k8s-kubernetes--网络策略、flannel网络插件和calico网络插件
文章目录
- 一、k8s网络通信
-
- 1.网络策略
- 2.service和iptables的关系
- 二、pod间通信
-
- 1.同节点之间的通信
- 2.不同节点的pod之间的通信需要网络插件支持(详解)
-
- (1)Flannel vxlan模式跨主机通信原理
- (2)vxlan模式(默认模式)
- (3)host-gw模式:主机网关
- (4)Directrouting:直接路由
- 三、flannel网络插件
- 四、calico网络插件
-
- 1.部署:
- 2.网络策略
-
- (1)限制pod流量
- (2)限制namespace流量
- (3)同时限制namespace和pod
- (4)限制集群外部流量
一、k8s网络通信
抽象的接口层,将容器网络配置方案与容器平台方案解耦
CNI(Container Network Interface)就是这样的一个接口层,它定义了一套接口标准,提供了规范文档以及一些标准实现。采用CNI规范来设置容器网络的容器平台不需要关注网络的设置的细节,只需要按CNI规范来调用CNI接口即可实现网络的设置
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等。
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下:
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
容器间通信:同一个pod内的多个容器间的通信,通过lo即可实现;
pod之间的通信:
同一节点的pod之间通过cni网桥转发数据包。(brctl show可以查看)
不同节点的pod之间的通信需要网络插件支持。
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换。
pod和外网通信:iptables的MASQUERADE。
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
1.网络策略
网络策略官网:https://kubernetes.io/zh-cn/docs/concepts/services-networking/network-policies/
前置条件
网络策略通过网络插件来实现。要使用网络策略,你必须使用支持 NetworkPolicy 的网络解决方案。 创建一个 NetworkPolicy 资源对象而没有控制器来使它生效的话,是没有任何作用的。(Flannel不支持 NetworkPolicy,所以使用Flannei网络插件是不会隔离pod的)
隔离和非隔离的 Pod
默认情况下,Pod 是非隔离的,它们接受任何来源的流量。
Pod 在被某 NetworkPolicy 选中时进入被隔离状态。 一旦名字空间中有 NetworkPolicy 选择了特定的 Pod,该 Pod 会拒绝该 NetworkPolicy 所不允许的连接。 (名字空间下其他未被 NetworkPolicy 所选择的 Pod 会继续接受所有的流量)
网络策略不会冲突,它们是累积的。 如果任何一个或多个策略选择了一个 Pod, 则该 Pod 受限于这些策略的 入站(Ingress)/出站(Egress)规则的并集。因此评估的顺序并不会影响策略的结果。
为了允许两个 Pods 之间的网络数据流,源端 Pod 上的出站(Egress)规则和 目标端 Pod 上的入站(Ingress)规则都需要允许该流量。 如果源端的出站(Egress)规则或目标端的入站(Ingress)规则拒绝该流量, 则流量将被拒绝。
2.service和iptables的关系
service 的代理是 kube-proxy
kube-proxy 运行在所有节点上,它监听 apiserver 中 service 和 endpoint 的变化情况,创建路由规则以提供服务 IP 和负载均衡功能。简单理解此进程是Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上,而kube-proxy底层又是通过iptables和ipvs实现的。
iptables原理
Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。iptables模式下的kube-proxy不再起到Proxy的作用,其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,并更新对应的iptables规则,Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
ipvs原理
IPVS在Kubernetes1.11中升级为GA稳定版。IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为最新模式。
在IPVS模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。
可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,iptables可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能损耗。
kube-proxy ipvs和iptables的异同
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
与iptables相比,IPVS拥有以下明显优势:
- 为大型集群提供了更好的可扩展性和性能;
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- 支持服务器健康检查和连接重试等功能;
- 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。

二、pod间通信
1.同节点之间的通信
同一节点的pod之间通过cni网桥转发数据包。(brctl show可以查看)
2.不同节点的pod之间的通信需要网络插件支持(详解)
(1)Flannel vxlan模式跨主机通信原理

flannel网络
- VXLAN,即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network)。
- VTEP:VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因。
- Cni0: 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。
- Flannel.1: TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
- Flanneld:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息。
flannel网络原理
- 当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
- VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
- 内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
- Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
- flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
- linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
- 此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
flannel支持多种后端:
- Vxlan
vxlan //报文封装,默认
Directrouting //直接路由,跨网段使用vxlan,同网段使用host-gw模式。
- host-gw: //主机网关,性能好,但只能在二层网络中,不支持跨网络,如果有成千上万的Pod,容易产生广播风暴,不推荐
- UDP: //性能差,不推荐
- flannel网络
VXLAN,即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network)。
VTEP:VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因。
Cni0: 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。
Flannel.1: TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
Flanneld:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息。
- flannel网络原理
当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
- flannel支持多种后端:
1. Vxlan
vxlan //报文封装,默认
Directrouting //直接路由,跨网段使用vxlan,同网段使用host-gw模式。
2. host-gw: //主机网关,性能好,但只能在二层网络中,不支持跨网络,如果有成千上万的Pod,容易产生广播风暴,不推荐
3. UDP: //性能差,不推荐
(2)vxlan模式(默认模式)
[root@server2 ~]# vim damo.yml
[root@server2 ~]# cat damo.yml
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
#clusterIP: None
#type: NodePort
#type: LoadBalancer
externalIPs:
- 172.25.13.100
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo2
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
[root@server2 ~]# kubectl apply -f damo.yml
[root@server2 ~]# kubectl get pod -o wide ##查看详细信息
##下面的命令每一个节点都可以用
[root@server2 ~]# cat /run/flannel/subnet.env
[root@server2 ~]# ip n ##获取对应mac地址
[root@server2 ~]# ip addr ##查看flannel.1对应的mac地址
[root@server4 ~]# bridge fdb
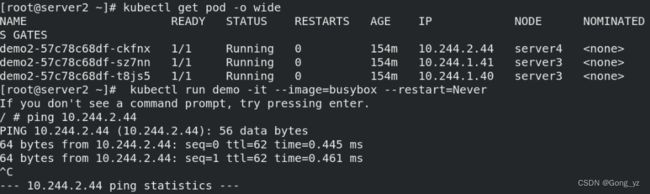
[root@server2 ~]# kubectl attach demo -it
/ # ping 10.244.2.44
[root@server3 ~]# tcpdump -i eth0 -nn host 172.25.70.4
(3)host-gw模式:主机网关

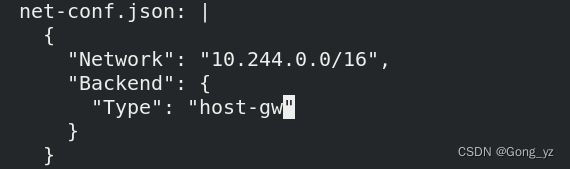
[root@server2 ~]# kubectl -n kube-system edit cm kube-flannel-cfg
Type: ##修改模式为host-gw
[root@server2 ~]# kubectl get pod -n kube-system |grep flannel | awk '{system("kubectl delete pod "$1" -n kube-system")}'
##类似于之前,重启生效,是一个删除在生成的过程
[root@server3 ~]# ip route ##每个节点都可以通过这条命令查看route,也可以用route -n


(4)Directrouting:直接路由
[root@server2 ~]# kubectl -n kube-system edit cm kube-flannel-cfg ##修改模式
[root@server2 ~]# kubectl get pod -n kube-system |grep flannel | awk '{system("kubectl delete pod "$1" -n kube-system")}' ##重新生效


三、flannel网络插件
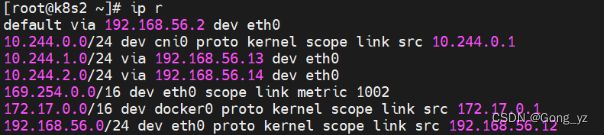
使用host-gw模式:每个网段加了静态路由,就不需要封装后走隧道(隧道接口还在,虚拟机重启后,接口消失)(上面也有此部分演示)
[root@k8s2 ~]# kubectl -n kube-flannel edit cm kube-flannel-cfg

重启pod生效
[root@k8s2 ~]# kubectl -n kube-flannel delete pod --all
加了静态路由 ,访问10.244.1.0,通过eth0访问192.168.56.13即可
访问10.244.2.0,通过eth0访问192.168.56.14即可
四、calico网络插件
官方网址:https://docs.tigera.io/
对比flannel,calico支持网络策略

1.部署:
删除flannel插件
[root@k8s2 ~]# kubectl delete -f kube-flannel.yml
删除所有节点上flannel配置文件,避免冲突,部署完后,会生成calico文件
[root@k8s2 ~]# rm -f /etc/cni/net.d/10-flannel.conflist
[root@k8s3 ~]# rm -f /etc/cni/net.d/10-flannel.conflist
[root@k8s4 ~]# rm -f /etc/cni/net.d/10-flannel.conflist
下载部署文件
[root@k8s2 calico]# wget https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml
修改镜像路径
[root@k8s2 calico]# vim calico.yaml




下载镜像
[root@k8s1 ~]# docker pull docker.io/calico/cni:v3.25.0
[root@k8s1 ~]# docker pull docker.io/calico/node:v3.25.0
[root@k8s1 ~]# docker pull docker.io/calico/kube-controllers:v3.25.0
上传镜像到harbor

部署calico
[root@k8s2 calico]# kubectl apply -f calico.yaml

重启所有集群节点,让pod重新分配IP
[root@server3 ~]# systemctl daemon-reload
[root@server3 ~]# systemctl restart kubelet
等待集群重启正常后测试网络
[root@k8s1 ~]# curl myapp.westos.org
Hello MyApp | Version: v1 | Pod Name
2.网络策略
(1)限制pod流量
[root@k8s2 calico]# vim networkpolicy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: myapp-v1
policyTypes:
- Ingress ##控制入站
ingress:
- from: ##什么样的数据包能进来访问myapp-v1的pod,标签是myapp-v1,就会控制流量
- podSelector:
matchLabels:
role: test ##角色
ports:
- protocol: TCP
port: 80
[root@k8s2 calico]# kubectl apply -f networkpolicy.yaml
构建的策略显示如下图中部分:

控制的对象是具有app=myapp-v1标签的pod

此时访问svc是不通的,得符合网络策略的流量才可以访问

[root@k8s2 calico]# kubectl run demo --image busyboxplus -it --rm
If you don't see a command prompt, try pressing enter.
/ # curl 10.108.1.129 ##不通
给测试pod添加指定标签后,可以访问
[root@k8s2 calico]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
demo 1/1 Running 0 61s run=demo
root@k8s2 calico]# kubectl label pod demo role=test ##加标签和角色
加角色和标签后,在demo,可以访问:

(2)限制namespace流量
[root@k8s2 calico]# vim networkpolicy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: myapp-v1
policyTypes:
- Ingress
ingress:
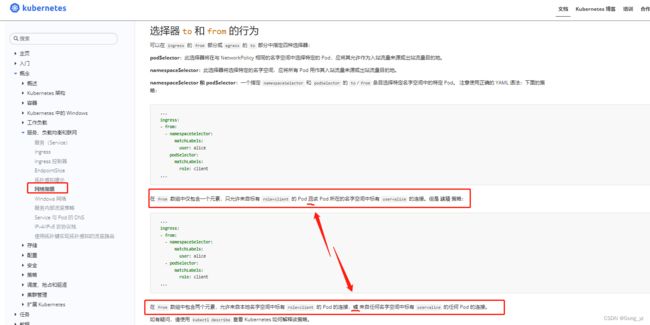
- from:
- namespaceSelector: ## 新建test 中namespace
matchLabels:
project: test
- podSelector: ##和namespace 二选一
matchLabels:
role: test
ports:
- protocol: TCP
port: 80
[root@k8s2 calico]# kubectl apply -f networkpolicy.yaml
from后显示两个策略:

[root@k8s2 ~]# kubectl create namespace test
给namespace添加指定标签:
[root@k8s2 calico]# kubectl label ns test project=test

[root@k8s2 calico]# kubectl -n test run demo --image busyboxplus -it --rm
If you don’t see a command prompt, try pressing enter.
/ # curl 10.108.1.129
Hello MyApp | Version: v1 | Pod Name
(3)同时限制namespace和pod
[root@k8s2 calico]# vim networkpolicy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: myapp-v1
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
project: test
podSelector: ##相比上面实验,去掉“-”;表示同时限制namespace和pod
matchLabels:
role: test
ports:
- protocol: TCP
port: 80
[root@k8s2 calico]# kubectl apply -f networkpolicy.yaml
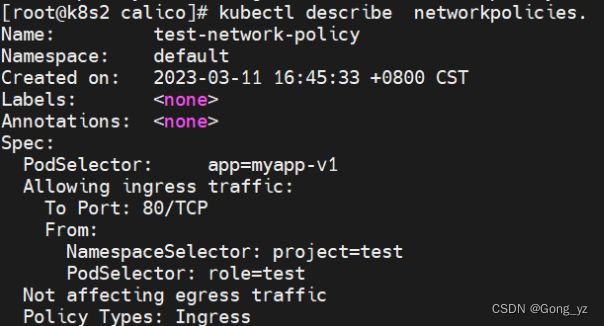
给test命令空间中的pod添加指定标签后才能访问
[root@k8s2 calico]# kubectl -n test label pod demo role=test
pod/demo labeled
[root@k8s2 calico]# kubectl -n test get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
demo 1/1 Running 0 5m33s role=test,run=demo
(4)限制集群外部流量


[root@k8s2 calico]# vim networkpolicy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: myapp-v1
policyTypes:
- Ingress
ingress:
- from:
- ipBlock: ##限制网段,允许192.168.56.0/24进来
cidr: 192.168.56.0/24
- namespaceSelector: ##“-”表示或者符合下面的条件
matchLabels:
project: myproject
podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 80
[root@k8s2 calico]# kubectl apply -f networkpolicy.yaml


[root@k8s1 ~]# curl 192.168.56.101
Hello MyApp | Version: v1 | Pod Name