[C++ 网络协议] 多线程服务器端
具有代表性的并发服务器端实现模型和方法:
多进程服务器:通过创建多个进程提供服务。
多路复用服务器:通过捆绑并统一管理I/O对象提供服务。
多线程服务器:通过生成与客户端等量的线程提供服务。✔
目录
1. 线程的概念
1.1 为什么要引入线程
1.2 线程和进程的差异
2.线程函数
2.1 线程的创建
2.1 分离线程
3. 线程存在的问题和临界区
4. 线程安全
5. 线程同步
5.1 互斥量(Mutual Exclusion)
5.1.1 概念
5.1.2 互斥量的创建
5.1.3 互斥量的销毁
5.1.4 上锁和解锁
5.2 信号量
5.2.1 概念
5.2.2 创建信号量
5.2.3 销毁信号量
5.2.4 post和wait
6. 多线程服务器端的实现
1. 线程的概念
1.1 为什么要引入线程
之前学习的内容中,讲解了多进程服务器端的实现方法,明确了其缺点:
- 创建进程的过程会带来一定的开销
- 为了完成进程间的数据交换,要进行特殊的IPC技术(管道通信等)
- 每秒多次的上下文切换(进程A和进程B之间切换运行,操作系统要先将进程A的相关信息移出内存,再读入进程B的相关信息),带来的巨大开销
所以,为了保持多进程的优点,同时在一定程度上客服其缺点,就引入了线程,也被称为“轻量级进程”,其相比于进程有如下优点:
- 线程的创建和上下文切换比进程的创建和上下文切换更快。
- 线程间的通信,无需特殊技术。
1.2 线程和进程的差异
对于进程来说,每次创建新进程,都要复制旧进程的整个内存区域,包括:全局数据区、堆区、栈区。但如果创建进程只是为了获得多个代码执行流,那么就不应该复制整个进程的内存区域。如图:
![[C++ 网络协议] 多线程服务器端_第1张图片](http://img.e-com-net.com/image/info8/ce4b2732e3b44c0da0dff5e6f7006cd2.jpg)
所以,线程共享数据区、堆区,而分离栈区,进程是分离整个内存区。
进程和线程可以定义为如下形式:
进程:在操作系统构成单独执行流的单位
线程:在进程中构成单独执行流的单位
线程和进程的关系:
进程就像是一个装有线程的篮子,里面的运行注意都是线程,main函数的执行也是由线程来执行的,一般被称为主线程。如图:
![[C++ 网络协议] 多线程服务器端_第2张图片](http://img.e-com-net.com/image/info8/a6c5ba5b21e743729bf9ae7b0eff1e37.jpg)
2.线程函数
2.1 线程的创建
#include
int pthread_create(
pthread_t* restrict thread, //保存新创建线程ID的变量地址值
const pthread_attr_t* restrict attr, //传递线程属性的参数,传递NULL,创建默认属性的线程
void* (*start_routine)(void*), //线程的main函数,单独执行流中执行的函数地址值
void* restrict arg //第三个参数调用函数时要传入的参数信息的变量地址值
);
成功返回0
失败返回其他值 restrict关键字:它只可以用于限定和约束指针,并表明指针是访问一个数据对象的唯一且初始的方式.即它告诉编译器,所有修改该指针所指向内存中内容的操作都必须通过该指针来修改,而不能通过其它途径(其它变量或指针)来修改。这样做的好处是,能帮助编译器进行更好的优化代码,生成更有效率的汇编代码。
线程的代码在编译时命令行需要添加-lpthread的声明来连接线程库,如:
gcc thread.c -o thr -lpthread
传递多个参数的方法:定义一个结构体,存放参数,然后进行指针的转换。
struct thread_param { int fd; sockaddr_in addr; }; int main() { ...... thread_param params; params.fd=clientfd; params.addr=clientAddr; pthread_create(&clientthread,NULL,thread_client_handle,(void*)¶ms); } void* thread_client_handle(void* args) { thread_param params=*(thread_param*)args; int clientfd=params.fd; sockaddr_in clientAddr=params.addr; ...... }
2.1 分离线程
#include
int pthread_join(
pthread_t thread, //要分离的线程ID
void** statrus //保存线程的main函数的返回值的指针变量地址值
);
成功返回0
失败返回其他值 函数功能:阻塞住主线程的运行,直到这个子线程运行结束,被销毁后,主线程才会继续执行。
#include
int pthread_detach(
pthread_t thread //要分离的线程ID
);
成功返回0
失败返回其他值 函数功能:不会阻塞主线程的运行,子线程自己运行结束后,自己进行销毁。调用该函数后,不能再调用pthread_join。
3. 线程存在的问题和临界区
当有多个线程同时访问一个共享数据时,就很大概率导致意想不到的错误发生。例如:
当有2个线程访问同一个全局变量num初始值为100,并都要对其进行+1操作,理想情况下得到的值应该是102,但可能会有如下情况的发生:
1.线程A首先访问变量num,要给num进行+1的操作,其会做以下事情
A.首先从全局数据区中读取num的值。
B.再将其传递到CPU,让CPU计算后,得到其结果。
C.再把值写入到num变量中。
2.在线程A执行到C之前,此时线程B就读取了num的值,然后当线程B执行完以上步骤时,此时num的值已经变为了101,但是线程A此时也同时进行了C步,那么num最终的结果将仍然是101,这并不是理想的结果。
所以可能会出现各种不同的问题。这样所有线程都执行的函数,这类函数内部就存在临界区。
临界区的位置是在:函数内同时运行多个线程时引起问题的多条语句构成的代码块。
我们要如何避免这种线程共享数据的问题的发生?
1.使用线程安全的函数
2.实现线程同步
4. 线程安全
根据临界区是否引起问题,函数可以分为两类:
1.线程安全函数:被多个线程同时调用也不会引发问题的函数。一般来说,大部分标准函数都是线程安全函数。
2.非线程安全函数:与线程安全函数相反,多个线程调用可能会引发问题。
怎么使用线程安全函数?
1.平台在定义非线程安全函数的同时,就提供了具有相同功能的线程安全函数。具有线程安全函数的名称后缀通常为_r。例如:gethostbyname(非线程安全函数),gethostbyname_r(线程安全函数)。
2.或者可以在头文件处,声明_REENTRANT宏,声明了此宏,就会将程序内的函数自动改为线程安全函数调用。
或者在编译时加上gcc -D_REEDTRANT thread.c -o thread -lpthread
5. 线程同步
线程同步一般涉及如下两个情况:
1.同时访问统一内存空间时的情况。(互斥量)
2.指定访问统一内存空间的线程执行顺序的情况。(信号量)
5.1 互斥量(Mutual Exclusion)
5.1.1 概念
互斥量是一种同步技术,其提供锁机制,当某一个线程在调用临界区代码时,可以使用互斥量将临界区保护起来,即将其锁住,其他线程将会等待此线程解锁之后,才进入调用临界区代码。
5.1.2 互斥量的创建
方式一:
#include
int pthread_mutex_init(
pthread_mutex_t* mutex, //创建互斥量时传递保护互斥量的变量地址
const pthread_mutexattr_t* attr //传递创建的互斥量的属性,传递NULL则默认
);
成功返回0
失败返回其他值 方式二:
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;不推荐第二种方式,因为不容易发现错误。
5.1.3 互斥量的销毁
#include
int pthread_mutex_destroy(
pthread_mutex_t* mutex, //销毁互斥量时传递的互斥量地址值
);
成功返回0
失败返回其他值 5.1.4 上锁和解锁
#include
int pthread_mutex_lock(pthread_mutex_t* mutex);
int pthread_mutex_unlock(pthread_mutex_t* mutex);
成功返回0
失败返回其他值 注意:上锁(lock)后一定要记得解锁(unlock),不然其他线程将一直处于阻塞状态,造成死锁。
5.2 信号量
5.2.1 概念
信号量也是一种同步技术,利用二进制信号量(只用0和1)来完成控制线程顺序为中心的同步方法。
5.2.2 创建信号量
#include
int sem_init(
sem_t* sem, //创建信号量时传递保存的信号量的变量地址值
int pshared, //传递其他值时,创建可以多个进程共享的信号量
//传递0时,创建只允许一个进程使用的信号量
unsigned int value //创建的信号量的初始值
);
成功返回0
失败返回其他值 5.2.3 销毁信号量
#include
int sem_destroy(sem_t* sem); //销毁时传递需要销毁的信号量变量地址值
成功返回0
失败返回其他值 5.2.4 post和wait
#include
//sem是传递保存信号量读取值的变量地址值
int sem_wait(sem_t* sem); //信号量-1,类似于互斥量的lock
int sem_post(sem_t* sem); //信号量+1,类似于互斥量的unlock
成功返回0
失败返回其他值
调用sem_wait时,因为信号量的值不能<0,所以当线程执行sem_wait时sem的值是0时,那么线程此时就会阻塞住,当sem的值是1,线程会继续执行,同时会将sem减为0。如:
sem_t signal=1;
sem_wait(&signal); //signal变为0,且继续执行
...
sem_post(&signal); //signal变为1
sem_t signal2=0;
sem_wait(&signal2); //signal为0,阻塞状态
...
sem_post(&signal2); //signal变为1要保证线程的访问顺序,需要两个信号量,如下面的代码,需要保证线程A先处理,线程B再取值。
static sem_t sem_one;
static sem_t sem_two;
int main()
{
sem_init(&sem_one,0,0); //sem_one初始化为0
sem_init(&sem_two,0,1); //sem_two初始化为1
......
//线程A先create和join
}
void* Handle(void* arg) //线程A
{
sem_wait(&sem_two); //先进入执行,将sem_two置为0,等待线程B执行结束,将sem_two置为1,再第二次执行
......
sem_post(&sem_one);
}
void* accu(void* arg) //线程B
{
sem_wait(&sem_one); //等待线程A执行到sem_post(&sem_one)将其置为1
......
sem_post(&sem_two);
}6. 多线程服务器端的实现(聊天室)
实现思路:
服务器端作为一个中转站,将一个客户端发送的消息,发送给另一个客户端。
map容器:key是ip地址,value是文件描述符,每连接一个客户端把这个客户端的ip地址和文件描述符以键值对的形式存入map中。
message结构体:客户端之间接收和发送的数据,里面存有要发送的客户端的ip地址,以及聊天消息内容。
mutex互斥量:保护对map进行插入的代码段的临界区。
服务器端代码:
#define _REENTRANT
#include
#include
#include
#include
#include
#include
#include
#include
#include 客户端实现思路:
先输入要交流的对象的IP地址,然后创建一个子线程,主线程写,子线程读。
客户端代码:
#include
#include
#include
#include
#include
#include
struct message
{
char ip[17];
char content[100];
};
void* thread_read(void* arg);
std::string strIp;
int main()
{
int clientfd=socket(PF_INET,SOCK_STREAM,IPPROTO_TCP);
if(clientfd==-1)
{
std::cout<<"socket fail!"<>strIp;
pthread_t readthread;
pthread_create(&readthread,NULL,thread_read,(void*)&clientfd);
pthread_detach(readthread);
std::string chatcontent;
while(1)
{
std::cout<<"您(输入'Q'退出聊天):";
std::cin>>chatcontent;
if(chatcontent.compare("Q")==0)
{
break;
}
message msg;
strcpy(msg.ip, strIp.c_str());
strcpy(msg.content, chatcontent.c_str());
write(clientfd,(const char*)&msg,sizeof(msg));
}
close(clientfd);
}
void* thread_read(void* arg)
{
int clientfd=*(int*)arg;
char buff[1024];
int readLen;
while((readLen=read(clientfd,buff,sizeof(buff))))
{
message* msg=(message*)buff;
std::cout<<"对方(IP:"<content< 执行结果:
服务器:
![[C++ 网络协议] 多线程服务器端_第3张图片](http://img.e-com-net.com/image/info8/e85dafec142f421a90e456f804b90ca7.jpg)
客户端1:

客户端2:
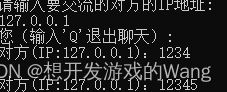
其实这种通过IP地址来确定要发送的客户端的实现是有问题的:每个客户端作为主机在连接到因特网上时,电信/联通网会分配动态IP地址,所以这种向服务器端传IP地址从而建立沟通通道的效果行不通。建议是每个客户端主机都能有一个唯一标识,来进行判断。