 对于当前请求的方法和所请求的资源,请求中提交的实体并不是服务器中所支持的格式,因此请求被拒绝。 |
| 416 | Requested Range Not Satisfiable | 服务器不能满足客户在请求中指定的Range头。(HTTP 1.1新) |
| 417 | Expectation Failed | 在请求头 Expect 中指定的预期内容无法被服务器满足,或者这个服务器是一个代理服务器,它有明显的证据证明在当前路由的下一个节点上,Expect 的内容无法被满足。 |
| 421 | There are too many connections from your internet address | 从当前客户端所在的IP地址到服务器的连接数超过了服务器许可的最大范围。通常,这里的IP地址指的是从服务器上看到的客户端地址(比如用户的网关 或者代理服务器地址)。在这种情况下,连接数的计算可能涉及到不止一个终端用户。 |
| 422 | Unprocessable Entity | 请求格式正确,但是由于含有语义错误,无法响应。(RFC 4918 WebDAV) |
| 423 | Locked | 当前资源被锁定。(RFC 4918 WebDAV) |
| 424 | Failed Dependency | 由于之前的某个请求发生的错误,导致当前请求失败,例如 PROPPATCH。(RFC 4918 WebDAV) |
| 425 | Unordered Collection | 在WebDav Advanced Collections 草案中定义,但是未出现在《WebDAV 顺序集协议》(RFC 3658)中。 |
| 426 | Upgrade Required | 客户端应当切换到TLS/1.0。(RFC 2817) |
| 449 | Retry With | 由微软扩展,代表请求应当在执行完适当的操作后进行重试。 |
| 500 | Internal Server Error | 服务器遇到了意料不到的情况,不能完成客户的请求。 |
| 501 | Not Implemented | 服务器不支持实现请求所需要的功能。例如,客户发出了一个服务器不支持的PUT请求。 |
| 502 | Bad Gateway | 服务器作为网关或者代理时,为了完成请求访问下一个服务器,但该服务器返回了非法的应答。 |
| 503 | Service Unavailable | 服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个Retry-After头。 |
| 504 | Gateway Timeout | 由作为代理或网关的服务器使用,表示不能及时地从远程服务器获得应答。(HTTP 1.1新) |
| 505 | HTTP Version Not Supported | 服务器不支持请求中所指明的HTTP版本。(HTTP 1.1新) |
| 506 | Variant Also Negotiates | 由《透明内容协商协议》(RFC 2295)扩展,代表服务器存在内部配置错误:被请求的协商变元资源被配置为在透明内容协商中使用自己,因此在一个协商处理中不是一个合适的重点。 |
| 507 | Insufficient Storage | 服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。WebDAV (RFC 4918) |
| 509 | Bandwidth Limit Exceeded | 服务器达到带宽限制。这不是一个官方的状态码,但是仍被广泛使用。 |
| 510 | Not Extended | 获取资源所需要的策略并没有没满足。(RFC 2774) |
HTTP 重定向
当一个客户端访问某个 URL 的时候,由于某种原因,服务端会告诉客户端需要重新访问另一个 URL,这就是重定向。
最常见的重定向状态码就是301和302,301俗称“永久重定向”(Moved Permanently), 302 俗称“临时重定向”(“Moved Temporarily”) 。

“Location” 字段属于响应字段,必须出现在响应报文里。但只有配合 301/302 状态码才有意义,它标记了服务器要求重定向的 URL。
301 永久重定向
很多客户端记住的是原 URL,但是这个 URL在服务端已经不用了,此时请求服务器会返回 301,浏览器看到 301,就知道原来的 URL “过时”了,就会做适当的优化。比如刷新历史记录、更新书签,下次可能就会直接用新的 URL 访问,省去了再次跳转的成本。
302 临时重定向
302 俗称“临时重定向”(“Moved Temporarily”),意思是原 URL 处于“临时 维护”状态,新的 URL是起“顶包”作用的“临时工”。
浏览器看到 302,会认为原来的 URL 仍然有效,但暂时不可用,所以只会执行简单的跳转页面,不记录新的 URL,也不会有其他的多余动作,下次访问还是用原 URL。
比如,服务器中临时维护某个 URL,就可以返回 302 状态码。
URL 格式
URI 是统一资源标识符,URL 是统一资源定位符,URL 是 URI 的一种具体实现。
URL 格式:schema://host:port/path

schema:协议名,表示资源应该使用哪种协议来访问。如 http、https- 在
scheme之后,必须是三个特定的字符://,它把scheme和后面的部分分离开 host:port在://之后,是资源所在的主机名,即主机名加端口号path是资源在主机上的位置路径- 有了协议名和主机地址、端口号,再加上后面标记资源所在位置的path,浏览器就可以连接服务器访问资源了。
查询参数:schema://host:port/path?key=value&key=value
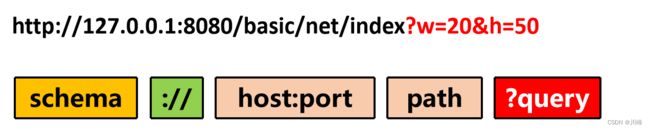
path后面使用一个"?“分割开来,”?"后面的就是query查询参数部分,query部分是由“&”拼接的多个key=value键值对
获取图片的时候,想要指定不同大小,仅用“协议名 + 主机名 +路径”的方式是无法适应这些场景的,所以 URI 后面还有一个 “query” 部分,它在 path 之后,用一个 “?” 开始,但不包含 “?”,表示对资源附加的额外要求。
片段标识:

它是 URI 所定位的资源内部的一个“锚点”或者说是“标签”,浏览器可以在获取资源后直接跳转到它指示的位置
但片段标识符仅能由浏览器这样的客户端使用,服务器是看不到的。也就是说,浏览器永远不会把带#fragment 的 URI 发送给服务器,服务器也永远不会用这种方式去处理资源的片段。
URL 编码
在 URI 里只能使用 ASCII 码,但如果要在 URI 里使用英语以外的汉语、日语等其他语言该怎么办呢?
还有,某些特殊的 URI,会在 path、query 里出现“@&?"等起界定符作用的字符,会导致 URI 解析错误,这时又该怎么办呢?
URI 引入了编码机制,对于 ASCII 码以外的字符集和特殊字符做一个特殊的操作,把它们转换成与 URI 语义不冲突的形式。
URI 转义的规则有点“简单粗暴”,直接把非 ASCII 码或特殊字符转换成十六进制字节值,然后前面再加上一个“%”。
例如,空格被转义成“%20”,“?”被转义成“%3F”。而中文、日文等则通常使用 UTF-8 编码后再转义,例如“银河”会被转义成 “%E9%93%B6%E6%B2%B3”。