训练吞吐量提升6倍!飞桨弹性计算推荐系统套件ElasticCTR1.0发布

如今,睡前刷刷新闻、视频已经成了大多数人的习惯,有人认为可以适当缓解压力、打发时间、有趣好玩, 甚至已经成为生活中“不可或缺”的部分。
为什么大家会觉得有趣呢?这后面很大程度是“推荐系统”在起作用。推荐系统常用的一种推荐策略,就是根据用户的历史喜好推荐新的内容,让用户喜欢看,从而增加用户粘性。
具体是如何实现推荐的?
目前在推荐系统领域,应用深度学习模型来实现推荐,可以取得非常好的效果,是未来的发展趋势。
以一个新闻推荐的简单例子来看,用户访问 APP 时,会对推送的新闻条目点击(正样本)或是滑过不点击(负样本),这些点击行为信息、加上用户信息、新闻条目信息经过特征提取以后,可以得到用户特征和新闻特征之间的匹配度,匹配度越高说明用户对这条新闻越感兴趣。
因此再推送新的新闻时,就可以从清单中选择匹配度最高的新闻推送给用户。
看起来问题的处理不算复杂,但实现开发这样一套推荐系统,开发者会面临诸多问题:

▲ 图:推荐系统的Workflow
① 需要做繁杂的数据预处理:实际环境中数据集可能有成千上万个特征,但并非每个条目都有所有的特征,也并非每个特征都有必要参与训练,需要处理后才能参与训练;同时数据集的来源是原始的日志信息,还需要做一定的格式转换。
② 需要高速的数据集传输设计:推荐系统需要处理的日志数据非常庞大,单机或是本地文件系统很难作为日志数据的载体,需要有分布式的文件系统。而且在读取文件的过程中,需要设计高效的机制提升数据读写效率和并发处理效率,多队列并发的 IO 组件尤为重要。
③ 需要复杂的分布式计算架构:庞大的数据集需要强有力的分布式训练框架支持,而完成分布式计算的任务,开发者需要在繁杂的机器集群之间配置,既繁琐又容易出错 。
④ 需要精细的模型加载和配送系统:对于推荐系统来说,千万甚至亿级别的稀疏特征作为模型输入十分常见,稀疏参数的规模动辄超过单机内存,因此实现分布式稀疏参数查询,并且能够对海量稀疏参数做精确裁剪、分片,是必不可少的工作。
⑤ 需要吞吐量高的客户端服务端交互:模型的部署上线难度取决于两个方面,第一个是模型的大小,过大的模型需要做分割,分割之后的稀疏参数需要有专属的高速KV服务器来索引;第二个是响应速度,客户端、服务端、稀疏参数索引之间的通信应当尽可能快速高效。
以上每个问题,对开发者来说都是一座大山,闯过一个个关卡之后,才能打通整个推荐系统。
好在打怪升级的道路上并不寂寞,百度飞桨近期发布了一套弹性计算推荐系统套件 ElasticCTR,可实现端到端的推荐系统部署,为广大 AI 开发者又增添一套强劲的武器装备。
接下来我们就来了解一下 ElastcCTR 都有哪些武器装备。
ElasticCTR是什么?
ElasticCTR,即飞桨弹性计算推荐系统,是基于 Kubernetes 的企业级推荐系统开源解决方案。
该方案融合了百度业务场景下持续打磨的高精度 CTR 模型、飞桨开源框架的大规模分布式训练能力、工业级稀疏参数弹性调度服务,帮助用户在 Kubernetes 环境中一键完成推荐系统部署,具备高性能、工业级部署、端到端体验的特点,并且作为开源套件,满足二次深度开发的需求。
ElasticCTR有哪些特色?
1. 端到端部署套件,免去繁琐的中间处理环节,助力推荐系统快速上线
推荐排序的 workflow 复杂而琐碎,开发者会面临不同组件间难以整合的问题。
例如:HDFS 的分布式文件系统,难以被训练组件全内存多线程高效读取;训练组件产出模型后,由于模型中的稀疏参数体积过大,需要在部署模型时做分割处理;推理组件需要对体积过大的稀疏参数做分片存储处理,并且还需实现高效的远程调用。
因此有一套端到端的方案实现一站式部署,对开发者来说可以大大提升工作效率。
百度在推荐系统领域有多年的成熟经验,在这些经验的加持下,ElasticCTR 打通了端到端的部署流程,用户只需配置好数据集,通过一个 elastic_control.sh 启动工具,即可用简单几行命令,启动高性能的分布式训练和在线预测服务 PaddleServing 等组件。中间的繁琐步骤、模型配送等流程都不需要额外操作。

▲ 图:ElasticCTR的Workflow示意
此外,在接下来几个月,ElasticCTR 还将继续完善召回、向量检索等其他功能,也将整合更多的推荐模型,全方位的打造端到端推荐系统部署方案,帮助开发者快速上线推荐业务。
2. 弹性调度,全异步多线程分布式训练,训练吞吐量提升6倍
对于不同规模的数据集和访问需求,ElasticCTR 提供了资源弹性分配机制,在保证高效的同时尽可能节省资源消耗。在实际生产环境下,一套分布式系统的搭建已经十分繁杂,更不用说在其基础上弹性的增减资源,而 ElasticCTR 就给出了这样的解决方案,为开发者排忧解难。
依托 Kubernetes 的弹性分配能力,以及百度开源的各个组件对弹性调度的大力支持,用户在训练前配置训练的参数服务器和训练节点的数量等参数后,即可启动启动训练。
经验证,使用 Criteo 数据集训练 CTR-DNN 模型,训练吞吐量相比同类框架可提升 6 倍。事实上,Criteo 数据集只是一个简单的例子,在实际应用中会有更大规模的稀疏参数,ElasticCTR 的训练和部署优势会更加显著。
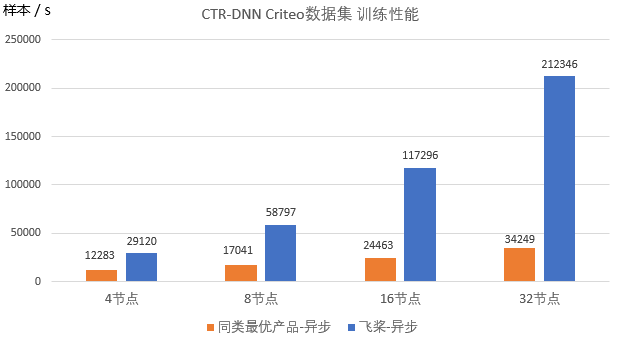
▲ 图:CTR-DNN模型训练效果对比
3. 流式训练,实现自动、分批、按时训练和配送模型
常见的深度学习训练方式中,通常是固定数据集进行多轮次迭代,但是在推荐系统中,由于日志数据的时效性,数据集需分时段加载,训练好的模型也需按时段配送。
在实际生产环境中往往是分日期、分时段保存用户点击信息的日志,ElasticCTR 支持流式训练方式,它的意义在于用户可以按照自定义的时段来训练模型,也可以监听存放数据集的 HDFS 上是否有增量的数据集参与训练,训练好的模型亦可定时增量配送。
在分布式文件系统上,按照一定的格式,例如 yyyyMMdd/hh 的格式将每个时间段的数据集准备好,通过配置文件指定,就可以把对应时间段里的模型全部训练,并且按时配送。如果没有设定终止时间,就是在线训练,时刻等待新的数据集。
4. 工业级全组件开源,满足二次深度开发诉求
ElasticCTR 采用全开源组件,满足开发者二次深度开发的需求。在数据读取和预处理环节,采用 HDFS 的存储,全内存多线程读取,打破数据传输的各种可能瓶颈;在训练环节,采用飞桨核心框架的分布式训练能力,全异步多线程分布式训练,训练速度可达到同类框架 6 倍之多.
在部署环节,采用飞桨在线部署框架 PaddleServing 简单易用的部署服务,并结合百度推荐场景成熟应用多年的稀疏参数索引服务 Cube,确保了超大规模模型的快速部署和高效服务.
此外,为充分利用 Kubernetes 的弹性调度和资源分配机制以增强可用性,引入了 Kubernetes 的 job 管理框架 Volcano。
如何用ElasticCTR来搭建推荐系统?
接下来实战演练一下 ElasticCTR。我们以 Criteo 广告数据集为输入,采用 ElasticCTR 构建一个完整的推荐系统,实现广告的推荐。Criteo 广告数据集一共有 27 个维度的稀疏参数,每一条样本均有一个label来表示用户是否点击了这条广告。
1. 创建 k8s 集群
ElasticCTR 是基于 Kubernetes(即 k8s)环境的,所以需要先创建 k8s 集群,这里推荐使用百度智能云容器引擎 CCE,可参考文档百度智能云 CCE 容器引擎帮助文档-创建集群 (https://cloud.baidu.com/doc/CCE/s/zjxpoqohb),其他云平台或是自建 K8S 集群亦可部署 ElasticCTR。
在准备好 K8S 集群之后,安装 volcano,具体步骤可参考 :
https://volcano.sh/docs/getting-started/
2. 克隆 ElasticCTR 代码库
ElasticCTR 已在 github 上开源:
git clone https://github.com/PaddlePaddle/ElasticCTR
用户可以在操作 K8S 集群的开发机上下载代码库。
3. 准备数据集
部署一个 HDFS 集群,并在 HDFS 上存放好 Criteo 数据集。具体可参考 HDFS 配置教程。
https://github.com/PaddlePaddle/ElasticCTR/blob/master/HDFS_TUTORIAL.md
4. 执行训练
ElasticCTR 通过工具 elastic-control.sh 配置训练参数和启动训练,只需5条命令,即可搞定训练和部署。
sh elastic-control.sh -r #训练参数配置
sh elastic-control.sh -a #执行训练
sh elastic-control.sh -l #查看训练进度
sh elastic-control.sh –c #下载客户端SDK
python bin/elastic_ctr.py $IP 8010 conf/slot.conf data/ctr_prediction/data.txt #客户端预测
1)配置训练参数:
a. 在项目的 elastic-ctr-cli 文件夹下,配置 data.config 文件,指定数据集的来源。

上图可查看 data.config 的配置信息,包含 HDFS 的地址和路径,以及训练的起始时间(2019年12月2日0点)和终止时间(2019年12月2日0点,只训练一个小时的数据)。
执行如下命令,配置训练参数:
sh elastic-control.sh -r -u 4 -m 20 -t 2 -p 2 -b 2 -s slot.conf -f data.config
该命令表示在这次训练当中启动每个节点 4 个 CPU 20GB 的内存,2 个训练节点,2 个参数服务器节点,2 个稀疏参数索引服务节点,特征信息存放在 slot.conf,HDFS 地址和流式训练配置放在 data.config。
2)执行训练
sh elastic-control.sh -a

以上信息说明组件全部启动成功。
3)查看训练进度
sh elastic-control.sh -l

我们可以在上图看到训练结束,模型加载完成,此时就可以在客户端进行最后的验证了。
5. 在线预测
下载客户端 SDK,然后执行预测。
sh elastic-control.sh -c
python bin/elastic_ctr.py $IP 8010 conf/slot.conf data/ctr_prediction/data.txt
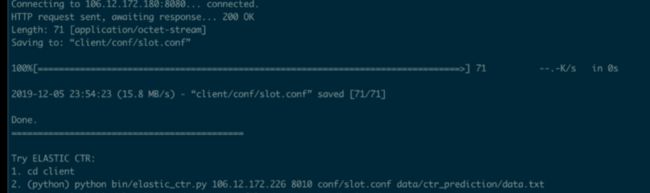
最终我们可以看到对于 data.txt 里的每一条样本,模型都会给出预估结果和概率,来预测用户是否会点击此广告条目。

我们在 data.txt 中存放了 100 条的数据,最终预测的 AUC 约为 0.68。
百度的使命是用科技让复杂的世界变简单,而 ElasticCTR 的使命是让推荐系统的开发和使用变简单。我们也将继续拥抱开源,博采众长,升级并完善 ElasticCTR 的各项功能,让推荐系统的工业应用更加便捷,开发者的工作更加容易。
参考链接
更多 ElasticCTR 的应用方法,欢迎访问项目地址:
GitHub:
https://github.com/PaddlePaddle/ElasticCTR
Gitee:
https://gitee.com/paddlepaddle/elasticctr
如果您加入官方 QQ 群,您将遇上大批志同道合的深度学习同学。
官方 QQ 群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

