Elasticsearch10:Elasticsearch的高级特性
一、ES中的settings
ES中的settings可以设置索引库的一些配置信息,主要是针对分片数量和副本数量
其中分片数量只能在一开始创建索引库的时候指定,后期不能修改。
副本数量可以随时修改。
首先查看一下ES中目前已有的索引库的默认settings信息。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/emp/_settings?pretty'
{
"emp" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "emp",
"creation_date" : "1803648122805",
"number_of_replicas" : "1",
"uuid" : "kBpwz6kAQ2eS0uCISVcaew",
"version" : {
"created" : "7130499"
}
}
}
}
}
此时分片和副本数量默认都是1。
尝试手工指定分片和副本数量。
针对不存在的索引,在创建的时候可以同时指定分片(5)和副本(1)数量:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/test1/' -d'{"settings":{"number_of_shards":5,"number_of_replicas":1}}'
查看这个索引库的settings信息:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test1/_settings?pretty'
{
"test1" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "5",
"provided_name" : "test1",
"creation_date" : "1804844538706",
"number_of_replicas" : "1",
"uuid" : "WEUwvKVoRzWfna-KFntdqQ",
"version" : {
"created" : "7130499"
}
}
}
}
}
针对已存在的索引,只能通过settings指定副本信息。
将刚才创建的索引的副本数量修改为0。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/test1/_settings' -d'{"index":{"number_of_replicas":0}}'
查看这个索引库目前的settings信息:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test1/_settings?pretty'
{
"test1" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "5",
"provided_name" : "test1",
"creation_date" : "1804844538706",
"number_of_replicas" : "0",
"uuid" : "WEUwvKVoRzWfna-KFntdqQ",
"version" : {
"created" : "7130499"
}
}
}
}
}
二、ES中的mapping
mapping表示索引库中数据的字段类型信息,类似于MySQL中的表结构信息。
一般不需要手工指定mapping,因为ES会自动根据数据格式识别它的类型
如果你需要对某些字段添加特殊属性(例如:指定分词器),就必须手工指定字段的mapping。
下面先来看一下ES中的常用数据类型:
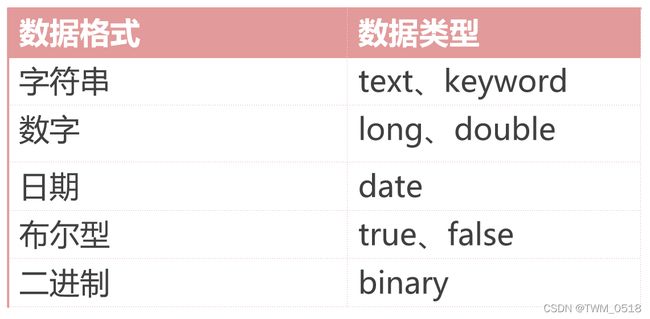
1、字符串:支持text和keyword类型
(1)text类型支持分词,支持模糊、精确查询,但是不支持聚合和排序操作,text类型不限制存储的内容长度,适合大字段存储。
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/text.html
(2)keyword类型不支持分词,会直接对数据建立索引,支持模糊、精确查询,支持聚合和排序操作。keyword类型最大支持存储内容长度为32766个UTF-8类型的字符,可以通过设置ignore_above参数指定某个字段最大支持的字符长度,超过给定长度后的数据将不被索引,此时就无法通过termQuery精确查询返回结果了。keyword类型适合存储手机号、姓名等不需要分词的数据。
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/keyword.html
2、数字:最常用的就是long和double了,整数使用long、小数使用double。当然也支持integer、short、byte、float这些数据类型。
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/number.html
3、日期:最常用的就是date类型了,date类型可以支持到毫秒,如果特殊情况下需要精确到纳秒需要使用date_nanos这个类型。
其中date日期类型可以自定义日期格式,通过format参数指定:
{“type”:“date”,“format”:“yyyy-MM-dd”}
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/date.html
4、布尔型:支持true或者false。
5、二进制:该字段存储编码为Base64字符串的二进制值。如果想要存储图片,可以存储图片地址,或者图片本身,存储图片本身的话就需要获取图片的二进制值进行存储了。
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/binary.html
ES中还支持一些其他数据类型,感兴趣的话可以到文档里面看一下:
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/mapping-types.html
下面查询一下目前已有的索引库score的mapping信息:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/score/_mapping?pretty'
{
"score" : {
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"score" : {
"type" : "long"
},
"subject" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
通过返回的mapping信息可以看到score这个索引库里面有3个字段,name、score和subject。
1:name是text类型,其中还通过fields属性指定了一个keyword类型,表示name字段会按照text类型和keyword类型存储2份。
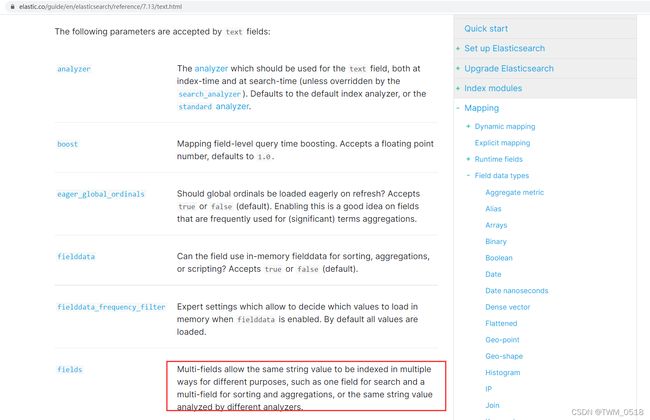
针对fields属性的解释官网里面有详细介绍,见下图:
大致意思是说,一个字段可以设置多种数据类型,这样ES会按照多种数据类型的特性对这个字段进行存储和建立索引。
“ignore_above” : 256,表示keyword类型最大支持的字符串长度是256。
ES默认会把字符串类型的数据同时指定text类型和keyword类型。
想要实现分词检索的时候需要使用text类型,在代码层面直接指定这个name字段就表示使用text类型。
想要实现精确查询的时候需要使用keyword类型,在代码层面指定name.keyword表示使用name的keyword类型。
其实前面我们在讲排序的时候也用到了这个keyword类型的特性,因为直接指定name字段会使用text类型,text类型不支持排序和聚合,所以使用的是name.keyword。
2:score是long类型,整数默认会被识别为long类型。
3:subject也是text类型,和name是一样的。
注意:ES 7.x版本之前字符串默认只会被识别为text类型,不会附加一个keyword类型。
下面我们首先操作一个不存在的索引库的mapping信息:
指定name为text类型,并且使用ik分词器。
age为integer类型。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/test2' -d'{"mappings":{"properties":{"name":{"type":"text","analyzer": "ik_max_word"},"age":{"type":"integer"}}}}'
查看这个索引库的mapping信息。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test2/_mapping?pretty'
{
"test2" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
在这个已存在的索引库中增加mapping信息。
注意:只能新增字段,不能修改已有字段的类型,否则会报错。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test2/_mapping' -d'{"properties":{"age":{"type":"long"}}}'
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"mapper [age] cannot be changed from type [integer] to [long]"}],"type":"illegal_argument_exception","reason":"mapper [age] cannot be changed from type [integer] to [long]"},"status":400}
可以假设一下,假设支持修改已有字段的类型,之前name是text类型,如果我修改为long类型,这样就会出现矛盾了,所以ES不支持修改已有字段的类型。
在已存在的索引库中增加一个flag字段,类型为boolean类型
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/test2/_mapping' -d'{"properties":{"flag":{"type":"boolean"}}}'
查看索引库的最新mapping信息。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test2/_mapping?pretty'
{
"test2" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"flag" : {
"type" : "boolean"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
三、ES的偏好查询(分片查询方式)
ES中的索引数据最终都是存储在分片里面的,分片有多个,并且分片还分为主分片和副本分片。
ES在查询索引库中的数据时,具体是到哪些分片里面查询数据呢?
在具体分析这个之前,我们先分析一下ES的分布式查询过程:

这个表示是一个3个节点的ES集群,集群内有一个索引库,索引库里面有P0和P1两个主分片,这两个主分片分别都有2个副本分片,R0和R1。
查询过程主要包含三个步骤:
1、客户端发送一个查询 请求到 Node 3 , Node 3 会创建一个空优先队列,主要为了存储结果数据。
2、Node 3 将查询请求转发到索引的主分片或副本分片中。每个分片在本地执行查询并将查询到的结果添加到本地的有序优先队列中。
具体这里面Node 3 将查询请求转发到索引的哪个分片中,可以是随机的,也可以由我们程序员来控制。
默认是randomize across shards:表示随机从分片中取数据。
3、每个分片返回各自优先队列中所有文档的 ID 和排序值给到 Node 3 ,Node 3合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
注意:当客户端的一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片,并将它们查询到的结果整合成全局排序后的结果集合,这个结果集合会返回给客户端。
这里面的Node3节点其实就是协调节点。
接下来我们来具体分析一下如何控制查询请求到分片之间的分发规则:
先创建一个具有5个分片,0个副本的索引库
分片太少不好验证效果。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/pre/' -d'{"settings":{"number_of_shards":5,"number_of_replicas":0}}'
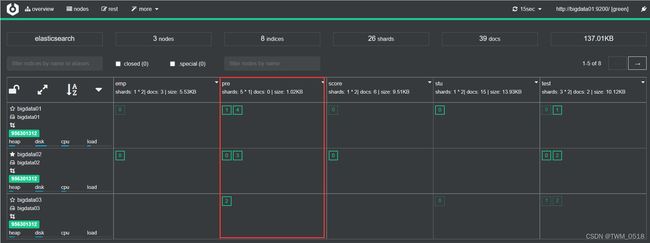
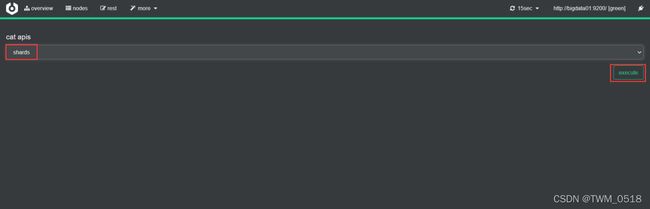
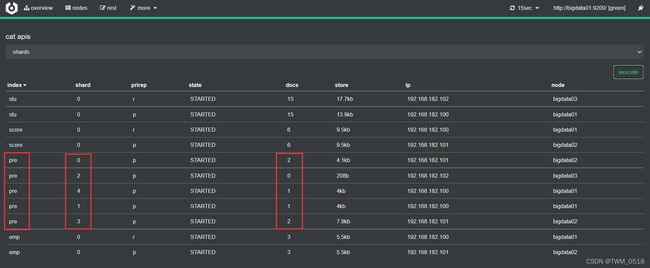
在索引库中初始化一批测试数据:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/1' -d'{"name":"tom","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/2' -d'{"name":"jack","age":29}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/3' -d'{"name":"jessica","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/4' -d'{"name":"dave","age":19}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/5' -d'{"name":"lilei","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/pre/_doc/6' -d'{"name":"lili","age":29}'
这些测试数据在索引库的分片中的分布情况是这样的:
在代码层面通过preference(…)来设置具体的分片查询方式:
//指定分片查询方式
searchRequest.preference();//默认随机
1、_local
_local:表示查询操作会优先在本地节点(协调节点)的分片中查询,没有的话再到其它节点中查询。
这种方式可以提高查询性能,假设一个索引库有5个分片,这5个分片都在Node3节点里面,客户端的查询请求正好也分配到了Node3节点上,这样在查询这5个分片的数据就都在Node3节点上进行查询了,每个分片返回结果数据的时候就不需要跨网络传输数据了,可以节省网络传输的时间。
但是这种方式也会有弊端,如果这个节点在某一时刻接收到的查询请求比较多的时候,会对当前节点造成比较大的压力,因为这些查询请求都会优先查询这个节点上的分片数据。
searchRequest.preference("_local");
此时是可以查到所有数据的。
数据总数:6
{"name":"jessica","age":18}
{"name":"lilei","age":18}
{"name":"dave","age":19}
{"name":"jack","age":29}
{"name":"lili","age":29}
{"name":"tom","age":18}
2、_only_local
_only_local:表示查询只会在本地节点的分片中查询。
searchRequest.preference("_only_local");
这种方式只会在查询请求所在的节点上进行查询,查询速度比较快,但是数据可能不完整,因为我们无法保证索引库的分片正好都在这一个节点上。
数据总数:2
{"name":"dave","age":19}
{"name":"tom","age":18}
注意:大家在自己本地试验的时候,结果和我的可能不一样,因为请求不一定会分到哪一个节点上面。
3、_only_nodes
_only_nodes:表示只在指定的节点中查询。
可以控制只在指定的节点中查询某一个索引库的分片信息。
但是注意:这里指定的节点列表里面,必须包含指定索引库的所有分片,如果从这些节点列表中获取到的索引库的分片个数不完整,程序会报错。
这种情况适用于在某种特殊情况下,集群中的个别节点压力比较大,短时间内又无法恢复,那么我们在查询的时候可以规避掉这些节点,只选择一些正常的节点进行查询。
前提是索引库的分片有副本,如果没有副本,只有一个主分片,就算主分片的节点压力比较大,那也只能查询这个节点了。
在这里面需要指定节点ID,节点ID应该如何获取呢?
通过ES中针对节点信息的RestAPI可以快速获取:
http://bigdata01:9200/_nodes?pretty
返回的信息有点多,建议在浏览器中访问。
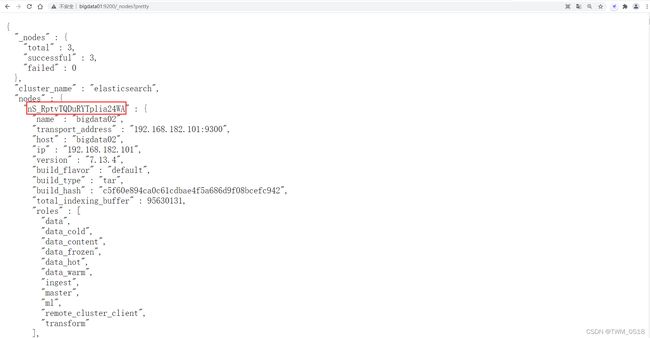
最终可以获取到三个节点的ID:
bigdata01: l7H4B3pdRm6ckBWd7ODS5Q
bigdata02: nS_RptvTQDuRYTplia24WA
bigdata03: KzjZauWGRt6hJRKTgZ7BcA
注意:这个节点ID是集群随机生成的一个字符串,所以每个人的集群节点ID都是不一样的。
目前这个索引库的分片分布在3个节点上

在这里可以指定一个或者多个节点ID,多个节点ID之间使用逗号分割即可
首先指定bigdata01节点的ID
searchRequest.preference("_only_nodes:KzjZauWGRt6hJRKTgZ7BcA");
注意:执行这个查询会报错,错误提示找不到pre索引库的2号分片的数据,2号分片是在bigdata03节点上
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"no data nodes with criteria [l7H4B3pdRm6ckBWd7ODS5Q] found for shard: [pre][2]"}],"type":"illegal_argument_exception","reason":"no data nodes with criteria [l7H4B3pdRm6ckBWd7ODS5Q] found for shard: [pre][2]"},"status":400}
再把bigdata03的节点ID添加到里面
searchRequest.preference("_only_nodes:l7H4B3pdRm6ckBWd7ODS5Q,KzjZauWGRt6hJRKTgZ7BcA");
执行发现还是会报错,提示找不到pre索引库的3号分片,3号分片是在bigdata02节点上的
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"no data nodes with criterion [l7H4B3pdRm6ckBWd7ODS5Q,KzjZauWGRt6hJRKTgZ7BcA] found for shard: [pre][3]"}],"type":"illegal_argument_exception","reason":"no data nodes with criterion [l7H4B3pdRm6ckBWd7ODS5Q,KzjZauWGRt6hJRKTgZ7BcA] found for shard: [pre][3]"},"status":400}
再把bigdata02的节点ID添加到里面
searchRequest.preference("_only_nodes:l7H4B3pdRm6ckBWd7ODS5Q,KzjZauWGRt6hJRKTgZ7BcA,nS_RptvTQDuRYTplia24WA");
此时执行就可以正常执行了:
数据总数:6
{"name":"jessica","age":18}
{"name":"lilei","age":18}
{"name":"dave","age":19}
{"name":"jack","age":29}
{"name":"lili","age":29}
{"name":"tom","age":18}
注意:在ES7.x版本之前,_only_nodes后面可以只指定某一个索引库部分分片所在的节点信息,如果不完整,不会报错,只是返回的数据是不完整的。
4、_prefer_nodes
_prefer_nodes:表示优先在指定的节点上查询。
优先在指定的节点上查询索引库分片中的数据
如果某个节点比较空闲,尽可能的多在这个节点上查询,减轻集群中其他节点的压力,尽可能实现负载均衡。
这里可以指定一个或者多个节点
searchRequest.preference("_prefer_nodes:l7H4B3pdRm6ckBWd7ODS5Q");
最终可以查询到完整的结果:
数据总数:6
{"name":"jessica","age":18}
{"name":"lilei","age":18}
{"name":"dave","age":19}
{"name":"jack","age":29}
{"name":"lili","age":29}
{"name":"tom","age":18}
5、_shards
_shards:表示只查询索引库中指定分片的数据。
在查询的时候可以指定只查询索引库中指定分片中的数据,其实有点类似于Hive中的分区表的特性。
如果我们提前已经知道需要查询的数据都在这个索引库的哪些分片里面,在这里提前指定对应分片编号,这样查询请求就只会到这些分片里面进行查询,这样可以提高查询效率,减轻集群压力。
可以指定一个或者多个分片编号,分片编号是从0开始的。
searchRequest.preference("_shards:0,1");
最终可以看到这两个分区里面的数据:
数据总数:3
{"name":"jessica","age":18}
{"name":"lilei","age":18}
{"name":"dave","age":19}
那我们如何控制将某一类型的数据添加到指定分片呢?
不要着急,一会就会讲到。
custom-string:自定义一个参数,不能以下划线(_)开头。
有时候我们希望多次查询使用索引库中相同的分片,因为分片会有副本,正常情况下如果不做控制,那么两次查询的时候使用的分片可能会不一样,第一次查询可能使用的是主分片,第二次查询可能使用的是副本分片。
大家可能会有疑问,不管是主分片,还是副本分片,这些分片里面的数据是完全一样的,就算两次查询使用的不是相同分片又会有什么问题吗?
会有问题的!如果searchType使用的是QUERY_THEN_FETCH,此时分片里面的数据在计算打分依据的时候是根据当前节点里面的词频和文档频率,两次查询使用的分片不是同一个,这样就会导致在计算打分依据的时候使用的样本不一致,最终导致两次相同的查询条件返回的结果不一样。
当然了,如果你使用的是DFS_QUERY_THEN_FETCH就不会有这个问题了,但是DFS_QUERY_THEN_FETCH对性能损耗会大一些,所以并不是所有情况下都使用这种searchType。
通过自定义参数的设置,只要两次查询使用的自定义参数是同一个,这样就可以保证这两次查询使用的分片是一样的,那么这两次查询的结果肯定是一样的。
注意:自定义参数不能以_开头。
searchRequest.preference("abc");//自定义参数
查询到的结果还是完整的。
数据总数:6
{"name":"jessica","age":18}
{"name":"lilei","age":18}
{"name":"dave","age":19}
{"name":"jack","age":29}
{"name":"lili","age":29}
{"name":"tom","age":18}
四、ES中的routing路由功能
ES在添加数据时,会根据id或者routing参数进行hash,得到hash值再与该索引库的分片数量取模,得到的值即为存入的分片编号
如果多条数据使用相同的routing,那么最终计算出来的分片编号都是一样的,那么这些数据就可以存储到相同的分片里面了。
后期查询的只需要到指定分片中查询即可,可以显著提高查询性能。
如果在面试的时候面试官问你如何在ES中实现极速查询,其实就是问这个routing路由功能的。
下面来演示一下:
创建一个新的索引库,指定5个分片,0个副本。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/rout/' -d'{"settings":{"number_of_shards":5,"number_of_replicas":0}}'
初始化数据:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/1?routing=class1' -d'{"name":"tom","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/2?routing=class1' -d'{"name":"jack","age":29}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/3?routing=class1' -d'{"name":"jessica","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/4?routing=class1' -d'{"name":"dave","age":19}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/5?routing=class1' -d'{"name":"lilei","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/rout/_doc/6?routing=class1' -d'{"name":"lili","age":29}'
如果是使用的JavaAPI,那么需要通过使用routing函数指定。
private static void addIndexByJson(RestHighLevelClient client) throws IOException {
IndexRequest request = new IndexRequest("emp");
request.id("10");
String jsonString = "{" +
"\"name\":\"jessic\"," +
"\"age\":20" +
"}";
request.source(jsonString, XContentType.JSON);
request.routing("class1");
//执行
client.index(request, RequestOptions.DEFAULT);
}
查看数据在分片中的分布情况,发现所有数据都在0号分片里面,说明routing参数生效了

通过代码查询的时候,可以通过偏好查询指定只查询0号分片里面的数据。
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("rout");
//指定分片查询方式
searchRequest.preference("_shards:0");
这样就可以查看所有的数据:
数据总数:6
{"name":"tom","age":18}
{"name":"jack","age":29}
{"name":"jessica","age":18}
{"name":"dave","age":19}
{"name":"lilei","age":18}
{"name":"lili","age":29}
通过偏好查询中的_shard手工指定分片编号在使用的时候不太友好,需要我们单独维护一份数据和分片之间的关系,比较麻烦。
还有一种比较简单常用的方式是在查询的时候设置相同的路由参数,这样就可以快速查询到使用这个路由参数添加的数据了。
底层其实是会计算这个路由参数对应的分片编号,最终到指定的分片中查询数据。
SearchRequest searchRequest = new SearchRequest();
//指定索引库,支持指定一个或者多个,也支持通配符,例如:user*
searchRequest.indices("rout");
//指定分片查询方式
//searchRequest.preference("_shards:0");
//指定路由参数
searchRequest.routing("class1");
结果如下
数据总数:6
{"name":"tom","age":18}
{"name":"jack","age":29}
{"name":"jessica","age":18}
{"name":"dave","age":19}
{"name":"lilei","age":18}
{"name":"lili","age":29}
我们把routing参数修改一下,改为class2
//指定路由参数
searchRequest.routing("class2");
此时结果如下:
数据总数:0
从这可以看出来,这个routing参数确实生效了。
注意:routing机制使用不好可能会导致数据倾斜,就是有的分片里面数据很多,有的分片里面数据很少
五、ES的索引库模板(了解)
在实际工作中针对一批大量数据存储的时候需要使用多个索引库,如果手工指定每个索引库的配置信息的话就很麻烦了。
配置信息其实主要就是settings和mapping。
可以通过提前创建一个索引库模板,后期在创建索引库的时候,只要索引库的命名符合一定的要求就可以直接套用模板中的配置。
下面看一个案例:
首先创建两个索引库模板:
第一个索引库模板:
[root@bigdata01 ~]#curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/_template/t_1' -d '
{
"template" : "*",
"order" : 0,
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"properties":{
"name":{"type":"text"},
"age":{"type":"integer"}
}
}
}
'
第二个索引库模板:
[root@bigdata01 ~]#curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/_template/t_2' -d '
{
"template" : "te*",
"order" : 1,
"settings" : {
"number_of_shards" : 3
},
"mappings" : {
"properties":{
"name":{"type":"text"},
"age":{"type":"long"}
}
}
}
’
注意:order值大的模板内容会覆盖order值小的。
第一个索引库模板默认会匹配所有的索引库,第二个索引库模板只会匹配索引库名称以te开头的索引库,通过template属性配置的。
如果我们创建的索引库名称满足第二个就会使用第二个模板,不满足的话才会使用第一个模板。
下面创建一个索引库,索引库名称为:test10
[root@bigdata01 ~]# curl -XPUT 'http://localhost:9200/test10'
查看索引库test10的setting和mapping信息。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test10/_settings?pretty'
{
"test10" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "3",
"provided_name" : "test10",
"creation_date" : "1804935156129",
"number_of_replicas" : "1",
"uuid" : "iJLdIRwQSpagzEtIu0LDEw",
"version" : {
"created" : "7130499"
}
}
}
}
}
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/test10/_mapping?pretty'
{
"test10" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
}
}
}
}
}
通过结果可以看出来test10这个索引库使用到了第二个索引库模板。
接下来再创建一个索引库,索引库名称为hello
[root@bigdata01 ~]# curl -XPUT 'http://bigdata01:9200/hello'
查看索引库hello的setting和mapping信息。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/hello/_settings?pretty'
{
"hello" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "2",
"provided_name" : "hello",
"creation_date" : "1804935301339",
"number_of_replicas" : "1",
"uuid" : "xkg-XXSQSHKcJ_5nxyTPTQ",
"version" : {
"created" : "7130499"
}
}
}
}
}
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/hello/_mapping?pretty'
{
"hello" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text"
}
}
}
}
}
通过结果可以看出来hello这个索引库使用到了第一个索引库模板。
后期想要查看索引库模板内容可以这样查看:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/_template/t_*?pretty'
{
"t_1" : {
"order" : 0,
"index_patterns" : [
"*"
],
"settings" : {
"index" : {
"number_of_shards" : "2"
}
},
"mappings" : {
"properties" : {
"name" : {
"type" : "text"
},
"age" : {
"type" : "integer"
}
}
},
"aliases" : { }
},
"t_2" : {
"order" : 1,
"index_patterns" : [
"te*"
],
"settings" : {
"index" : {
"number_of_shards" : "3"
}
},
"mappings" : {
"properties" : {
"name" : {
"type" : "text"
},
"age" : {
"type" : "long"
}
}
},
"aliases" : { }
}
}
想要删除索引库模板可以这样做:
[root@bigdata01 ~]# curl -XDELETE 'http://bigdata01:9200/_template/t_2'
六、ES的索引库别名(了解)
在工作中使用ES收集应用的运行日志,每个星期创建一个索引库,这样时间长了就会创建很多的索引库,操作和管理的时候很不方便。
由于新增索引数据只会操作当前这个星期的索引库,所以为了使用方便,我们就创建了两个索引库别名:curr_week和last_3_month。
curr_week:这个别名指向当前这个星期的索引库,新增数据使用这个索引库别名。
last_3_month:这个别名指向最近三个月的所有索引库,因为我们的需求是需要查询最近三个月的日志信息。
后期只需要修改这两个别名和索引库之间的指向关系即可,应用层代码不需要任何改动。
下面来演示一下这个案例:
假设ES已经收集了一段时间的日志数据,每一星期都会创建一个索引库,所以目前创建了4个索引库:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/log_20260301/'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/log_20260308/'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/log_20260315/'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/log_20260322/'
分别向每个索引库里面初始化1条测试数据:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/log_20260301/_doc/1' -d'{"log":"info->20260301"}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/log_20260308/_doc/1' -d'{"log":"info->20260308"}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/log_20260315/_doc/1' -d'{"log":"info->20260315"}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/log_20260322/_doc/1' -d'{"log":"info->20260322"}'
为了使用方便,我们创建了两个索引库别名:curr_week和last_3_month。
curr_week指向最新的索引库:log_20260322
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_aliases' -d '
{
"actions" : [
{ "add" : { "index" : "log_20260322", "alias" : "curr_week" } }
]
}'
last_3_month指向之前3个月内的索引库:
可以同时增加多个索引别名。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_aliases' -d '
{
"actions" : [
{ "add" : { "index" : "log_20260301", "alias" : "last_3_month" } },
{ "add" : { "index" : "log_20260308", "alias" : "last_3_month" } },
{ "add" : { "index" : "log_20260315", "alias" : "last_3_month" } }
]
}'
以后使用的时候,想要操作当前星期内的数据就使用curr_week这个索引库别名就行了。
查询一下curr_week里面的数据:
这里面就1条数据,和使用索引库log_20260322查询的结果是一样的。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/curr_week/_search?pretty'
{
"took" : 987,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log_20260322",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260322"
}
}
]
}
}
再使用last_3_month查询一下数据:
这里面返回了log_20260301、log_20260308和log_20260315这3个索引库里面的数据。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/last_3_month/_search?pretty'
{
"took" : 73,
"timed_out" : false,
"_shards" : {
"total" : 6,
"successful" : 6,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log_20260301",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260301"
}
},
{
"_index" : "log_20260308",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260308"
}
},
{
"_index" : "log_20260315",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260315"
}
}
]
}
}
过了一个星期之后,又多了一个新的索引库:log_20260329
创建这个索引库并初始化一条数据
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/log_20260329/'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/log_20260329/_doc/1' -d'{"log":"info->20260329"}'
此时就需要修改curr_week别名指向的索引库了,需要先删除之前的关联关系,再增加新的。
删除curr_week和log_20260322之间的关联关系。
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_aliases' -d '
{
"actions" : [
{ "remove" : { "index" : "log_20260322", "alias" : "curr_week" } }
]
}'
新增curr_week和log_20260329之间的关联关系
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_aliases' -d '
{
"actions" : [
{ "add" : { "index" : "log_20260329", "alias" : "curr_week" } }
]
}'
此时再查询curr_week中的数据其实就是查询索引库log_20260329里面的数据了。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/curr_week/_search?pretty'
{
"took" : 25,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log_20260329",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260329"
}
}
]
}
}
然后再把索引库log_20260322添加到last_3_month别名中:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_aliases' -d '
{
"actions" : [
{ "add" : { "index" : "log_20260322", "alias" : "last_3_month" } }
]
}'
这些关联别名映射关系和移除别名映射关系的操作需要写个脚本定时执行,这样就可以实现别名自动关联到指定索引库了。
假设时间长了,我们如果忘记了这个别名下对应的都有哪些索引库,可以使用下面的方法查看一下:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/_alias/curr_week?pretty'
{
"log_20260329" : {
"aliases" : {
"curr_week" : { }
}
}
}
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/_alias/last_3_month?pretty'
{
"log_20260315" : {
"aliases" : {
"last_3_month" : { }
}
},
"log_20260308" : {
"aliases" : {
"last_3_month" : { }
}
},
"log_20260301" : {
"aliases" : {
"last_3_month" : { }
}
},
"log_20260322" : {
"aliases" : {
"last_3_month" : { }
}
}
}
如果想知道哪些别名指向了这个索引,可以这样查看:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/log_20260301/_alias/*?pretty'
{
"log_20260301" : {
"aliases" : {
"last_3_month" : { }
}
}
}
注意:针对3个月以前的索引基本上就很少再使用了,为了减少对ES服务器的性能损耗(主要是内存的损耗),建议把这些长时间不使用的索引库close掉,close之后这个索引库里面的索引数据就不支持读写操作了,close并不会删除索引库里面的数据,后期想要重新读写这个索引库里面的数据的话,可以通过open把索引库打开。
将log_20260301索引库close掉:
[root@bigdata01 ~]# curl -XPOST 'http://bigdata01:9200/log_20260301/_close'
此时再查看这个索引库的数据就查询不到了:
会提示这个索引库已经被close掉了
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/log_20260301/_search?pretty'
{
"error" : {
"root_cause" : [
{
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "VGfSvKVJRjy5h3aCcsveKQ",
"index" : "log_20260301"
}
],
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "VGfSvKVJRjy5h3aCcsveKQ",
"index" : "log_20260301"
},
"status" : 400
}
注意:这些close之后的索引库需要从索引库别名中移除掉,否则会导致无法使用从索引库别名查询数据,因为这个索引库别名中映射的有已经close掉的索引库。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/last_3_month/_search?pretty'
{
"error" : {
"root_cause" : [
{
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "VGfSvKVJRjy5h3aCcsveKQ",
"index" : "log_20260301"
}
],
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "VGfSvKVJRjy5h3aCcsveKQ",
"index" : "log_20260301"
},
"status" : 400
}
接下来将log_20260301索引库重新open(打开)。
[root@bigdata01 ~]# curl -XPOST 'http://bigdata01:9200/log_20260301/_open'
索引库open之后就可以查询了:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/log_20260301/_search?pretty'
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log_20260301",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260301"
}
}
]
}
}
索引库别名也可以正常使用了:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/last_3_month/_search?pretty'
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 8,
"successful" : 8,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log_20260301",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260301"
}
},
{
"_index" : "log_20260308",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260308"
}
},
{
"_index" : "log_20260315",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260315"
}
},
{
"_index" : "log_20260322",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"log" : "info->20260322"
}
}
]
}
}
索引库close掉之后,虽然对ES服务器没有性能损耗了,但是对ES集群的磁盘占用还是存在的,所以可以根据需求,将一年以前的索引库彻底删除掉。
七、ES SQL
针对ES中的结构化数据,使用SQL实现聚合统计会很方便,可以减少很多工作量。
ES SQL支持常见的SQL语法,包括分组、排序、函数等,但是目前不支持JOIN。
在使用的时候可以使用SQL命令行、RestAPI、JDBC、ODBC等方式操作。
本地测试的时候使用SQL命令行更加方便。
想要实现跨语言调用使用RestAPI更加方便。
Java程序员使用JDBC方式更方便。
1、ES SQL命令行下的使用
[es@bigdata01 elasticsearch-7.13.4]$ bin/elasticsearch-sql-cli http://bigdata01:9200
sql> select * from user;
age | name
---------------+---------------
20 |tom
15 |tom
17 |jack
19 |jess
23 |mick
12 |lili
28 |john
30 |jojo
16 |bubu
21 |pig
19 |mary
60 |刘德华
20 |刘老二
sql> select * from user where age > 20;
age | name
---------------+---------------
23 |mick
28 |john
30 |jojo
21 |pig
60 |刘德华
如果想要实现模糊查询,使用sql中的like是否可行?
sql> select * from user where name like '刘华';
age | name
---------------+---------------
sql> select * from user where name like '刘%';
age | name
---------------+---------------
60 |刘德华
20 |刘老二
like这种方式其实就是普通的查询了,无法实现分词查询。
想要实现分词查询,需要使用match。
sql> select * from user where match(name,'刘华');
age | name
---------------+---------------
60 |刘德华
20 |刘老二
退出ES SQL命令行,需要输入exit;
sql> exit;
Bye!
2、RestAPI下ES SQL的使用
查询user索引库中的数据,根据age倒序排序,获取前5条数据
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/_sql?format=txt' -d'
{
"query":"select * from user order by age desc limit 5"
}
'
age | name
---------------+---------------
60 |刘德华
30 |jojo
28 |john
23 |mick
21 |pig
3、JDBC操作ES SQL
首先添加ES sql-jdbc的依赖。
org.elasticsearch.plugin
x-pack-sql-jdbc
7.13.4
开发代码:
package com.imooc.es;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
/**
* JDBC操作ES SQL
*
*/
public class EsJdbcOp {
public static void main(String[] args) throws Exception{
//指定jdbcUrl
String jdbcUrl = "jdbc:es://http://bigdata01:9200/?timezone=UTC+8";
Properties properties = new Properties();
//获取JDBC连接
Connection conn = DriverManager.getConnection(jdbcUrl, properties);
Statement stmt = conn.createStatement();
ResultSet results = stmt.executeQuery("select name,age from user order by age desc limit 5");
while (results.next()){
String name = results.getString(1);
int age = results.getInt(2);
System.out.println(name+"--"+age);
}
//关闭连接
stmt.close();
conn.close();
}
}
注意:jdbc这种方式目前无法免费使用,需要购买授权。
Exception in thread "main" java.sql.SQLInvalidAuthorizationSpecException: current license is non-compliant for [jdbc]
所以在工作中常用的是RestAPI这种方式。
八、ES优化策略
1、ES中Too many open files的问题。
ES中的索引数据都是存储在磁盘文件中的,每一条数据在底层都会产生一份索引片段文件
这些索引数据默认的存储目录是在ES安装目录下的data目录里面。
[es@bigdata01 index]$ pwd
/data/soft/elasticsearch-7.13.4/data/nodes/0/indices/28q_rMHAR4GJBImzb40woA/0/index
[es@bigdata01 index]$ ll
total 52
-rw-rw-r--. 1 es es 479 Mar 12 15:21 _0.cfe
-rw-rw-r--. 1 es es 3302 Mar 12 15:21 _0.cfs
-rw-rw-r--. 1 es es 363 Mar 12 15:21 _0.si
-rw-rw-r--. 1 es es 479 Mar 12 15:21 _1.cfe
-rw-rw-r--. 1 es es 2996 Mar 12 15:21 _1.cfs
-rw-rw-r--. 1 es es 363 Mar 12 15:21 _1.si
-rw-rw-r--. 1 es es 923 Mar 12 16:28 _2_1.fnm
-rw-rw-r--. 1 es es 103 Mar 12 16:28 _2_1_Lucene80_0.dvd
-rw-rw-r--. 1 es es 160 Mar 12 16:28 _2_1_Lucene80_0.dvm
-rw-rw-r--. 1 es es 479 Mar 12 16:28 _2.cfe
-rw-rw-r--. 1 es es 3718 Mar 12 16:28 _2.cfs
-rw-rw-r--. 1 es es 363 Mar 12 16:28 _2.si
-rw-rw-r--. 1 es es 533 Mar 12 16:33 segments_4
-rw-rw-r--. 1 es es 0 Mar 12 15:21 write.lock
注意:路径中的28q_rMHAR4GJBImzb40woA表示是索引库的UUID。
ES在查询索引库里面数据的时候需要读取所有的索引片段,如果索引库中数据量比较多,那么ES在查询的时候就需要读取很多索引片段文件,此时可能就会达到Linux系统的极限,因为Linux会限制系统内最大文件打开数。
这个最大文件打开数的的配置在安装ES集群的时候我们已经修改过了:
主要就是这些参数:
[root@bigdata01 soft]# vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
*
理论上来说,不管我们将最大文件打开数修改为多大,在使用的时候都有可能会出问题,因为ES中的数据是越来越多的,那如何解决?
其实也不用过于担心,因为ES中默认会有一个自动的索引片段合并机制,这样可以保证ES中不会产生过多的索引片段。
只要是单个索引片段文件小于5G的,在自动索引片段合并机制触发的时候都会进行合并。
2、索引合并优化,清除标记为删除状态的索引数据。
咱们前面分析过,ES中的删除并不是真正的删除,只是会给数据标记一个删除状态,索引片段在合并的时候,是会把索引片段中标记为删除的数据真正删掉,这样也是可以提高性能的,因为标记为删除状态的数据是会参与查询的,只不过会被过滤掉。
索引片段合并除了可以避免产生Too many open files这个问题,其实它也是可以显著提升查询性能的,因为我们读取一个中等大小的文件肯定是比读取很多个小文件效率更高的
除了等待自动的索引片段合并,也可以手工执行索引片段合并操作,但是要注意:索引片段合并操作是比较消耗系统IO资源的,不要在业务高峰期执行,也没必要频繁调用,可以每天凌晨执行一次。
[root@bigdata01 ~]# curl -XPOST 'http://bigdata01:9200/stu/_forcemerge'
合并之后会的索引片段就变成了这样,这些文件其实属于一个索引片段,都是以_3开头的:
[es@bigdata01 index]$ ll
total 72
-rw-rw-r--. 1 es es 158 Mar 14 15:47 _3.fdm
-rw-rw-r--. 1 es es 527 Mar 14 15:47 _3.fdt
-rw-rw-r--. 1 es es 64 Mar 14 15:47 _3.fdx
-rw-rw-r--. 1 es es 922 Mar 14 15:47 _3.fnm
-rw-rw-r--. 1 es es 202 Mar 14 15:47 _3.kdd
-rw-rw-r--. 1 es es 69 Mar 14 15:47 _3.kdi
-rw-rw-r--. 1 es es 200 Mar 14 15:47 _3.kdm
-rw-rw-r--. 1 es es 159 Mar 14 15:47 _3_Lucene80_0.dvd
-rw-rw-r--. 1 es es 855 Mar 14 15:47 _3_Lucene80_0.dvm
-rw-rw-r--. 1 es es 78 Mar 14 15:47 _3_Lucene84_0.doc
-rw-rw-r--. 1 es es 92 Mar 14 15:47 _3_Lucene84_0.pos
-rw-rw-r--. 1 es es 305 Mar 14 15:47 _3_Lucene84_0.tim
-rw-rw-r--. 1 es es 74 Mar 14 15:47 _3_Lucene84_0.tip
-rw-rw-r--. 1 es es 261 Mar 14 15:47 _3_Lucene84_0.tmd
-rw-rw-r--. 1 es es 59 Mar 14 15:47 _3.nvd
-rw-rw-r--. 1 es es 103 Mar 14 15:47 _3.nvm
-rw-rw-r--. 1 es es 575 Mar 14 15:47 _3.si
-rw-rw-r--. 1 es es 316 Mar 14 15:47 segments_5
-rw-rw-r--. 1 es es 0 Mar 12 15:21 write.lock
如果一个索引库中的数据已经非常多了,手工执行索引片段合并操作可能会产生一些非常大的索引片段(超过5G的),如果继续向这个索引库里面写入新的数据,那么ES的自动索引片段合并机制就不会再考虑这些非常大的索引片段了(超过5G的),这样会导致索引库中保留了非常大的索引片段,从而降低搜索性能。
这种问题该如何解决呢?往下面继续看!
3、分片和副本个数调整。
分片多的话,可以提升建立索引的能力,单个索引库,建议使用5-20个分片比较合适。
分片数过少或过多,都会降低检索效率。
分片数过多会导致检索时打开比较多的文件,另外也会导致多台服务器之间的通讯。
而分片数过少会导致单个分片索引过大,所以检索速度也会慢。
建议单个分片存储20G左右的索引数据【最高也不要超过50G,否则性能会很差】
所以,大致有一个公式:分片数量=数据总量/20G
当数据规模超过单个索引库最大存储能力的时候,只需要新建一个索引库即可,所以ES中的海量数据存储能力是需要依靠多个索引库的,这样就可以解决前面所说的索引库中单个索引片段过大的问题。
副本多的话,理论上来说可以提升检索的能力,但是如果设置很多副本的话也会对服务器造成额外的压力,因为主分片需要给所有副本分片同步数据,所以建议最多设置1-2个副本即可。
注意:从ES7.x版本开始,集群中每个节点默认支持最多1000个了片,这块主要是考虑到单个节点的性能问题,如果集群内每个节点的性能都比较强,当然也是支持修改的。
先查看一下现在集群默认的参数配置:
现在里面的参数都是空的。
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/_cluster/settings?pretty'
{
"persistent" : { },
"transient" : { }
}
修改节点支持的最大分片数量:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPUT 'http://bigdata01:9200/_cluster/settings' -d '{ "persistent": { "cluster.max_shards_per_node": "10000" } }'
重新查询集群最新的参数配置:
[root@bigdata01 ~]# curl -XGET 'http://bigdata01:9200/_cluster/settings?pretty'
{
"persistent" : {
"cluster" : {
"max_shards_per_node" : "10000"
}
},
"transient" : { }
}
4、初始化数据时,建议将副本数设置为0。
如果是在项目初期,ES集群刚安装好,需要向里面批量初始化大量数据,此时建议将副本数设置为0,这样是可以显著提高入库效率的。
如果有副本的话,在批量初始化数据的同时,索引库的主分片还需要负责向副本分片同步数据,这样会影响数据的入库性能。
5. 针对不使用的index,建议close,减少性能损耗。
具体的操作方式在前面讲索引库别名的时候已经讲过了。
6、调整ES的JVM内存大小,单个ES实例最大不超过32G。
单个ES实例官方建议最大使用32G内存,如果超过这个内存ES也使用不了,这样会造成资源浪费。
所以在前期申请ES集群机器的时候,建议单机内存在32G左右即可。
如果由于历史遗留问题导致每台机器的内存都很大,假设是128G的,如果在这台机器上只部署一个ES实例,会造成内存资源浪费,此时有一种取巧的方式,在同一台机器上部署多个ES实例,只需要让这台机器中的每个ES实例监听不同的端口就行了。
这样这个128G内存的机器理论上至少可以部署4个ES实例。
但是这样会存在一个弊端,如果后期这台机器出现了故障,那么ES集群会同时丢失4个节点,可能会丢数据,所以还是尽量避免这种情况。