Github 3k+ stars 南科大 VIP Lab 近期开源 Track-Anything | SAM + VOS: 一键视频标注
本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!

Title: Track Anything: Segment Anything Meets Videos
Paper: https://arxiv.org/pdf/2304.11968.pdf
Code: https://github.com/gaomingqi/Track-Anything
导读
近日,南方科技大学 VIP 实验室开源了一款基于 SAM 的跟踪模型——Track-Anything,可以轻松地对视频中感兴趣的目标进行标注、跟踪和一键隐藏。所见即所得,一键触发。先给大家展示一段Demo:
回到正题。本文主要介绍了一个新的计算机视觉算法模型Track Anything Model, TAM。该模型的设计灵感来自于已经受到广泛关注的Segment Anything Model, SAM,SAM 是一种在图像分割方面表现出色的模型。然而,SAM 在视频中的分割性能一般表现较差。因此,本文提出了一种基于交互式设计的新模型TAM,旨在实现视频中的高性能交互式跟踪和分割。在该模型中,只需要少量的人类参与即可通过点击追踪感兴趣的任何物体,并在一次推理过程中获得令人满意的结果。在不进行额外训练的情况下,这种交互式设计在视频物体跟踪和分割方面表现出色。
笔者空闲的时候亲自尝试了一把,感觉效果相对来说还是不错滴,虽然存在一些问题。文末会附上安装教程和注意事项,不想了解细节的小伙伴可直接跳转到文末。
特点
Track Anything 旨在实现在任意视频中对物体的灵活跟踪。因此,作者定义了该任务的目标对象可以根据用户的兴趣进行灵活选择、添加或删除,用户选择的视频的长度和类型也可以是任意的,而不仅仅限于修剪视频。在这样的设置下,可以实现多种下游任务,包括单个/多个目标跟踪、长期目标跟踪、无监督VOS、半监督VOS 和 交互式VOS 等各类 VOS。
注:Video Object Segmentation, VOS,即视频目标分割。
方法
背景介绍
本文方法主要是基于已有算法组装成一个pipeline,下面简单介绍下几个主要成员。
Segment Anything Model
SAM 是由 Meta AI Research 提出的,近期引起了学术界和工业界广泛的关注。作为图像分割的基础模型,SAM 基于 ViT 模型,在大规模数据集 SA-1B 上进行了训练。显然,SAM 在图像分割方面表现出色,特别是在零样本分割任务上。然而,SAM 只在图像分割方面表现优异,不能处理复杂的视频分割任务。因此,这也是本文方法提出的意义。
XMem
该模型可以根据目标物体在第一帧的掩码描述,在后续帧中跟踪该物体并生成相应的掩码。XMem的设计灵感来源于·Atkinson-Shiffrin·记忆模型,旨在通过统一的特征内存存储解决长视频中的困难问题。然而,XMem 的缺点也很明显:
- 作为半监督 VOS 模型,它需要一个精确的掩码来初始化;
- 对于长视频来说,XMem 很难从跟踪或分割失败中恢复已有对象。
在本文中,作者通过引入与 SAM 的交互跟踪来解决这两个问题。
Interactive Video Object Segmentation
交互式 VOS(Interactive VOS)模型旨在将用户交互(如涂鸦)作为输入,用户可以迭代地细化分割结果,直到满意为止。交互式 VOS 因为比为对象掩码指定每个像素点更容易提供涂鸦而受到了广泛的关注。然而,作者发现当前的交互式 VOS 方法需要多轮迭代才能细化结果,这影响了它们在实际应用中的效率。
这个挺有意思的,光看字面意思其实没啥感觉,大家可以安装部署完亲自去体验下。简而言之,就是你点一下图片中自己感兴趣的目标,图片就会渲染一次,将当前目标的掩码自动打出来。不过由于 SAM 本身分割的粒度比较细,例如当一个人身上背了一个包,如果你的鼠标点击包的位置,那大概率就会把属于包的语义给出来,这时候就需要你再点一下属于人身体躯干上的其它位置,一般几下以内就可以达到不错的效果。
当然,工程上还用到了其他模型,如 MMEditing 提供的视频超分辨率模型 BasicVSR 用于对推理后的结果进行处理,有兴趣的可自行查源码,此处不展开细讲。
实现细节
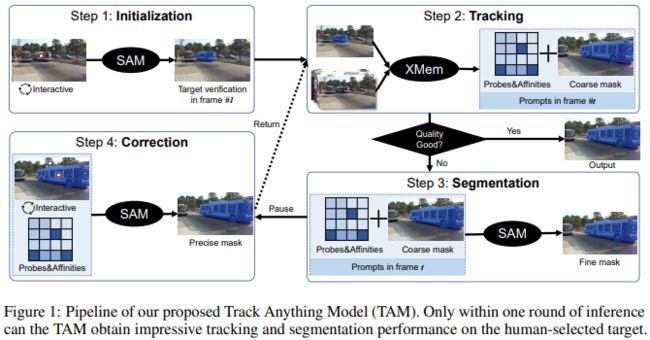
TAM 模型的处理流程如上图所示,主要分四个步骤,下面逐一介绍。
Step 1: Initialization with SAM
在步骤1中,作者使用了 SAM 来进行初始化。由于 SAM 提供了使用弱提示(例如点和边界框)来分割感兴趣区域的机会,因此这里我们可以直接用来提供目标对象的初始掩码。按照 SAM 的流程,用户可以通过单击或使用几个单击修改对象掩码,以获得满意的初始化结果。
Step 2: Tracking with XMem
在步骤2中,作者使用了 XMem 来进行跟踪。在给定初始掩码后,XMem 会在后续帧上执行半监督 VOS。由于XMem 是一种先进的 VOS方法,可以在简单的情况下输出令人满意的结果,因此在大多数情况下输出 XMem 的预测掩码。这里还有个细节,便是当掩码质量不太好时,作者会保存 XMem 的预测结果以及相应的中间参数,例如Probes和Affinities,并跳到步骤3,不清楚的可参考图示。
上面两个名词简单说下个人理解。在 XMem 方法中,每个像素都有一个特征表示,并且它们被存储在一个诸如 “feature memory store” 的内存中。探针(probe)是一组查询特征,用于计算与 feature memory store 中其他特征的相似度。亲和力(affinity) 则是相似度的计算结果,用于衡量两个像素之间的相似度。因此,在这个步骤中,当 XMem 无法输出令人满意的掩码时,作者保存了探针和亲和力,以便在步骤3中重新初始化 XMem,并尝试恢复跟踪。这一块笔者此前没接触过,凭感觉写的,如有谬论,敬请谅解。
Step 3: Refinement with SAM
在 VOS 模型的推理过程中,持续地预测一致性和精确性的分割掩码是具有挑战性的。实际上,大多数最先进的视频对象分割模型在推理过程中倾向于越来越粗略地分割目标。因此,当 XMem 预测的分割质量不理想时,本文利用 SAM 对其进行改进。具体来说,作者将 XMem 生成的探针和关联信息投影为 SAM 的点提示,将步骤2中生成的预测掩码用作 SAM 的掩码提示。然后,SAM 能够利用这些提示生成经过改进的分割掩码。如此一来,改进掩码还将被添加到 XMem 中,以改进所有后续的分割对象。
Step 4: Correction with human participation
步骤4主要就是人工的参与啦。经过以上三个步骤,TAM 现在可以成功解决一些常见的挑战并预测出分割掩模。然而,我们注意到在一些极具挑战性的情况下,尤其是处理长视频时,仍然很难准确地区分对象。因此,TAM 提出在推理过程中添加人类修正,只需要很小的人类工作量就可以在性能上实现质的飞跃。具体而言,用户可以强制停止 TAM 的过程,并使用正负点击修正当前帧的掩模。
应用场景
Efficient video annotation
在视频注释方面,TAM 具有将感兴趣的区域进行分割并灵活选择用户想要跟踪的对象的能力。因此,它可以用于视频注释任务,如视频对象跟踪和视频对象分割。另一方面,基于点击的交互使其易于使用,注释过程高效。这意味着,TAM 可以用于快速标注视频数据集,从而促进视频领域的进一步发展。
Long-term object tracking
长期目标跟踪是指在跟踪目标时,需要应对目标消失和重新出现的情况,这一问题更加贴近实际应用需求。当前的长期目标跟踪任务要求跟踪器具有这种能力,但仍受限于裁剪后的视频范围。而 TAM 则在真实世界应用中更为先进,可以应对长视频中的镜头变换等复杂情况。
User-friendly video editing
通过 TAM 我们还可以将视频中的物体进行分割,从而方便我们删除或修改视频中的物体。作者还提到了 E2FGVI 这个工具,该工具可以用来评估 TAM 在视频编辑方面的应用价值。
Visualized development toolkit for video tasks.
为了方便使用,本文还提供了多种视频任务的可视化界面,例如 VOS、VOT、视频修复等等。使用提供的工具包,用户可以将自己的模型应用于真实世界的视频,并即时可视化结果。相应的演示可在Hugging Face中找到,或者自己安装在本地部署。
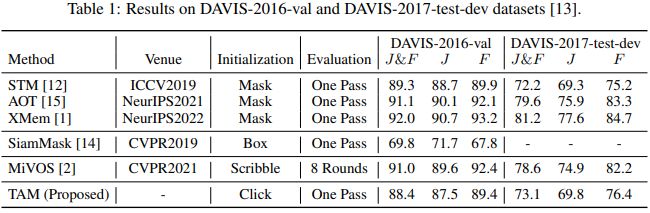
效果

安装教程
TAM 目前可支持 Linux & Windows 上进行安装使用,大体的安装流程如 Github Repo 所示:
# Clone the repository:
git clone https://github.com/gaomingqi/Track-Anything.git
cd Track-Anything
# Install dependencies:
pip install -r requirements.txt
# Run the Track-Anything gradio demo.
python app.py --device cuda:0
# python app.py --device cuda:0 --sam_model_type vit_b # for lower memory usage
这里有几个小问题需要注意下:
-
请提前准备并测试好的你的 git 环境,运行过程需要下载许多插件和第三方库,网速不好的真的可以摔键盘了;
-
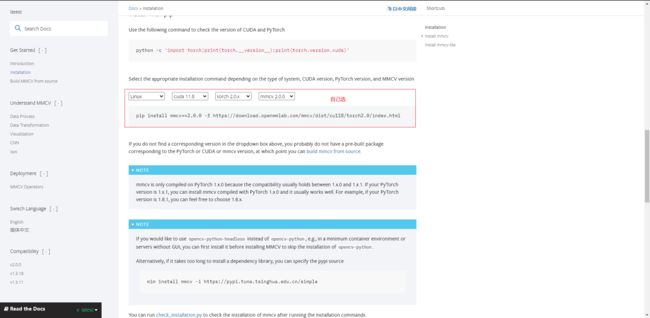
requirements并没有指定具体的包版本,相信绝大部分小伙伴 pip 完会发现少这少那,比较常见的错误便是 mmcv 和 torch 这两个库。例如 torch 库默认会装 2.0,如果你的机器不支持,大概率是会报无法编译 CUDA 的错误,这时候你就需要安装适配自己机器版本的 torch 环境了。此外,mmcv 这个需要安装完整版和适配版本。
安装链接:
pytorch: https://pytorch.org/get-started/previous-versions/
mmcv: https://mmcv.readthedocs.io/en/latest/get_started/installation.html
- 安装完之后可能没报错,当你运行打开 localhost 时,会发现 505 错误或者直接一片空白的网页。这时候不要慌,请尝试将 app.py 文件中,将
server_name的 ip 地址替换后重新运行下即可。
# app.py
...
iface.launch(debug=True, enable_queue=True, share=True, server_port=args.port, server_name="0.0.0.0")
# 替换为
iface.launch(debug=True, enable_queue=True, share=True, server_port=args.port, server_name="127.0.0.1")
Windows 上部署安装教程请参考视频:https://www.youtube.com/watch?v=MQJ4LMLXm30。
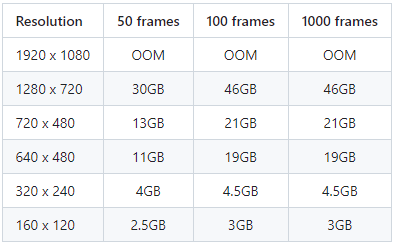
此外,需要注意的是,不同的模型运行的显存不一样,显存不够的可尝试使用小一点的模型,如:
python app.py --device cuda:0 --sam_model_type vit_b
具体可参考:https://github.com/gaomingqi/Track-Anything/issues/4
笔者的使用体验:
- 对于遮挡的情况,目前看来有一定概率会出现目标丢失的情况。例如当图中这个绿框的人走到这个橙色框时,后续的帧就完全断了。
-
在进行
Tracking处理时,显存会不断的增大,而非一开始就 OOM。 -
使用 point 交互式操作,有时候遇到图像太大目标太小,很容易点错。gradio 没有提供像 CVAT 上的缩放功能,这一点用户体验不是很好。
最后,有任何疑问或交流需求的,欢迎请添加小编微信:cv_huber,备注 Track-Anything 加入交流群一起探讨吧。
