数组规约问题的逐步进化 --- cuda实现方法
数组规约计算:
一个有 N 个元素的数组 x, 我们需要计算该数组中所有元素的和,即 sum = x[0] + x[1] + x[2] + … + x[N-1]
怎样可以更快更准确的得到计算结果
使用CPU进行计算
#include "error.cuh"
#include 运算结果
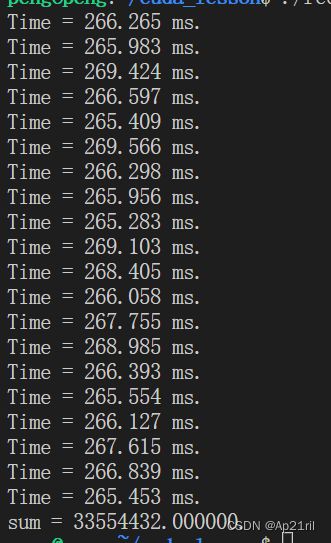
在使用单精度浮点数时,输出如上图所示,该结果完全错误。这是因为,在计算过程中出现了“大数吃小数”的现象。具体来说,当一个足够大的单精度浮点数加上1.23时,其值就不在增加了,单精度浮点数只有6、7位有效数字。
CPU运算速度: 267 ms左右
cuda 优化
仅使用全局内存
//全局内存
void __global__ reduce_global(real *d_x, real *d_y)
{
const int tid = threadIdx.x;
//赋值符号右边是数组d_x中第blockDim.x * blockIdx.x个元素的地址
//这样定义的x在不同的线程块中指向全局内存中不同的地址,使得我们可以在不同的线程块中对数组d_x中不同的部分进行规约
real *x = d_x + blockDim.x * blockIdx.x;
//这个for循环就是在各个线程块中对其数据独立的进行规约。
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
x[tid] += x[tid + offset];
}
//同步语句 保证同一个线程块捏的线程按照代码出现的顺序执行指令
//若不加可能会出现,一个线程对某个元素的修改还没写入,另一个线程就又读取这个元素。很明显是有问题的
__syncthreads();
}
//经过上述计算,每个线程块中的元素都被相加到了线程块中tid=0的线程中,也就是线程块的第一个位置
//到这里只是将一个长度为 1e9 的数组d_x规约到一个长度为 1e9/128 的数组d_y中。
//为了计算整个数组元素的和,需要将数组d_y复制到主机端,并在主机端对d_y进行规约,这样并不高效,但后面会优化。
if (tid == 0)
{
d_y[blockIdx.x] = x[0];
}
}

运算结果:30 ms左右
可以看出,只是使用全局内存,运算速度已经有很好的提升了,约为CPU版本的8.9倍。我的显卡为1050,比较老,若使用更高版本的显卡,提升会更明显。樊哲勇老师的书上使用2070,提升了17倍。
使用共享内存
void __global__ reduce_shared(real *d_x, real *d_y)
{
//线程块中的第几个线程
const int tid = threadIdx.x;
//网格中的第几个线程块
const int bid = blockIdx.x;
//全局位置
const int n = bid * blockDim.x + tid;
//定义共享内存数组,这个大小和线程块的大小一致,否则会引起错误或降低核函数性能
//在一个核函数中定义一个共享内存变量,就相当于在每一个线程块中有了一个该变量的副本。每个副本都不一样,虽然是共用一个变量名。
__shared__ real s_y[128];
//将全局内存中的数据复制到共享内存中。
//当bid=0时,即为第0个线程块:将全局内存中第0-blockDim.x-1个元素复制到第0个线程块的共享内存样本
//当bid=0时,即为第1个线程块:将全局内存中第blockDim.x-2*blockDim.x-1个元素复制到第1个线程块的共享内存样本
//通过n < N的判断,该函数能处理N不是线程块大小整数倍的情景
s_y[tid] = (n < N) ? d_x[n] : 0.0;
//在利用共享内存进行线程块的合作通信之前都要进行同步,确保共享内存变量中的数据对线程块内所有线程来说都准备就绪
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
//使用共享内存替代了原来的全局变量。每个线程块都对其中的共享内存副本进行操作
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
//共享内存变量的生命周期仅仅在核函数内,所以必须在核函数结束前,将共享内存中的某些结果保存到全局内存中
if (tid == 0)
{
//bid表示哪一个线程块
d_y[bid] = s_y[0];
}
}

结果: 18 ms
使用共享内存减少全局内存的访问一般来说会带来性能的提升,但不是绝对的。
使用共享内存有两个好处:
一个是不再要求全局内存数组的长度N是线程块大小的整数倍,若不足则会补0。
另一个是在规约的过程中不会改变全局内存数组中的数据。
使用动态共享内存
在定义共享内存变量时不小心把共享内存数组长度写错会出现问题,为了解决这个问题,可以使用动态共享内存。只需要做两处修改。
(1)
reduce_dynamic<<<grid_size, BLOCK_SIZE, smem>>>(d_x, d_y);
smem 是核函数中每个线程块需要定义的动态共享内存的字节数。没有这个参数的话默认为0。
(2)
还需要改变核函数中共享内存变量的声明方式
extern __shared__ real s_y[];
与静态共享内存的声明方式有两点不同。
第一,必须加上限定词 extern
第二,不能指定数组大小
void __global__ reduce_dynamic(real *d_x, real *d_y)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ real s_y[];
s_y[tid] = (n < N) ? d_x[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0)
{
d_y[bid] = s_y[0];
}
}
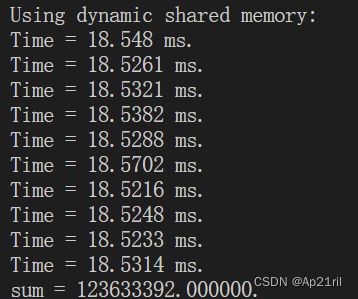
结果表明,使用动态共享内存和静态共享内存的核函数在执行时间上几乎没有任何差别。所以使用动态共享内存不会影响程序性能,但有时可提高程序的可维护性。
TODO:
使用原子函数
使用束内同步函数
使用洗牌函数
使用协作组
本文参考樊哲勇老师的《CUDA编程 基础与实践》