数据分析——练习笔记(一)
通过实战练习,学会用pandas做数据分析
案例数据来自科赛网https://www.kesci.com/apps/home/project/5b333f3c8566927866faa2d7
案例一 探索Chipotle快餐数据
1、导入库
import pandas as pd2、导入数据集
path1 = "../input/pandas_exercise/exercise_data/chipotle.tsv" # chipotle.tsv3、将数据集存入一共名为chipo的数据框中
chipo = pd.read_csv(path1)4、查看前10行内容
chipo.head(10)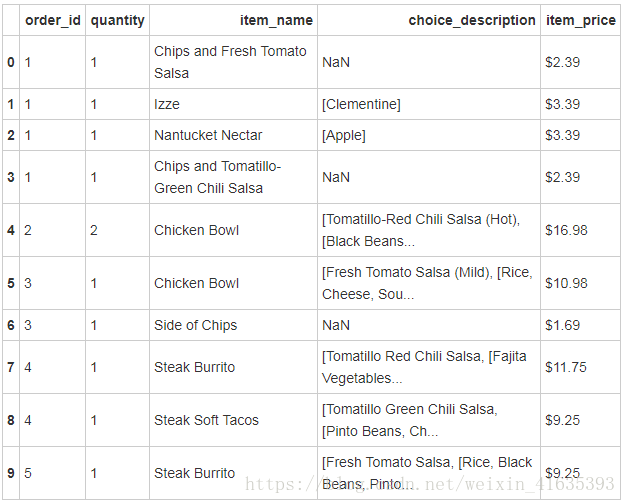
5、数据集中有多少个列
chipo.shape[1]df.shape #返回tuple (行,列)
6、打印出全部的列名称
chipo.columnsdf.columns #列名,返回index类型的列的集合
7、数据集的索引是怎样的
chipo.indexdf.index #索引名,返回index类型的索引的集合
8、被下单最多商品是什么
chipo[['item_name', 'quantity']].groupby(['item_name', as_index=False).agg({'quantity':sum})
c.sort_value(['quantity'], ascending=False, inplace=True)
c.head()groupby函数的as_index参数
首先看一下pandas官方给出的groupby函数,可以看到默认值为as_index=True
groupby()中的形参可用help(df.groupby)查看
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)下面部分是从https://stackoverflow.com/questions/41236370/what-is-as-index-in-groupby-in-pandas搬运
import pandas as pd
df = pd.DataFrame(data={'books':['bk1','bk1','bk1','bk2','bk2','bk3'], 'price': [12,12,12,15,15,17]})
print df
print
print df.groupby('books', as_index=True).sum()
print
print df.groupby('books', as_index=False).sum()
Output:注意两次print输出中‘book’和‘price’的位置
books price
0 bk1 12
1 bk1 12
2 bk1 12
3 bk2 15
4 bk2 15
5 bk3 17
price
books
bk1 36
bk2 30
bk3 17
books price
0 bk1 36
1 bk2 30
2 bk3 179、在item_name这一列中,一共有多少种商品被下单
chipo['item_name'].unique()s.unique() #Series去重
10、在choice_description中,下单次数最多的商品是什么?
chipo['choice_description'].value_counts().head()s.value_counts() #Series统计频率,并从大到小排序,DataFrame没有这个方法
11、一共有多少商品被下单?
chipo['quantity'].sum()12、将item_price转换为浮点数
13、在改数据集对应的时期内,收入(revenue)是多少
14、在该数据及对应的时期内,一共有多少订单?
15、每一单(order)对应的平均总价是多少
16、一共有多少种不同的商品被售出?