《BloombergGPT: A Large Language Model for Finance》全文翻译
《BloombergGPT: A Large Language Model for Finance》- BloombergGPT:金融业的大型语言模型
- 论文信息
- 摘要
- 1. 简介
-
- 1.1 BloombergGPT
- 1.2 更广泛的贡献
- 2. 数据集
-
- 2.1 Financial Datasets (363B tokens – 54.2% of training)
-
- 2.1.1 Web (298B tokens – 42.01% of training)
- 2.1.2 News (38B tokens – 5.31% of training)
- 2.1.3 Filings (14B tokens – 2.04% of training)
- 2.1.4 Press (9B tokens – 1.21% of training)
- 2.1.5 Bloomberg (5B tokens – 0.70% of training)
- 2.2 Public Datasets (345B tokens – 48.73% of training)
-
- 2.2.1 The Pile (184B tokens – 25.9% of training)
- 2.2.2 C4 (138B tokens – 19.48% of training)
- 2.2.3 Wikipedia (24B tokens – 3.35% of training)
- 2.3 标记化
- 3. 模型
-
- 3.1 架构
- 3.2 模型缩放
- 3.3 训练配置
- 3.4 大规模优化
- 4. 训练运行
- 5. 评估
-
- 5.1 Few-shot 方法
- 5.2 保留损失
- 5.3 财务任务
-
- 5.3.1 外部财务任务
- 5.3.2 内部任务:情感分析
- 5.3.3 探索性任务:NER
- 5.4 BIG-bench Hard
- 5.5 知识评估
- 5.6 阅读理解
- 5.7 语言任务
- 5.8 总结
- 6. 定性样本
- 7. 相关工作
- 8. 伦理、局限性和影响
-
- 8.1 合乎道德的使用
- 8.2 开放性
- 9.总结
论文信息
- 题目:《BloombergGPT: A Large Language Model for Finance》
- 作者:Shijie Wu and et al.
- 期刊:arXiv
- 发表时间:26 May 2023
- 内容概述:彭博社构建了迄今为止最大的特定领域数据集,训练了专门用于金融领域的 LLM,开发了拥有 500 亿参数的语言模型——BloombergGPT。该模型依托彭博社的海量金融数据源,构建了一个 3630 亿个标签的数据集,支持金融行业内的各类任务。
摘要
NLP 在金融技术领域的应用是广泛而复杂的,其应用范围包括情感分析、命名实体识别和问题回答。大型语言模型(LLMs)已被证明在各种任务中是有效的;然而,文献中还没有报道过专门用于金融领域的 LLM。在这项工作中,我们提出了 BloombergGPT,这是一个 500 亿参数的语言模型,在广泛的金融数据上进行训练。我们根据彭博社广泛的数据来源构建了一个 3630 亿个标记的数据集,这可能是迄今为止最大的领域专用数据集,并从通用数据集中增加了 3450 亿个标记。我们在标准的 LLM 基准、开放的金融基准和一套最准确反映我们预期用途的内部基准上验证了 BloombergGPT。我们的混合数据集训练使我们的模型在金融任务上比现有的模型有明显的优势,同时也没有牺牲一般 LLM 基准的性能。此外,我们解释了我们的建模选择、训练过程和评估方法。作为下一步,我们计划发布训练日志(Chronicles),详细介绍我们在训练 BloombergGPT 方面的经验。
1. 简介
2020 年发布的 GPT-3 展示了训练大型自动回归语言模型(LLM)的强大好处。GPT-3 有 1750 亿个参数,比之前的 GPT-2 模型增加了上百倍,并在现在流行的各种 LLM 任务中表现出色,包括阅读理解、开放式问题回答和代码生成。这种表现已经在其他几个模型中得到了复制。此外,有证据表明,大型模型表现出涌现行为;参数增长使它们获得小型模型中不存在的能力。涌现行为的一个明显的例子是通过少量提示执行任务的能力,在这种情况下,一个模型可以从少量的例子中学习任务。当我们增加语言模型的规模时,这种能力的提高远远超过了随机。广义上讲,少量提示极大地扩展了模型支持的任务范围,降低了用户寻求新语言任务自动化的门槛。
在 GPT-3 之后,模型的规模增长到 2800 亿、5400 亿和 1 万亿参数。工作还探索了实现高性能 LLM 的其他重要方面,如不同的训练目标、多语言模型、更有效和更小的模型,以及确定数据和参数的训练规模。
这些努力几乎都集中在一般的 LLM 上,在涵盖广泛的主题和领域的数据集上进行训练。虽然其中包括一些专门领域的数据集(如代码或生物医学文章),但重点是建立具有广泛能力的 LLM。最近只用特定领域的数据来训练模型的努力产生了一些模型,尽管这些模型小得多,但在这些领域的任务上却击败了通用的 LLM。这些发现促使我们进一步开发专注于特定领域的模型。
金融技术(FinTech)是一个庞大且不断增长的领域,NLP 技术具有越来越重要的作用。金融 NLP 任务包括情感分析,命名实体识别,新闻分类,以及问题回答。虽然这些任务的范围与一般 NLP 基准中的任务相似,但金融领域的复杂性和术语需要一个特定领域的系统。由于生成性 LLMs 在一般情况下具有吸引力(少量的学习,文本生成,对话系统,等等),但是一个专注于金融领域的 LLM 将是非常有价值的。虽然有针对金融领域的掩码语言模型,但没有针对这个领域的任务调整过的 LLM。
1.1 BloombergGPT
我们训练 BloombergGPT,这是一个 500 亿参数的语言模型,支持金融业内的各种任务。我们没有建立一个通用的 LLM,也没有建立一个专门针对特定领域数据的小型 LLM,而是采取了一种混合方法。通用模型涵盖了许多领域,能够在各种任务中发挥高水平的作用,并在训练期间避免了专业化的需要。然而,现有的领域专用模型的结果表明,通用模型不能取代它们。在彭博社,我们支持大量不同的任务,通用模型可以很好地满足这些任务,但是我们绝大多数的应用都是在金融领域,专门的模型可以更好地满足这些应用。出于这个原因,我们着手建立一个模型,在金融基准上取得一流的结果,同时也在通用的 LLM 基准上保持有竞争力的性能。
我们利用彭博社现有的数据创建、收集和整理资源,构建了迄今为止最大的特定领域数据集来实现这一目标。由于彭博社主要是一家金融数据公司,我们的数据分析师已经收集和策划了 40 年的金融语言文件。我们拥有广泛的金融数据档案,涵盖了一系列的主题,并仔细跟踪数据来源和使用权。我们将这些数据添加到公共数据集中,以创建一个拥有超过 7000 亿个标记的大型训练语料库。使用这个训练语料库的一部分,我们训练了一个 BLOOM 风格的、500 亿参数的模型,该模型是根据 Homann 等人(2022)和 Le Scao 等人(2022)的指导方针设计的。我们在标准的 LLM 基准、开放的金融基准和一套最能准确反映我们预期用例的彭博社内部基准上验证了该模型。我们的结果表明,我们的混合训练方法使我们的模型在领域内的金融任务上大大超过了现有的模型,而在一般的 NLP 基准上则与之相当或更好。
1.2 更广泛的贡献
除了为金融数据构建一个 LLM 之外,我们的目标是为更广泛的研究界作出贡献。特别是,我们在本文中记录的经验提供了证据,进一步发展了社区对文献中几个开放问题的理解。
特定领域的 LLMs。现有的少数特定领域的 LLMs 是专门在特定领域的数据源上训练的,或者将一个非常大的通用模型改编为特定领域的任务。我们的替代方法(在特定领域和一般数据源上训练一个LLM)到目前为止还没有被研究。所得到的模型在特定领域的任务上表现很好,同时在通用的基准上也保持了强大的性能。基准上保持强劲的性能。
训练数据。几乎所有的语言模型都在很大程度上依赖于网络搜刮的数据,例如 C4 和 The Pile(其中包括 OpenWebText2)。这种数据在使用前可以通过各种方式进行清理或子集,但数据重复的问题和有毒语言仍然存在。我们的训练数据对于 LLM 培训来说是不寻常的,因为它包括大量来自可靠来源的、经过策划和准备的 数据的可靠来源。
评价。LLM 评估仍然是一个具有挑战性和不断发展的问题,新的基准试图使不同模型的评估标准化。然而,对于特定领域的任务,评估和实际使用情况之间仍然存在不匹配。评估是建立在现有的数据集上的,而不一定是建立在模型在实践中如何使用上的。我们提供了公共金融 NLP 基准以及 Bloomberg 内部任务的选择结果,这与我们的预期用例更加一致,并直接评估我们的模型执行相关任务的能力。
模型规模。早期的 LLMs 对 2000-4000 亿个语料库进行了一次训练,Homann 等认为模型训练不足,而是专注于用更多的数据训练更小的模型,这是 Touvron 等最近采用的一种策略。我们在 Homan 的激励下选择了一个模型规模,在超过 7000 亿个语料库中的 5690 亿个语料上训练了一个 500 亿个参数的模型,以产生一个能与更大的模型竞争的模型。
标记器。在收集训练数据后,标记化的关键步骤是将文本转化为适合语言模型的格式。这一步骤的重要性经常被忽视,许多旧的 LLM 使用相同的标记器和词汇,这意味着我们没有什么证据来支持其他标记器。我们采取不同的方法,使用 Unigram 模型,而不是基于合并的子词标记器,因为它节省了概率,允许在推理时进行更智能的标记。
模型构建的挑战。GPT-3 和后续模型是大型团队的工作,需要大量的计算。重现这些结果的最初工作,如 OPT Zhang 等,并不符合原始模型的性能。随着每个后续模型的发布,社区的理解、经验和软件工具都在增加。在开发 BloombergGPT 时,我们受益于作为 BLOOM 研究的一部分而开发的现有代码,Scao 等的研究表明,一个中等规模的团队可以在特定领域的数据上产生一个有竞争力的模型。我们详细描述了我们训练 BloombergGPT 的经验,以支持未来的训练工作,并解决上述每个主题。
2. 数据集

表 1:用于训练 BloombergGPT 的完整训练集的细分。提供的统计数据包括每个文档的平均字符数(“C/D”)、每个标记的平均字符数(“C/T”)以及总体标记的百分比(“T%”)。每列的单位均在标题中标出。
为了训练 BloombergGPT,我们构建了FinPile,这是一个由一系列英文金融文件组成的综合数据集,包括新闻、文件、新闻稿、网络抓取的金融文件,以及从彭博档案中提取的社交媒体。这些文件是在过去 20 年里通过我们的商业流程获得的。我们用广泛用于训练 LLM 的公共数据来充实 FinPile。结果是一个训练语料库,大约一半是特定领域的文本,一半是通用文本。关于完整的训练集的分类,见表 1。为了提高数据质量,我们根据 Lee 等人对每个数据集(The Pile, C4, Wikipedia, FinPile)进行了去重;作为一个副作用,表 1 中报告的统计数据可能与其他论文中的数据不同。
2.1 Financial Datasets (363B tokens – 54.2% of training)
在过去的四十年里,彭博终端提供了一套全面的多样化的结构化和非结构化的金融数据和分析方法。在为这一使命服务的过程中,彭博社的分析师们策划了一套内部创建或从外部来源获得的金融文件。我们利用这些广泛收集和维护的文件来创建 FinPile,其中包括公司文件、金融新闻和其他与金融市场相关的数据。
FinPile 中包括的一些文件,如公司文件,是可以向公众提供的,尽管收集这些文件并为 LLM 训练进行预处理是一项非艰巨的任务。其他文件,如(彭博新闻的一个子集),必须购买。其余的文件是私人的,除其他来源外,可以通过彭博终端获得。最后,我们对这些数据进行清理,以剥离标记、特殊格式化和模板。
请注意,FinPile 中的每份文件都有时间戳,日期从 2007- 03-01 到 2022-07-31;在这个时间范围内,文件的质量和数量都有所增加。虽然我们在这项工作中没有利用日期信息,但我们计划在未来使用它,例如用于评估模型对不同时间段的学习情况。虽然我们不能发布 FinPile,但我们在一个大型的、精心策划的、干净的特定领域数据集上的训练经验可能会给社区提供有用的见解,特别是建立一个金融 LLM 的优势和挑战,以及一般的特定领域模型。我们在表 2 中提供了 FinPile 的分类和分析,并在下文中对包括的数据类型进行了简要描述。

表 2:FinPile 文档中包含的代币数量(以百万为单位),按年份(行)和类型(列)组织。单位为数百万代币。
2.1.1 Web (298B tokens – 42.01% of training)
彭博社通过识别包含金融相关信息的网站来收集网络内容。虽然这个类别占了 FinPile 的大部分,但它的分类很粗略,内容主要是按网站域名的位置分类。在这些特定地点的来源中,例如 “美国”(占总数的15.95%)、“亚太地区”(占总数的4.72%)和 “英国”(占总数的1.98%),文件类型是高度多样化的,正如网络抓取所预期的那样。虽然网络来源在现有的公共LLMs 培训数据集中很常见,但彭博社的网络抓取主要集中在有金融相关信息的高质量网站上,而不是通用的网络抓取。
2.1.2 News (38B tokens – 5.31% of training)
新闻类包括所有的新闻来源,不包括彭博社记者撰写的新闻文章。总的来说,FinPile 中有数百个英文新闻来源,包括 “彭博转录”(占总数的0.41%),这些是彭博电视新闻的转录稿。一般来说,这个数据集的内容来自于与金融界相关的有信誉的新闻来源,以便保持事实性和减少偏见。
2.1.3 Filings (14B tokens – 2.04% of training)
公司档案是由(公共)公司准备的财务报表,并向公众开放。在一些国家,如美国,上市公司被要求定期编制和提交他们的财务报表;例如,10-K 年度报告和10-Q 季度报告。在我们的数据集中,大部分的文件来自 EDGAR,也就是美国证券交易委员会的在线数据库(占总数的1.90%)。文件通常是带有表格和图表的长篇 PDF 文件,其中有大量的财务信息,这些信息在彭博中被处理和规范化。申报文件与通常用于训练 LLMs 的文件类型有很大不同,但包含了对金融决策至关重要的信息。
2.1.4 Press (9B tokens – 1.21% of training)
新闻类包含通常由公司发布的与财务有关的新闻稿。与文件一起,新闻稿代表了一个公司的大部分公共信息。然而,与文件不同,新闻稿在内容和风格上与新闻故事相似。
2.1.5 Bloomberg (5B tokens – 0.70% of training)
该类别包括彭博社撰写的新闻和其他文件,如意见和分析。最大的来源是 “彭博新闻”(占总数的0.44%)和 “彭博第一消息”(占总数的 0.13%),这是彭博撰写的实时新闻通讯。虽然彭博新闻涵盖了广泛的主题,但它通常专注于与金融界相关的内容。该数据集包含不同长度的文件。
2.2 Public Datasets (345B tokens – 48.73% of training)
我们在训练语料库中使用了三个广为人知且可用的公共数据集。
2.2.1 The Pile (184B tokens – 25.9% of training)
The Pile是 GPT-Neo、GPT- J 和 GPT-NeoX(20B)中使用的数据集。我们将 The Pile 纳入我们的训练数据,原因如下。首先,它已经被用来成功地训练一个 LLM。第二,它已经进行了大量的数据清理和预处理。第三,它包括多个领域,我们相信这种多样化的数据将有助于推广到新的领域,甚至可能支持金融数据的训练。例如,FreeLaw 和 GitHub 等领域对彭博社分别从事法律文件和软件开发的团队很有用。The Pile 的创建者特意选择包括重复的内容,重复的因素与内容的感知质量成正比。然而,由于我们对每一个数据集都进行了重复,The Pile 的规模被大大缩小。此外,请注意,我们的标记器(§2.3)是在 The Pile 上训练的。
2.2.2 C4 (138B tokens – 19.48% of training)
The Colossal Clean Crawled Corpus (C4) 是一个常用于训练LLM的数据集,并被引入以支持训练 T5。虽然它与 Pile-CC 重叠,但 C4 的清理和处理方式不同;因此,我们觉得在 The Pile 之外包括 C4 比重复的文档更能增加价值。我们发现,由于层层清理,C4 包含高质量的自然语言文档,尽管其他人已经注意到,在网络领域的分布是不寻常的,有很高的数据比例来自于专利(Dodge 等人,2021)。
2.2.3 Wikipedia (24B tokens – 3.35% of training)
The Pile 和 C4 都包括过时的维基百科副本,因此包括最新的维基百科页面可能对模型的事实性有益。因此,我们包括了 2022 年 7 月 1 日的英文维基百科的转储。这个数据集的标记效率很低(每个标记3.06个字符),表明标记量高于平均水平,这表明进一步清理可能有利于未来的模型训练。
2.3 标记化
基于 Kudo 和 Richardson 以及 Bostrom 和 Durrett 的良好结果,我们选择了 Unigram 标记器,而不是基于贪婪合并的子词标记器,如字节对编码(BPE)或 Wordpiece。按照 GPT-2 Radford 等人的做法,我们将数据视为字节序列,而不是 Unicode 字符,我们将 256 个字节中的每个字节都作为标记。在预符号化步骤中,通过贪婪地匹配以下正则表达式,将输入的字节序列分解成若干块: [ A − Z a − z ] + ∣ [ 0 − 9 ] ∣ [ ∧ A − Z a − z 0 − 9 ] + [A-Za-z]+|[0-9]|[{}^{\wedge} A-Za-z0-9]+ [A−Za−z]+∣[0−9]∣[∧A−Za−z0−9]+. 这遵循 GPT-2 的规定,防止多个字符类出现在一个标记中。然而,我们在字母块中加入了空格,这使得多字令牌可以被学习,增加了信息密度并减少了上下文长度。预编码遵循 PaLM Chowdhery 等人(2022)的方法,将每个数字放在自己的块中,希望这将导致对数字的更好处理。我们在 The Pile Gao 等人的基础上训练我们的标记器,因为它来自不同的领域,包括代码和学术论文,其比例适合我们的用例。
并行标记器训练。Unigram 标记器的实现效率太低,无法一次性处理整个 Pile 数据集,因此我们采用了分割和合并的方法。我们将 Pile 中的 22 个领域分成 256 个大小基本相同的小块。然后,我们在 22×256(总共 =5,632)个块中的每一个上训练一个词汇量为 65,536(216)的 Unigram 标记器。我们分层次地合并各个标记器,首先合并每个领域的 256 个标记器,然后合并得到的 22 个标记器,得到最终的标记器。
单词标记器相当于标记的概率分布(即单词语言模型),我们通过对相应标记的概率进行加权平均来合并标记器,其权重由用于训练标记器的数据的相对大小(字节)决定。结果是一个具有 700 万个标记的标记器。为了将词汇的大小减少到 217 个标记,我们放弃了概率最小的标记,并重新进行规范化。为了确保我们不需要词汇外的标记,我们还将不在 The Pile 中出现的 36 个(可能的 256 个)字节以及一个 <|endoftext|> 标记作为标记。
在选择词汇量方面有多种考虑。对于 LLMs 来说,大词汇量的一个好处是更多的信息可以装入上下文窗口。另一方面,较大的词汇量会产生开销:更大比例的模型参数需要用于标记的嵌入。我们根据词汇量从 25,000 到 550,000 不等的实验,选择了 217 个标记的词汇量大小。对于每个词汇量,我们对 C4 数据集进行标记,并计算出数据集的总大小(以字节为单位),其中每个标记用 log2(词汇量)比特表示。我们的启发式方法是选择能使 C4 的编码表示最小的词汇量。这给了我们一个 125,000 的词汇量,然后我们把它四舍五入到最接近的 2 的幂(217,或 131,072 个符号)。相对于大约 50,000 个标记的标准词汇量,我们的标记器是很大的。关于标记化效率的分析,见表 3。
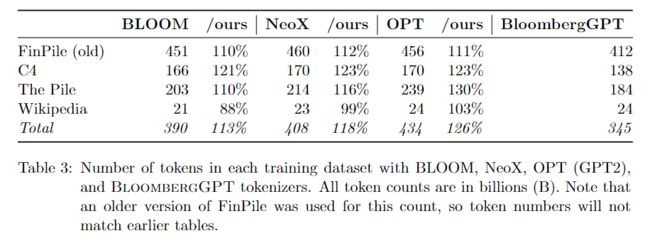
表 3:使用 BLOOM、NeoX、OPT (GPT2) 和 BloombergGPT 标记器的每个训练数据集中的标记数量。所有代币数量均以十亿为单位 (B)。请注意,此计数使用的是旧版本的 FinPile,因此令牌编号将与早期的表不匹配。
3. 模型
3.1 架构
我们的模型是一个基于 BLOOM 的纯解码器因果语言模型。我们提出了一个架构的概述,完整的细节见附录 A。
该模型包含 70 层的变压器解码器块,定义如下:
h ‾ l = h l − 1 + S A ( L N ( h l − 1 ) ) h l = h ‾ l + F F N ( L N ( h ‾ l ) ) \overline{h}_l= h_{l-1} + SA(LN(h_{l-1})) \\ h_l = \overline{h}_l + FFN(LN(\overline{h}_l)) hl=hl−1+SA(LN(hl−1))hl=hl+FFN(LN(hl))
其中, S A SA SA 是多头自我注意, L N LN LN 是层-正常化, F F N FFN FFN 是具有 1 个隐藏层的前馈网络。在 F F N FFN FFN 内部,非线性函数是 G E L U GELU GELU。 A L i B i ALiBi ALiBi 位置编码是通过变压器网络的自我注意部分的加法偏置来应用的。在最终的 softmax 之前,输入的 token 嵌入与线性映射相联系。继 Le Scao 等人之后,并在 Dettmers 等人中首次使用,该模型在标记嵌入后有一个额外的规范化层,正式:
h ‾ 1 = L N e m ( h 0 ) + S A ( L N ( L N e m ( h 0 ) ) ) \overline{h}_1 = LN^{em} (h_0) + SA(LN(LN^{em} (h_0))) h1=LNem(h0)+SA(LN(LNem(h0)))
其中 h 0 h_0 h0是初始标记嵌入, L N e m LN^{em} LNem是嵌入层归一化的新成分。请注意,第二项包括两个连续的层规范化。
3.2 模型缩放
规模。我们的模型规模是基于 Chinchilla 的缩放规律,特别是他们的方法 1 和方法 2。我们从 40GB A100 GPU 的 130 万 GPU 小时的总计算预算开始。由于我们采用激活检查点来减少我们的内存占用,由于重复的前向传递,这使我们每次迭代都要花费额外的 0.33 倍 TFLOPs。为了考虑这个额外的成本,我们在 Chinchilla 方程中插入 0.75×1.3M,而不是全部。
从 Hoffmann 等人那里,我们使用表 3 中报告的方法 1 和表 A3 中报告的方法 2 的数据,并将回归线拟合到它们的对数刻度版本。这样我们就得到了:
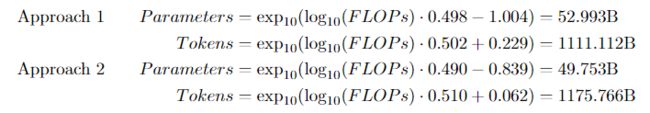
这些计算意味着,考虑到我们的计算预算(假设只通过一次数据),我们的数据集约为 7000 亿个代币,对于 "Chinchilla最优 " 配置来说太小。FinPile 已经是最大的特定领域训练集之一,我们不希望它占我们总训练量的一半以下。
由于我们的数据有限,我们选择了最大的模型,同时确保我们可以在所有的代币上进行训练,并且仍然留有 ~30% 的总计算预算作为缓冲,以应对不可预见的失败、重试和重新启动。这使我们找到了一个 50B 的参数模型,这也是我们计算预算的 Chinchilla 最佳规模。图 1 提供了一个缩放规律的总结,以及 BloombergGPT 与其他模型的对比情况。

形状。为了确定如何将 50B 参数分配给不同的模型组件(即我们模型的 “形状”),我们遵循 Levine 等人的方法 (2020),他提出对于自注意力层的总数 L L L,最佳隐藏维度 D D D 可以通过以下方式获得:
D = e x p ( 5.039 ) e x p ( 0.0555 ⋅ L ) D = exp(5.039)~exp(0.0555\cdot L) D=exp(5.039) exp(0.0555⋅L)
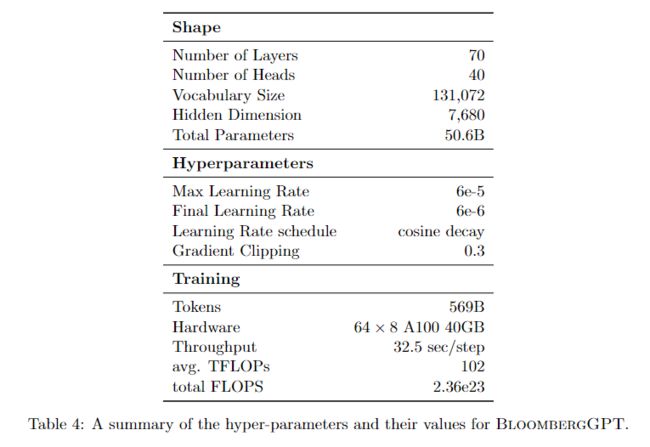
我们将 L L L 扫过一个整数值的范围,并挑选出 ( L , D ) (L,D) (L,D) 的组合,产生总共 ~50B 的参数。这导致我们选择了 L = 70 L=70 L=70 和 D = 7510 D=7510 D=7510 作为目标形状参数。然而,我们也想遵循这样的传统,即隐藏的维度被注意力头的数量均匀地除以,而商数则是注意力头的维度。此外,我们希望维度是 8 的倍数,以便在 Tensor Core 操作中获得更高的性能 NVIDIA(2023)。我们确定了 40 个头,每个头的维度为 192,结果总的隐藏维度为 D = 7680 D=7680 D=7680,总共有 50.6 B 50.6B 50.6B 个参数。表 4 提供了 BloombergGPT 中使用的超参数的摘要。
3.3 训练配置
训练。BloombergGPT 是一个用标准的从左到右的因果语言建模目标训练的 PyTorch 模型。按照 Brown 等人的做法,我们希望所有的训练序列都是完全相同的长度,在我们的例子中是 2,048 个标记,以最大限度地提高GPU 的利用率。为了实现这一点,我们将所有标记化的训练文件与一个 <|endoftext|> 标记作为文件分隔符连接起来。然后,我们把这个标记序列分成 2,048 个标记的小块。请注意,使用这种方法,每个训练序列可能包含来自不同领域的多个文档。还要注意的是,由于我们使用的是 ALiBi 位置编码,BloombergGPT 在推理时可以应用于长于 2,048 的序列。为了优化效率,训练序列被分组为批次,下面将详细介绍。
优化。我们使用 AdamW 优化器。我们设定 β 1 β_1 β1 为 0.9, β 2 β_2 β2 为 0.95,权重衰减为 0.1。按照 Brown 等人的做法,我们将最大的学习率设置为 6e-5,并使用余弦衰减学习率调度器进行线性预热。我们在前 1800 步对学习率进行预热。按照 Hoffmann 等人的做法,最终的学习率是最大学习率的 0.1 倍,即 6e-6。我们还采用了批量预热:在前 7200 步中,我们使用 1024 个批量(210 万个代币),然后在剩余的训练中改用 2048 个批量(420 万个代币)。
在最初的运行中,我们将所有层的辍学率设置为 0.0,尽管后来我们增加了辍学率,如第 4 节所述。模型参数被随机初始化为正态分布的样本,均值为零,标准差 1 / ( 3 D ) = 0.006588 \sqrt{1/(3D)} = 0.006588 1/(3D)=0.006588。按照 Megatron-LM,我们将 MLP 中第二层的标准差和注意力输出层的标准差按 1 / 2 L 1/\sqrt{2L} 1/2L 重新划分。我们使用查询关键层缩放的技术,该技术被提出来改善 FP16 混合精度训练的数值稳定性,但也可能有助于 BF16。
训练的不稳定性。LLMs 优化需要在难以置信的复杂的非凸损失表面上运行凸优化算法。以前的工作已经报告了在训练 LLM 时的各种不稳定性。例如,Chowdhery 等人发现,尽管启用了梯度剪裁,但在训练 PaLM 时,损失激增了大约 20 倍。他们通过在尖峰开始前大约 100 步的检查点重新开始训练,然后跳过 200-500 个数据批,来缓解这些问题。他们假设,尖峰的发生是由于特定的数据批处理与特定的模型参数状态的结合。同样,在 OPT 训练期间,Zhang 等人注意到梯度和激活规范的尖峰,或训练困惑的分歧。在这些行为发生后,他们降低了学习率,从而稳定了这些规范,使训练得以继续。有趣的是,Scao 等人只报告了一个单一的损失尖峰,模型从其中自行恢复了。
硬件堆栈。我们使用 AWS 提供的 Amazon SageMaker 服务来训练和评估 BloombergGPT。我们使用训练时的最新版本,在总共 64 个 p4d.24xlarge 实例上训练。每个 p4d.24xlarge 实例有 8 个英伟达 40GB A100 GPU,采用英伟达 NVSwitch 节点内连接(600 GB/s)和英伟达 GPUDirect 使用 AWS Elastic Fabric Adapter(EFA)节点间连接(400 Gb/s)。这就产生了总共 512 个 40GB 的 A100 GPU。为了快速访问数据,我们使用亚马逊 FSX for Lustre,它支持每 TiB 存储单元高达 1000 MB/s 的读写吞吐量。
3.4 大规模优化
为了训练 BloombergGPT,它的内存占用比云实例上可用的 GPU 内存更大,我们依靠 ZeRO 优化的第三阶段。我们利用 AWS 专有的 SageMaker 模型并行化(SMP)库,该库可以在多个GPU 设备上自动分配大型模型,并在多个设备上自动分配。在试验了各种技术后,我们平均达到 102 TFLOPs,每个训练步骤需要 32.5 秒。我们发现以下设置在我们的训练中是表现最好的。
ZeRO优化(阶段 3)。ZeRO 将训练状态(模型参数、梯度和优化器状态)分散到一组 GPU 中。我们将一个模型分散到 128 个GPU上,在训练中我们有 4 个模型的副本。
MiCS。Zhang 等人降低了云训练集群的训练通信开销和内存再需求。MiCS 包括分层通信、2 跳梯度更新、规模感知模型分区等功能。
激活检查点。Chen 等人通过移除激活来最小化训练内存消耗,代价是在后向传递过程中的额外计算。当一个层启用激活检查点时,只有层的输入和输出在前向传递后被保留在内存中,而任何中间张量被从内存中丢弃。在后向传递过程中,这些中间张量可以被重新计算。我们将激活检查点应用于每个转化器层。
混合精度训练。为了减少内存需求,前向和后向都以 BF16 进行,而参数则以全精度(FP32)存储和更新。ALiBi 矩阵是以全精度计算的,并存储在 BF16 中。我们还使用 FP32 来计算 Attention 块中的融合 softmax,并将其结果存储在 BF16 中。最后,损失函数中的 softmax 计算是以 FP32 计算的。
融合内核。另一种优化的可能性是将几个操作组合成一个单一的 GPU 操作。这既可以通过避免在计算图中存储中间结果来减少峰值内存用量,也有助于提高速度。与 Megatron-LM Shoeybi 等人(2019)类似,我们在 SMP 中的自我注意模块中使用了一个掩蔽-因果-软键融合内核。在实践中,我们观察到速度有 4-5 TFLOPs 的提高,并在其余配置的情况下避免内存外错误。
4. 训练运行
训练 BloombergGPT 的过程涉及到根据模型训练的进展而做出的决定。我们分享这个过程中的一些亮点。图 2 显示了训练和验证集的学习曲线。实线显示的是(平滑的)训练损失,虚线显示的是被保留的验证集的损失。线条颜色的变化表示优化超参数配置的变化,要么是按计划,要么是对验证损失的增加或停滞的反应。该图显示了成功的模型训练运行的路径。为了呈现一个清晰的图表,该图没有显示不同模型配置的其他尝试、回滚后被覆盖的部分运行,或在最终模型中没有使用的其他训练策略。
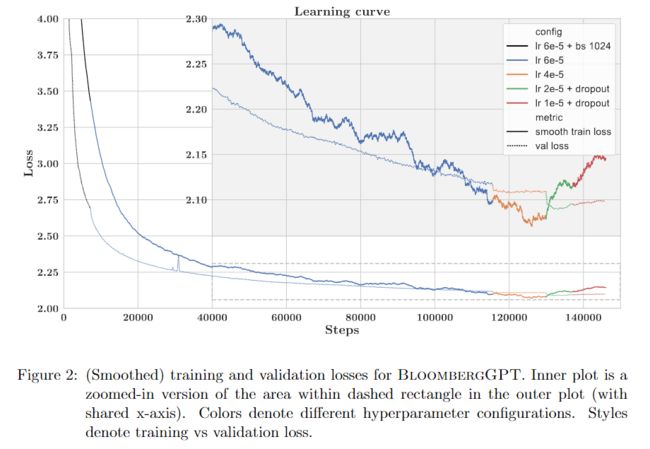
图 2:BloombergGPT 的(平滑)训练和验证损失。内部图是外部图中虚线矩形内区域的放大版本(具有共享 x 轴)。颜色表示不同的超参数配置。样式表示训练损失与验证损失。
我们在当前批次上每五步测量一次训练损失。原始值变化很大,在绘图时造成很大的抖动。该图通过显示一个运行的平均值来平滑训练损失 y t = Σ i = 0 t x i ⋅ ( 1 − α ) ( t − 1 ) Σ i = 0 t ( 1 − α ) ( t − 1 ) y_t = \frac{\Sigma^t_{i=0} x_i\cdot (1-\alpha)^{(t-1)}}{\Sigma^t_{i=0}(1-\alpha)^{(t-1)}} yt=Σi=0t(1−α)(t−1)Σi=0txi⋅(1−α)(t−1),其中 α = 0.001 α=0.001 α=0.001。对验证损失不需要进行平滑处理,因为它是在整个验证集上每 300 步测量一次。我们总共训练了 139,200步(约 53 天),并在完成了训练数据(709B 标记中的 569B 标记)80% 的历时后结束了模型训练。我们提前结束了训练,因为在我们保留的开发集上的损失不再改善,尽管大幅延长训练可能会产生进一步的改善。
我们以 1,024 的热身批处理量开始运行,进行了 7,200 步,之后我们切换到 2,048 的常规批处理量(颜色从黑色变为蓝色)。批量大小的变化表现为在 7,200 步的验证损失中出现明显的曲率变化。训练的其余部分大多表现稳定,训练和验证损失不断减少。在后来的阶段,即步骤 115500 之后,我们观察到验证损失持平或增加,就需要进行干预。然后,我们依次应用了以下纠正性修改措施:
- 步骤 115,500(蓝色到橙色):将学习率缩减到 2/3;
- 步骤 129,900(橙色到绿色):将学习率减半,并增加辍学率(概率为 0.1 能力);
- 步骤 137,100(绿色到红色):再次将学习率减半;
我们在第 146,000 步结束了运行,因为在验证损失方面缺乏可观察的进展。根据验证损失和下游评估,我们选择了步骤 139,200 的检查点作为最终模型。
5. 评估
我们评估了 BloombergGPT 在两大类任务中的表现:金融类任务和通用任务。金融类任务帮助我们测试了我们的假设,即在高质量的金融类数据上进行训练会在金融类任务上产生更好的结果。一般目的的任务是研究我们的模型的性能是否可以直接与以前公布的结果相媲美。对于金融任务,我们收集了公开可用的金融数据集,包括一系列的 NLP 任务。然后,为了直接测试 BloombergGPT 在 Bloomberg 感兴趣的任务上的能力,我们还从 Bloomberg 内部的高质量评估集中抽取了情感分析和命名实体识别等任务。对于通用任务,我们从现有的多个基准中提取,并将结果分为以下几类:BIG-bench Hard, Knowledge Assessments, Reading Comprehension, and Linguistic Tasks。每种类型的任务数量和分组的定义见表 5。

表 5:评估基准。我们根据一组高覆盖率的标准基准来评估 BloombergGPT,这些标准基准评估取自 HELM、SuperGLUE、MMLU 和 GPT-3 套件的下游性能。由于它们具有显着的重叠和/或相互包含,因此我们将它们重组为此处介绍的类别。我们仅评估每个数据集的一个设置。我们进一步评估 BloombergGPT 的一系列内部和公共财务任务。

表 6:评估模型队列。 OPT 和 BLOOM 都有多种尺寸可供选择,我们会报告我们评估过的尺寸。我们注意到,模型之间的计算数字仅具有部分可比性:例如,BLOOMs 训练数据只有 1/3 英语,而 OPT 则重复了部分训练数据。我们会在可用时报告 GPT-3 结果,但由于缺乏可用性而没有自行运行。
我们根据模型大小、训练数据类型、整体性能以及最重要的访问量,将 BloombergGPT 与 § 7 中描述的三个最接近的模型进行比较。表 6 中提供了模型大小和计算的概述。
- GPT-NeoX:根据 Liang 等人的研究,该模型是 50B 参数下性能最好的可用模型。
- OPT66B:我们选择与 OPT66B 进行比较,因为我们的模型大小和结构大致相同,尽管我们的模型更小。
- BLOOM176B:虽然这个模型比 BloombergGPT 大得多,但我们使用相同的模型结构和软件栈。我们注意到,BLOOM176B 是多语言的,所以虽然它大得多,但它也是在更多语言的数据上训练出来的。
这三个模型都使用了我们在训练中使用的一些相同的通用数据集。我们还报告了原始 GPT-3 的结果,只要是外部可用的。
我们倾向于自己运行模型,以确保相同的评估设置,我们将任何在其他地方报道过的、不是由我们运行的结果放在一个单独的组中。为了公平地比较这些模型,我们避免对提示和其他技术进行任何调整,因为这些调整可能导致某些模型的结果得到改善,但不是所有的模型。为此,每个任务都通过 "标准 "提示进行测试(如表 7 所示),即没有对基础模型进行任何参数改变,没有任务描述,也没有思维链提示。呈现给模型的几张照片的数量取决于任务,我们在各自的章节中包括这些细节。对于每组结果,我们进一步提出与 Liang 等人类似的胜率,它代表了我们自己运行评估的所有模型对之间的单个任务的并排比较中的 “胜利” 部分。
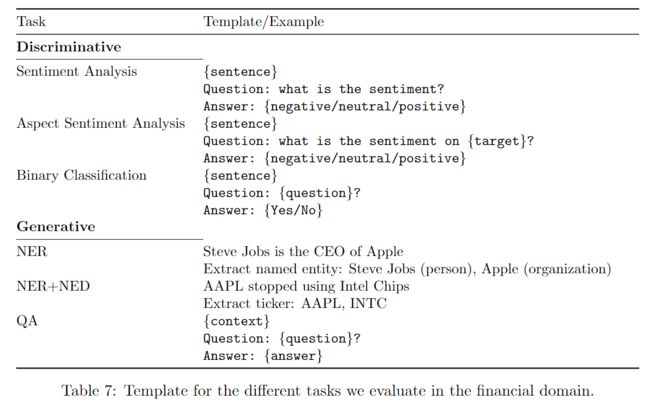
表 7:我们在金融领域评估的不同任务的模板。
5.1 Few-shot 方法
对于给出一组候选人的任务,我们按照 Brown 等人的做法,进行基于似然的分类。我们考虑了三种分类方法:规则化、口径化和规范化。从形式上看,
- 常规: a r g m a x α p ( α ∣ s ) arg~max_{\alpha}~p(\alpha | s) arg maxα p(α∣s);
- 校准: a r g m a x α p ( α ∣ s ) / p ( α ∣ " A n s w e r : " ) arg~max_{\alpha}~p(\alpha | s) / p(\alpha | "Answer:") arg maxα p(α∣s)/p(α∣"Answer:");
- 归一化: a r g m a x α p ( α ∣ s ) / l e n ( α ) arg~max_{\alpha}~p(\alpha | s) / len(\alpha) arg maxα p(α∣s)/len(α);
其中 α \alpha α 是候选词, s s s 是上下文, l e n len len 衡量子词标记的数量。我们报告每个模型和任务的最佳方法的性能。对于其他任务,我们通过贪婪的解码进行生成。
只要有可能,我们就会使用外部分割并报告测试集的性能。如果测试标签不公开,我们就报告设计集的性能。如果一个数据集的外部分割不存在,我们通过选择 20% 的例子作为测试,其余作为训练,来创建训练和测试分割。所有的少见语境的例子都是从训练集中抽出来的。为了减少少数照片评估的差异,除非另有规定,否则我们对每个测试例子抽取不同的镜头。为了保持一致性,对于每个测试例子,所有的模型都有相同的表面形式作为我们评估的输入。
5.2 保留损失
我们首先测试了 BloombergGPT对in- distribution 金融数据的语言分布的建模情况。我们在一个包含 FinPile 所有部分的例子(在 § 2 节中描述)的保留数据集上评估不同模型的每字节比特数。为了限制数据泄露,并更好地模拟 LLM 的真实使用情况,我们选择了一个严格意义上比训练集更久远的时间上的搁置数据集,并在训练集和搁置集之间执行重复数据删除。在评估过程中,对于长度超过 2,048 个标记的文件,我们使用滑动窗口的方法,以一半的窗口大小作为背景。这意味着在预测过程中,超过前 2048 个的任何标记都至少有 1024 个标记作为上下文。我们按 FinPile 中的文件类型报告损失分类。
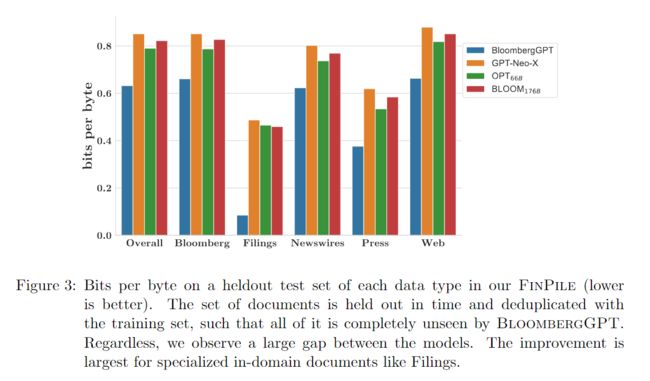
图 3:FinPile 中每种数据类型的保留测试集的每字节位数(越低越好)。该文档集被及时保存并与训练集进行重复数据删除,因此 BloombergGPT 完全看不到所有这些文档。无论如何,我们观察到模型之间存在很大差距。对于诸如申请之类的专业域内文档来说,改进最大。
图 3 显示,BloombergGPT 的表现一直优于其他模型。虽然这是预料之中的,而且主要是作为一种理智的检查,但它也为其他模型的概括能力提供了宝贵的见解。例如,与 BloombergGPT 的差距在文件类别中最为明显,可能是因为这些文件虽然是公开的,但通常是 PDF 格式的,因此没有包括在任何现有的数据集中。
5.3 财务任务
金融领域最常考虑的 NLP 任务在更广泛的 NLP 文献中也很常见;但是,这些任务在对金融数据进行分析时具有不同的特点和挑战。以情感分析为例,诸如 “COM-PANY 将削减 10000 个工作岗位” 这样的标题在一般意义上描绘了负面的情感,但有时也会被认为是对公司的金融情感是积极的,因为它可能会导致股票价格或投资者信心增加。我们使用公共和内部基准的组合来评估 BloombergGPT、BLOOM176B、GPT-NeoX 和 OPT66B 的表现。所有考虑的任务类型及其相应的提示模板见表 7。
5.3.1 外部财务任务
我们的公共金融基准包括 FLUE 基准和 ConvFinQA 数据集中的四个任务。由于 LLM 在这些金融任务中的表现还没有被广泛报道,因此没有标准的测试框架。因此,我们对它们进行了调整,使其适用于少量的设置(见第 5.1 节)。我们在设计实验时的指导原则是选择拍摄次数,使所有模型的平均性能达到最佳。虽然这些任务的定制模型的非 LLM 数量是可用的,但由于评估设置的不同,我们在此省略了报告。因此,我们的主张仅限于 LLMs 的比较。我们对以下任务进行评估(更多细节见附录 B):
- FPB:金融短语库数据集包括对金融新闻句子的情感分类任务。任何可能对投资者有利/不利的新闻都被认为是积极/消极的,否则就是中性的。我们创建了我们自己的分类,并在 5 次拍摄中报告了由支持度加权的 F1 得分。
- FiQA SA:第二个情感分析任务是预测英语财经新闻和微博头条中特定方面的情感,这些新闻和微博头条是作为 2018 年金融问题回答和意见挖掘挑战的一部分发布的。虽然原始数据集是在一个连续的尺度上注释的,但我们将数据离散成一个具有消极、中立和积极类别的分类设置。与 FPB 一样,我们创建了自己的分割,包括微博和新闻,并使用 5 次拍摄设置,报告加权的 F1。
- 标题:这是一个二元分类任务,即黄金商品领域的新闻头条是否包括某些信息。这个由人类注释的数据集包括关于 “黄金” 的英文新闻标题。每篇新闻都带有以下标签的一个子集:“价格与否”、“价格上涨”、“价格下跌”、“价格稳定”、“过去的价格”、“未来的价格”、“过去的一般”、“未来的一般”、“资产比较”。我们用 ocial 文档将每个标签口述成一个问题,使用 5 个镜头,并报告所有类别的平均加权 F1 得分。
- NER:这是一项针对金融数据的命名实体识别任务,这些数据来自于提交给 SEC 的金融协议,用于信用风险评估。被注释的实体类型遵循标准的 CoNLL 格式,并被注释为 PER、LOC、ORG 和 MISC。由于在少量的设置中学习预测空的输出是不可行的,我们放弃了不包含任何实体的句子。由于 MISC 标签的定义不明确,我们进一步删除了它。所有的模型都需要更多的镜头才能表现良好,因此我们选择了 20 个镜头,并报告实体级的 F1 得分。
- ConvFinQA:给定来自标准普尔 500 指数收益报告的输入,包括文本和至少一个包含财务数据的表格,任务是回答需要对输入进行数字推理的转换问题。这项任务需要数字推理、对结构化数据和金融概念的理解,并且需要一个模型将后续问题与对话转折联系起来。
对于 ConvFinQA,我们使用整个黄金对话,其背景被用作模型的输入。当对话的每个 “回合” 结束时,该 “回合” 与该回合的答案一起被附加为未来回合的背景。我们报告了公共开发集上的精确匹配精度。
BloombergGPT 在五个任务中的四个任务(ConvFinQA、FiQA SA、FPB 和 Headline)中表现最好,在 NER 中排名第二(表 8)。因此,在我们测试的所有模型中,BloombergGPT 的胜率也是最高的。对于 ConvFinQA 来说,与同等规模的模型的差距尤其明显,由于要求使用对话输入来推理表格并生成答案,所以 ConvFinQA 具有挑战性。

表 8:金融领域任务的结果。
5.3.2 内部任务:情感分析
对于彭博社的内部任务,我们考虑针对特定方面的情感分析,这在金融文献中是很普遍的。我们使用的所有数据集都是英文的。
我们的注释过程包括一个发现阶段,在此期间,我们建立一个符号和抽样程序,了解每个例子通常需要多少注释者,并确定注释者需要的培训水平。根据任务的复杂性,我们的注释者是彭博社的一个专门的金融专家团队、顾问工人或两者的组合。在每一种情况下,平局都是由额外的注释者裁定解决的,模糊的例子被排除。本节中的所有数据集都由两名注释者进行注释,并由第三名注释者打破任何平局。
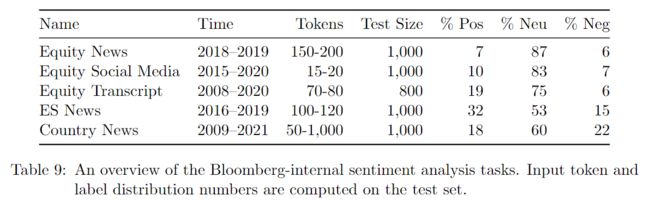
表 9:彭博内部情绪分析任务概述。输入标记和标签分布数是在测试集上计算的。
我们使用与外部数据集类似的五次评价来衡量 LLM 在内部数据集上的表现。由于数据集很大,我们最多随机抽取 1k 个测试例子。我们报告了由每个标签的支持度加权的 F1。请注意,与外部数据集类似,在我们的内部数据集中使用的未标记的数据版本很可能出现在 FinPile 中,因此在训练期间被 BloombergGPT 看到。然而,由于 FinPile 的一些内容也可以在网上找到,我们与之比较的其他 LLM 也可能是在这些数据的无标签版本上训练的。数据集的统计数据见表 9。
- 股票新闻情绪:这项任务是预测新闻故事中对一个公司的特定情感。该数据集由彭博社的英文新闻故事、高级内容和网络内容组成。对 “正面”、"负面"或 “中性” 的注释表明,该新闻故事可能会增加、减少或不改变投资者对该公司的长期信心。
- 股票社交媒体情绪:该任务类似于 “股票新闻情绪”,但我们使用的不是新闻,而是与金融相关的英文社交媒体内容。
- 股票记录情绪:这项任务也类似于 “股票新闻情绪”,但我们使用的不是新闻,而是公司新闻发布会的文字记录。这些文字记录是通过使用语音识别,有时还需要人工编辑来实现的。长的文字记录是分块处理的,在我们的数据集中,每个块通常包含 70 到 80 个标记。
- ES 新闻情绪: 虽然这项任务是预测新闻故事中对某一公司(方面)所表达的特定方面的情绪,但其目的不是为了表明对投资者信心的影响。如果新闻故事中含有反映公司环境和社会政策的好的、坏的或中性的新闻内容,那么这些故事将被注释为 “正面”、“负面” 或 “中性”。
- 国家新闻情绪: 这项任务与其他情感任务不同,其目标是预测新闻故事中对一个国家的情感表达。该数据集由彭博社的英文新闻故事、优质内容和网络内容组成。如果新闻报道中提到了该国经济的增长、萎缩或现状,这些故事就会被注释为 “正面”、“负面” 或 “中性”。
表 10 显示,在四个内部特定的情感任务中,BloombergGPT 的表现比其他所有测试模型都要好,差距很大。唯一的任务是模型表现相似的任务是社交媒体情感任务,而 BloombergGPT 在其他三个任务中比其他模型至少高出 25 分,最高超过 60 分。

表 10:内部特定方面情绪分析数据集的结果。 BloombergGPT 在情绪分析任务上远远优于所有其他模型。
5.3.3 探索性任务:NER
尽管 NER 是一项成熟的 NLP 任务,使用 BERT(Wu 和 Dredze,2019;Luoma 和 Pyysalo,2020)和 T5(Liu 等人,2022)风格的模型取得了最先进的结果,但 NER 在很大程度上是一个生成式 LLM 的未探索任务。HELM 中没有 NER(Liang 等人,2022),BIG-bench 中只有一个(Polish)任务(Srivastava 等人,2022),并且我们研究的 LLM 论文都没有报告 NER 性能。因此,鉴于 NER 在金融领域的重要性,我们将 NER 视为一项探索性任务并报告初步 NER 结果。
对于生成式 LLM 来说,NER 可能是一项困难的任务,有几个原因。误码率是一项信息提取任务,更适合于编码器-解码器或仅编码器的架构。LLMs 的生成性质并没有为 NER 带来优势。我们发现,与其他任务相比,为获得合理的 NER 结果,需要大量的提示工程和更多的拍摄次数。针对金融业的 NER 有一些微妙之处,使其在零或少量的学习中特别困难。
例如,考虑到(编造的)标题 “彭博社:马斯克先生在 Twitter 上增加了新的功能,并对中国进行了评论”。根据我们的注释指南和下游任务的需要:(a) 报道新闻的组织 “彭博社” 可以被标记或不被标记,这取决于我们是否只想要突出的实体,(b) “马斯克先生” 或只是 “马斯克” 是要被标记的 PER,© “Twitter” 可以被标记为 ORG 或 PRD(产品),因为功能是添加到 Twitter 产品而不是组织,以及 (d) “中国” 可以被标记为 ORG 或 LOC,尽管正确的标记可能是 ORG。如果不在提示中加入广泛的注释指南,LLM 就不知道预期的标签行为。
基于初步测试,我们确定了以下设置,以获得所有模型在内部 NER 任务上的最佳性能。首先,我们把要预测的实体类型限制为 ORG、PER 和 LOC。总的来说,我们过滤掉了不到 1% 的实体。我们还删除了所有不包含实体的文档(即所有的 “O”)。这两种修改都是为了增加在少数提示中看到的例子的有用性。我们希望在 NER 的提示工程方面的进一步工作能够产生更好的结果。
我们考虑了七个来自不同领域的彭博社内部 NER 数据集。
- BN NER:这是对 2017 年至 2020 年间彭博社英文长篇新闻内容(“BN wire”)中出现的实体的命名实体识别任务。
- BFW NER:与 “BN NER” 类似,但我们使用 2018 年至 2020 年期间 “Bloomberg First Word” 中的短篇报道,而不是使用长篇的 BN 线。
- Filings NER:这项任务的目标是识别公司提交的强制性财务披露中出现的实体。该数据集包含在 2016 年至 2019 年期间抽样的文件。
- Headlines NER:这项任务的目标是识别出现在彭博社英文新闻内容的标题中的实体。该数据集包含 2016 年至 2020 年的头条新闻采样。
- Premium NER:这项任务的目标是识别彭博社摄取的第三方英文新闻内容的子集中出现的实体。该数据集包含 2019 年和 2021 年之间采样的故事。
- Transcripts NER:该任务的目标是识别出现在公司新闻发布会记录中的实体。该数据集包含 2019 年的文字记录。
- Social Media NER:这项任务的目标是识别英语金融相关的社交媒体内容中出现的实体。该数据集包含 2009 年至 2020 年期间取样的社交媒体内容。
由于我们的数据集是实质性的,我们从每个经过过滤的内部数据集中随机抽取 4000 个训练样本和 500 个测试样本。我们利用 20 次的提示,用 F1 进行评估。内部 NER 任务的结果是混合的(表 12)。大得多的 BLOOM176B 赢得了大部分的 NER 任务。在同样大小的模型中,BloombergGPT 的成绩最好,排名第一(标题),第二四次(BN、Premium、Transcripts、Social media),第三一次(BFW),最后一次(Filing)。
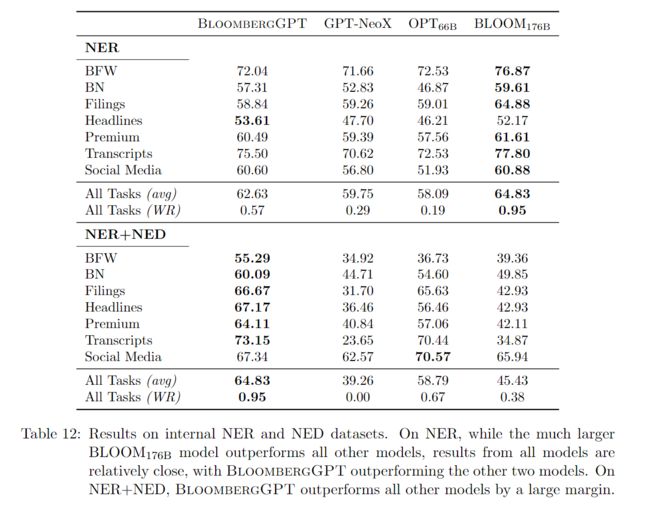
表 12:内部 NER 和 NED 数据集的结果。在 NER 上,虽然更大的 BLOOM176B 模型优于所有其他模型,但所有模型的结果都相对接近,其中 BloombergGPT 优于其他两个模型。在 NER+NED 上,BloombergGPT 大幅优于所有其他模型。
探索性任务:NER+NED 命名实体消歧(NED)将实体提及与知识库或其他结构化信息源中的已知实体联系起来。在金融领域,我们试图将文本中提到的公司与它们的股票符号联系起来,股票符号是一个缩写,用于唯一识别特定股票市场上公开交易的股票。
我们通过评估一个联合的 NER+NED 任务来直接测试 LLM 完成这一任务的能力:识别文件中提到的公司的股票代码。这就要求模型首先识别提到的公司,然后生成相应的股票代码。例如,鉴于 “AAPL 宣布他们将在未来的产品中停止使用英特尔芯片”,正确的 NER 输出将是 “AAPL, Intel”,而正确的 NER+NED 输出将是 “AAPL, INTC”。
这个任务的优点之一是它对提取确切的文本跨度的变化具有鲁棒性。虽然 NER 的评估需要精确的匹配,但不需要首先识别跨度就可以成功地生成 tickers。此外,它评估了一个模型对公司、其各种表面形式以及公司与股票的映射的知识。
我们通过在每个领域的彭博社内部 NER 注释的文档上运行一个最先进的实体链接系统,为金融数据中的公司创建带有链接的股票的评估数据。我们删除了没有链接代码的文档。在 NER 评估之后,我们从每个经过过滤的内部数据集中随机抽出 4000 个训练样本和 500 个测试样本。我们利用 20 次的提示,用 F1 进行评估。
表 12 显示,BloombergGPT 在很大程度上优于其他所有模型,但在社交媒体数据上,它排在 BLOOM176B 之后。在我们的社交媒体数据中,公司往往是通过其股票代码来引用的,这就取消了模型链接提及的要求,并将任务还原为 NER。这些结果进一步强调了 BloombergGPT 在金融任务中的优势。
5.4 BIG-bench Hard
我们现在转向在标准、通用 NLP 任务上评估 BloombergGPT。虽然我们模型的重点是财务任务,但我们包含通用训练数据不仅可以帮助改进财务任务,还可以让我们的模型在更标准的 NLP 数据集上表现良好。我们从 BIG-bench Hard(Suzgun 等人,2022)开始,这是 BIG-bench 中最具挑战性的任务的子集(Srivastava 等人,2022)。它仅包括构建时的最佳可用模型无法通过标准提示技术实现高于平均人类评估者的性能的任务。

表 13:使用标准 3 次提示的 BIG-bench 硬结果。遵循 Suzgun 等人的惯例。 (2022),我们用上标 λ 表示算法任务,并给出 NLP 和算法类别的平均值。 PaLM540B(Chowdhery 等人,2022)的基线数字取自原始 BBH 论文。
每个任务的结果如表 13 所示。总体而言,虽然 BloombergGPT 落后于更大的 PaLM540B(10 倍参数)和 BLOOM176B(3.5 倍参数),但它是类似大小的模型中表现最好的。事实上,它的性能更接近 BLOOM176B,而不是 GPT-NeoX 或 OPT66B。它还在日期理解、hyperbaton(形容词排序)和跟踪打乱的对象方面实现了所有模型的最佳性能。总之,根据这个基准,我们发现开发金融专用的 BloombergGPT 并没有以牺牲其通用能力为代价。
5.5 知识评估
我们接下来评估知识,我们把它定义为回忆在模型训练中看到的信息的能力。知识的评估是通过让模型回答问题而不提供额外的背景或资源(闭卷情景)。这包括多项选择题,并且我们报告了准确性。我们遵循 Brown 等人(2020)的模板。情景列表如下:
- ARC:从三年级到九年级的科学考试中收集的多项选择题,包括简单和具有挑战性的分叉。
- CommonsenseQA:需要不同类型常识性知识的多选题 QA 数据集。
- MMLU:在 57 个科目中手动收集的多项选择知识问题。
- PhysicalQA:关于物理世界如何运作的问题。
BloombergGPT 在 BLOOM176B、GPT-NeoX 和 OPT66B 的一项任务中取得了最高的性能,在其他三项任务中位居第二(表 14)。与上一节类似,它的性能优于类似规模的模型,而几乎与更大的模型持平。大规模多任务语言理解涵盖了 57 个不同的主题,因此比上述任务的覆盖面要广得多。表 15 中的汇总结果描绘了一个更加一致的画面,并遵循在 BIG-bench hard 中看到的见解。BloombergGPT 一直优于 OPT66B,而 OPT66B 又优于 GPT-NeoX,而 GPT-3 的表现最好。与前几节相比,BloombergGPT 在这一类别中也优于 BLOOM176B,尽管差距很小。它落后于 GPT-3 的报告性能,特别是在社会科学类别中。与 GPT-3 的差距在 STEM 和 “其他” 领域最为接近,这些领域包括金融和会计相关的问题。

表 14:知识任务 1-shot 结果。 GPT-3 的基线数字取自 Brown 等人(2020)。在所有模型中,BloombergGPT 在我们自己运行的模型中胜率最高,平均表现第二好。

表 15:MMLU(Hendrycks 等人,2021)基准的结果(5 次)。 GPT-3 的基线数字取自 Hendrycks 等人(2021)。虽然 BloombergGPT 在其中三个类别上落后于 BLOOM176B,但其平均值是我们自己评估的所有模型中最高的。社会科学领域与 GPT-3 的差距最大,而其他类别的表现则接近。
5.6 阅读理解
我们将阅读理解基准定义为模型能够根据所呈现的输入文本中的信息产生正确反应的任务。我们的分组包括开卷的 QA 任务,与Brown等人(2020)相反,他们将这些任务分成不同的类别。我们遵循 Brown 等人(2020)的模板,并报告准确性。我们包括以下任务:
- BoolQ:关于维基百科的一段话的是/否问题。
- OpenBookQA:小学水平的科学问题的多选题,给定一本书的科学事实,应用于新的情况。
- RACE:一个初中和高中英语考试的多选数据集。
- 多句子阅读理解:短的段落和多句子问题。
- 用常识推理进行阅读理解:自动生成关于 CNN 和《每日邮报》新闻文章的问题。
表 16 反映了与上述评价中类似的排名情况:虽然 GPT-3 的性能最高,但 BloombergGPT 却紧随其后。除了 OpenBookQA,BloombergGPT 的性能是 BLOOM176B、GPT-NeoX 和 OPT66B 中最高的。令人惊讶的是,BLOOM176B 在这个类别中明显落后。

表 16:阅读理解结果(1 次)。 GPT-3 的基线数字取自 Brown 等人(2020)。 BloombergGPT 远远超过了我们自己评估的模型,并且稍微落后于 GPT-3。
5.7 语言任务
我们将那些与面向用户的应用没有直接联系的场景定义为语言学任务。这些任务包括评估消歧义、语法或连带关系的任务。这些任务旨在直接评估一个模型理解语言的能力。我们遵循 Brown 等人(2020)的模板,并报告准确性。任务的清单如下:
- 识别文本含义:给出两个文本片段,识别其中一个文本的含义是否包含在内。
- 对抗性 NLI:逆向构建的必然性检测。
- 承诺银行:自然发生的话语,其最后一个句子包含一个句子嵌入的谓语。
- 合理选择:前提和两个备选方案,任务是选择与前提有更合理的因果关系的方案。
- 语境中的词语:判断一个词在两个句子中的含义是否相同。
- Winograd:当代词在语义上不明确时,确定它指的是哪个词。
- Winogrande:反向挖掘有挑战性 Winograd 实例。
- HellaSWAG:为一个故事或一组指令挑选的最佳结局。
- StoryCloze:为五句话的长篇故事选择正确的结尾句。
语言类任务的结果(表 17)与知识类的趋势相似。BloombergGPT 略微落后于 GPT-3,而超过了其他模型。与阅读理解类别类似,BLOOM176B 落在 BloombergGPT 后面。

表 17:语言场景结果(1-shot)。 GPT-3 的基线数字取自 Brown 等人。 (2020)。胜率和平均值仅根据准确度数字计算。 BloombergGPT 在我们评估的模型中始终得分最高,胜率高达 85%。
5.8 总结
在许多基准测试中的数十项任务中,出现了清晰的画面。在我们比较的数百亿参数的模型中,BloombergGPT 表现最好。此外,在某些情况下,它具有竞争力或超过了更大模型(数千亿个参数)的性能。虽然 BloombergGPT 的目标是成为金融任务中的最佳模型,并且我们包含了通用训练数据来支持特定领域的训练,但该模型在通用数据上的能力仍然超过了类似规模的模型,并且在某些情况下匹配或优于更大的模型。
6. 定性样本
我们现在分享我们模型中的定性例子,这些例子突出了我们的领域专业化的好处。
Bloomberg 查询语言的生成。BloombergGPT 的一个用例是使与金融数据的互动更加自然。检索数据的一种现有方式是通过彭博查询语言(BQL)。BQL 可用于与不同类别的证券进行互动,每一类都有自己的字段、函数和参数。BQL 是一个令人难以置信的强大但复杂的工具。正如我们在图 4 中所示,BloombergGPT 可以通过将自然语言查询转化为有效的 BQL,从而使 BQL 更易于使用。

图 4:使用 BloombergGPT 生成有效的 Bloomberg 查询语言。仅使用几次镜头设置中的几个示例,该模型就可以根据自然语言的请求,利用其有关股票行情和财务术语的知识来组成有效的查询来检索数据。在每种情况下,模型都会给出 3 个示例(未显示),后跟 “输入” 和 “输出:” 提示。
关于新闻标题的建议。其他得到良好支持的例子是在新闻领域。由于它是在许多新闻文章上训练出来的,它可以用于许多新闻应用,并协助记者的日常工作。例如,在构建新闻通讯时,记者可能需要为每个新的部分写出简短的标题。虽然一个专门的模型来帮助完成这项任务可能过于昂贵,难以维护,但 BloombergGPT 开箱即用,表现良好(图 5)。

图 5:使用 BloombergGPT 在三镜头设置中生成短标题建议。彭博新闻社每天发送许多需要这些头条新闻的新闻通讯。 BloombergGPT 可以通过建议文本中的初始标题来帮助编辑过程。
金融问题的回答。由于金融领域的训练数据,我们能够向 BloombergGPT 查询与金融世界相关的知识。例如,它在识别一个公司的 CEO 方面表现良好。图 6 显示了几个例子,包括其他模型的输出。虽然 BloombergGPT 正确地识别了 CEO,但 GPT-NeoX 却没有,而 FLAN-T5-XXL 则完全失败,一直忽略了公司,而是预测了提示中包含的 Cirrus Logic 公司的 CEO。虽然 BloombergGPT 不能完美地解决这个任务,并且会犯错误,但我们无法找到任何其他模型解决了这个任务而 BloombergGPT 却没有的例子。

图 6:测试 BloombergGPT、GPT-NeoX 和 FLAN-T5-XXL 回忆公司首席执行官姓名的能力。每个模型都在 10 次拍摄设置中运行。我们会抽取最多三个答案,如果不正确则将全部答案呈现出来。 *Michael Corbat 担任花旗集团首席执行官直至 2021 年,强调了最新模式的重要性。
7. 相关工作
语言模型。语言模型在 NLP 界有很长的历史。训练概率语言模型来为单词序列评分的想法可能是由 Jelinek(1976)首次提出的。N-gram 模型流行了几十年,并在语料库上训练了高达 2 万亿代币。在过去的十年中,由于机器学习、数据可用性和计算方面的创新,训练语言模型的研究加速了。自回归语言建模的早期工作使用了递归神经网络,但这些是在小数据集上训练的小模型。转换器架构的引入促进了这些模型在数据、计算和参数数量方面的扩展。
开发模型的过程能够更好地接近语言在大型语料库中的分布,从而发现这些模型产生的表征是许多下游任务的有用起点。Radford 等人(2018)以及 Howard 和 Ruder(2018)证明了这一点,他们表明以自回归语言建模为目标的生成式预训练在迁移学习中取得了出色的表现。Radford 等人(2019)进一步表明,扩大模型规模和训练数据导致自回归语言模型在不同的下游任务中表现良好,无需任何额外的监督微调。
Brown 等人(2020)表明,进一步扩展模型导致出现新的模型能力和模型的稳健性提高。自从 Brown eta1.(2020)发布 GPT-3 以来,许多其他研究者建立了大型语言模型,以研究数据数量、数据质量、网络结构、参数缩放、数据缩放、标记化和开源策略。
特定领域的大型语言模型。针对特定领域的训练对于掩码(仅指编码器)语言模型的价值已被证实。普遍接受的方法是在特定领域的数据上从头开始训练 BERT 模型,或在新的特定领域数据上继续预训练现有模型。遵循这些策略,BioBERT 将 BERT 适应于生物医学领域,SciBERT 则在科学出版物上进行训练。这些论文的结果表明,领域内训练使模型在各种生物医学文本挖掘任务中的表现优于以前的最先进模型。这种范式的进一步例子是用于临床领域的 ClinicalBERT,用于科学生物医学论文的 BioMed-RoBERTa,以及用于 Twitter 数据的 BERTweet 和 Bernice。
由于训练 10B 以上参数的自回归-解码器-纯语言模型的成本明显高于训练 1B 参数下的掩码 LMs,因此特定领域的自动回归模型的例子要少得多。然而,现有的方法都遵循同样的两种策略。调整现有的模型之后,medPaLM 使 PaLM 适应生物医学领域,Minerva 使之适应数学推理任务。
最近,出现了几个为特定领域数据从头开始训练的纯解码器模型的例子。一个流行的领域是蛋白质序列,因为它们可以用类似语言序列来表示,但不包括在自然语言模型中。但自然语言领域的模型也有好处。Galactica 专门在大量的科学数据集上进行训练,并包括科学符号的特殊处理。Galactica 在科学任务上表现非常好的同时,在更多标准的 NLP 任务上也有令人惊讶的表现。BioGPT 和 BioMedLM Bolton 等人(2023)都是在生物医学数据上训练的小型 GPT 式模型。Lehman 等人(2023)比较了专门在特定领域数据上训练的编码器/解码器模型与那些从通用训练中调整的模型。从事大型生成性语言对话模型的研究人员对使用特定领域训练数据的好处得出了类似的结论。
这些发现突出了域内预训练的优势,特别是有足够数据可用的情况下,就像我们的情况那样。受 Galactica 通用能力的启发,我们用公共数据来增强我们的私有数据,目的是研究一个模型是否可以在不牺牲通用领域性能的情况下获得领域内能力。
训练数据。大规模的原始文本数据库对于训练 LLMs 至关重要。因此,现在有几个涵盖广泛来源的语料库。
Colossal Clean Crawled Corpus从Common Crawl 中提取,以创建一个经过处理的训练语料。The Pile 是一个精心策划的语料库,包含广泛的数据源。这些数据集是建立或包括在网络爬虫 (OpenWebText2) 上的,它由来自高质量来源的数据数组增强。各种努力都是为了通过删除不需要或有害的文本来清理数据集,特别是 web 数据。BLOOM 仔细选择数据源,并包括各种过滤机制。
虽然网络数据是获得大量不同数据的有效策略,但强大的清理工作仍然会导致数据伪影、重复以及各种类型的有毒语言,而且会导致少数人的声音被无意地边缘化。Dodge 等人(2021)研究了 C4,以更好地了解元数据,以及包含和排除的数据。他们的发现表明,C4 包含的机器生成的文本由于排除过滤器而有偏差,并且可能包含从 NLP 任务的评估数据集中提取的例子。Zeng 等人(2022)也做了类似的努力,记录了他们为训练中文大语言模型所做的预处理。
Lee 等人(2022a)研究了重复数据删除对几个数据集的模型性能的影响,发现重复数据删除减少了记忆训练数据的释放,可以更好地估计泛化误差,并在不影响性能的情况下改善训练时间和成本。这些见解强调了构建高质量训练语料的重要性和挑战。正如第 2 节所讨论的,彭博社的核心业务是策划和提供数据集的访问,我们用它来构建高质量的数据集 FINPILE 来训练 BloombergGPT,从而获得一流的金融性能。
评估。语言模型处理的任务已经大大增加,需要一个与传统特定任务系统非常不同的评估过程。目前有两种评估语言模型的范式:第一种是通过自动评估在许多不同的场景中评估一个模型,第二种是通过整合到用户工作流程中进行外在和特定任务的评估。
虽然第二种策略对于评估模型在产品中的部署是必要的,但以第一种策略的规模来运行这些人工评估是不可行的,因此在引入新模型时,遵循第一种策略是标准的。在我们的案例中,我们结合了多个现有基准的通用评价,这些基准有不同的目标。Srivastava 等人(2022)的目标是通过向整个研究界征集任务来实现最大的覆盖率,而 HELM(Liang 等人,2022)建议在各种“场景”中进行评估,这些场景通过特定的数据集来体现。早期的语言模型论文开发了他们自己的评估模式。虽然这些基准允许模型之间进行并排比较,但要确保所有的实验参数(提示、解码策略、少样本例子等)都是相同的,这是一个挑战。出于这个原因,我们在评估中区分了报告的和验证的数字(第 5 节)。
除了通用的评估,我们还需要有针对性的领域评估。之前的特定领域模型如 Galactica 选择了一组模型可能表现良好的任务。在他们的案例中,这些是各种科学任务。然而,金融 NLP 领域没有标准的基准。虽然最近关于 FLUE 的工作旨在提供这样一个基准,但它对相关任务的覆盖面有限,对少样本学习没有建议的评估策略,而且一些注释的质量很低。为了提供外部可比较的结果,我们为 FLUE 制定了一个少样本策略,但也决定用公司内部的基准来增加公开可用的评估任务。
模型大小。就收集数据和训练模型的计算成本和人力而言,大型语言模型的训练仍然很昂贵。确定最佳的训练数据量以及模型的形状和大小,以实现对再资源的最佳利用,变得非常重要。
Kaplan 等人(2020)首先研究了语言模型性能对结构、参数大小、计算能力和数据集大小的依赖性。他们报告说,模型参数的数量、数据集大小和计算量按照幂律平稳地提高了自回归语言建模目标的性能。Hernandez 等人(2021)对不同分布的数据传输的类似调查发现,这也遵循幂律。除了研究对损失的影响,Rae 等人(2021) 通过训练广泛的模型规模,分析了规模对不良特性的影响,如偏差和毒性。
Levine 等人(2020)比较了模型架构,研究了使用自我注意的模型的扩展性,并得出了深度与宽度分配的准则。Tay 等人(2021)报告说,模型形状(深度宽度比)影响了下游任务的表现,即使它对预训练目标的影响很小。Tay 等人(2022a)进一步研究了不同模型架构的缩放效果,并表明架构的选择在缩放时是相关的,香草变压器架构的缩放效果最好。
对这项工作特别重要的是 Hoffmann 等人(2022)的研究,他们研究了在固定的计算预算下,模型的大小和训练代币的数量对模型性能的影响。他们认为,现有的大型语言模型是训练不足的,模型的大小和训练代币的数量应该是同等规模的。他们通过 Chinchilla 证明了这一假设,这个模型比大多数最大的 LLMs 要小得多,但性能更高。这些发现为拥有强大性能的小型模型 “Chinchilla最优” 的训练打开了大门,而且推理的效率比大型模型高得多。这些发现促使我们考虑使用一个标准的架构建立一个接近 Chinchilla 最优的模型。
标记化。标记化和词汇选择在模型的表现中起着至关重要的作用,因为它们可以帮助模型学习有意义的表征,并对未见过的词进行归纳。字节对编码(BPE)通过反复合并训练集中最频繁的序列对来学习一个贪婪的自下而上的词汇,直到达到预定的词汇量。Radford 等人(2018)通过限制基础词汇为所有可能的字节,而不是所有 Unicode 字符,来适应 BPE。Wordpiece 标记化也通过反复合并训练数据可能性最大的序列对来学习贪婪的自下而上的词汇,这与 Sennrich 等人的方法略有不同。
与 BPE 和 Wordpiece 相反,Unigram 标记器通过首先初始化一个大的词汇,并反复丢弃那些增加损失(例如,训练数据的对数可能性)最少的词汇项目来学习一个自上而下的词汇。根据结构,Unigram 模型可以以几种不同的方式对输入文本进行标记。也就是说,Unigram 模型保存了概率,允许在推理时进行更智能的标记化。
最后 SentencePiece 调整了上述方案,以处理没有空间分隔的语言。Beltagy 等人(2019)构建了一个专门针对科学文本的词汇,并观察到他们的特定领域训练的词汇与在一般领域文本上训练的非特定领域 BERT 词汇只有 42% 的重合。同样地,Lewis 等人(2020)的研究表明,专门的生物医学词汇能够持续改善序列标记任务的性能。Lieber 等人(2021年)构建了一个更大的词汇表以确保标记效率,作者声称这导致了训练时间的减少和更好的语义表示。这些发现表明,选择一个最能反映该训练领域的标记器和配套词汇的重要性。由于这些原因,我们决定训练我们自己的 unigram 标记器,而不是依赖现有的公共标记器。
位置嵌入。基于变换器的模型依靠位置嵌入来编码文本中的词的位置和位置信息。对序列位置的编码以及这种选择对模型性能的影响已经得到了广泛的研究。其中包括正弦嵌入,旋转位置嵌入,添加相对位置偏差,以及添加线性偏差到注意力头。Press 等人(2022)的策略的一个副作用是,人们可以在较短的序列上进行训练,而不会在较长的序列上有性能损失。这有两个好处:第一,模型学会了对较长序列的概括(推断);第二,模型可以在较短的序列上训练,减少训练时间。
8. 伦理、局限性和影响
伴随着大型语言模型的快速发展和采用,人们对这些模型的伦理、用途和局限性进行了严格的讨论。为了更完整地处理这些主题,我们引导读者参考 Bommasani 等人(2021);Bender 等人(2021);Birhane 等人(2022);Weidinger 等人(2021,2022)。我们讨论的是与 BloombergGPT 的发展直接相关的问题。
8.1 合乎道德的使用
金融是一个敏感的技术领域,确保准确、真实的信息对我们的产品、我们的客户以及公司在市场上的声誉至关重要。另一方面,我们的客户也急于采用最先进的技术来支持他们的工作流程。为了向金融界提供自然语言应用,我们开发了一个严格的风险和测试评估过程。这个过程包括仔细的注释指南 Tseng 等人(2020),由中央风险和合规组织进行多层次的启动前审查,并由产品负责人(如新闻室)酌情审查,以及启动后监测。此外,我们根据所有适用的法规进行 NLP 和 AI 系统的研究、开发和部署。
同样的,毒性和偏见也是我们作为一个公司,对我们生产的任何内容,不管是来自人类还是机器的内容,都要特别小心的领域。由于在我们的模型中对毒性和偏见的测量取决于其应用领域,量化产生有害语言的可能性仍然是一个开放的问题。我们特别感兴趣的是研究 FINPILE,它更干净,包含更少的明显的偏见或有毒语言的例子(如新闻稿),减少了该模型产生不适当内容的倾向性。随着我们着手开发基于该技术的产品,我们将应用现有的测试程序以及风险和合规控制,以确保安全使用。
8.2 开放性
社区中正在进行一场涉及到 LLMs 应该如何发布的辩论,如果有的话。虽然不公开的模型不能被社区充分评估,但发布模型可能导致邪恶的目的。特别是像 BroOMBERG GPT 这样的模型,它是在大量的新闻稿、新闻报道和文件中训练出来的,发布模型有很高的风险,会被模仿而滥用。
我们已经看到了许多不同的策略来减轻与发布 LLM 相关的风险。一种策略是自由和公开地分享训练有素的模型 Scao 等人(2022),并依靠许可证来规定模型应该和不应该如何使用。另一种策略是要求个人申请获取训练好的模型参数。一个更具限制性的方法是提供对模型的 API 访问,但不能访问基础模型参数或关于模型训练的数据的详细信息。最后,有些人没有提供对模型的访问权。每个决定都反映了各种因素的组合,包括模型的使用、潜在的危害和商业决策。
彭博社的核心业务主张之一是围绕提供对几十年来收集的数据的访问。众所周知,LLM 很容易受到数据泄漏的攻击,而且有可能在给定的模型权重下提取大量的文本片段。此外,即使给研究人员选择性的访问权也不能保证模型不会被泄露。如果没有强大的隐私保证,我们必须担心提供对模型权重的访问就意味着提供对 FINPILE 的访问。出于这个原因,我们谨慎行事,跟随其他 LLM 开发者的做法,不公布我们的模型。
然而,我们在训练和评估 BloombergGPT 方面的见解和经验有助于发展对这些模型的理解。特别是,我们的经验可能对那些建立他们自己的特定领域模型的人有用。在开发 BloombergGPT 的过程中,我们发现 OPT 编年史、BLOOM 团队的经验以及 GPT-3、PaLM、Chinchilla、Galactica 和 Gopher 等非开放模型的工作都是我们工作的重要助力。
9.总结
我们提出了BloombergGPT,一个用于金融 NLP 的最佳 LLM。
我们的模型为正在进行的关于训练特定领域模型的有效方法的对话做出了贡献。我们的训练策略是将特定领域的数据和通用数据混合在一起,从而使模型在两个领域的性能达到平衡。通常,我们的工作提供了另一个关于选择 Chinchilla 最佳尺寸模型的数据点。最后,我们希望我们的模型训练日志能够为那些训练自己的 LLM 的人提供一个指导。
我们有几个有趣的方向要追求。首先,任务微调已经在 LLMs 中产生了显著的改进,我们计划考虑在金融领域的模型调整中存在哪些独特的机会。第二,通过对 FINPILE 中的数据进行训练,我们选择的数据可能表现出较少的毒性和偏见的语言。这对最终模型的影响尚不清楚,我们计划对此进行测试。第三,我们试图了解我们的标记化策略如何改变所产生的模型。这些是我们希望通过 BloombergGPT 追求的几个新的研究方向。
我们在一般的 LLM 基准上取得了强有力的结果,并在财务任务上超过了可比的模型。我们将其按照影响的递减顺序归结为:1.精心策划的内部数据集,2.我们对标记器的独特选择,3.最新的架构。我们将继续用 BloombergGPT 开发金融应用,以进一步探索这些建模选择的好处。
【转载自】重磅精译全文(三万字)|BloombergGPT:金融业的大型语言模型;