Dapper入门
Dapper
一、dapper是什么
dapper是一款轻量级的ORM(Object Relationship Mapper),它负责**数据库和编程语言之间的映射。SqlConnection,MysqlConnection,OracleConnection都是继承于DBConnection,而DBConnection又是实现了IDBConnection的接口。因为Dapper是对IDBConnection接口进行了方法扩展**,比如你看到的SqlMapper.cs,所以dapper支持多数据库。
二、dapper的简单使用
Dapper总结(一)—基本CRUD操作 (wjhsh.net)
https://www.cnblogs.com/nsky/p/8425410.html
0、准备的测试类
1 //用户类
2 public class UserInfo
3 {
4 public int UId { get; set; }//用户Id
5 public string UserName { get; set; }//用户名
6 public int Age { get; set; }//年龄
7 public int RoleId { get; set; }//角色Id
8
9 }
10 //角色类
11 public class RoleInfo
12 {
13 public int RId { get; set; }//角色Id
14 public string RoleName { get; set; }//角色名
15 }
1、execute方法,返回值为int类型,表示受影响行数
var conn = new SqlConnection(ConfigurationManager.ConnectionStrings["connString"].ConnectionString);
Model.Show insert = new Model.Show { name = "insert", remark = "新增" };
//以下注意一点:下面操作是基于多个文件来的,所以可能出现不同的字符串(例如:Show是一个表)
//插入数据
2 //单条数据插入
3 int result = conn.Execute("insert into userinfo values(@username,@age,@roleid)", new
4 {
5 @UserName = "user1", //是否加前缀 @ 都可以
6 Age = 20,
7 RoleId = 1
8 }); // result=1
9
10 //多条数据插入
11 List users=new List(){
12 new UserInfo(){UserName="user2",Age=22,RoleId=1},
13 new UserInfo(){UserName="user3",Age=23,RoleId=1},
14 new UserInfo(){UserName="user4",Age=24,RoleId=2},
15 };
int result2 = conn.Execute("insert into userinfo values(@username,@age,@roleid)", users); // result2=3
//匿名类也行
var anonymous = new List {
new {name="51",remark="2"},
new {name="61",remark="2"},
new {name="71",remark="2"},
new {name="81",remark="2"},
};
//批量插入
int r1 = conn.Execute("insert into show (Name,remark)values(@name,@remark)", anonymous);
19 //修改
20 int rusultEdit = conn.Execute("update userinfo set age=25 where username=@username", new { UserName = "user0" });
Model.Show insert = new Model.Show { id = 258, name = "insert", remark = "新增" };
//传对象
conn.Execute("update show set name='update' where id =@id", insert);
//删除
int id = 250;
conn.Execute("delete show where id = @id", new { id }); //变量名id必须跟@id匹配。才能映射
23 int resultDel = conn.Execute("delete from userinfo where uid=@uid", new { UId = 6 }); //也可以
//删除也可以传对象
Model.Show insert = new Model.Show { id = 256, name = "71", remark = "新增" };
conn.Execute("delete show where id = @id and name=@name", insert); //也可以
2、Query方法,返回值为IEnumerable类型
1 //带参数查询 例子:查询用户名为user1,年龄为20的用户[dapper自动可以Mapper到Object]
2 IEnumerable query1 = conn.Query("select * from userinfo where age=@Age and username=@username", new{Age=20,UserName="user1"})
//in查询 例子:查询年龄是20,21,或22的用户
5 IEnumerable query2=conn.Query("select * from userinfo where age in @ages",new {ages=new int [3]{20,21,22}});
conn.Query("select * from show where id in (@ids)", new { ids=252 });//这样写的方式 in 后面的有括号和没有括号的区别
dapper 多表查询,dapper可以实现多个sql一起查询,然后返回多个结果。需要用QueryMultiple 方法
比如:三个条件的sql
string multsql = @“select * from show where id=@id
select * from show where name=@name
select * from show where remark=@remark”;
当然。我这里都是from show ,你可以from A from B from C 都是可以的
//多表查询 这里不单单是一个表的查询,可以是多个表 from A from B...
string multsql = @"select * froExecutem show where id=@id
select * from show where name=@name
select * from show where remark=@remark";
SqlMapper.GridReader gridReader = conn.QueryMultiple(multsql, new { id = 1, name = "张三", remark = "海南" });
if (!gridReader.IsConsumed) //没有释放 true代表释放
{
var g1 = gridReader.Read(); //转实体类
var g2 = gridReader.Read();
var g3 = gridReader.Read();
//var g4 = gridReader.Read(); //基本读取方式,只返回3个表。不能读第4次
}
//返回多个结果集 例子:查询用户列表和角色列表
8 var sql = "select * from userinfo; select * from roleinfo";
9 var query3 = conn.QueryMultiple(sql);//GridReader类型
10 var usesList = query3.Read();//IEnumberable类型
11 var roleList = query3.Read();
可以看到。QueryMultiple 有两种读取方式 ,很方便
var g3 = gridReader.Read
var g4 = gridReader.Read(); //基本读取方式
GridReader(网格读者)类型
这里需要注意 的是,参数部分顺序:new { id = 1, name = “张三”, remark = “海南” }
需要跟sql 中参数的顺序是一一对应的。 id=@id name=@name remark=@remark
Read读取的顺序也需要返回的顺序一样,返回几个表。就只能Read几次
query join 操作
dapper 提供了join操作,
比如我现在有两个表join
select * from Show s right join info i on s.Name = i.Name

var ss1 = conn.Query("select * from Show s right join info i on s.Name = i.Name", (show, info) =>
{
show.info = info;
return show;
});
看看Query参数,一个泛型委托 Func

这里用到了select * 这样查询效率是不可取的,
在实际中。我们一般会select 出需要的字段,或者指定字段。或者过滤不需要的字段
比如:select s.Name,s.remark,s.id,i.name,i.address,i.id from Show s right join info i on s.Name = i.Name
执行结果后。你会发现 info 中除了id有值,其余属性是没有获取到值的(i.address本应该有值)
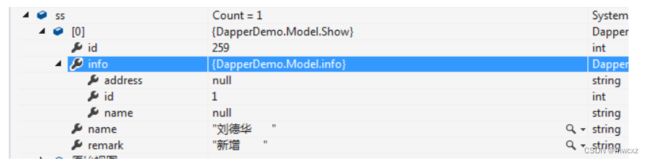
看下Query方法有个默认值, splitOn = “Id”
(ll in this we go right to left through the data reader in order to cope with properties that arel/
named the same as a subsequent primary key that we split on
在这种情况下,我们**从右到左**通过数据读取器来处理属性,这些属性与我们分割的后续主键相同。)
其实说白了就是:splitOn所采用的方法就是**对我们所要获得的属性列表list从右到左进行查找**,如果查找到了 **splitOn = “Id”**中的这个Id属性那么就将list一分为二,左边属于TFirst 右边属于TSecond.
我的sql中select s.Name,s.remark,s.id,i.name,i.address,i.id
Dapper找到了最后一个id。来分割读取数据。分割后。左边是前面的表(show)右边是后面的表(info),
也就是方法中的 TFirst 和TSecond

然后分别映射
这就是为什么show有值,而info只有id有值的原因

为了进一步测试我说的正确性。我修改sql :select s.Name,s.remark,s.id,i.name,i.address
如果按照上面说的。s.id应该是show表的id。那么分割后,映射到了info表,执行看看结果,是正确的
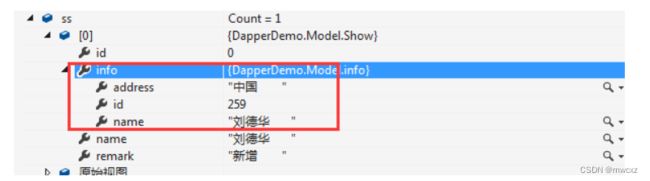
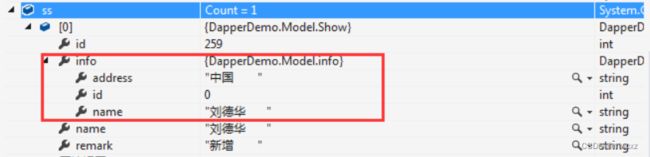
要解决这个问题。就只能手动指定splitOn的值。这里应该是splitOn:name(以属性name进行分割)
修改代码:

执行结果正确了。info的id没值。是因为select 过滤掉了
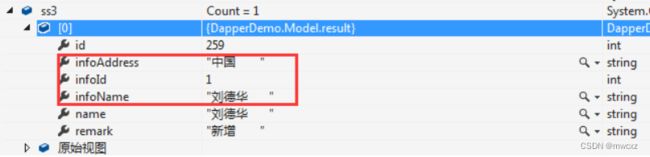
当然。这样仅仅 是两个表join。如果是三个表,或者更多。在项目中还是有的吧,2个以上的表join利用splitOn进行分割就不可取了
可以**把多个类整合到一个类下面**。show和info都有同名 的name。所以需要取别名

修改sql
select s.Name,s.remark,s.id ==,i.name as infoName,i.address as infoAddress,i.id as infoId==from Show s right join info i on s.Name = i.Name
var ss3 = conn.Query("select s.Name,s.remark,s.id ,i.name as infoName,i.address as infoAddress,i.id as infoId from Show s right join info i on s.Name = i.Name");
执行结果:
注意一点:
上面说了 splitOn 默认是id 分割。如果sql中没有指定id。则需要手动指定。否则会报错
比如:我sql中没有默认的id
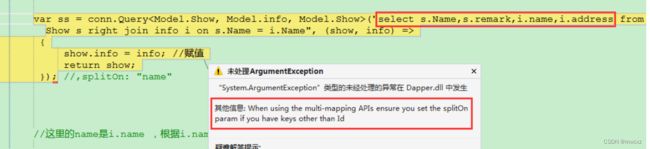
表连接查询
1 //用户类
2 public class UserInfo
3 {
4 public int UId { get; set; }//用户Id
5 public string UserName { get; set; }//用户名
6 public int Age { get; set; }//年龄
7 public int RoleId { get; set; }//角色Id
8
9 }
10 //角色类
11 public class RoleInfo
12 {
13 public int RId { get; set; }//角色Id
14 public string RoleName { get; set; }//角色名
15 }
//表连接查询 例子:查询用户信息和其对应的角色名
14 //1、返回强类型结果
15 var sql2 = @"select u.username,u.age,u.uid ,r.rolename from userinfo as u join roleinfo as r on u.roleid=r.rid";
16 var result2 = conn.Query(sql2, (user, role) =>
17 {
18 user.Role = role;
19 return user;
20 }, splitOn: "RoleName");//splitOn参数表示分割,前边的是第一个对象的属性,后边的是第二个对象的属性
21
22 //2、返回动态类型结果
23 var result3 = conn.Query(sql2);
24 foreach (var item in result3)
25 {
26 Console.WriteLine("username:{0},rolename:{1}", item.username, item.rolename);
27 }
dapper事物
模拟一个删除数据失败,事物回滚的操作
假设删除 id=259的数据
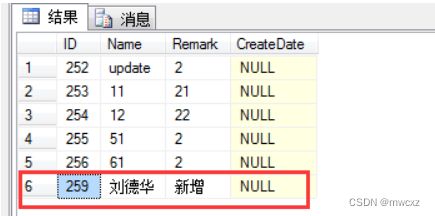
//创建一个事物
using (var trans = conn.BeginTransaction()) //开启数据库事物
{
try
{
conn.Execute("delete show where id = @id", new { id = 259 }, trans);
int a = 0;
int b = 5 / a; //此处会异常,导致事物回滚
trans.Commit(); //提交事物
}
catch (Exception ex)
{
//事物回滚
trans.Rollback();
}
}
运行发现报错:无效操作。连接被关闭。
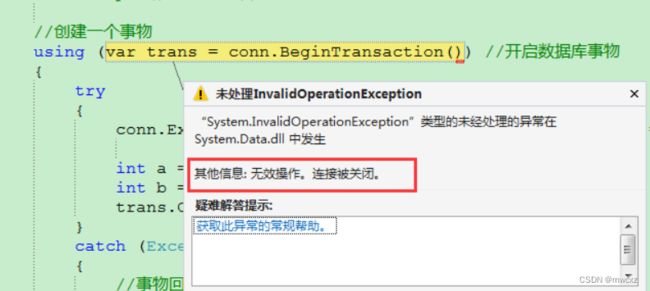
因为dapper**在CRUD操作中会自动判断连接是否打开**:ConnectionState.Closed
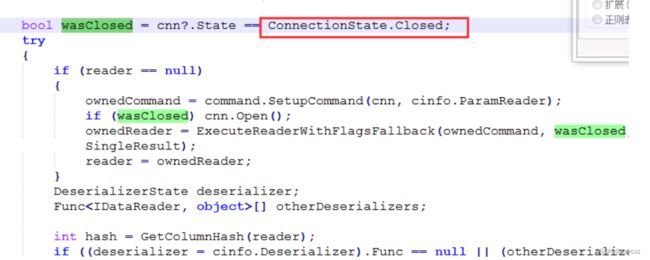
而**事物不会,则需要手动打开连接**
conn.Open(); //先打开连接
事物已经提交。但没有Commit前不会生效,在cath中回滚事物 trans.Rollback();
存储过程的crud格式
创建存储过程
使用Transact-SQL语句创建存储过程
Transact-SQL语言使用CREATE PROCEDURE语句创建存储过程,其一般格式为:
CREATE PROC [ EDURE ] procedure_name [ ;number ]
[ @parameter data_type [ = default ],…]
AS
sql_statement
说明:
procedure_name:给出存储过程名。
number:为可选的整数,对同名的存储过程指定一个序号。
@parameter:为存储过程的形参,@符号作为第一个字符来指定参数名。
data_type:指出参数的数据类型。
default:给出参数的默认值。
sql_statement:存储过程所要执行的SQL语句,它可以是一组SQL语句,可以包含流程控制语句等。
执行存储过程
zTransact-SQL语言使用EXECUTE语句执行存储过程,其一般格式为:
exec dbo.存储过程名 参数值;
一般在执行存储过程是,最好加上架构名称,例如 dbo.USP_GetAllUser 这样可以可以减少不必要的系统开销,提高性能。 因为如果在存储过程名称前面没有加上架构名称,SQL SERVER 首先会从当前数据库sys schema(系统架构)开始查找,如果没有找到,则会去其它schema查找,最后在dbo架构(系统管理员架构)里面查找。
存储过程的修改和删除
1**.修改存储过程Transact-SQL语言使用ALTER PROCEDURE语句修改存储过程,其一般格式为:**
大致同创建
ALTER PROC [ EDURE ] procedure_name [ ;number ]
**[ @parameter data_type [ = default ]****,****…]**
AS
sql_statement
2**.删除存储过程**
Transact-SQL语言使用DROPPROCEDURE****语句删除存储过程,其一般格式为:
ALTER PROC [ EDURE ] procedure_name [ ;number ]
**[ @parameter data_type [ = default ]****,****…]**
AS
sql_statement
【例6-5】 删除存储过程score_find。
DROP PROCEDURE score_find
,
,
,
,
,
,
,
.Net调用存储过程
①不需要获取返回值和输出参数
我这里存储过程,就不在编写了,用之前的列子 http://www.cnblogs.com/nsky/p/7766653.html
用CommandType.StoredProcedure 标记是存储过程
如果只执行存储过程。不需要获取返回值和输出参数。直接这样既可
//不获取输出参数
var qq = conn.Query("[proc_show01]", new { id = 1, ck = 1 }, commandType: CommandType.StoredProcedure);
执行结果:

如果考虑安全,可以用参数化
DynamicParameters dp = new DynamicParameters();
dp.AddDynamicParams(new { @id = 1 });
dp.AddDynamicParams(new { @ck = 1 });
//不获取输出参数
var qq = conn.Query("[proc_show01]", dp, commandType: CommandType.StoredProcedure);
DynamicParameters 还有一个参数的构造函数
可以这样写:
DynamicParameters dp = new DynamicParameters(new { id = 1,ck=1 });
,
,
,
②需要获取输出参数和返回值
//获取输出参数
DynamicParameters dp = new DynamicParameters();
dp.Add("@id", 0, DbType.Int32, ParameterDirection.Output); //输出参数。
dp.Add("@ck", 0, DbType.Int32, ParameterDirection.Output); //输出参数
dp.Add("@returnValue", 0, DbType.Int32, ParameterDirection.ReturnValue); //返回值
var qq1 = conn.Query("[proc_show01]", dp, commandType: CommandType.StoredProcedure);
var ck = dp.Get("@ck"); //输出参数
var id2 = dp.Get("@id"); //输出参数,是新增后的id值
var returnValue = dp.Get("@returnValue");
执行结果:
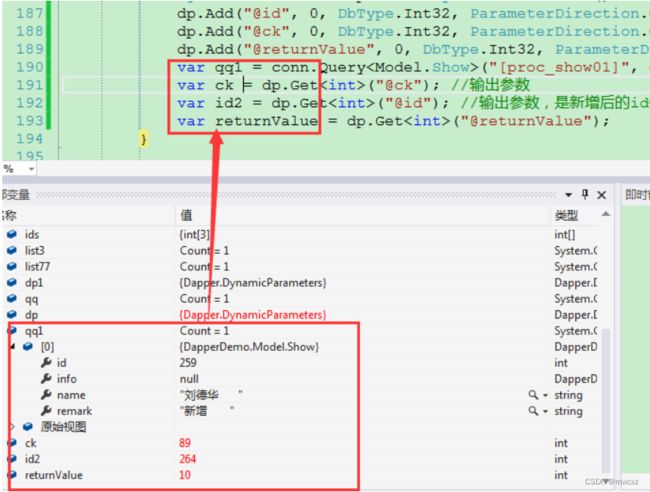
也许你看不明白,这些值的说明。那看看我存储过程的逻辑

存储过程及触发器
sql servre 帮助文档中对存储过程的解释
创建存储过程。存储过程是已保存的 Transact-SQL 语句集合,或对 Microsoft .NET Framework 公共语言运行时 (CLR) 方法的引用,
可接收并返回用户提供的参数。可以创建过程供永久使用,或在一个会话(局部临时过程)中临时使用,或在所有会话(全局临时过程)中临时使用
创建存储过程可以**用 proc或者procedure关键字** proc是简写
编写个简单的存储过程,没有任何参数和返回值的存储过程
USE TestInfo
GO
IF OBJECT_ID('proc_show01','P') IS NOT NULL --存储过程是否存在
DROP PROCEDURE proc_show01 --删除存储过程
GO
CREATE PROC proc_show01
AS
SELECT * FROM Show
执行sql语句成功后,在sql中可以看到存储过程已经创建
OBJECT_ID(object_name,'object_type);函数用于判断对象是否存在
object_type对应的类型如下
AF = Aggregate function (CLR)
C = CHECK constraint --检查约束
D = DEFAULT (constraint or stand-alone)
F = FOREIGN KEY constraint --外键约束
FN = SQL scalar function --函数
FS = Assembly (CLR) scalar-function
FT = Assembly (CLR) table-valued function
IF = SQL inline table-valued function
IT = Internal table
P = SQL Stored Procedure --存储过程
PC = Assembly (CLR) stored-procedure --CLR存储过程
PG = Plan guide
PK = PRIMARY KEY constraint --主键约束
R = Rule (old-style, stand-alone) --规则
RF = Replication-filter-procedure
S = System base table --数据库
SN = Synonym
SQ = Service queue
TA = Assembly (CLR) DML trigger --CLR触发器
TF = SQL table-valued-function
TR = SQL DML trigger --DML触发器
U = Table (user-defined) --数据表
UQ = UNIQUE constraint --唯一约束
V = View --视图
X = Extended stored procedure
比如上面的判断存储过程是否存在 OBJECT_ID('proc_show01','P') 获取存储过程名为:proc_show01
判断表是否存在 OBJECT_ID('info','U') 获取表名为:info
或者:
select * from sysobjects where name='info' and type='u'
SQL Server支持五种类型的完整性约束
NOT NULL (非空)–防止NULL值进入指定的列,在单列基础上定义,默认情况下,ORACLE允许在任何列中有NULL值.
CHECK (检查)–检查在约束中指定的条件是否得到了满足.
UNIQUE (唯一)–保证在指定的列中没有重复值.在该表中每一个值或者每一组值都将是唯一的.
PRIMARY KEY (主键)–用来唯一的标识出表的每一行,并且防止出现NULL值,一个表只能有一个主键约束.
POREIGN KEY (外部键)–通过使用公共列在表之间建立一种父子(parent-child)关系,在表上定义的外部键可以指向主键或者其他表的唯一键.
在.Net转编写测试代码。调用刚创建的存储过程
/// 执行存储过程
///
/// 存储过程的名称
/// 存储过程参数
/// 
编写一个有输入参数的存储过程
USE TestInfo
GO
IF OBJECT_ID('proc_show01','P') IS NOT NULL--存储过程是否存在
DROP PROCEDURE proc_show01 --删除存储过程
GO
CREATE PROC proc_show01
(
@name nvarchar(20)
)
AS
SELECT * FROM Show where @name=Name
编写存储过程的可空参数,当存储过程参数有默认值的时候,
那么.net在调用存储过程的时候。可以不用传参数。否则如果不传这会报错
所以:
除非定义了参数的默认值或者将参数设置为等于另一个参数,否则用户必须在调用过程时为每个声明的参数提供值
USE TestInfo
GO
IF OBJECT_ID('proc_show01','P') IS NOT NULL --存储过程是否存在
DROP PROCEDURE proc_show01 --删除存储过程
GO
CREATE PROC proc_show01
(
@name nvarchar(20) = null --默认值为空
)
AS
IF @name is null
begin
set @name='刘德华' --当没有传值的时候。设置默认值
end
select * from Show where @name = name
--测试。当不传值的时候,默认查询的是 “刘德华”
创建有输入参数和输出参数的存储过程
USE TestInfo
GO
IF OBJECT_ID('proc_show01','P') IS NOT NULL--存储过程是否存在
DROP PROCEDURE proc_show01 --删除存储过程
GO
CREATE PROC proc_show01
(
@id int output, --输出参数,输出id
@name nvarchar(20) = null --默认值为空
)
AS
IF @name is null
begin
set @name='刘德华' --当没有传值的时候。设置默认值
set @id=0
select * from Show where name = @name
--return
end
else
begin
set @id=(select ID from Show where name = @name)
select * from Show where name = @name
end
既然有输出参数。那么得修改上面的.Net代码。如下
///
/// 调用存储过程
///
/// 存储过程名称
/// 输出参数(这里是ID)
/// 参数
/// 在组装参数的时候**。要指定哪些参数是输入参数。哪些是输出参数,默认是输入参数(Input)。**
如果是输入(或者输入输出)参数。则必须要赋值。在存储过程中没有给默认值的情况下
在下图可以看出。有输入参数有两个 Input 和 InputOutput
.Net 有个ParameterDirection 枚举类
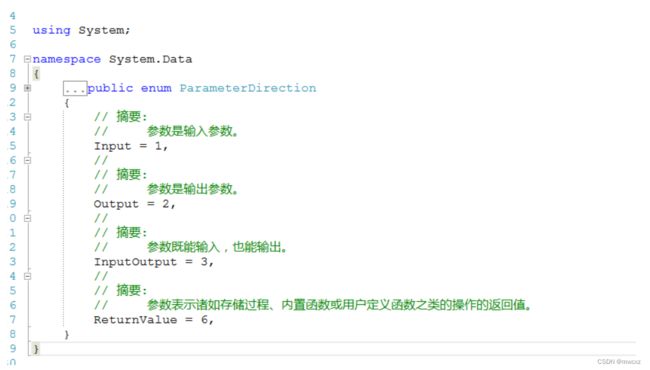
sql 中有out 输出参数,output 输入输出参数
CREATE PROC proc_show01
(
@id int output, --输入输出参数,输出id
@ck int out,
@name nvarchar(20) = null --默认值为空 ,默认是输入参数
)
但在.Net都是output。因为output就是输入输出参数的总称
param[3].Direction = ParameterDirection.Output
测试代码
static void Main(string[] args)
{
//SqlParameter p = new SqlParameter("@name", "张三");
//拼装参数 (定义一个参数对象)
SqlParameter[] param = {
new SqlParameter("@id",SqlDbType.Int),
new SqlParameter("@name",SqlDbType.NVarChar)
};
//设置参数是输出参数
param[0].Direction = ParameterDirection.Output;
param[1].Value = "王五";
int id;
DataTable dt = SQLHelper.GetPro1("proc_show01", out id, param); //没有参数
}
运行看结果
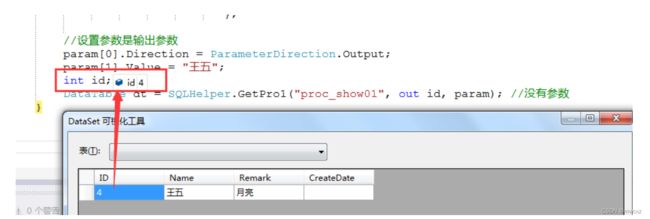
上面用 param[0].Direction = ParameterDirection.Output; 指定第一个参数是输出参数
然后通过 v1 = **Convert*.ToInt32(param[0].Value); 获取存储过程返回的值
从ParameterDirection枚举可以看出输入输出参数都测试过了。还有一个操作的返回值没有测试
有操作类返回值的存储过程
USE TestInfo
GO
IF OBJECT_ID('proc_show01','P') IS NOT NULL--存储过程是否存在
DROP PROCEDURE proc_show01 --删除存储过程
GO
CREATE PROC proc_show01
(
@id int output, --输出参数,输出id
@name nvarchar(20) = null --默认值为空
)
AS
/*
定义一个变量,返回一个值
也可以不定义变量,直接用return 返回
*/
declare @returnValue int
IF @name is null
begin
set @name='刘德华' --当没有传值的时候。设置默认值
set @id=0
select * from Show where name = @name
set @returnValue=10
--return 0 --这里同样可以
end
else
begin
set @id=(select ID from Show where name = @name)
select * from Show where name = @name
set @returnValue=11
end
return @returnValue --返回值
用 ParameterDirection.ReturnValue 指定是返回值
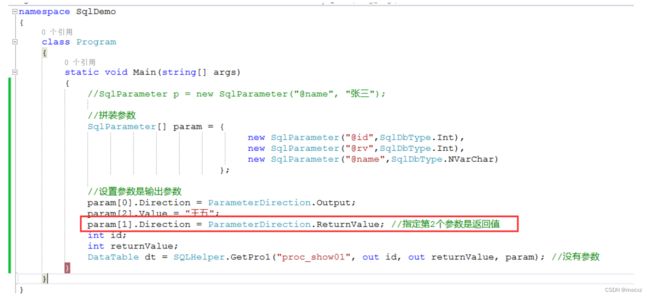
GetPro1则要加一个out 参数
public static DataTable GetPro1(string cmdText, out int v1,out int v2, params SqlParameter[] param)
则: v2 = Convert.ToInt32(param[1].Value);
测试看效果
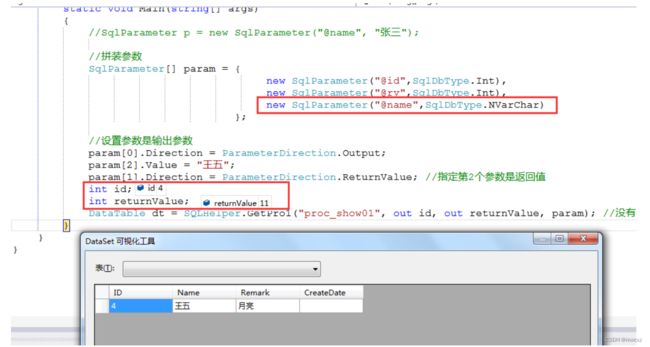
存储过程里面也可以执行一个新增操作。然后返回刚新增的ID,比如:
begin
set @name='刘德华' --当没有传值的时候。设置默认值
--set @id=0
select * from Show where name = @name
set @returnValue=10
--return 0 --这里同样可以
insert Show(Name,Remark)VALUES('新增','地球');
set @id = @@IDENTITY --返回新增的ID
end
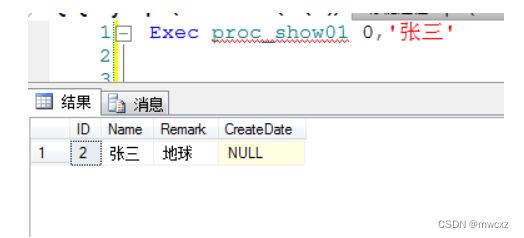
上面都是通过.net代码访问存储过程,那么通过Transact-SQL语句怎么执行呢?
Transact-SQL 语句用exec(简写)关键字 ,全称是execute关键字
因为存储过程的参数顺序是

所以可以这样直接传参数,但顺序必须根据存储过程定义参数顺序一样
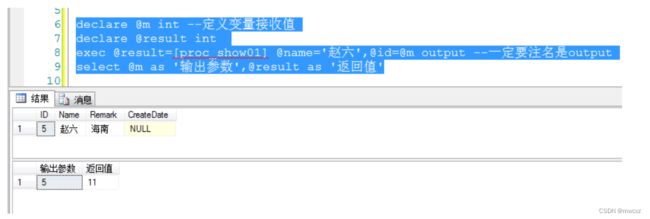
上面只是获取结果集。那么怎获取输出参数(outPut)和返回值呢(ReturnValue)
因为返回值是方法的返回值。所以可以变量名=存储过程名称 是不是跟.Net中很相似?
declare @m int --定义变量接收值
declare @result int
exec @result=[proc_show01] @name='赵六',@id=@m output --一定要注名是output
select @m as '输出参数',@result as '返回值'
执行结果
其实就是参数名= 值 @name=‘赵六’,@id=@m 的方式。因为
一旦使用了 ‘@name = value’ 形式之后,所有后续的参数就必须以 ‘@name = value’ 的形式传递。
用这种方式。顺序可以不用跟存储过程中定义参数的顺序相同
如果不用@name = value’的方式同样可以,
但这样直接传参数,但顺序必须根据存储过程定义参数顺序一样,返回值放在最前面
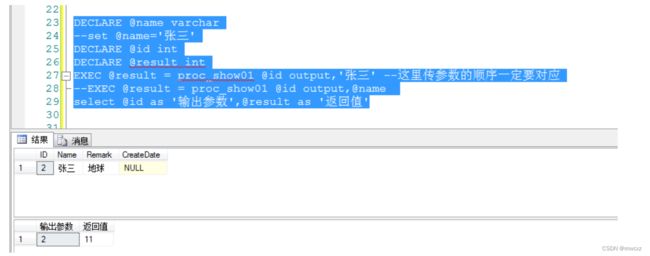
DECLARE @name varchar
--set @name='张三'
DECLARE @id int
DECLARE @result int
EXEC @result = proc_show01 @id output,'张三' --这里传参数的顺序一定要对应
--EXEC @result = proc_show01 @id output,@name
select @id as '输出参数',@result as '返回值'
结果一样,其实不一样。因为传的参数不一样,哈哈哈
使用老师提供的SqlMapperUtil.cs来学习
基于的是控制台
GetMaxID
SqlMapperUtil.cs代码
///
/// return specific table max ID
/// 字段名FieldName要符合max()函数的要求
///
///
///
///
/// (sql, null).Single(); //严格返回一个元素项,否则抛出异常
}
}
Program.cs代码:
Console.WriteLine(SqlMapperUtil.GetMaxID("sname", "student"));
InsertSqlWithReturnId
SqlMapperUtil.cs代码
//返回新插入行的主键Id值
public static int InsertSqlWithReturnId(string sql, dynamic parms, string connectionName = null) {
using (SqlConnection cnn = GetOpenConnection(connectionName)) {
return cnn.Query(sql + ";SELECT CAST(SCOPE_IDENTITY() as int);", (object)parms).Single(); //SCOPE_IDENTITY()取得返回在当前会话中的任何表内所生成的最后一个标识值(返回值为十进制(38,0),所以采用强制类型转换)
}
}
Program.cs代码:
var sql = "insert into Student values(@Sno,@Sname,@Ssex,@Sbirthday,@Sclass)";
int num = SqlMapperUtil.InsertSqlWithReturnId(sql, new
{
Sno = "118",
Sname = "张三",
Ssex = "男",
Sbirthday = "2022/7/2",
Sclass = "研20"
});
Console.WriteLine(num);
Exists
SqlMapperUtil.cs代码
public static bool Exists(string sql, dynamic parms, string connectionName = null) {
using (SqlConnection cnn = GetOpenConnection(connectionName)) {
return cnn.Query(sql, (object)parms).Single() > 0 ? true : false; //cnn.Query()返回值为IEnumerable类型
}
}
Program.cs代码:
var sql = "insert into Student values(@Sno,@Sname,@Ssex,@Sbirthday,@Sclass)";
int num = SqlMapperUtil.InsertSqlWithReturnId(sql, new
{
Sno = "118",
Sname = "张三",
Ssex = "男",
Sbirthday = "2022/7/2",
Sclass = "研20"
});
Console.WriteLine(num);
MultipleSql
public static int MultipleSql(string sql, IEnumerable entities, string connectionName = null) where T : class, new() {
using (SqlConnection cnn = GetOpenConnection(connectionName)) {
int records = 0;
foreach (T entity in entities) {
records += cnn.Execute(sql, entity);
}
return records;
}
}
string multsql = @"select * from Student where Sname=@Sname
select * from Student where Sname=@Sname
select * from Student where Sname=@Sname"
;
var entities =new List { new { Sname = "李军" } , "李军" , "李军" };
Console.WriteLine(SqlMapperUtil.MultipleSql(multsql, entities));
未理解
SqlWithTransaction
public static int SqlWithTransaction(string sql, dynamic parms = null, string connectionName = null) {
using (SqlConnection cnn = GetOpenConnection(connectionName)) {
int records = 0;
//方法一
using (var trans = cnn.BeginTransaction()) { //开启数据库事物
try {
records = cnn.Execute(sql, (Object)parms, trans, 30, CommandType.Text);
trans.Commit(); //提交事物
}
catch (DataException ex) {
trans.Rollback(); //事物回滚
throw ex;
}
}
//方法二TransactionScope不一定比方法一好,原因在: http://stackoverflow.com/questions/10689779/bulk-inserts-taking-longer-than-expected-using-dapper
return records;
}
}
var sql = "select * from course";
Console.WriteLine(SqlMapperUtil.SqlWithTransaction(sql));
//demo2
var sql = "update Student set Ssex= '男' where Sno = '108'";
Console.WriteLine(SqlMapperUtil.SqlWithTransaction(sql));
StoredProcWithTransaction
public static int StoredProcWithTransaction(string procname, dynamic parms = null, string connectionName = null) {
using (SqlConnection cnn = GetOpenConnection(connectionName)) {
int records = 0;
//方法一
using (var trans = cnn.BeginTransaction()) {
try {
records = cnn.Execute(procname, (object)parms, trans, 30, CommandType.StoredProcedure);
trans.Commit();
}
catch (DataException ex) {
trans.Rollback();
throw ex;
}
}
//方法二TransactionScope不一定比方法一好 http://stackoverflow.com/questions/10689779/bulk-inserts-taking-longer-than-expected-using-dapper
return records;
}
}
var parms = new DynamicParameters();
parms.Add("@Sname", "李军");
Console.WriteLine(SqlMapperUtil.StoredProcWithTransaction("getStudentBySname", parms));
//方法2
Console.WriteLine(SqlMapperUtil.StoredProcWithTransaction("getStudentBySname", new{Sname=”李军“}));
CREATE PROCEDURE [dbo].[getStudentBySname]
@Sname nvarchar(20)
AS
begin
select *
from dbo.Student
where @Sname=Sname;
end
go
--通过他们的Sname来查找一个特定的用户

ToDataTable
//由一个list列表得到一个table
public static DataTable ToDataTable(this IList list) {
PropertyDescriptorCollection props = TypeDescriptor.GetProperties(typeof(T)); //获取指定类型组件的属性集合。
DataTable table = new DataTable();
for (int i = 0; i < props.Count; i++) { //创建表格
PropertyDescriptor prop = props[i];
table.Columns.Add(prop.Name, Nullable.GetUnderlyingType(prop.PropertyType) ?? prop.PropertyType);
}
object[] values = new object[props.Count];
foreach (T item in list) { //表格中添加数据
for (int i = 0; i < values.Length; i++)
values[i] = props[i].GetValue(item) ?? DBNull.Value;
table.Rows.Add(values);
}
return table;
}
GetParametersFromObject
///
/// 由一个对象去生成一个动态参数袋
///
///
///
///
SetIdentity
public static void SetIdentity(IDbConnection connection, Action setId) {
dynamic identity = connection.Query("SELECT @@IDENTITY AS Id").Single();
T newId = (T)identity.Id;
setId(newId);
}
GetPropertyValue
public static object GetPropertyValue(object target, string propertyName) {
PropertyInfo[] properties = target.GetType().GetProperties(BindingFlags.Public | BindingFlags.Instance);//获得当前实例的确切运行时类型的属性组
object theValue = null;
foreach (PropertyInfo prop in properties) {
if (string.Compare(prop.Name, propertyName, true) == 0) {
theValue = prop.GetValue(target, null);
}
}
return theValue;
}