C++11新特性内存模型总结详解--一篇秒懂
自己开发了一个股票软件,功能很强大,需要的点击下面的链接获取:
QStockView股票智能分析报警软件下载链接 - 一字千金 - 博客园
目录
1 介绍... 1
1.1 原子操作... 1
1.2 指令执行顺序... 2
1.3 编译器和CPU指令重排... 2
1.4 依赖关系... 3
1.5 memoryorder作用... 3
2 六种内存模式... 3
2.1 Relaxed ordering. 5
2.2 Release – acquire. 6
2.3 Release – consume. 7
2.4 memory_order_acq_rel 10
2.5 Sequentially-consistent ordering. 11
2.6 总结... 13
3 参考文献... 14
1 介绍
多线程编程已经是大家熟知的知识,多线程编程主要的问题就是多线程同时访问一个变量时,会造成同时读写同一个变量的问题,造成数据异常,通常会使用mutex、临界区、条件变量来实现多线程同步,避免多线程同时读写同一个变量。但是锁竞争也会影响程序的执行效率,所以C++11引入了原子变量atomic,实现变量的原子操作,线程对变量的操作马上对其他线程可见,避免使用锁临界区造成的消耗。同时C++11引入了内存模型,可以同步不同线程之间的原子变量操作前后的代码的重排限制。
1.1 原子操作
首先,什么是原子操作?原子操作就是对一个内存上变量(或者叫左值)的读取-变更-存储(load-add-store)作为一个整体一次完成。例如x++这个表达式如果编译成汇编,对应的是3条指令:mov(从内存到寄存器),add,mov(从寄存器到内存)那么在多线程环境下,就存在这样的可能:当线程A刚刚执行完第二条add指令的时候,还没有执行第三条mov指令,线程B就同时开始执行第一条指令。那么B读到的数据还是0,A执行第三条指令后写入内存,x值是1,B再执行第三条指令从寄存器写到内存,x还是1。如果是原子操作,mov(从内存到寄存器),add,mov(从寄存器到内存)这三条指令必须一次完成,线程A执行三条之后,x=1,线程B在执行三条指令,得到x=2。atomic本身就是一种锁,它自己就已经完成这种原子操作的作用。内存顺序是控制不同原子操作之间的执行顺序,比如是线程B先加1还是线程A先加1。
1.2 指令执行顺序
为了尽可能地提高计算机资源利用率和性能,编译器会对代码进行重新排序, CPU 会对指令进行重新排序、延缓执行、各种缓存等等,以达到更好的执行效果。单线程则是按照线程中的代码顺序执行指令,多线程时,两个线程之间执行指令的顺序会进行优化调整,所以无法保证两个线程中指令执行的相对顺序,例如线程1有指令A,B,线程2有指令C,D,两个线程同时执行,那么可能的执行顺序是ABCD,ACBD,CDAB,CABD等;所以C++11引用内存顺序操作,实现控制多线程中指令执行顺序,实现多线程同步。能够按照你想的顺序执行指令。
happens-before关系,说白了就是代码编写顺序,一般是指单线程内部的代码顺序。Synchronized-with关系则是多线程之间的同步关系,通过6个模式,实现多线程中指向执行顺序的不同约束。
1.3 编译器和CPU指令重排
代码顺序:就是你按照代码一行一行从上往下的顺序;
编译器对代码可能进行指令重排。也就是编译生成的二进制(机器码)的顺序与源代码可能不同,例如一个线程中有两行代码x++;y++;虽然y++在x++之后,但是编译器可能会把y++放到x++之前。而且CPU内部也有指令重排,也就是说,CPU执行指令的顺序,也不见得是完全严格按照机器码的顺序。当代CPU的IPC(每时钟执行指令数)一般都远大于1,也就是所谓的多发射,很多命令都是同时执行的。比如,当代CPU当中(一个核心)一般会有2套以上的整数ALU(加法器),2套以上的浮点ALU(加法器),往往还有独立的乘法器,以及,独立的Load和Store执行器。Load和Store模块往往还有8个以上的队列,也就是可以同时进行8个以上内存地址(cache line)的读写交换。
1.4 依赖关系
单线程中指令重排也不会乱排,不相关的指令可以重排,相关的指令不能重排;例如线程1中有两条指令x++;y++;这两条指令是完全不相关的,可以任意调整顺序。但是如果是x++;y=x;那这两条指令是依赖关系,那么一定是按照代码顺序去执行。
1.5 memoryorder作用
memory order,其实就是限制编译器以及CPU对单线程当中的指令执行顺序进行重排的程度(此外还包括对cache的控制方法)。这种限制,决定了以atomic操作为基准点(边界),对其之前后的内存访问命令,能够在多大的范围内自由重排(或者反过来,需要施加多大的保序限制),也被称为栅栏。从而形成了6种模式。它本身与多线程无关,是限制的单一线程当中指令执行顺序。
参考文献
如何理解 C++11 的六种 memory order? - 知乎
2 六种内存模式
| 编号 |
顺序关系 |
说明 |
| 1 |
Relaxed order限制相关变量的原子操作。 |
只保证线程1中的g.Store和线程2中的g.load操作是原子操作。不保证线程之间的g操作指令同步顺序。也不限制其他变量的顺序。 |
| 2 |
Release-acquire同步多线程顺序,强制其他变量的顺带关系。 |
(1) 线程1中,g.store(release)之前读写操作不允许重排到g.store(release)后面。 (2) g.load(acquire)之后的读写操作不允许被重排到g.load(acquire)之前。 (3) 如果g.store()在gload()之前执行,那么g.store(release)之前的所有写操作对g.load(acquire)之后的命令可见。 |
| 3 |
Release-consume只同步同步顺序,强制其他变量的顺带关系。 |
(1) 只保证原子操作,不会影响非依赖关系变量的重排顺序限制。 (2) 对有依赖关系的变量,如果g.store()在gload()之前执行,限制g.store(release)之前的所有写操作对g.load(acquire)之后的命令可见。 |
| 4 |
memory_order_acq_rel: |
(1)在当前线程对读取和写入施加 acquire-release 语义,语句后的不能重排到前面,语句前的不能重排到后面。 (2)可以看见其他线程施加 release 语义之前的所有写入,同时自己的 release 结束后所有写入对其他施加 acquire 语义的线程可见。 |
| 5 |
memory_order_seq_cst |
顺序一致性模型,(1)对变量施加acq_rel语义限制的限制,(2)同时还建立一个对所有原子变量操作的全局唯一修改顺序,所有线程看到的内存操作的顺序都是一样的。 |
2.1 Relaxed ordering
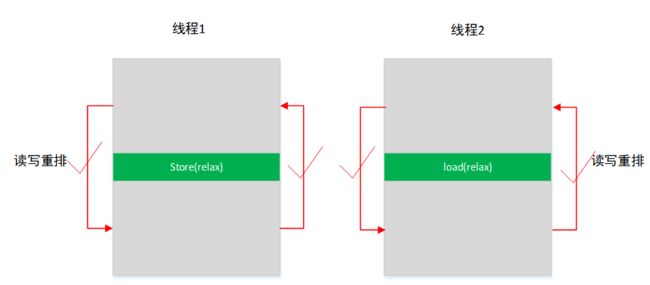
Relaxed ordering,放松的排序,只保证操作是原子操作,但是不保证任何顺序,单线程中除了依赖关系的按照代码顺序,没有依赖关系的则排序任意。举个例子。如下建立两个原子变量,线程1中执行赋值操作A,B,线程2中执行读取操作C,D。因为Relaxed ordering只保证操作A,B,C,D是原子操作,A,B之间没有依赖关系,C,D之间也没有依赖关系,所以线程1中执行顺序可以是A,B,也可以是B,A,线程2中执行顺序可以是C,D,也可以是D,C,线程1和线程2之间也没有任何同步关系,所以线程1和线程2同时执行时,A,B,C,D可以是任意顺序,如果D在A之前执行,例如执行顺序是B,D,C,A,则D指令断言会出现失败,因为A操作还没有写入f为true。例子中C操作的 while循环,只是保证B操作执行完。实际应用中可以不用循环。
atomic
atomic
// thread1
f.store(true, memory_order_relaxed);//A
g.store(true, memory_order_relaxed);//B
// thread2
while(!g.load(memory_order_relaxed));//C
assert(f.load(memory_order_relaxed));//D
如果存在依赖关系,把B改成g.store(f, memory_order_relaxed);,g依赖于f,则线程1中执行顺序只能是A,B,线程2中还是任意顺序CD,或者DC。线程1和线程2中执行顺序还是任意顺序,只是A必须在B前面。可以是ABCD、ACBD,DABC等;D还是有可能在A之前执行,所以D还是会出现断言失败。怎么保证A一定在D之前执行,让断言不失败呢,也是要控制两个线程中的两条指令的顺序,可以使用Release – acquire顺序关系来实现。
2.2 Release – acquire
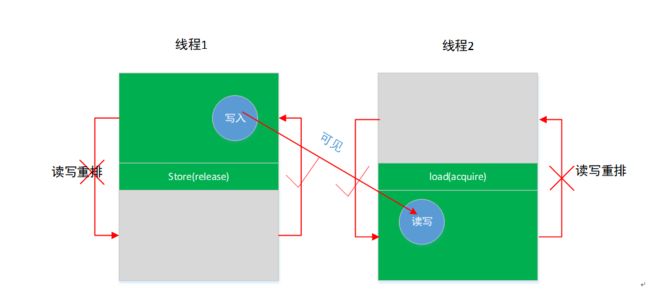
多线程并发是为了提高效率,多线程同步是为了解决同时访问同一个变量的问题,线程1中g.store(release)写变量和线程2中g.load(acquire)读变量组合使用,并不是保证g.store(release)一定在g.load(acquire)之前执行,如果线程1一直sleep几秒,线程2会执行g.load(acquire)命令。这里的同步是指线程1中g.store(release)之前读写不能被重排到g.store(release)之后,线程2 g.load(acquire)之后的读写不能被重排到g.load(acquire)之前,如果g.store(release)先于g.load(acquire)之前执行(前提),那么线程1中g.store(release)之前的读写对线程2中g.load(acquire)之后的读写可见。如果g.load(acquire)先于g.store(release)之前执行,那么无法保证线程1中g.store(release)之前的读写对线程2中g.load(acquire)之后的读写可见。总结三点如下:
(1) load(acquire)所在的线程中load(acquire)之后的所有写操作(包含非依赖关系),不允许被移动到这个load()的前面,一定在load之后执行。
(2) store(release)之前的所有读写操作(包含非依赖关系),不允许被重排到这个store(release)的后面,一定在store之前执行。
(3) 如果store(release)在load(acquire)之前执行了(前提),那么store(release)之前的写操作对 load(acquire)之后的读写操作可见。
例如
bool f=false;
atomic
// thread1
f=true//A
g.store(true, memory_order_release);//B
// thread2
while(!g.load(memory_order_ acquire));//C
assert(f));//D
根据规则(1),线程1中A不允许被重排到B之后,根据规则(2)D不允许被重排到C之前,根据规则(3),因为C中有while循环,一直等待,等到B执行完了,C中循环才退出,保证B在C之前执行完,A又一定在B之前执行完,那么D读到就永远是true,永远不会失败。如果C没 循环,即使加了release和acquire,也不能保证B在C之前执行,D也可能会出现失败。
release -- acquire 有个牛逼的副作用:线程 1 中所有发生在 B 之前的A操作,都会在B之前执行,D也一定在C之后执行,A,D好像很无辜,无缘无故的就被强制顺序了。如果不想让A,D被顺带强制顺序,可以使用Release – consume。
2.3 Release – consume
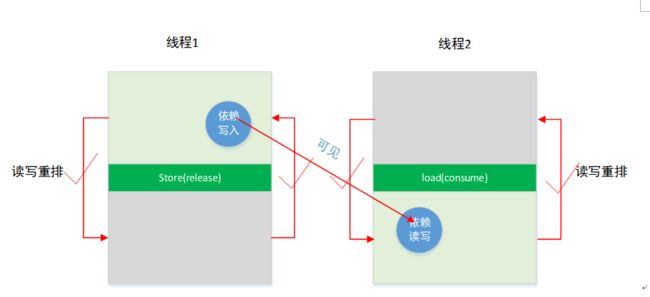
(1)Release – consume实例
Release – consume也是实现多线程之间指令的同步问题,与Release – acquire不同的是,Release – consume不会限制线程中其他变量的顺序重排,不会顺带强制其前后其他指令(无依赖关系)的顺序。避免了其他指令强制顺序带来的额外开销。例如:
bool f=false;
atomic
// thread1
f=true//A
g.store(true, memory_order_release);//B
// thread2
while(!g.load(memory_order_consume);//C
assert(f));//D
同样的例子例子中使用了release和consume关系,不会限制A、B和C、D指令的顺序,可以任意重排,线程1中可以是AB,BA,线程2中可以是CD,DC。线程1和线程2可以是任意的排列组合。所以D有可能断言失败。这种情况和relax是一样的。
(2)Release – consume依赖关系变量限制重排
有依赖关系的变量的指令顺序还是会按照代码顺序去执行,如果AB之间有依赖关系例如下面的例子:
bool f=false;
atomic
// thread1
f=true//A
g.store(f, memory_order_release);//B g依赖于f
// thread2
while(!g.load(memory_order_consume);//C
assert(f));//D
因为B中的变量g依赖于f,所以线程1中指令顺序只能是AB,线程2中D一定成功,因为在线程1中g依赖于f,所以A一定在B之前执行,线程2中D也被限制不能重排到C之前,C中的while循环会一直等到g变为true,说明f已经为true,那么D永远成功。
(3)relax和consume的区别
那么relax和consume不是一样吗?都是线程中有依赖关系就按照代码顺序。否则可以任意排序,relax和consume的区别是什么?如下面的例子所示,将release和consume都换成relax。
bool f=false;
atomic
// thread1
f=true//A
g.store(f, memory_order_relax);//B g依赖于f
// thread2
while(!g.load(memory_order_ relax);//C
assert(f));//D
线程1中g依赖于f,所以按照代码顺序,A在B之前执行。因为在线程2中CD之间没有依赖关系,所以线程2中CD可以任意重排。而如果是consume,那么线程2中就只能是CD顺序,不能被重排。因为线程1中依赖关系也影响了线程2中的指令重排限制,线程中B之前的依赖变量写入对线程2中C之后的依赖变量的读取可见。这就是relax和consume的区别。
2.4 memory_order_acq_rel

对读取和写入施加 acquire-release 语义,也就是g.store(acquire-release)或者g.load(acquire-release)前面无法被重排到后面,后面无法被重排到前面。
可以看见其他线程施加 release 之前的所有写入,同时自己之前所有写入对其他施加 acquire 语义的线程可见。例如下面的例子:
bool f=false;
atomic
bool h=false;
// thread1
f=true//A
g.store(true, memory_order_release);//B
// thread2
while(!g.load(memory_order_ acquire);//C
assert(f));//D
assert(h);//E
//thread3
h=true;//F
while(!g.load(memory_order_acq_rel);//G
assert(f));//H
根据规则,线程1中A操作不允许被重排到B之后,线程2中DE操作不允许被重排到C之前。线程3中F操作不允许被重排到G之后,H操作不允许被重排到G之前。
线程1中A操作写入对线程2中D读取以及线程3中H操作的读取都是可见,即DH在g为true的前提下,读到的一定是true;同时线程3中F操作的写入对线程2中E操作的读取可见,即E操作在g为true的前提下,读到的一定是true。
2.5 Sequentially-consistent ordering
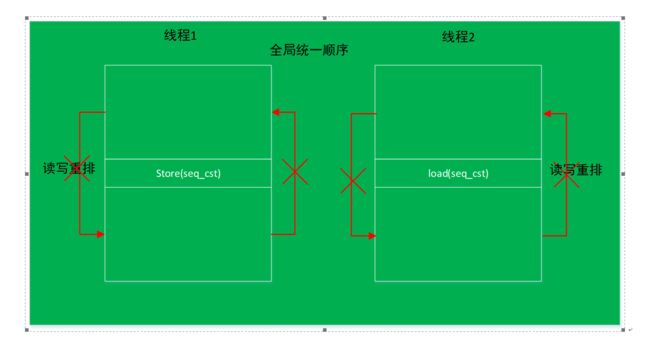
默认情况下,std::atomic使用的是 Sequentially-consistent ordering,除了包含release/acquire的限制,同时还建立一个对所有原子变量操作的全局唯一修改顺序。即采用统一的全局顺序,所有的线程看到的顺序是一致的。会在多个线程间切换,达到多个线程仿佛在一个线程内顺序执行的效果。即单线程中按照代码顺序,多线程之间按照一个全局统一顺序,具体什么顺序按照时间片的分配。
举例如下
// 顺序一致
std::atomic
std::atomic
void write_x()
{
x.store(true,std::memory_order_seq_cst);//A
}
void write_y()
{
y.store(true,std::memory_order_seq_cst);//B
}
void read_x_then_y()
{
while(!x.load(std::memory_order_seq_cst));//C
if(y.load(std::memory_order_seq_cst))//D
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_seq_cst));//E
if(x.load(std::memory_order_seq_cst))F
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
上面一共四个线程,假如四个线程同时启动,那ABCDEF6条指令按照什么顺序执行呢?四个线程并发执行,都可能先执行,总的全局顺序会选择下图中的一条环线顺序开始执行,而且对所有的线程来说都是按照这个全局顺序执行。
例如按照ACDBEF的顺序执行,假如线程write_x先分配到时间片,A先执行,x变为true,线程read_x_then_y中C操作while循环退出,D操作执行,B执行,y变为true,E中while循环退出,执行F。
再比如ABCDEF,ACBEDF等,只是C一定在D之前,E一定在F之前。

2.6 总结
六种模型参数本质上是限制单线程内部的指令重排顺序,并不是同步不同线程之间的指令顺序,而是通过限制单线程中指令的重排,以控制带有模型参数的变量前后的指令被重排顺序限制。这种限制,决定了以atomic操作为基准点(边界),对其之前的内存访问命令,以及之后的内存访问命令,能够在多大的范围内自由重排。上面的例子中,使用while循环,来一直等待,是为了保证store为true后,load为true,从而退出while循环,因为store之前的写指令在store之前完成,所以store之前的写指令对while(load(acquire))之后的写指令可见,while循环一直等待,强制了多线程间两个指令的顺序,这样写只是为了说明原理,实际应用中不会这样去编程。
3 参考文献
如何理解 C++11 的六种 memory order? - 知乎
https://en.cppreference.com/w/cpp/atomic/memory_order
C++11的6种内存序总结_Andrew LD-CSDN博客_memory_order_relaxed
内存顺序(Memory Order) - 知乎
理解 C++ 的 Memory Order | Senlin's Blog