【斯坦福cs324w】中译版 大模型学习笔记八 新的模型架构
文章目录
- 混合专家模型
-
- 基础知识
-
- 基本思想
- 训练
- 节约计算
- 平衡专家
- 并行
- Sparsely-gated mixture of experts
-
- 符号定义
- 平衡专家
- 示例
-
- Switch Transformer
- Balanced Assignment of Sparse Experts(BASE) layers
- GLaM
- FacebookMoE
- 基于检索的模型
-
-
- RAG
-
- 参考资料
llm面对的问题
模型的规模太大,分布式训练方法中的模型并行、流水并行都受到网络带宽的限制
思想
进一步缩小模型,使用更小的参数子集来进行训练
两种模型架构
混合专家模型

基于检索的模型

混合专家模型
基础知识
基本思想
思想图示

举个例子
对于一个预测问题
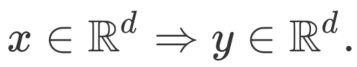
传统的解决办法——学习前馈(ReLU激活)神经网络

说明:其中的参数为 θ = ( W 1 , W 2 ) \theta = (W_1, W_2) θ=(W1,W2)
存在的问题:由于模型不够深、不够宽,其表达能力是受限的
使用专家混合的解决思路



猜想:由于将模型参数进行拆分,引入门控函数实现了有同样大小参数量的模型有了更好的表达能力
门控函数(Gating Funciton)深度学习中用于控制信息的流动和筛选的函数,通常由一个sigmoid函数和一个可学习的权重矩阵组成
常见的门控函数
重置门:需要遗忘/重置的信息
更新门:需要保留/更新的信息
输出门:需要保留或筛选的信息
对于一个分类问题
训练
反向传播,同时更新门控函数和专家

节约计算
调整门控函数,将大多数专家对应的分量设置为0,得到门控函数的近似,前向和反向传播时则只需要考虑门控函数非零分量对应的专家的计算
举个例子

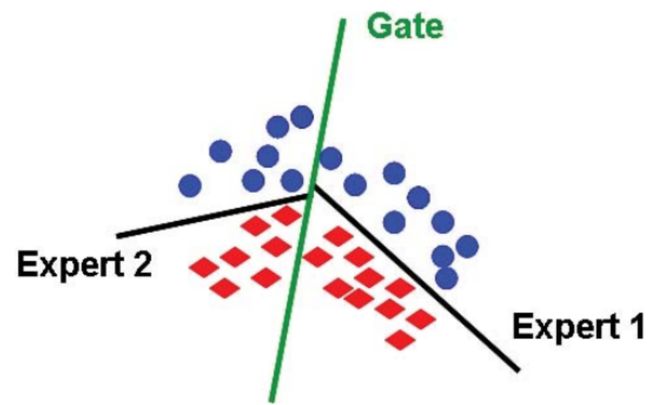
平衡专家
在节约计算的同时也需要考虑更大程度地让更多的专家纳入计算,增强网络的表达能力
如果在一层网络中只有一个专家处于活跃状态,即 g ( x ) = [ 0 , 1 , 0 , 0 , 0 ] g(x)=[0,1,0,0,0] g(x)=[0,1,0,0,0],这其实是一种浪费
并行
混合专家系统的设计保证其并行化的易行性
具体做法
将每个专家放置在不同的机器上
使用中心节点计算近似门控函数
Sparsely-gated mixture of experts
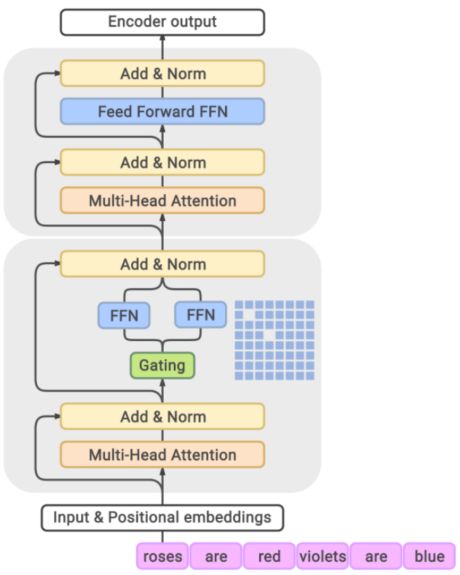
如何将混合专家思想用于语言模型
每个token对应一个专家
在每个Transformer Block中使用混合专家系统
利用前馈层独立每个token,将前馈网络转变为混合专家(MoE)前馈网络
![]()
MoE Transformer Block图示
举个例子:一个top-2的近似门控函数定义


符号定义
B: batch_size
E: expert_num

平衡专家
目标
解决某些专家被过度使用的问题,期望达到一个batch里面每个专家的使用次数是均匀分布的,即 c = [ c 1 , c 2 , . . . , c E ] c = [c_1, c_2, ..., c_E] c=[c1,c2,...,cE]均匀分布
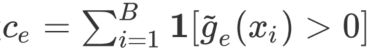
具体做法
在loss里面加上load_balancing_loss作为专家选择的惩罚项
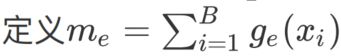

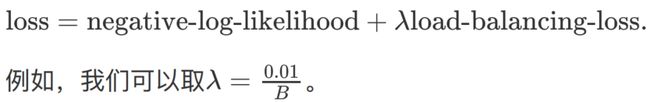
示例

对于这个MoE,我们会在loss中对 e 2 e_2 e2有一个较大的惩罚项
Switch Transformer
模型训练配置

Balanced Assignment of Sparse Experts(BASE) layers
门控函数定义:对batch中所有token进行联合优化的结果
为每个token分配一个专家
系统中通过约束实现负载平衡
GLaM
Generalist Language Model
使用的是top2的专家策略
特点

结果

FacebookMoE
使用top2的专家策略
基于检索的模型

检索思想

RAG
Retrieval-augmented generation
图示表示
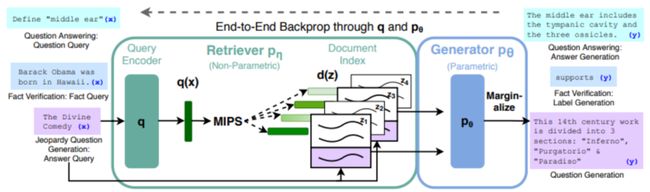
说明:模型分为retriever和generator两个部分
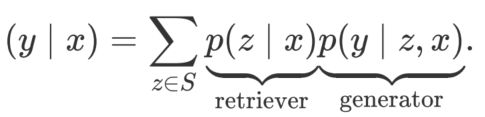
检索器
使用Dense Passage Retrieval(DPR)
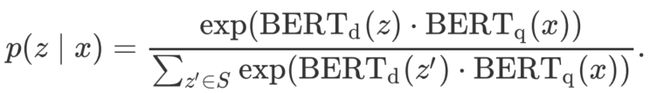
生成器
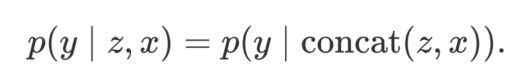
参考资料
- datawhale的so-large-lm学习资料