Improved Baselines with Momentum Contrastive Learning 论文学习
1. 解决了什么问题?
最近的非监督表征学习关注在对比学习上。在检测和分割任务上,MoCo 的非监督预训练表现优于在 ImageNet 监督预训练的表现;在线性分类表现上,SimCLR 进一步缩小了非监督和监督预训练的差距。
2. 提出了什么方法?
使用一个 MLP 映射 head 和数据增强方法,改进了 MoCo。这两个方法与现有的 MoCo 和 SimCLR 框架是正交的,能提升 MoCo 在图像分类和目标检测上迁移学习的效果。此外,MoCo 框架无需较大的 batch size,就能处理大量的负样本。SimCLR 要用到 4 k ∼ 8 k 4k\sim 8k 4k∼8k的 batches,只能用 TPU 训练,而 MoCoV2 基线模型只用 8 8 8张显卡,效果好于 SimCLR。
对比学习
该框架从数据中学习相似/不相似的表征,这些数据划分为相似/不相似的样本对。该问题可表述为一个字典查询问题。一个有效的对比损失函数 InfoNCE:
L q , k + , { k − } = − log exp ( q ⋅ k + / τ ) exp ( q ⋅ k + / τ ) + ∑ k − exp ( q ⋅ k − / τ ) \mathcal{L}_{q,k^+,\lbrace k^-\rbrace}=-\log \frac{\exp\left(q\cdot k^+/\tau\right)}{\exp\left(q\cdot k^+ / \tau\right)+\sum_{k^-}\exp \left(q\cdot k^-/\tau\right)} Lq,k+,{k−}=−logexp(q⋅k+/τ)+∑k−exp(q⋅k−/τ)exp(q⋅k+/τ)
q q q 是 query 表征, k + k^+ k+是正样本 key 的表征, { k − } \lbrace k^-\rbrace {k−}是负样本 keys 的表征。 τ \tau τ是调节超参数。在实例判别 pretext 任务,如果 query 和 key 出自同一张图片的增强版本,则为正样本对,不然就是负样本对。该等式可用多种机制最小化,差异在于如何维护 keys。在端到端的机制中,负样本 keys 来自于相同的 batch,通过反向传播完成端到端的更新。SimCLR 基于这个机制,需要一个较大的 batch 提供大量的负样本。而在 MoCo 中,使用了一个队列来维护负样本 keys,每个 batch 中只编码了 queries 和正样本 keys。使用了一个动量编码器来保证当前 keys 表征和之前 keys 表征的连续性。MoCo 将 batch size 从负样本个数中解耦了出来。
改进设计
SimCLR 从三个方面改进了端到端的实例判别任务:
- Batch size 很大, 4 k ∼ 8 k 4k\sim 8k 4k∼8k,提供充裕的负样本。
- 用 MLP head 替换输出全连接层。
- 更强的数据增强方法。
在 MoCo 框架中,已经有了大量的负样本。MLP head 和数据增强与 MoCo 是正交的。
设定
在 128 128 128万张图片的 ImageNet 上训练非监督学习。作者遵循了评测的标准协议:
- ImageNet 线性分类:冻结特征,只训练一个监督线性分类器,报告 1-crop ( 224 × 224 224\times 224 224×224) top-1 验证准确率。
- 迁移到 VOC 目标检测:在 VOC07+12 trainval 集上微调 Faster R-CNN,在 VOC 07 test 集上评测,使用 COCO 指标。
MLP Head
将全连接层替换为一个两层的 MLP head,隐藏层维度是 2048 2048 2048,后带 ReLU。这只会在非监督训练阶段使用,线性分类或迁移学习阶段不使用该 MLP head。下图中,默认 τ = 0.07 \tau=0.07 τ=0.07,使用 MLP head 预训练能将准确率从 60.6 % 60.6\% 60.6%提升到 62.9 % 62.9\% 62.9%。采用最优的 τ = 0.2 \tau=0.2 τ=0.2,准确率升至 66.2 % 66.2\% 66.2%。

数据增强

增加了 blur 增强。从上表可看出,只使用 blur 增强,不使用 MLP 能提升 MoCo 基线 2.8 % 2.8\% 2.8%至 63.4 % 63.4\% 63.4%,检测准确率甚至高于只使用 MLP 的时候。一起使用 MLP 和 blur 增强时,分类准确率提升为 67.3 % 67.3\% 67.3%。
Comparison with SimCLR
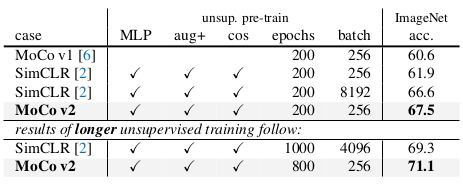
在相同 epochs 和 batch size 时,MoCo V2 的分类准确率领先 SimCLR 5.6 % 5.6\% 5.6%,当 epochs 个数是 800 800 800时,MoCo V2 的分类准确率是 71.1 % 71.1\% 71.1%。
计算成本

End-to-end 是 SimCLR 的显卡使用情况。在 8 8 8卡 GPU 上都没法跑 4 k 4k 4k的 batch size。即使 batch size 是 256 256 256,end-to-end 也非常消耗显存和时间,它需要对 q q q和 k k k编码器计算反向传播,而 MoCo 只用对 q q q编码器计算。