CH08_搬迁特性
搬迁函数(Move Function)
曾用名:搬迁函数(Move Method)
class Account{
get overdraftCharge(){...}
...
}
class AccountType{
get overdraftCharge(){...}
...
}
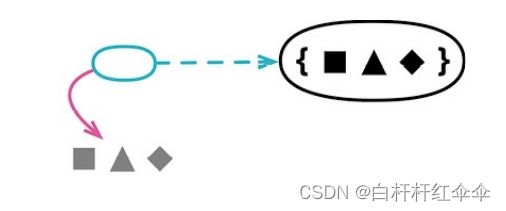
动机
模块化是优秀软件设计的核心所在,好的模块化能够在修改程序时只需理解程序的一小部分。为了设计出高度模块化的程序,需要保证互相关联的软件要素都能集中到一块,并确保块与块之间的联系易于查找、直观易懂。
任何函数都需要具备上下文环境才能存活。这个上下文可以是全局的,但它更多时候是由某种形式的模块所提供的。对一个面向对象的程序而言,类作为最主要的模块化手段,其本身就能充当函数的上下文;通过嵌套的方式,外层函数也能为内层函数提供一个上下文。不同的语言提供的模块化机制各不相同,但这些模块的共同点是,它们都能为函数提供一个赖以存活的上下文环境。
搬移函数最直接的一个动因是,它频繁引用其他上下文中的元素,而对自身上下文中的元素却关心甚少。此时,让它去与那些更亲密的元素相会,通常能取得更好的封装效果,因为系统别处就可以减少对当前模块的依赖。
做法
-
检查函数在当前上下文里引用的所有程序元素(包括变量和函数),考虑是否需要将它们一并搬移
如果发现有些被调用的函数也需要搬移,我通常会先搬移它们。这样可以保证移动一组函数时,总是从依赖最少的那个函数入手。
如果该函数拥有一些子函数,并且它是这些子函数的唯一调用者,那么你可以先将子函数内联进来,一并搬移到新家后再重新提炼出子函数。
-
检查待搬移函数是否具备多态性
在面向对象的语言里,还需要考虑该函数是否覆写了超类的函数,或者为子类所覆写。
-
将函数复制一份到目标上下文中。调整函数,使它能适应新家。
如果函数里用到了源上下文(source context)中的元素,就得将这些元素一并传递过去,要么通过函数参数,要么是将当前上下文的引用传递到新的上下文那边去。
搬移函数通常意味着,还得给它起个新名字,使它更符合新的上下文。 -
执行静态检查
-
设法从源上下文中正确引用目标函数
-
修改源函数,使之成为一个纯委托函数
-
测试
-
考虑对源函数使用内联函数(115)
也可以不做内联,让源函数一直做委托调用。但如果调用方直接调用目标函数也不费太多周折,那么最好还是把中间人移除掉。
搬移字段
class Customer {
get plan() {return this._plan;}
get discountRate() {return this._discountRate;}
// ...
}
class Customer {
get plan() {return this._plan;}
get discountRate() {return this.plan.discountRate;}
// ...
}
动机
编程活动中需要编写许多代码,为系统实现特定的行为,但往往数据结构才是一个健壮程序的根基。一个适应于问题域的良好数据结构,可以让行为代码变得简单明了,而一个糟糕的数据结构则将招致许多无用代码,这些代码更多是在差劲的数据结构中间纠缠不清,而非为系统实现有用的行为。
好的数据结构至关重要——不过这也与编程活动的许多方面一样,它们都很难一次做对。如果具备一些领域驱动设计(domain-driven design)方面的经验和知识,往往有助于更好地设计数据结构。
如果发现数据结构已经不适应于需求,就应该马上修缮它。如果容许瑕疵存在并进一步累积,使代码愈来愈复杂。
搬移字段的操作通常是在其他更大的改动背景下发生的。实施字段搬移后,可能会发现字段的诸多使用者应该通过目标对象来访问它,而不应该再通过源对象来访问。诸如此类的清理,在此后的重构中一并完成。
做法
- 确保源字段已经得到可良好封装
- 测试
- 在目标对象上创建一个字段(及对应的访问函数)
- 执行静态检查
- 确保源对象里能够正常引用目标对象
- 调整源对象的访问函数,令其使用目标对象的字段
- 测试
- 移除源对象上的字段
- 测试
搬移语句到函数(Move Statements into Function)
反向重构:搬移语句到调用者(217)
result.push(`title:
${person.photo.title}`);
result.concat(photoData(person.photo));
function photoData(aPhoto) {
return [
`location:
${aPhoto.location}`,
`date:
${aPhoto.date.toDateString()}`,
];
}
result.concat(photoData(person.photo));
function photoData(aPhoto) {
return [
`title:
${aPhoto.title}`,
`location:
${aPhoto.location}`,
`date:
${aPhoto.date.toDateString()}`,
];
}
动机
要维护代码库的健康发展,需要遵守几条黄金守则,其中最重要的一条当属“消除重复”。
如果某些语句与一个函数放在一起更像一个整体,并且更有助于理解,建议将语句搬移到函数里去。如果它们与函数不像一个整体,但仍应与函数一起执行,可以用提炼函数(106)将语句和函数一并提炼出去。
做法
- 如果重复的代码段近离调用目标函数的地方还有些距离,则先用移动语句(223)将这些语句挪动到紧邻目标函数的位置。
- 如果目标函数仅被唯一一个源函数调用,那么只需将源函数中的重复代码段剪切并粘贴到目标函数中即可,然后运行测试。本做法的后续步骤至此可以忽略。
- 如果函数不止一个调用点,那么先选择其中一个调用点应用提炼函数(106),将待搬移的语句与目标函数一起提炼成一个新函数。给新函数取个临时的名字,只要易于搜索即可。
- 调整函数的其他调用点,令它们调用新提炼的函数。每次调整之后运行测试。
- 完成所有引用点的替换后,应用内联函数(115)将目标函数内联到新函数里,并移除原目标函数。
- 对新函数应用函数改名(124),将其改名为原目标函数的名字。
搬移语句到调用者(Move Statements to Callers)
反向重构:搬移语句到函数(213)
emitPhotoData(outStream, person.photo);
function emitPhotoData(outStream, photo) {
outStream.write(`title:
${photo.title}\n`);
outStream.write(`location:
${photo.location}\n`);
}
emitPhotoData(outStream, person.photo);
outStream.write(`location:
${person.photo.location}\n`);
function emitPhotoData(outStream, photo) {
outStream.write(`title:
${photo.title}\n`);
}
动机
作为程序员,我们的职责就是设计出结构一致、抽象合宜的程序,而程序抽象能力的源泉正是来自函数。与其他抽象机制的设计一样,我们并非总能平衡好抽象的边界。随着系统能力发生演进(通常只要是有用的系统,功能都会演进),原先设定的抽象边界总会悄无声息地发生偏移。
函数边界发生偏移的一个征兆是,以往在多个地方共用的行为,如今需要在某些调用点面前表现出不同的行为。
这个重构手法比较适合处理边界仅有些许偏移的场景,但有时调用点和调用者之间的边界已经相去甚远,此时便只能重新进行设计了。
做法
-
最简单的情况下,原函数非常简单,其调用者也只有寥寥一两个,此时只需把要搬移的代码从函数里剪切出来并粘贴回调用端去即可,必要的时候做些调整。运行测试。如果测试通过,那就大功告成,本手法可以到此为止。
-
若调用点不止一两个,则需要先用提炼函数(106)将你不想搬移的代码提炼成一个新函数,函数名可以临时起一个,只要后续容易搜索即可。
如果原函数是一个超类方法,并且有子类进行了覆写,那么还需要对所有子类的覆写方法进行同样的提炼操作,保证继承体系上每个类都有一份与超类相同的提炼函数。接着将子类的提炼函数删除,让它们引用超类提炼出来的函数。
-
对原函数应用内联函数(115)。
-
对提炼出来的函数应用改变函数声明(124),令其与原函数使用同一个名字。
以函数调用取代内联代码(Replace Inline Code with Function Call)
let appliesToMass = false;
for(const s of states) {
if (s === "MA") appliesToMass = true;
}
appliesToMass = states.includes("MA");
动机
一个命名良好的函数,本身就能极好地解释代码的用途,使读者不必了解其细节。
函数同样有助于消除重复,因为同一段代码不需要编写两次,每次调用一下函数即可。
如果一些内联代码,它们做的事情仅仅是已有函数的重复,通常会以一个函数调用取代内联代码。
当内联代码与函数之间只是外表相似但其实并无本质联系时,这种情况下,当改变了函数实现时,并不期望对应内联代码的行为发生改变。判断内联代码与函数之间是否真正重复,从函数名往往可以看出端倪。
做法
- 将内联代码替代为对一个既有函数的调用。
- 测试
移动语句(Slide Statements)
曾用名:合并重复的代码片段(Consolidate Duplicate Conditional Fragments)

const pricingPlan = retrievePricingPlan();
const order = retreiveOrder();
let charge;
const chargePerUnit = pricingPlan.unit;
const pricingPlan = retrievePricingPlan();
const chargePerUnit = pricingPlan.unit;
const order = retreiveOrder();
let charge;
动机
让存在关联的东西一起出现,可以使代码更容易理解。如果有几行代码取用了同一个数据结构,那么最好是让它们在一起出现,而不是夹杂在取用其他数据结构的代码中间。
通常来说,把相关代码搜集到一处,往往是另一项重构(通常是在提炼函数(106))开始之前的准备工作。相比于仅仅把几行相关的代码移动到一起,将它们提炼到独立的函数往往能起到更好的抽象效果。
做法
- 确定待移动的代码片段应该被搬往何处。仔细检查待移动片段与目的地之间的语句,看看搬移后是否会影响这些代码正常工作。如果会,则放弃这项重构。
- 剪切源代码片段,粘贴到上一步选定的位置上。
- 测试。
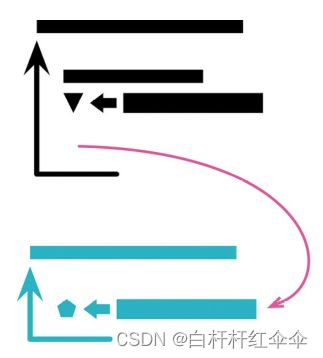
拆分循环(Split Loop)
let averageAge = 0;
let totalSalary = 0;
for (const p of people) {
averageAge += p.age;
totalSalary += p.salary;
}
averageAge = averageAge / people.length;
let totalSalary = 0;
for (const p of people) {
totalSalary += p.salary;
}
let averageAge = 0;
for (const p of people) {
averageAge += p.age;
}
averageAge = averageAge / people.length;
动机
一些身兼多职的循环,它们一次做了两三件事情,不为别的,就因为这样可以只循环一次。但如果在一次循环中做了两件不同的事,那么每当需要修改循环时,都得同时理解这两件事情。如果能够将循环拆分,让一个循环只做一件事情,那就能确保每次修改时只需要理7解要修改的那块代码的行为就可以了。
拆分循环还能让每个循环更容易使用。如果一个循环只计算一个值,那么它直接返回该值即可;但如果循环做了太多件事,那就只得返回结构型数据或者通过局部变量传值了。
做法
- 复制一遍循环代码。
- 识别并移除循环中的重复代码,使每个循环只做一件事。
- 测试。
完成循环拆分后,考虑对得到的每个循环应用提炼函数(106)。
以管道取代循环(Replace Loop with Pipeline )

const names = [];
for (const i of input) {
if (i.job === "programmer")
names.push(i.name);
}
const names = input
.filter(i => i.job === "programmer")
.map(i => i.name)
动机
越来越多的编程语言都提供了更好的语言结构来处理迭代过程,这种结构就叫作集合管道(collection pipeline)。集合管道[mf-cp]是这样一种技术,它允许使用一组运算来描述集合的迭代过程,其中每种运算接收的入参和返回值都是一个集合。
最常见的则非map和filter莫属:map运算是指用一个函数作用于输入集合的每一个元素上,将集合变换成另外一个集合的过程;filter运算是指用一个函数从输入集合中筛选出符合条件的元素子集的过程。
做法
-
创建一个新变量,用以存放参与循环过程的集合。
-
从循环顶部开始,将循环里的每一块行为依次搬移出来,在上一步创建的集合变量上用一种管道运算替代之。每次修改后运行测试。
-
搬移完循环里的全部行为后,将循环整个删除。
如果循环内部通过累加变量来保存结果,那么移除循环后,将管道运算的最终结果赋值给该累加变量。
移除死代码(Remove Dead Code)

if(false){
doSomethingThatUsedtoMatter();
}
动机
大多数现代的编译器还会自动将无用的代码移除。但当尝试阅读代码、理解软件的运作原理时,无用代码确实会带来很多额外的思维负担。
一旦代码不再被使用,就该立马删除它。
做法
- 如果死代码可以从外部直接引用,比如它是一个独立的函数时,先查找一下还有无调用点。
- 将死代码移除。
- 测试。