窗口函数概述
一、什么是窗口函数
窗口函数,也叫OLAP(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理
二、窗口函数类别
1、专用窗口函数:
rank、dense_rank、row_number
2、聚合函数:
sum、avg、count、max、min
3、简单使用rank窗口函数:每个班级内按成绩排名
select *,
rank() over(PARTITION by scourse order by sresult) as ranking
from score;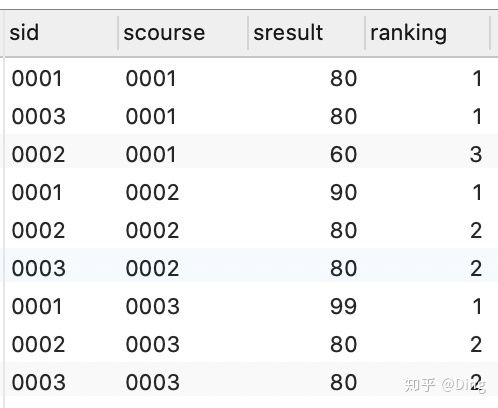
这样操作后都是按班级分组,按成绩排序,并且多了一个ranking列。窗口函数具备了我们之前学过的group by子句分组的功能和order by 子句排序的功能,那么,为什么还要用窗口函数呢,这是因为,group by分组后改变了表的行数,一行只有一个类别,二partition by 和rank函数不会减少表中的行数。
例如下面统计每个班级的人数。
select scourse,count(sid)
from score
GROUP BY scourse
order by scourse;-- group by
select scourse,
count(scourse) over(partition by scourse order by scourse) AS CURRENT_count
from score;-- 窗口函数

三、经典面试题
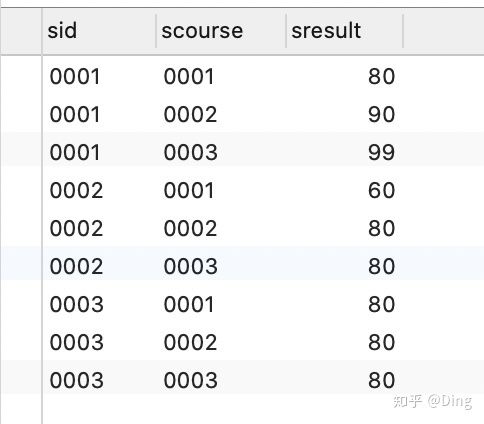
成绩表(学号、班级号、成绩)
- 排名问题:
1、每个班级按成绩排名
SELECT *,
rank() over (PARTITION BY scourse ORDER BY sresult DESC) AS ranking,
dense_rank() over (PARTITION BY scourse ORDER BY sresult DESC) AS des_rank,
row_number() over (PARTITION BY scourse ORDER BY sresult DESC) AS row_num
FROM score
-- rank:存在并列排名,且占用原来名次
dense_rank:存在并列排名,不占用原来名次
row_number:不存在并列排名
2、编写一个SQL查询来实现分数排名
SELECT sresult,
dense_rank() over (PARTITION BY scourse ORDER BY sresult DESC) AS des_rank
FROM score 
3、按课程号分组取成绩最大值所在行的数据
SELECT *
FROM score as a
WHERE sresult = (SELECT max(sresult) FROM score as b WHERE b.scourse = a.scourse);-- 关联子查询
4、按课程号分组取成绩最小值所在行的数据
SELECT *
FROM score as a
WHERE sresult = (SELECT min(sresult) FROM score as b WHERE b.scourse = a.scourse);-- 关联子查询
把子查询结果当成一个表,注意这个表要给他命名
- Top N问题:
5、查找每个学生成绩最高的两个科目
SELECT *, row_number() over (partition by sid order by scresult DESC) as ranking
FROM score
WHERE ranking <=2;-- 这个运行是错误的,因为select语句在where后面执行的
SELECT *
FROM (SELECT *, row_number() over (partition by sid order by sresult DESC) as ranking FROM score)as a
WHERE ranking <=2;
总结:Top N问题的常见解法
SELECT *
FROM (SELECT *, row_number() over (partition by sid order by sresult DESC) as ranking FROM score)as a
WHERE ranking <=N;6、聚合函数作为窗口函数
分组后可直观看到,每组中截取到本行数据,统计数据是多少
SELECT *,
sum(sresult) over (partition by sid order by sresult) as current_sum,
avg(sresult) over (partition by sid order by sresult) as current_avg,
count(sresult) over (partition by sid order by sresult) as current_count,
max(sresult) over (partition by sid order by sresult) as current_max,
min(sresult) over (partition by sid order by sresult) as current_min
FROM score; 
- 组内比较的问题:
7、查找单科成绩高于该科目平均成绩的学生名单
思路:先按照学科分组,然后使用聚合函数avg求每科平均值,然后把它作为一张新表,再用select函数在这张表里找大于单科平均成绩的行数
select *
from (
SELECT *, avg(sresult) over (partition by scourse) as avg_score FROM score
) as a
where sresult > avg_score ;总结:查找每个组里大于平均值的数据
方法一、使用窗口函数实现
方法二、使用标量子查询
select *
from score a
where sresult > (
select avg(sresult) from score b where a.scourse=b.scourse group by scourse)- 移动平均问题:
8、业务场景:在公司业绩名单排名中,直观的看到与相邻名次业绩的平均,求和等统计数据
SELECT *,
avg(sresult) over (order by scourse rows 2 preceding) as current_avg
FROM score;
比如第四行的current_avg,是等于自己的sresult(90)+它前两行的sresult(60+80)的平均值
四、总结
- 窗口函数有以下功能:
1)同时具有分组(partiton by)和排序(order by) 的功能
2)不减少原表的行数,所有经常用来在每组内排名
- 注意事项:窗口函数原则上只能写在select 子句中
- 窗口函数使用场景:
1)经典top N问题,比如找出每个部门排名前N的员工进行奖励
2)经典排名问题,比如每个部门按业绩来排名
3)在每个组里比较的问题,比如查找每个组里大于平均值得数据,可以有2种方法:
方法1,使用前面窗口函数案例来实现
方法2,使用关联子查询