SQL中GROUP BY/left join用法示例
SQL中GROUP BY用法示例
原文链接:https://www.jianshu.com/p/9f0a49c04bce
概述
GROUP BY我们可以先从字面上来理解,GROUP表示分组,BY后面写字段名,就表示根据哪个字段进行分组,如果有用Excel比较多的话,GROUP BY比较类似Excel里面的透视表。
GROUP BY必须得配合聚合函数来用,分组之后你可以计数(COUNT),求和(SUM),求平均数(AVG)等。
聚合函数目前只能对数值型(int,float)进行计算,非数值型(字符串)可以自定义函数计算
常用聚合函数
count() 计数
sum() 求和
avg() 平均数
max() 最大值
min() 最小值
语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
例子
下图是员工在职时间表 dept_emp共四个字段,分别是emp_no(员工编号),dept_no(部门编号),from_date(起始时间),to_date(结束时间),记录了员工在某一部门所处时间段,to_date等于9999-01-01的表示目前还在职。
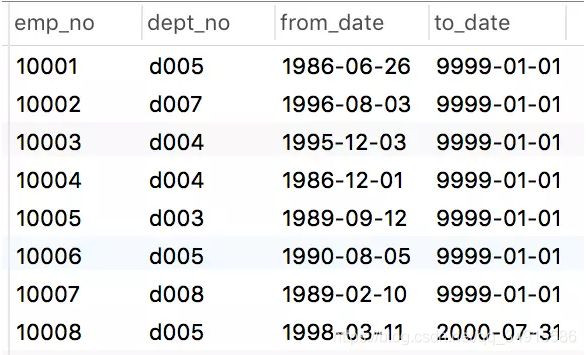
如果想统计每个部门有多少名在职员工,步骤如下:
1.筛选在职员工 where to_date=‘9999-01-01’;
2.对部门进行分组group by dept_no
3.对员工进行计数 count(emp_no)
SELECT
dept_no as 部门,
count(emp_no) as 人数
FROM
dept_emp
WHERE
to_date = '9999-01-01'
GROUP BY
dept_no
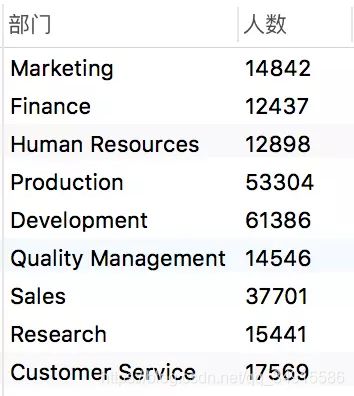
结果

进一步获取部门编号对应的部门名称
另外一张表departments具有字段dept_name、dept_no
SELECT
( SELECT d.dept_name FROM departments d WHERE de.dept_no = d.dept_no ) AS 部门,
count( de.emp_no ) AS 人数
FROM
dept_emp de
WHERE
de.to_date = '9999-01-01'
GROUP BY
de.dept_no
结果
HAVING
where是聚合前的筛选,having是聚合后对筛选
举个例子:
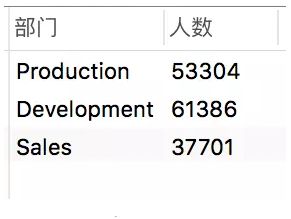
每个部门人数都有了,那如果我们想要进一步知道员工人数大于30000的部门是哪些,这个时候就得用到HAVING了。
语句如下:
SELECT
( SELECT d.dept_name FROM departments d WHERE de.dept_no = d.dept_no ) AS 部门,
count( de.emp_no ) AS 人数
FROM
dept_emp de
WHERE
de.to_date = '9999-01-01'
GROUP BY
de.dept_no
HAVING
count( de.emp_no ) > 30000
结果
联合
现在有一张表titles,共有4个字段,分别是emp_no(员工编号),title(职位),from_date(起始时间),to_date(结束时间),记录的是员工在某个时间段内职位名称,因为会存在升职,转岗之类的,里面emp_no可能会对应多个职位,我们现在要取到所有员工最近的职位信息,包括离职员工。
本文介绍两种方法去实现结果:
方法一
嵌套一个group by、聚合函数max()子查询获取最近的职位信息。
思路
1.通过对emp_no分组取每个emp_no对应的最大的from_date;
SELECT
emp_no,
max( from_date ) AS max_date
FROM
titles
GROUP BY
emp_no

2.通过查询出来的最大的from_date取筛选最近的的一条职位信息。
SELECT
t.emp_no,
t.title
FROM
titles t
LEFT JOIN ( SELECT emp_no, max( from_date ) AS max_date FROM titles GROUP BY emp_no ) et
ON t.emp_no = et.emp_no AND t.from_date = et.max_date
嵌套语句编写时先测试最里层的结果