数据库编程
数据库编程
- 一.嵌入式SQL
-
- 1.嵌入式SQL的处理过程
- 2.嵌入式SQL语句与主语言之间的通信
- 3.不用游标的SQL语句
- 4.使用游标的SQL语句
- 5.动态SQL
- 二.过程化SQL
-
- 1.过程化SQL的块结构
- 2.变量和常量的定义
- 3.流程控制
- 三.存储过程和函数
-
- 1.存储过程
- 2.函数
- 四.ODBC编程
-
- 1.ODBC概述
- 2.ODBC工作原理概述
- 3.ODBC API基础
- 4.ODBC的工作流程
一.嵌入式SQL
1.为什么引入嵌入式SQL:
- SQL语言是非过程性语言
- 事务处理应用需要高级语言
1.嵌入式SQL的处理过程
(1)主语言
嵌入式SQL是将SQL语句嵌入程序设计语言中,被嵌入的程序设计语言,如C、C++、Java,称为宿主语言,简称主语言。
(2)处理过程
预编译方法
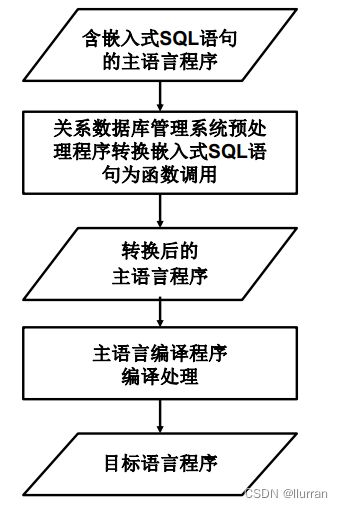
(3)为了区分SQL语句与主语言语句,所有SQL语句必须加前缀EXEC SQL。
主语言为C语言时,语句格式:
EXEC SQL
;
2.嵌入式SQL语句与主语言之间的通信
(1)将SQL嵌入到高级语言中混合编程,程序中会含有两种不同计算模型的语句:
①SQL语句
- 描述性的面向集合的语句
- 负责操纵数据库
②高级语言语句
- 过程性的面向记录的语句
- 负责控制逻辑流程
(2)数据库工作单元与源程序工作单元之间的通信
①向主语言传递SQL语句的执行状态信息,使主语言能够据此控制程序流程,主要用SQL通信区实现。
②主语言向SQL语句提供参数,主要用主变量实现。
③将SQL语句查询数据库的结果交主语言处理,主要用主变量和游标实现。
- 游标:解决集合性操作语言与过程性操作语言的不匹配。
(3)SQL通信区(SQLCA)
①SQLCA是一个数据结构。
②SQLCA的用途
a.SQL语句执行后,系统反馈给应用程序信息:
- 描述系统当前工作状态;
- 描述运行环境。
b.这些信息将送到SQL通信区中。
c.应用程序从SQL通信区中取出这些状态信息,据此决定接下来执行的语句。
③SQLCA使用方法
a.SQLCA相当于指向通信区的默认对象或句柄。
b.定义SQLCA:
- 用EXEC SQL INCLUDE SQLCODE定义。
- 调用为SQLCA.SQLCODE
c.使用SQLCA(是应用程序到数据库的通信链接的句柄)
- SQLCA中有一个存放每次执行SQL语句后返回代码的变量SQLCODE
- 如果SQLCODE等于预定义的常量SUCCESS,则表示SQL语句成功,否则表示出错。
- 应用程序每执行完一条SQL语句之后都应该测试一下SQLCODE的值,以了解该SQL语句执行情况并做相应处理。
(4)主变量Host Variable
①嵌入式SQL语句中可以使用主语言的程序变量来输入或输出数据。
②在SQL语句中使用的主语言程序变量简称为主变量。
③主变量的类型
a.输入主变量
- 由应用程序对其赋值,SQL语句引用。
b.输出主变量
- 由SQL语句对其赋值或设置状态信息,返回给应用程序。
④指示变量Indicator Variable
a.是一个整型变量,用来“指示”所指主变量的值或条件。
b.一个主变量可以附带一个指示变量
- 一般紧跟在主变量后定义
c.指示变量的用途
- 指示输入主变量是否为空值
- 检测输出变量是否为空值,值是否被截断
⑤使用主变量和指示变量的方法
a.说明主变量和指示变量
b.使用主变量
- 说明之后的主变量可以在SQL语句中任何一个能够使用表达式的地方出现。
- 为了与数据库对象名(表名、视图名、列名等)区别,SQL语句中的主变量前要加冒号(:)作为标志。
c.使用指示变量
- 指示变量前也必须加冒号标志
- 必须紧跟在所指主变量之后

⑥在SQL语言之外(主语言语句中)使用主变量和指示变量的方法
a.可以直接引用,不必加冒号
(5)游标
①为什么要使用游标
- SQL语言与主语言具有不同数据处理方式
- SQL语言是面向集合的,一条SQL语句原则上可以产生或处理多条记录
- 主语言是面向记录的,一组主变量一次只能存放一条记录
- 仅使用主变量并不能完全满足SQL语句向应用程序输出数据的要求
- 嵌入式SQL引入了游标的概念,用来协调这两种不同的处理方式
②游标
- 游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果。
- 每个游标区都有一个名字
- 用户可以用SQL语句逐一从游标中获取记录,并赋给主变量,交由主语言进一步处理。
(6)建立和关闭数据库连接
EXEC SQL CONNECT TO target[AS connection-name] [USER user-name];
①target是要连接的数据库服务器
- 常见的服务器标识串,如
< dbname >@< hostname > : < port >- 包含服务器标识的SQL串常量
- DEFAULT
②connect-name是可选的连接名,连接名必须是一个有效的标识符
- 在整个程序内有一个连接时可以不指定连接名
- 程序运行过程中可以修改当前连接
EXEC SQL SET CONNECTION connection-name | DEFAULT
③关闭数据库连接
EXEC SQL DISCONNECT [connection];
(7)程序实例
依次检查某个系的学生记录,交互式更新某些学生年龄。
EXEC SQL BEGIN DECLARE SECTION; //主变量说明开始
char Deptname[20];
char Hsno[9];
char Hsname[20];
char Hssex[2];
int HSage;
int NEWAGE;
EXEC SQL END DECLARE SECTION; //主变量说明结束
long SQLCODE;
EXEC SQL INCLUDE SQLCODE; //定义SQL通信区
int main(void) //C程序主程序开始
{
int count=0;
char yn; //变量yn代表yes或no
printf("Please choose the department name(CA/MA/IS):");
scanf("%s",deptname); //为主变量deptname赋值
EXEC SQL CONNECT TO TEST@localhost:54321 USER "SYSTEM"/"MANAGER"; //来凝结数据库TEST
EXEC SQL DECLARE SX CURSOR FOR //定义游标SX
SELECT Sno,Sname,Ssex,Sage //SX对应的语句
FROM Student
WHERE SDept=:deptname;
EXEC SQL OPEN SX; //打开游标SX,指向查询结果的第一行。游标SX相当于一个指针,指向已读取数据的SQL通信区SQLCA的第一行
for(;;) //用循环结构逐条处理结果集中的记录
{
EXEC SQL FETCH SX INTO :HSno,:Hsname,:HSsex,:HSage; //推进游标,将当前数据放入主变量
if(SQLCA.SQLCODE!=0) //SQLCA.SQLCODE!=0,表示操作不成功
break;
if(count++==0) //如果是第一行的话,先打出行头
printf("\n%-10s %-20s %-10s %-10s\n","Sno","Sname","Ssex","Sage");
printf("\n%-10s %-20s %-10s %-10d\n",HSno,HSname,HSsex,HSage); //打印查询结果
printf("UPDATE AGE(y/n)?"); //询问用户是否要更新该学生的年龄
do{scanf("%c",&yn);}
while(yn!='N' && yn!='n' && yn!='Y' && yn!='y');
if(yn=='y' || yn=='Y') //如果选择更新操作
{
printf("INPUT NEW AGE");
scanf("%d",&NEWAGE); //用户输入新年龄到主变量中
EXEC SQL UPDATE Student
SET Sage=:NEWAGE
WHERE CURRENT OF SX; //对当前游标指向的学生年龄进行更新
}
}
EXEC SQL CLOSE SX; //关闭游标SX,不再和查询结果对应
EXEC SQL COMMIT WORK; //提交更新
EXEC SQL DISCONNECT TEST; //断开数据库连接
}
3.不用游标的SQL语句
(1)不用游标的SQL语句的种类
- 说明性语句
- 数据定义语句
- 数据控制语句
- 查询结果为单记录的SELECT语句
- 非CURRENT形式的增删改语句
(2)查询结果为单记录的SELECT语句
①这类语句不需要使用游标,只需用INTO子句指定存放查询结果的主变量。
②例子:
根据学生号码查询学生信息:
EXEC SQL SELECT Sno,Sname,Ssex,Sage,Sdept
INTO :Hsno,:Hname,:Hsex,:Hage,:Hdept
FROM Student
WHERE Sno=:givensno;
//设把要查询的学生学号已赋值给了主变量givensno
③INTO子句、WHERE子句和HAVING短语的条件表达式中均可以使用主变量。
④查询返回的记录中,可能某些列为空值null。
⑤如果查询结果实际上并不是单条记录,而是多条记录,则程序出错,关系数据库管理系统会在SQLCA中返回错误信息。
例子:查询某个学生选修某门课程的成绩。假设已经把将要查询的学生的学号赋给了主变量givensno,将课程号赋给了主变量givencno。
EXEC SQL SELECT Sno,Cno,Grade
INTO :Hsno,:Hcno,:Hgrade:Gradeid //指示变量Gradeid。查询返回的记录中,某些列可能为空值NULL,则设定Gradeid<0
FROM SC
WHERE Sno=:givensno AND Cno=:givencno;
//如果Gradeid<0,不论Hgrade为何值,均认为该学生成绩值为空值
(3)非CURRENT形式的增删改语句
①在UPDATE的SET子句和WHERE子句中可以使用主变量,SET子句还可以使用指示变量。
②例子
修改某个学生选修1号课程的成绩。
EXEC SQL UPDATE SC
SET Grade=:newgrade //设修改的成绩已赋给主变量:newgrade
WHERE Sno=:givensno; //设学号已赋给主变量:givensno
③例子
某个学生新选修了某门课程,将有关记录插入SC表中。假设插入的学号已赋给主变量stdno,课程号已赋给主变量couno。
gradeid=-1; //gradeid为指示变量,赋为负值
EXEC SQL INSERT
INTO SC(Sno,Cno,Grade)
VALUES(:stdno,:couno,:gr:gradeid);
//stdno,couno,gr为主变量
//由于该学生刚选修课程,成绩应为空,所有要把指示变量赋值为负值
4.使用游标的SQL语句
(1)必须使用游标的SQL语句
- 查询结果为多条记录的SELECT语句
- CURRENT形式的UPDATE语句
- CURRENT形式的DELETE语句
(2)查询结果为多条记录的SELECT语句
①使用游标的步骤
- 说明游标
- 打开游标
- 推进游标指针并取当前记录
- 关闭游标
②说明(定义)游标
a.使用DECALRE语句
b.语句格式
- EXEC SQL DECLARE <游标名> CURSOR FOR
; c.功能
- 是一条说明性语句,这时关系数据库管理系统并不执行SELECT语句
③打开游标
a.使用OPEN语句
b.语句格式
- EXEC SQL OPEN <游标名>;
c.功能
- 打开游标实际上是执行相应的SELECT语句,把查询结果取到缓冲区中
- 这时游标处于活动状态,指针指向查询结果集中的第一条记录
④推进游标指针并取当前记录
a.使用FETCH语句
b.语句格式
- EXEC SQL FETCH <游标名>
INTO <主变量> [<指示变量>]
[,<主变量>[<指示变量>]]…;c.功能
- 指定方向推动游标指针,同时将缓冲区中的当前记录取出来送至主变量供主语言进一步处理。
⑤关闭游标
a.使用CLOSE语句
b.语句格式
- EXEC SQL CLOSE <游标名>;
c.功能
- 关闭游标,释放结果集占用的缓冲区及其他资源。
d.说明
- 游标被关闭后,就不再和原来的查询结果集相联系
- 被关闭的游标可以再次被打开,与新的查询结果相联系
(3)CURRENT形式的UPDATE语句和DELETE语句
①CURRENT形式的UPDATE语句和DELETE语句的用途
a.普通的UPDATE语句和DELETE语句
- 面向集合的操作
- 依次修改或删除所有满足条件的记录
b.只想修改或删除其中某个记录
- 用带游标的SELECT语句查出所有满足条件的记录
- 从中进一步找出要修改或删除的记录
- 用CURRENT形式的UPDATE语句和DELETE语句修改或删除之
- UPDATE语句和DELETE语句中要用子句
WHERE CURRENT OF <游标名>
表示修改或删除的是最近一次取出的记录,即游标指针指向的记录。
②注意
当游标定义中的SELECT语句带有UNION或ORDER BY子句时,该SELECT语句相当于定义了一个不可更新的视图。此时不能使用CURRENT形式的UPDATE语句和DELETE语句。
5.动态SQL
(1)静态嵌入式SQL
- 静态嵌入式SQL语句能够满足一般要求
- 无法满足要到执行时才能够要提交的SQL语句、查询的条件
(2)动态嵌入式SQL
- 允许在程序运行过程中临时“组装”SQL语句
- 支持动态组装SQL语句和动态参数两种形式
(3)使用SQL语句主变量
①SQL语句主变量
- 程序主变量包含的内容是SQL语句的内容,而不是原来保存数据的输入或输出变量
- SQL语句主变量在程序执行期间可以设定不同的SQL语句,然后立即执行
②例子
创建基本表TEST
EXEC SQL BEGIN DECLARE SECTION;
const char *stmt="CREATE TABLE test(a int);"; //SQL语句主变量,内容是创建表的SQL语句
EXEC SQL END DECLARE SECTION;
·······
EXEC SQL EXECUTE IMMEDIATE :stmt; //执行动态SQL语句
(4)动态参数
①动态参数
- SQL语句中的可变元素
- 使用参数符号(?)表示该位置的数据在运行时的设定
②和主变量的区别
- 动态参数的输入不是编译时完成绑定
- 而是通过PREPARE语句准备主变量和执行语句EXECUTE绑定数据或主变量来完成
③使用动态参数的步骤
a.声明SQL语句主变量
b.准备SQL语句(PREPARE)
- EXEC SQL PREPARE <语句名>
FROM;
④执行准备好的语句
EXEC SQL EXECUTE <语句名>
[INTO <主变量表>]
[USING <主变量或常量>];
⑤例子
向TEST中插入元组。
EXEC SQL BEGIN DECLARE SECTION;
const char *stmt="INSERT INTO test VALUES(?)"; //声明SQL主变量内容是INSERT语句
EXEC SQL END DECLARE SECTION;
···
EXEC SQL PREPARE mystmt FROM :stmt; //准备语句
···
EXEC SQL EXECUTE mystmt USING 100; //执行语句,设定INSERT语句插入值100
EXEC SQL EXECUTE mystmt USING 200; //执行语句,设定INSER语句插入值200
二.过程化SQL
1.过程化SQL的块结构
(1)过程化SQL
- 是基本SQL的扩展(基本SQL是非过程化的)
- 增加了过程化语句功能
- 基本结构是块
每个块可以互相嵌套
每个块完成一个逻辑操作

(2)过程化SQL块的基本结构
①定义部分
DECLARE变量、常量、游标、异常等
- 定义的变量、常量等只能在该基本块中使用。
- 当基本块执行结束时,定义就不再存在。
②执行部分
BEGIN
SQL语句、过程化SQL的流程控制语句
EXCEPTION
异常处理部分
END;
2.变量和常量的定义
(1)变量定义
- 变量名 数据类型 [[NOT NULL]:=初值表达式] 或
- 变量名 数据类型 [[NOT NULL] 初值表达式]
(2)常量定义
- 常量名 数据类型 CONSTANT:=常量表达式
- 常量必须要给一个值,并且该值在存在期间或常量的作用域内不能改变。如果试图修改它,过程化SQL将返回一个异常。
(3)赋值语句
- 变量名称:=表达式
3.流程控制
(1)条件控制语句
IF-THEN、IF-THEN-ELSE和嵌套的IF语句
IF condition THEN
Sequence_of_statements;
END IF;
IF condition THEN
Sequence_of_statements1;
ELSE
Sequence_of_statements2;
END IF;
在THEN和ELSE子句中还可以再包含IF语句,即IF语句可以嵌套。
(2)循环控制语句
LOOP、WHILE-LOOP和FOR-LOOP
1.简单的循环语句LOOP
Loop
Sequence_of_statements;
END LOOP;
多数数据库服务器的过程化SQL都提供EXIT、BREAK或LEAVE等循环结束语句,保证LOOP语句块能够结束。
2.WHILE-LOOP
WHILE condition LOOP
Sequence_of_statements;
END LOOP;
每次执行循环体语句之前,首先对条件进行求值。
如果条件为真,则执行循环体内的语句序列。
如果条件为假,则跳过循环并把控制传递给下一个语句。
3.FOR-LOOP
FOR count IN [REVERSE] bound1 ... bound2 LOOP
Sequence_of_statements;
END LOOP;
(3)错误处理
- 如果过程化SQL再执行时出现异常,则应该让程序在产生异常的语句处停下来,根据异常的类型去执行异常处理语句。
- SQL标准对数据库服务器提供什么样的异常处理做出了建议,要求过程化SQL管理器提供完善的异常处理机制。
三.存储过程和函数
1.存储过程
(1)命名块
编译后保存在数据库中,可以被反复调用,运行速度较快,过程和函数是命名块。
(2)匿名块
每次执行时都要进行编译,它不能被存储到数据库中,也不能在其他过程化SQL块中调用。
(3)存储过程的定义
由过程化SQL语句书写的过程,经编译和优化后存储在数据库服务器中,使用时只要调用即可。
(4)存储过程的优点
- 运行效率高
- 降低了客户机和服务器之间的通信量
- 方便实施企业规则
(5)存储过程的用户接口
①创建存储过程
CREATE OR REPLACE PROCEDURE 过程名([参数1,参数2,…]) AS <过程化SQL块>;
- 过程名:数据库服务器合法的对象标识。
- 参数列表:用名字来标识调用时给出的参数值,必须指定值的数据类型。参数也可以定义输入参数、输出参数或输入/输出参数,默认为输入参数。
- 过程体:是一个<过程化SQL块>,包括声明部分和可执行语句部分。
例子
利用存储过程来实现下面的应用:从账户1转指定数额的款项到账户2中。
CREATE OR REPLACE PROCEDURE
TRANSFER(inAccount INT,outAccount INT,amount FLOAT) //定义存储过程TRANSFER,其参数为转入账户、转出账户、转账额度
AS DECLARE //定义变量
totalDepositOut Float;
totalDepositIn Float;
inAccountnum INT; //假设账户关系表为Account(Accountnum,Total)
BEGIN //检查转出账户的余额
SELECT Total INTO totalDepositOut FROM Account
WHERE Accountnum=outAccount;
IF totalDepositOut IS NULL THEN //如果转出账户不存在或账户中没有存款
ROLLBACK; //回滚事务
RETURN;
END IF;
IF totalDepositOut<amount THEN //如果账户存款不足
ROLLBACK; //回滚事务
RETURN;
END IF;
SELECT Accountnum INTO inAccountnum FROM Account
WHERE Accountnum=inAccount;
IF inAccount IS NULL THEN //如果转入账户不存在
ROLLBACK;
RETURN;
END IF;
UPDATE Account SET total=total-amount
WHERE Accountnum=outAccount; //修改转出账户余额,减去转出额
UPDATE Account SET total=total+amount
WHERE Accountnum=inAccount; //修改转入账户余额,增加转入额
COMMIT; //提交转账事务
END; //结束过程
②执行存储过程
CALL/PERFORM PROCEDURE 过程名([参数1,参数2,…]);
- 使用CALL或者PERFORM等方式激活存储过程的执行。
- 在过程化SQL中,数据库服务器支持在过程体中调用其他存储过程。
例子:
从账户01003815868转10000元到01003813828账户中:
CALL PROCEDURE
TRANSFER(01003813828,01003815868,10000);
③修改存储过程
ALTER PROCEDURE 过程名1 RENAME TO 过程名2;
④删除存储过程
DROP PROCEDURE 过程名();
2.函数
(1)函数和存储过程的异同
- 同:都是持久性存储模块
- 异:函数必须指定返回的类型
(2)函数的定义语句格式
CREATE OR REPLACE FUNCTION 函数名 ([参数1,参数2,…]) RETURNS <类型> AS <过程化SQL块>;
(3)函数的执行语句
CALL/SELECT 函数名([参数1,参数2,…]);
(4)修改函数
①重命名
ALTER FUNCTION 函数名1 RENAME TO 函数名2;
②重新编译
ALTER FUNCTION 函数名 COMPILE;
四.ODBC编程
ODBC(开放数据库连接)优点:
- 移植性好。
- 能同时访问不同的数据库。
- 共享多个数据资源。
- 主要是存在不同的数据库管理系统。
1.ODBC概述
(1)ODBC产生的原因
- 由于不同的数据库管理系统的存在,在某个关系数据库管理系统下编写的应用程序就不能在另一个关系数据库管理系统下运行。
- 许多应用程序需要共享多个部门的数据资源,访问不同的关系数据库管理系统。
(2)ODBC
- 是微软公司开放服务体系中有关数据库的一个组成部分
- 提供了一组访问数据库的API
(3)ODBC约束力
- 规范应用开发
- 规范关系数据库管理系统应用接口
2.ODBC工作原理概述
(1)ODBC应用系统的体系结构
- 用户应用程序
- ODBC驱动程序管理器
- 数据库驱动程序
- 数据源
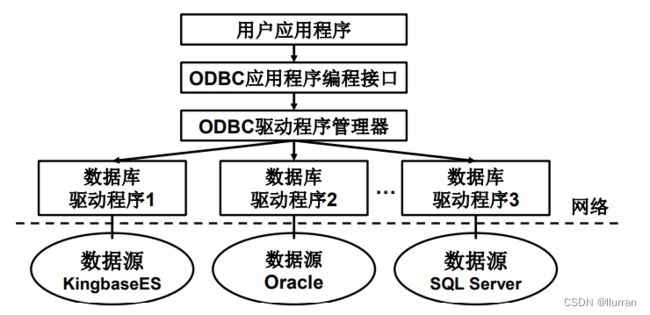
(2)ODBC应用程序包括的内容
- 请求连接数据库
- 向数据源发送SQL语句
- 为SQL语句执行结果分配存储空间,定义所读取的数据格式
- 获取数据库操作结果或处理错误
- 进行数据处理并向用户提交处理结果
- 请求事务的提交和回滚操作
- 断开与数据源的连接
(3)ODBC驱动程序管理器:用来管理各种驱动程序
- 包含在ODBC32.DLL中
- 管理应用程序和驱动程序之间的通信
- 建立、配置或删除数据源,并查看系统当前所安装的数据库ODBC驱动程序
①主要功能
- 装载ODBC驱动程序
- 选择和连接正确的驱动程序
- 管理数据源
- 检查ODBC调用参数的合法性
- 记录ODBC函数的调用等
(4)数据库驱动程序
①ODBC通过驱动程序来提供应用系统与数据库平台的独立性。
②ODBC应用程序不能直接存取数据库
- 其各种操作请求由驱动程序管理器提交给某个关系数据库管理系统的ODBC驱动程序。
- 通过调用驱动程序所支持的函数来存取数据库。
- 数据库的操作结果也通过驱动程序返回给应用程序。
- 如果应用程序要操纵不同的数据库,就要动态地链接到不同的驱动程序上。
③ODBC驱动程序类型
a.单束
- 数据源和应用程序在同一台机器上。
- 驱动程序直接完成对数据文件的I/O操作。
- 驱动程序相当于数据管理器。
b.多束
- 支持客户机-服务器、客户机-应用服务器/数据库服务器等网络环境下的数据访问。
- 由驱动程序完成数据库访问请求的提交和结果集接收。
- 应用程序使用驱动程序提供的结果集管理接口操纵执行后的结果数据。
(5)数据源管理
①数据源
是最终用户需要访问的数据,包含了数据库位置和数据库类型等信息,是一种数据连接的抽象。
②数据源对最终用户是透明的
- ODBC给每个被访问的数据源指定唯一的数据源名(DSN),并映射到所有必要的、用来存取数据的低层软件。
- 在连接中,用数据源名来代表用户名、服务器名、所连接的数据库名等。
- 最终用户无须知道数据库管理系统或其他数据管理软件、网络以及有关ODBC驱动程序的细节。
③例子
假设某个学校在SQL Server和KingbaseES上创建了两个数据库:学校人事数据库和教学科研数据库。
- 学校的信息系统要从这两个数据库中存取数据。
- 为了方便地与两个数据库连接,为学校人事数据库创建一个数据源名PERSON,为教学科研数据库创建一个名为EDU的数据源。
- 当要访问每一个数据库时,只要与PERSON和EDU连接即可,不需要记住使用的驱动程序、服务器名称、数据库名。
3.ODBC API基础
(1)ODBC应用程序编程接口的一致性
a.API一致性
- 包含核心级、扩展1级、扩展2级
b.语法一致性
- 包含最低限度SQL语法级、核心SQL语法级、扩展SQL语法级
(2)函数概述
①ODBC 3.0标准提供了76个函数接口
- 分配和释放环境句柄、连接句柄、语句句柄
- 连接函数(SQLDriverconnect等)
- 与信息相关的函数(SQLGetinfo、SQLGetFuction等)
- 事务处理函数(如SQLEndTran)
- 执行相关函数(SQLExecdirect、SQLExecute等)
- 编目函数,ODBC 3.0提供了11个编目函数,如SQLTables、SQLColumn等。应用程序可以通过对编目函数的调用来获取数据字典的信息,如权限、表结构等。
(3)句柄及其属性
①句柄是32位整数值,代表一个指针。
②ODBC 3.0中句柄分类
- 环境句柄
- 连接句柄
- 语句句柄
- 描述符句柄
③应用程序句柄之间的关系
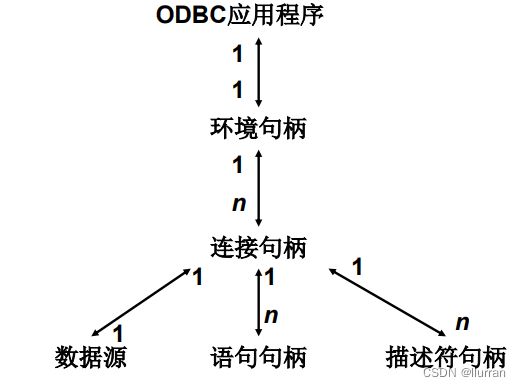
- 每个ODBC应用程序需要建立一个ODBC环境,分配一个环境句柄,存取数据的全局性背景,如环境状态、当前环境状态诊断、当前在环境上分配的连接句柄等。
- 一个环境句柄可以建立多个连接句柄(1:n),每一个连接句柄实现与一个数据源之间的连接(1:1)。
- 在一个连接中可以建立多个语句句柄,它不只是一个SQL语句,还包括SQL语句产生的结果集以及相关的信息等。
- 在ODBC 3.0中又提出了描述符句柄的概念,它是描述SQL语句的参数、结果集列的元数据集合。
(4)数据类型
①ODBC数据类型
- SQL数据类型:用于数据源
- C数据类型:用于应用程序的C代码
②应用程序可以通过SQLGetTypeInfo来获取不同的驱动程序对于数据类型的支持情况。
③SQL数据类型和C数据类型之间的转换规则

4.ODBC的工作流程
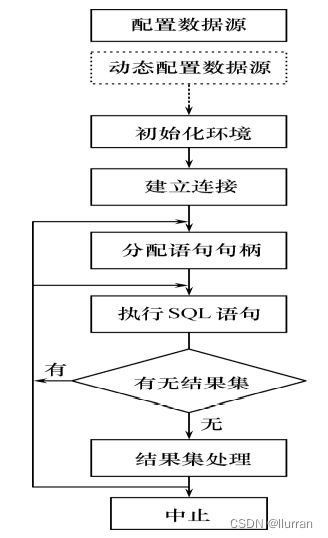
- 配置数据源
- 初始化环境
- 建立连接
- 分配语句句柄
- 执行SQL语句
- 结果集处理
- 中止处理
(1)例子
将KingbaseES数据库中Student表的数据备份到SQL Server数据库中。
- 该应用涉及两个不同的关系数据库管理系统中的数据源。
- 使用ODBC来开发应用程序,只要改变应用程序中连接函数(SQLConnect)的参数,就可以连接不同关系数据库管理系统的驱动程序,连接两个数据源。
- 在应用程序运行前,已经在KingbaseES和SQL Server中分别建立了Student关系表。
- 应用程序要执行的操作:
Ⅰ.在KingbaseES上执行SELECT * FROM Studdent;
Ⅱ.把获取的结果集,通过多次执行INSERT语句插入到SQL Server的Student表中。
①配置数据源
配置数据源有两种方法
- 运行数据源管理工具来进行配置
- 使用Driver Manager提供的ConfigDsn函数来增加、修改或删除数据源。
②初始化环境
- 没有和具体的驱动程序相关联,由Driver Manager来进行控制,并配置环境属性。
- 应用程序通过调用连接函数和某个数据源进行连接后,Driver Manager才调用所连的驱动程序中的SQLAllocHandle,来真正分配环境句柄的数据结构。
③建立连接
- 应用程序调用SQLAllocHandle分配连接句柄,通过SQLConnect、SQLDriverConnect或SQLBrowseConnect与数据源连接。
- SQLConnect连接函数的输入参数为:
配置好的数据源名称
用户ID
口令- 例子中KingbaseES ODBC为数据源名字,SYSTEM为用户名,MANAGER为用户密码。
④分配语句句柄
- 处理任何SQL语句之前,应用程序还需要首先分配一个语句句柄。
- 语句句柄含有具体的SQL语句以及输出的结果集等信息。
- 应用程序还可以通过SQLtStmtAttr来设置语句属性(也可以使用默认值)。
⑤执行SQL语句
a.应用程序处理SQL语句的两种方式:
- 预处理SQLPrepare、SQLExecute适用于语句的多次执行。
- 直接执行SQLExecdirect
b.如果SQL语句含有参数,应用程序为每个参数调用SQLBindParameter,并把它们绑定至应用程序变量。
c.应用程序可以直接通过改变应用程序缓冲区的内容从而在程序中动态改变SQL语句的具体执行。
d.应用程序根据语句类型进行的处理:
- 有结果集的语句(select或是编目函数),则进行结果集处理。
- 没有结果集的函数,可以直接利用本语句句柄继续执行新的语句或是获取行计数(本次执行所影响的行数)之后继续执行。
e.在插入数据时,采用了预编译的方式,首先通过SQLPrepare来预处理SQL语句,然后将每一列绑定到用户缓冲区。
⑥结果集处理
- 应用程序可以通过SQLNumResultCols来获取结果集中的列数。
- 通过SQL DescribeCol或是SQLColAttrbute函数来获取结果集每一列的名称、数据类型、精度和范围。
- ODBC中使用游标来处理结果集数据。
- ODBC中游标类型:
a.Forward-only游标,是ODBC的默认游标类型;
b.可滚动Scroll游标:静态、动态、码集驱动、混合型
结果集处理步骤:
- ODBC游标的打开方式不同于嵌入式SQL,不是显式声明而是系统自动产生一个游标,当结果集刚刚生成时,游标指向第一行数据之前。
- 应用程序通过SQLBindCol把查询结果绑定到应用程序缓冲区中,通过SQLFetch或是SQLFetchScroll来移动游标获取结果集中的每一行数据。
- 对于如图像这类特别的数据类型,当一个缓冲区不足以容纳所有的数据时,可以通过SQLGetdata分多次获取。
- 最后通过SQL Closecursor来关闭游标。
⑦中止处理
- 释放语句句柄
- 释放数据库连接
- 与数据库服务器断开
- 释放ODBC环境
#include