浅析DDD
什么是DDD
软件开发不是一蹴而就的事情,我们不可能在不了解产品(或行业领域)的前提下进行软件开发,在开发前,通常需要进行大量的业务知识梳理,而后到达软件设计的层面,最后才是开发。而在业务知识梳理的过程中,我们必然会形成某个领域知识,根据领域知识来一步步驱动软件设计,就是领域驱动设计的基本概念。
听起来这和传统意义的软件开发没啥区别,只是换了点新鲜的名词而已,其实不然。
软件开发 VS DDD
一般软件设计或者说软件开发分两种:瀑布式,敏捷式。
前者一般是项目经理经过大量的业务分析后,会基于现有需求整理出一个基本模型,再将结果传递给开发人员,这就是开发人员的需求文档,他们只需要照此开发便是。这种模式下,是很难频繁的从用户那里得到反馈,因此在前期分析时就已经默认了这个业务模型是正确的,那么结果可想而之,数月甚至数年后交付的时候,必然和客户的预期差距较大。
后者在此基础上进行了改进,它也需要大量的分析,范围会设计到更精细的业务模块,它是小步迭代,周期性交付,那么获取客户的反馈也就比较频繁和及时。可敏捷也不能够将业务中的方方面面都考虑到,并且敏捷是拥抱变化的,大量的需求或者业务模型变更必将带来不小的维护成本,同时,对人(Developer)的要求也必然会更高。
DDD则不同:它像是更小粒度的迭代设计,它的最小单元是领域模型(Domain Model),所谓领域模型就是能够精确反映领域中某一知识元素的载体,这种知识的获取需要通过与领域专家(Domain Expert)进行频繁的沟通才能将专业知识转化为领域模型。领域模型无关技术,具有高度的业务抽象性,它能够精确的描述领域中的知识体系;同时它也是独立的,我们还需要学会如何让它具有表达性,让模型彼此之间建立关系,形成完整的领域架构。通常我们可以用象形图或一种通用的语言(Ubiquitous Language)去描述它们之间的关系。在此之上,我们就可以进行领域中的代码设计(Domain Code Design)。如果将软件设计比做是造一座房子,那么领域代码设计就好比是贴壁纸。前者已经将房子的蓝图框架规划好,而后者只是一个小部分的设计:如果墙纸贴错了,我们可以重来,可如果房子结构设计错了,那可就悲剧了。
建立领域知识(Build Domain Model)
说了这么多领域模型的概念,到底什么是领域模型呢?以飞机航行为例子:
现要为航空公司开发一款能够为飞机提供导航,保证无路线冲突监控软件。那我们应该从哪里开始下手呢?根据DDD的思路,我们第一步是建立领域知识:作为平时管理和维护机场飞行秩序的工作人员来说,他们自然就是这个领域的专家,我们第一个目标就是与他们沟通,也许我们并不能从中获取所有想要的知识,但至少可以筛选出主要的内容和元素。你可能会听到诸如起飞,着陆,飞行冲突,延误等领域名词,让们从一个简单的例子开始(就算是错误的也没关系):
- 起点->飞机->终点
这个模型很直接,但有点过于简单,因为我们无法看出飞机在空中做了什么,也无法得知飞机怎么从起点到的终点,刚才我们似乎提到无路线冲突,那么如此似乎会好些:
- 飞机->路线->起点/终点
既然点构成线,那何不:
- 飞机->路线->points(含起点,终点)
这个过程,是我们不断建立领域知识的过程,其中的重点就是寻找领域专家频繁沟通,从中提炼必要领域元素。
尽管看起来还是很简单,但我们已经开始一步步的在建立领域对象和领域模型了。
通用语言(Ubiquitous Language)
上面的例子的确看起来简单,但过程并非容易:我们(开发人员)和领域专家在沟通的过程中是存在天然屏障的:我们满脑子都是类,方法,设计模式,算法,继承,封装,多态,如何面向对象等等;这些领域专家是不懂的,他们只知道飞机故障,经纬度,航班路线等专业术语。
所以,在建立领域知识的时候,我们(开发人员和领域专家)必须要交换知识,知识的范围范围涉及领域模型的各个元素,如果一方对模型的描述令对方感到困惑,那么应该立刻换一种描述方式,直到双方都能够接受并且理解为止。在这一过程中,就需要建立一种通用语言,作为开发人员和领域专家的沟通桥梁。
可如何形成这种通用语言呢?其实答案并不唯一,确切的说也没有什么标准答案。
a)UML
利用UML可以清晰的表现类,并且展示它们之间的关系。但是一旦聚合关系复杂,UML叶子节点将会变的十分庞大,可能就没有那么直观易懂了。最重要的是,它无法精确的描述类的行为。为了弥补这种缺陷,可以为具体的行为部分补充必要说明(可以是标签或者文档),但这往往又很耗时,而且更新维护起来十分不便。
b)伪代码
极限编程是推荐这么做的,这个办法对程序猿来说固然好,可立刻就要将现有模型映射到代码层面,这对人的要求也是不低,并不容易实现。
模型驱动设计(Domain Driven Design)
模型关系图(Model-Driven Design)
领域驱动设计中的模型关系图如下:

层结构(Layered Architecture)

- User Interface
负责向用户展现信息,并且会解析用户行为,即常说的展现层。
- Application Layer
应用层没有任何的业务逻辑代码,它很简单,它主要为程序提供任务处理。
- Domain Layer
这一层包含有关领域的信息,是业务的核心,领域模型的状态都直接或间接(持久化至数据库)存储在这一层。
- Infrastructure Layer
为其他层提供底层依赖操作。
层结构的划分是很有必要的,只有清晰的结构,那么最终的领域设计才宜用,比如用户要预定航班,向Application Layer的service发起请求,而后Domain Layler从Infrastructure Layer获取领域对象,校验通过后会更新用户状态,最后再次通过Infratructure Layer持久化到数据库中。
实体(Entity) & 值对象(Value Object)
实体与面向对象中的概念类似,在这里再次提出是因为它是领域模型的基本元素。在领域模型中,实体应该具有唯一的标识符,从设计的一开始就应该考虑实体,决定是否建立一个实体也是十分重要的。
值对象和我们说的编程中数值类型的变量是不同的,它仅仅是没有唯一标识符的实体,比如有两个收获地址的信息完全一样,那它就是值对象,并不是实体。值对象在领域模型中是可以被共享的,他们应该是“不可变的”(只读的),当有其他地方需要用到值对象时,可以将它的副本作为参数传递。
服务(Services)
当我们在分析某一领域时,一直在尝试如何将信息转化为领域模型,但并非所有的点我们都能用Model来涵盖。对象应当有属性,状态和行为,但有时领域中有一些行为是无法映射到具体的对象中的,我们也不能强行将其放入在某一个模型对象中,而将其单独作为一个方法又没有地方,此时就需要服务.
服务是无状态的,对象是有状态的。所谓状态,就是对象的基本属性:高矮胖瘦,年轻漂亮。服务本身也是对象,但它却没有属性(只有行为),因此说是无状态的。
PS:这与我们常说的服务器的状态是两个概念,无状态的服务器是指,对服务器来说每次接收到的HTTP请求都像是客户端第一次发送的一样;而有状态的服务器就会存储客户端的状态,常见的就是Cookie&Session
服务存在的目的就是为领域提供简单的方法。为了提供大量便捷的方法,自然要关联许多领域模型,所以说,行为(Action)天生就应该存在于服务中。
服务具有以下特点:
a)服务中体现的行为一定是不属于任何实体和值对象的,但它属于领域模型的范围内
b)服务的行为一定设计其他多个对象
c)服务的操作是无状态的
PS:不要随意放置服务,如果该行为是属于应用层的,那就应该放在那;如果它为领域模型服务,那它就应该存储在领域层中,要避免业务的服务直接操作数据库,最好通过DAO。
模块(Moudles)
对于一个复杂的应用来说,领域模型将会变的越来越大,以至于很难去描述和理解,更别提模型之间的关系了。模块的出现,就是为了组织统一的模型概念来达到减少复杂性的目的的。而另一个原因则是模块可以提高代码质量和可维护性,比如我们常说的高内聚,低耦合就是要提倡将相关的类内聚在一起实现模块化。
模块应当有对外的统一接口供其他模块调用,比如有三个对象在模块a中,那么模块b不应该直接操作这三个对象,而是操作暴露的接口。模块的命名也很有讲究,最好能够深层次反映领域模型。
聚合(Aggregates)
聚合被看作是多个模型单元间的组合,它定义了模型的关系和边界。每个聚合都有一个根,根是一个实体,并且是唯一可被外访问的。正是如此,聚合可以保证多个模型单元的不变性,因为其他模型都参考聚合的根。所以要想改变其他对象,只能通过聚合的根去操作。根如果没有了,那么聚合中的其他对象也将不存在。
一个简单的例子如下:
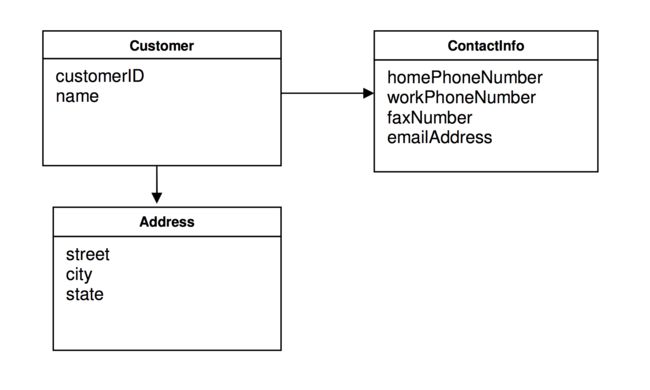
customer是该聚合的根,其他的都是内部对象,如果外部需要用户地址,拷贝一份传递出去即可。显而易见,用户如果不存在,其他信息均无意义。
工厂(Factories)
在大型系统中,实体和聚合通常是很复杂的,这就导致了很难去通过构造器来创建对象。工厂就决解了这个问题,它把创建对象的细节封装起来,巧妙的实现了依赖反转。当然对聚合也适用(当建立了聚合根时,其他对象可以自动创建)。工厂最早被大家熟知可能还是在设计模式中,的确,在这里提到的工厂也是这个概念。
但是不要盲目的去应用工厂,以下场景不需要工厂:
a)构造器很简单
b)构造对象时不依赖于其他对象的创建
c)用策略模式就可以解决
仓库(Repository)
仓库封装了获取对象的逻辑,领域对象无须和底层数据库交互,它只需要从仓库中获取对象即可。仓库可以存储对象的引用,当一个对象被创建后,它可能会被存储到仓库中,那么下次就可以从仓库取。如果用户请求的数据没在仓库中,则会从数据库里取,这就减少了底层交互的次数。当然,仓库获取对象也是有策略的,如下:

PS:仓库看起来有些像Infrastructure Layer的东西,但其实不然,仓库更像是本地缓存,需要时才会访问数据库
结束语
CQRS本身也是一种架构模式,但更多的是它被应用在DDD中。因为DDD中有工厂和仓库来管理领域模型,前者主要用于创建,而后者则用于存储。这就表明在DDD中是默认将读写分离的,DDD似乎就天生和CQRS有着无缝的链接。
CQRS往往要求数据库进行读写分离,具体来说,所有的更新操作均无返回值(void),而读操作才返回对应的值。在实现CQRS时,又和事件源(Event Source)相结合,以下是一个简单的交互过程:
客户端发起一个请求,服务端将其映射为一个命令,该命令会从仓库中读取一个相关的聚合,对该聚合进行操作,将会生成一个事件源,将该事件发送出去,接收方收到消息后(并不是立刻)将会更新领域对象,完成一次更新操作。
在此基础上,还有称之为六边形的架构风格,它将DDD的领域模型包裹在内,外围含有多种适配器来适配各种通信方式,总体来说,我觉得无论是DDD,CQRS还是六边形,都是一种架构的设计思路,没有绝对的优势,同时也有各自的复杂度,并不容易理解,但有时在软件设计时,不妨多学习一下其中的小细节和思路,必然能够有所收获。
至于能否应用?如何应用?,笔者只能说不能生搬硬套,需要有一定的实践经验才能去尝试,一般情况下,结合项目特点,能适当的灵活采用其中的设计思路即可。
作者:Pursue
链接:https://www.jianshu.com/p/b6ec06d6b594
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。