PySpark简介、搭建以及使用
目录
- 一、PySpark简介
-
- 使用场景
- 结构体系
- 二、PySpark集成搭建
- 三、 PySpark的使用
-
- PySpark包介绍
- PySpark处理数据
- PySpark中使用匿名函数
- 加载本地文件
- PySpark中使用SparkSQL
- Spark与Python第三方库混用
- Pandas DF与Spark DF
- 使用PySpark通过图形进行数据探索
一、PySpark简介
使用场景
大数据处理或机器学习时的原型( prototype)开发
- 验证算法
- 执行效率可能不高
- 要求能够快速开发
结构体系
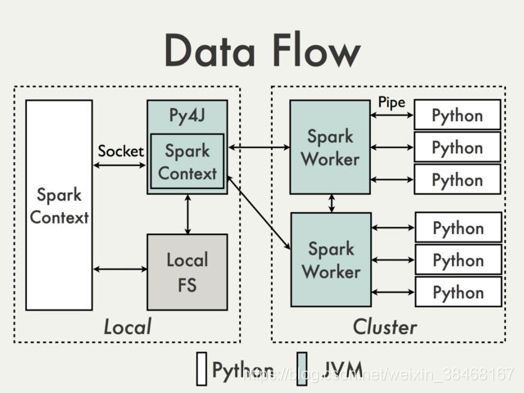
二、PySpark集成搭建
准备环境:JDK、Spark需要提前安装好
下载Anaconbda
- 地址:点击这里
- 选择:Anaconda3-5.1.0-Linux-x86_64.sh
至于版本最好不要使用过低版本,可能无法使用
安装bzip2
缺少 bzip2 安装 Anaconda 会失败
- 在Linux下安装bzip2:
yum install -y bzip2
上传/解压Anaconbda
-
将下载好的Anaconbda上传至Linux中
-
解压安装Anaconbda:
bash Anaconda3-5.1.0-Linux-x86_64.sh

-
回车,开始安装,然后提示接受协议(输入yes回车),然后指定安装到的位置,根路径必须已存在,(否则默认安装在/root/anaconbda3下面)

-
处理完上面的步骤后会提示是否自动添加环境变量,输入yes即可

-
然后还会提示是否安装VSCode,这里linux不需要安装,输入no即可
Linux默认自带python,安装Anacondd会覆盖原有的Python,可以通过修改.bashrc使两个版本pyrhon共存
设置两个版本的python共存
- 配置文件:
vim /root/.bashrc
#添加以下内容,自行修改自己安装的路径
export PATH="/opt/install/anaconda3/bin:$PATH"
alias pyana="/opt/install/anaconda3/bin/python"
alias python="/bin/python"
- 保存退出后生效配置文件:
source /root/.bashrc
生成 PySpark 配置文件
-
在当前用户文件夹下运行以下命令生成配置文件:
jupyter notebook --generate-config -
查看生成的配置文件:
ll /root/.jupyter/

-
修改配置文件,但在这之前,需要先执行以下操作
-
使用 pyana,进入交互模式,运行以下代码
from notebook.auth import passwd
passwd()
#按照提示设置密码后会生成与之对应的加密密码,然后保存这个生成的字符串,后面会赋值给 c.NotebookApp.password 属性

- 修改配置文件,允许从外部访问 Jupyter:
vi ./.jupyter/jupyter_notebook_config.py
c.NotebookApp.allow_root = True
c.NotebookApp.ip = '*'
c.NotebookApp.open_browser = False
c.NotebookApp.password = 'sha1:*****************'#将前面生成的值放到这里
c.NotebookApp.port = 7070 #指定外部访问的端口号
- 修改环境变量,将Jupyter作为PySpark的编辑运行工具:
vim /root/.bashrc
export PYSPARK_PYTHON=/opt/install/anaconda3/bin/python3 #指定/anaconda3/bin/python3
export PYSPARK_DRIVER_PYTHON=/opt/install/anaconda3/bin/jupyter #指定/anaconda3/bin/jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
ipython_opts="notebook -pylab inline"
-
生效环境变量:
source /root/.bashrc -
注意关闭防火墙
-
启动pyspark:
pyspark

-
使用浏览器打开Jupyter:
192.168.**.**:7070,并输入预先设置的密码

-
这里安装就算完成了
三、 PySpark的使用
- 初次使用建议创建一个文件夹,在这个文件夹保存操作过的代码
- 进入到新创建的文件夹下面,new->python3

- 然后就可以开始操作学习
- 执行命令
shift+回车:执行并开启新的一行
ctrl+回车:仅执行
PySpark包介绍
PySpark
Core Classes:
pyspark.SparkContext
pyspark.RDD
pyspark.sql.SQLContext
pyspark.sql.DataFrame
pyspark.streaming
pyspark.streaming.StreamingContext
pyspark.streaming.DStream
pyspark.ml
pyspark.mllib
PySpark处理数据
- 导包
from pyspark import SparkContext
- 获取SparkContext对象
sc=SparkContext.getOrCreate()
- 创建RDD
#不支持
makeRDD()
#支持
parallelize()
textFile()
wholeTextFiles()
- 演示

PySpark中使用匿名函数
- 使用Python的Lambda函数实现匿名函数
- scala与python对比
#scala
val a=sc.parallelize(List("dog","tiger","lion","cat","panther","eagle"))
val b=a.map(x=>(x,1))
b.collect
#python
a=sc.parallelize(("dog","tiger","lion","cat","panther","eagle"))
b=a.map(lambda x:(x,1))
b.collect()
- 演示

加载本地文件
addFile(path, recursive = False)
- 接收本地文件
- 通过SparkFiles.get()方法来获取文件的绝对路径
addPyFile( path )
- 加载已存在的文件并调用其中的方法
- 现在本地创建一个文件:
vi sci.py写入下面两个方法人,然后保存退出
#sci.py
def sqrt(num):
return num * num
def circle_area(r):
return 3.14 * sqrt(r)
- 在pyspark中通过addPyFile加载该文件
#加载预写入方法的文件
sc.addPyFile("file:///root/sci.py")
#导入文件中的方法
from sci import circle_area
#创建rdd并使用文件中的方法
sc.parallelize([5, 9, 21]).map(lambda x : circle_area(x)).collect()
- 演示

PySpark中使用SparkSQL
- 导包
from pyspark.sql import SparkSession
- 创建SparkSession对象
ss = SparkSession.builder.getOrCreate()
- 加载csv文件
ss.read.format("csv").option("header", "true").load("file:///xxx.csv")
演示
- 测试数据
Afghanistan 48.673000 SAs
Albania 76.918000 EuCA
Algeria 73.131000 MENA
Angola 51.093000 SSA
Argentina 75.901000 Amer
Armenia 74.241000 EuCA
Aruba 75.246000 Amer
Australia 81.907000 EAP
Austria 80.854000 EuCA
Azerbaijan 70.739000 EuCA
Bahamas 75.620000 Amer
Bahrain 75.057000 MENA
Bangladesh 68.944000 SAs
Barbados 76.835000 Amer
Belarus 70.349000 EuCA
Belgium 80.009000 EuCA
Belize 76.072000 Amer
Benin 56.081000 SSA
Bhutan 67.185000 SAs
Bolivia 66.618000 Amer
Bosnia_and_Herzegovina 75.670000 EuCA
Botswana 53.183000 SSA
Brazil 73.488000 Amer
Brunei 78.005000 EAP
Bulgaria 73.371000 EuCA
Burkina_Faso 55.439000 SSA
Burundi 50.411000 SSA
Cambodia 63.125000 EAP
Cameroon 51.610000 SSA
Canada 81.012000 Amer
Cape_Verde 74.156000 SSA
Central_African_Rep. 48.398000 SSA
Chad 49.553000 SSA
Channel_Islands 80.055000 EuCA
Chile 79.120000 Amer
China 73.456000 EAP
Colombia 73.703000 Amer
Comoros 61.061000 SSA
Congo_Dem._Rep. 48.397000 SSA
Congo_Rep. 57.379000 SSA
Costa_Rica 79.311000 Amer
Cote_d'Ivoire 55.377000 SSA
Croatia 76.640000 EuCA
Cuba 79.143000 Amer
- 操作代码
#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import DoubleType
#创建sparkSession对象
ss = SparkSession.builder.getOrCreate()
#读取本地csv文件,并为每列设置名称
#pyspark中一条语句换行需要加斜杠
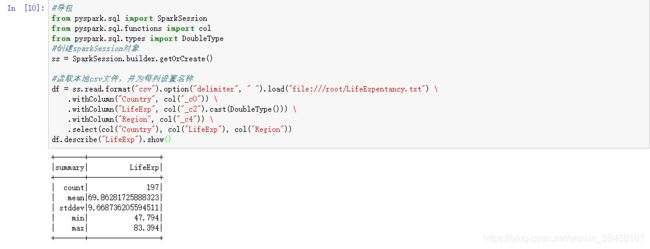
df = ss.read.format("csv").option("delimiter", " ").load("file:///root/example/LifeExpentancy.txt") \
.withColumn("Country", col("_c0")) \
.withColumn("LifeExp", col("_c2").cast(DoubleType())) \
.withColumn("Region", col("_c4")) \
.select(col("Country"), col("LifeExp"), col("Region"))
df.describe("LifeExp").show()
- 效果展示
Spark与Python第三方库混用
- 使用Spark做大数据ETL
- 处理后的数据使用Python第三方库分析或展示
1.Pandas做数据分析
#Pandas DataFrame 转 Spark DataFrame
spark.createDataFrame(pandas_df)
#Spark DataFrame转Pandas DataFrame
spark_df.toPandas()
2.Matplotlib实现数据可视化
3.Scikit-learn完成机器学习
Pandas DF与Spark DF
- PandasDF与SparkDF间的转换方法
- 测试数据
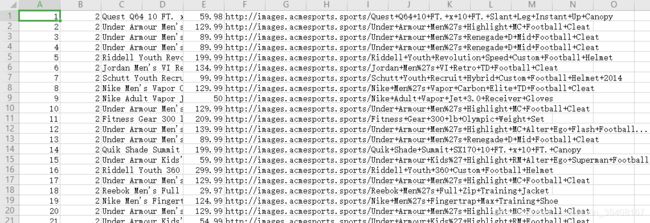
- 操作代码
# Pandas DataFrame to Spark DataFrame
import numpy as np
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
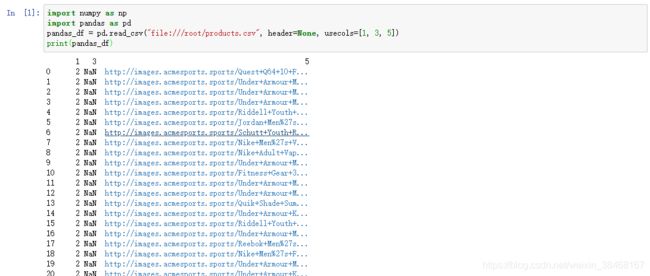
pandas_df = pd.read_csv("./products.csv", header=None, usecols=[1, 3, 5])
print(pandas_df)
# convert to Spark DataFrame
spark_df = spark.createDataFrame(pandas_df)
spark_df.show()
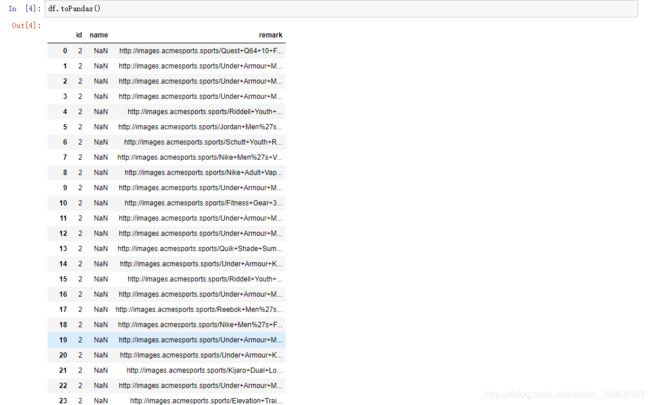
df2 = spark_df.withColumnRenamed("1", "id").withColumnRenamed("3", "name").withColumnRenamed("5", "remark")
# convert back to Pandas DataFrame
df2.toPandas()
- 演示

使用PySpark通过图形进行数据探索
- 将数据划分为多个区间,并统计区间中的数据个数
# 获取上面演示示例中的第一个df对象
rdd = df.select("LifeExp").rdd.map(lambda x: x[0])
#把数据划为10个区间,并获得每个区间中的数据个数
(countries, bins) = rdd.histogram(10)
print(countries)
print(bins)
#导入图形生成包
import matplotlib.pyplot as plt
import numpy as np
plt.hist(rdd.collect(), 10) # by default the # of bins is 10
plt.title("Life Expectancy Histogram")
plt.xlabel("Life Expectancy")
plt.ylabel("# of Countries")
- 演示

