一百八十五、大数据离线数仓完整流程——步骤四、在Hive的DWD层建动态分区表并动态加载数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(四)步骤四、在Hive的DWD层建动态分区表并动态加载数据
1、Hive的DWD层建库建表语句
--如果不存在则创建hurys_dc_dwd数据库
create database if not exists hurys_dc_dwd;
--使用hurys_dc_dwd数据库
use hurys_dc_dwd;
--1.转向比数据内部表——动态分区 dwd_turnratio
create table if not exists dwd_turnratio(
device_no string comment '设备编号(点位)',
create_time timestamp comment '创建时间',
volume_sum int comment '指定时间段内通过路口的车辆总数',
volume_left int comment '指定时间段内通过路口的左转车辆总数',
volume_straight int comment '指定时间段内通过路口的直行车辆总数',
volume_right int comment '指定时间段内通过路口的右转车辆总数',
volume_turn int comment '指定时间段内通过路口的掉头车辆总数'
)
comment '转向比数据表——动态分区'
partitioned by (day string) --分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
stored as orc --表存储数据格式为orc
;
2、海豚执行DWD层建表语句工作流
对于刚部署的服务器,由于Hive没有建库建表、而且手动建表效率低,因此通过海豚调度器直接执行建库建表的.sql文件
(1)海豚的资源中心加建库建表的SQL文件
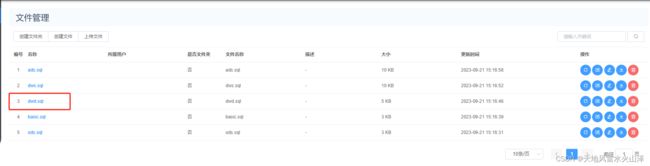

(2)海豚配置DWD层建表语句的工作流(不需要定时,一次就行)

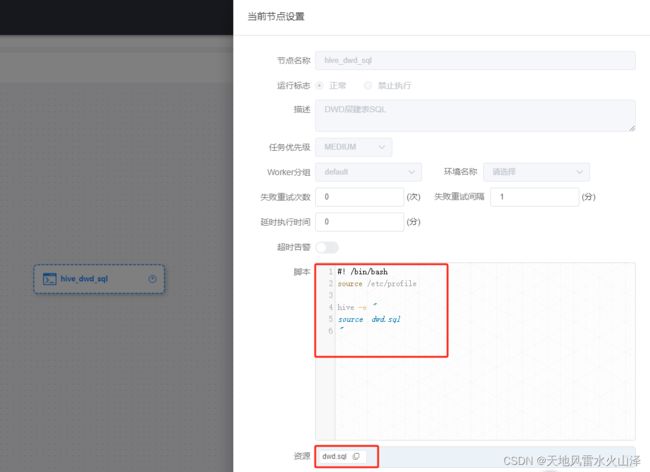
3、海豚配置DWD层每日动态加载数据的工作流(指定分区名)
(1)海豚配置DWD层每日动态加载数据的工作流(需要定时,每日一次)


#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
yesdate=`date -d yesterday +%Y-%m-%d`
hive -e "
use hurys_dc_dwd;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.exec.max.dynamic.partitions=1500;
insert overwrite table dwd_evaluation partition(day='$yesdate')
select device_no,
cycle,
lane_num,
create_time,
lane_no,
volume,
queue_len_max,
sample_num,
stop_avg,
delay_avg,
stop_rate,
travel_dist,
travel_time_avg
from hurys_dc_ods.ods_evaluation
where volume is not null and date(create_time)= '$yesdate'
group by device_no, cycle, lane_num, create_time, lane_no,
volume, queue_len_max, sample_num, stop_avg, delay_avg, stop_rate, travel_dist, travel_time_avg
"
(2)工作流定时任务设置(注意与其他工作流的时间间隔)

(3)注意点
3.3.1 动态加载数据的SQL需要指定分区名day='$yesdate',只加载前一天的数据
剩余数仓部分,待续!