LLM-TAP随笔——有监督微调【深度学习】【PyTorch】【LLM】
文章目录
- 5、 有监督微调
-
- 5.1、提示学习&语境学习
- 5.2、高效微调
- 5.3、模型上下文窗口扩展
- 5.4、指令数据构建
- 5.5、开源指令数据集
5、 有监督微调
5.1、提示学习&语境学习
提示学习
完成预测的三个阶段:提示添加、答案搜索、答案映射

提示添加
“[X] 我感到 [Z]”
x = “我不小心错过了公共汽车。”
x’ = “我不小心错过了公共汽车。我感到[Z]”
答案搜索
Z = {“太好了”,“好”,“一般”,“不好”,“糟糕”}
将给定提示 x ′ 而模型输出为 z 的过程记录为函数 f f i l l ( x ′ , z ) f_{fill} (x ′ , z) ffill(x′,z),对于每个答案空间 Z Z Z中的候选答案 z z z,分别计算模型输出它的概率, 从而找到模型对[Z] 插槽预测得分最高的输出:
z ~ = s e a r c h z ∈ Z P ( f f i l l ( x ′ , z ) ; θ ) \tilde{z} = search_{z∈Z}P(f_{fill}(x',z);θ) z~=searchz∈ZP(ffill(x′,z);θ)
答案映射
将模型的输出与最终的标签做映射。映射规则是人为制定的,比如,将“太好了”、“好”映射为“正面”标签,将“不好”,“糟糕”映射为“负面”标签,将“一般”映射为“中立”标签。

提示学习方法易于理解且效果显著,提示工程、答案工程、多提示学习方法、基于提示的训练策略等已经成为从提示学习衍生出的新的研究方向。
语境学习
关键思想是从类比中学习,整个过程并不需要对模型进行参数更新,仅执行向前的推理。
向模型输入特定任务的一些具体例子以及测试样例,让模型根据示例续写出测试样例的答案。
如下情感分类,续写情感极性:

5.2、高效微调
高效微调:在缩减训练参数量和GPU显存占用,同时使训练后的模型具有与全量微调相当的性能。
全量微调:微调全部参数需要相当高的算力。
LoRA( Low-Rank Adaptation of Large Language Models)
计算流程
h = W 0 x + Δ W x = W 0 x + B A x h = W_0x + \Delta Wx = W_0x + BAx h=W0x+ΔWx=W0x+BAx
矩阵 A 通过高斯函数初始化,矩阵 B 为零初始化,使得训练开始之前旁路对原模型不造成影响,即参数改变量为 0。
将原权重与训练后权重合并后, 推理时不存在额外的开销。
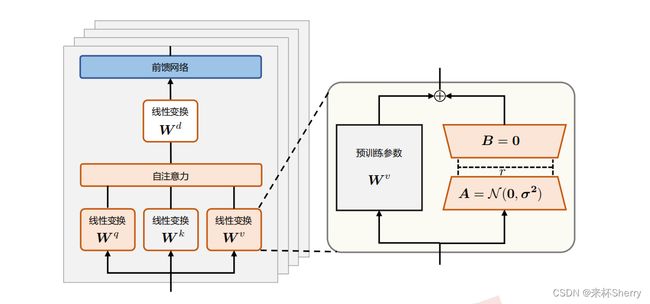
低秩矩阵通常有以下特点:
- 线性相关性较高:矩阵中的行或列之间存在较强的线性相关性,因此可以用较少的线性独立分量来近似表示。
- 信息冗余较多:由于线性相关性,低秩矩阵中包含了一些冗余信息,可以通过较低秩的近似来减少存储和计算成本。
- 较小的维度:低秩矩阵通常具有较低的维度,因为它们可以用较少的基向量(或特征向量)来表示。
其它高效微调方式
- 微调适配器(
Adapter)
分别对 Transformer 层中的自注意力模块与多层感知(MLP)模块,在其与其之后的残差连接之间添加适配器层(Adapter layer)作为可训练参数。
该方法及其变体会增加网络的深度,从而在模型推理时带来额外的时间开销。
- 前缀微调(
Prefix Tuning)
前缀微调是指在输入序列前缀添加连续可微的软提示作为可训练参数。由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。
软提示:连续提示的方法。
5.3、模型上下文窗口扩展
上下文窗口:在自然语言处理中,LLM(Large Language Model,大型语言模型)的上下文窗口指的是模型在处理文本时所考虑的文本片段或单词的范围。
- 具有外推能力的位置编码
ALiBi
相对位置编码
注意力加上线性偏置
S o f t m a x ( q i K T + m ⋅ [ − ( i − 1 ) , . . . , − 2 , − 1 , 0 ] ) Softmax(q_iK^T+m·[-(i-1),...,-2,-1,0]) Softmax(qiKT+m⋅[−(i−1),...,−2,−1,0])
- m为坡度,取值为: { 1 a , 1 a 2 , . . . , 1 256 } , 其中 a n u m _ h e a d s = 256 \{\frac{1}{a} , \frac{1}{a^2},...,\frac{1}{256} \} ,其中 a^{num\_heads} =256 {a1,a21,...,2561},其中anum_heads=256
- [ − ( i − 1 ) , . . . , − 2 , − 1 , 0 ] [-(i-1),...,-2,-1,0] [−(i−1),...,−2,−1,0]表示相对位置,取值:-(k索引[1,i] - q索引[i])
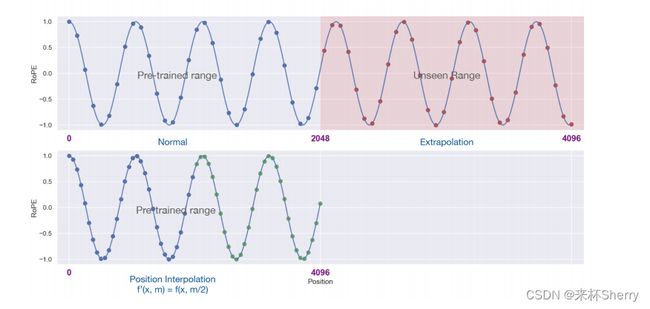
- 插值法
RoPE位置插值:
f ’ ( x , m ) = f ( x , m L ′ ) L f’(x,m) = f(x,\frac{m}{L'})L f’(x,m)=f(x,L′m)L
将更大的位置索引范围 [0,L′) 缩减至原始的索引范围 [0,L)
5.4、指令数据构建
指令数据的质量和多样性是衡量指令数据的重要维度,影响有监督微调过程的关键因素。
指令数据由指令、输入、输出组成。
指令数据示例:

- 手动构建
手动编写提示与相应的回答;
大量人力投入。
- 自动生成指令
Self-instruct
Self-instruct
其数据生成过程是一个迭代引导算法。
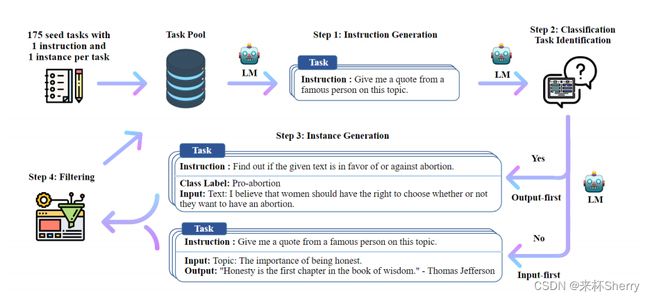
- 生成任务指令
手动构建175 seed tasks;
每次采样8个task 指令(人工6 + 迭代生成2);
直到停止生成 || 达到模型长度限制。
- 确定指令是否代表分类任务
处理不同。
不同原因:避免分类任务时,生成过多某些特定任务Input,而忽视其他类别。
- 生成任务输入和输出
输出:完整指令数据
No:Input-first, Input i n s t r u c t i o n > \frac{instruction}{}> instruction>Output
Yes:Output-first, Output i n s t r u c t i o n > \frac{instruction}{}> instruction>Input
- 过滤低质量数据
多样性:ROUGE-L相似度<0.7;
质量:启发式规则:除掉含某些关键字(如“图片”)、重复、过长或过短数据。
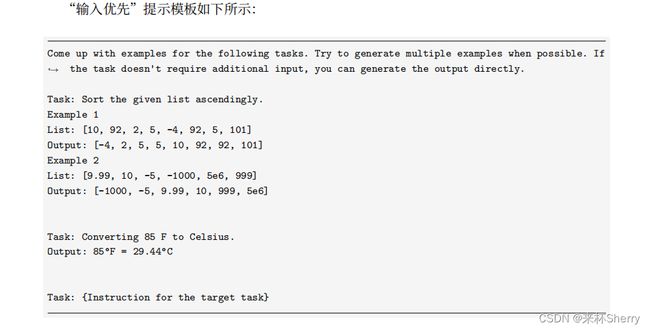

LLaMA 模型上进行有监督微调得到 Alpaca 模型, 所使用的指令数据集的示例

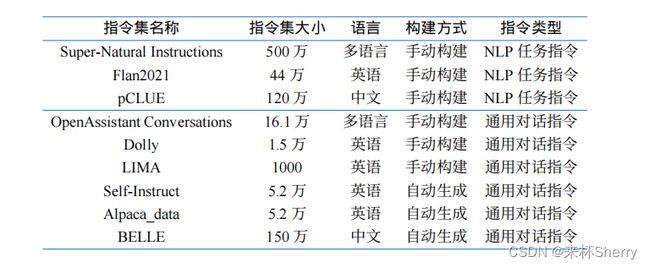
5.5、开源指令数据集
开源数据指令集